КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Режимы работы микропроцессорной системы
|
|
|
|
Трансляторы
Как следует из многоуровневой архитектуры ЭВМ, прикладные программы пишутся на языках высокого уровня (ЯВУ). Существуют сотни таких языков, но процессор понимает только язык единиц и нулей. Поэтому программы на ЯВУ обычно транслируются на уровень 3 или 4 (уровень ассемблера). Программы трансляторы бывают двух видов – интерпретаторы и компиляторы.
Программа (микропрограмма) способная вызывать команды, операнды из памяти, определять тип команд и выполнять эти команды называется – интерпретатор.
Интерпретатор разбивает исходную программу на маленькие шаги и последовательно переводит каждую команду в исполняемый машинный код, посылая ее сразу на исполнение. Интерпретатор, как правило, хранится в виде микрокоманд в ПЗУ, например, устройства управления.
Отличительные особенности: медленно (надо декодировать каждую команду, процессор простаивает), но легко переносится на любую платформу, самое главное – в этом случае машина получается существенно более простой, т.к. часть аппаратного обеспечения заменяется программным.
Другая возможность создать транслятор – это использовать программу компилятор. Компилятор переводит полностью исходную программу на эквивалентный набор машинного языка и только затем загружает ее в память машины для выполне ния.
Отличительные особенности: быстро, но изменение платформы приводит к необходимости разработки нового компилятора. Есть и третья возможность, известная под именем Java машины или виртуальной машины Java – это компилятор, транслирующий ЯВУ на промежуточный псевдокод, а затем с псевдокода интерпретатор. При этом сочетаются отличительные особенности того и другого метода.
|
|
|
Как уже отмечалось, микропроцессорная система обеспечивает большую гибкость работы, она способна настраиваться на любую задачу. Гибкость эта обусловлена прежде всего тем, что функции, выполняемые системой, определяются программой (программным обеспечением, software), которую выполняет процессор. Аппаратура (аппаратное обеспечение, hardware) остается неизменной при любой задаче. Записывая в память системы программу, можно заставить микропроцессорную систему выполнять любую задачу, поддерживаемую данной аппаратурой. К тому же шинная организация связей микропроцессорной системы позволяет довольно легко заменять аппаратные модули, например, заменять память на новую большего объема или более высокого быстродействия, добавлять или модернизировать устройства ввода/вывода, наконец, заменять процессор на более мощный. Это также позволяет увеличить гибкость системы, продлить ее жизнь при любом изменении требований к ней.
Но гибкость микропроцессорной системы определяется не только этим. Настраиваться на задачу помогает еще и выбор режима работы системы, то есть режима обмена информацией по системной магистрали (шине). Практически любая развитая микропроцессорная система (в том числе и компьютер) поддерживает три основных режима обмена по магистрали:
- программный обмен информацией;
- обмен с использованием прерываний (Interrupts);
- обмен с использованием прямого доступа к памяти (ПДП, DMA — Direct Memory Access).
Программный обмен информацией является основным в любой микропроцессорной системе. Он предусмотрен всегда, без него невозможны другие режимы обмена. В этом режиме процессор является единоличным хозяином (или задатчиком, Master) системной магистрали. Все операции (циклы) обмена информацией в данном случае инициируются только процессором, все они выполняются строго в порядке, предписанном исполняемой программой.
|
|
|
Процессор читает (выбирает) из памяти коды команд и исполняет их, читая данные из памяти или из устройства ввода/вывода, обрабатывая их, записывая данные в память или передавая их в устройство ввода/вывода. Путь процессора по программе может быть линейным, циклическим, может содержать переходы (прыжки), но он всегда непрерывен и полностью находится под контролем процессора. Ни на какие внешние события, не связанные с программой, процессор не реагирует (рис. 6.9). Все сигналы на магистрали в данном случае контролируются процессором.
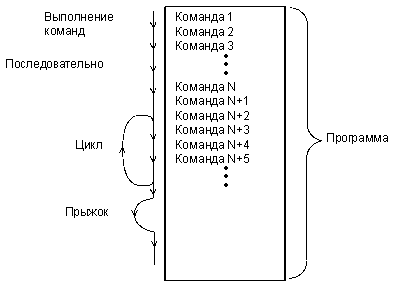
Рис. 6.9 Программный обмен информацией
Обмен по прерываниям используется тогда, когда необходима реакция микропроцессорной системы на какое-то внешнее событие, на приход внешнего сигнала. В случае компьютера внешним событием может быть, например, нажатие на клавишу клавиатуры или приход по локальной сети пакета данных. Компьютер должен реагировать на это, соответственно, выводом символа на экран или же чтением и обработкой принятого по сети пакета.
В общем случае организовать реакцию на внешнее событие можно тремя различными путями:
- с помощью постоянного программного контроля факта наступления события (так называемый метод опроса флага или polling);
- с помощью прерывания, то есть насильственного перевода процессора с выполнения текущей программы на выполнение экстренно необходимой программы;
- с помощью прямого доступа к памяти, то есть без участия процессора при его отключении от системной магистрали.
Проиллюстрировать эти три способа можно следующим простым примером. Допустим, вы готовите себе завтрак, поставив на плиту кипятиться молоко. Естественно, на закипание молока надо реагировать, причем срочно. Как это организовать? Первый путь — постоянно следить за молоком, но тогда вы ничего другого не сможете делать. Правильнее будет регулярно поглядывать на молоко, делая одновременно что-то другое. Это программный режим с опросом флага. Второй путь — установить на кастрюлю с молоком датчик, который подаст звуковой сигнал при закипании молока, и спокойно заниматься другими делами. Услышав сигнал, вы выключите молоко. Правда, возможно, вам придется сначала закончить то, что вы начали делать, так что ваша реакция будет медленнее, чем в первом случае. Наконец, третий путь состоит в том, чтобы соединить датчик на кастрюле с управлением плитой так, чтобы при закипании молока горелка была выключена без вашего участия (правда, аналогия с ПДП здесь не очень точная, так как в данном случае на момент выполнения действия вас не отвлекают от работы).
|
|
|
Первый случай с опросом флага реализуется в микропроцессорной системе постоянным чтением информации процессором из устройства ввода/вывода, связанного с тем внешним устройством, на поведение которого необходимо срочно реагировать.
Во втором случае в режиме прерывания процессор, получив запрос прерывания от внешнего устройства (часто называемый IRQ — Interrupt ReQuest), заканчивает выполнение текущей команды и переходит к программе обработки прерывания. Закончив выполнение программы обработки прерывания, он возвращается к прерванной программе с той точки, где его прервали (рис. 6.10).
Здесь важно то, что вся работа, как и в случае программного режима, осуществляется самим процессором, внешнее событие просто временно отвлекает его. Реакция на внешнее событие по прерыванию в общем случае медленнее, чем при программном режиме. Как и в случае программного обмена, здесь все сигналы на магистрали выставляются процессором, то есть он полностью контролирует магистраль. Для обслуживания прерываний в систему иногда вводится специальный модуль контроллера прерываний, но он в обмене информацией не участвует. Его задача состоит в том, чтобы упростить работу процессора с внешними запросами прерываний. Этот контроллер обычно программно управляется процессором по системной магистрали.
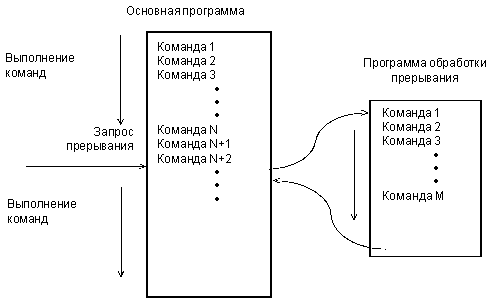
Рис. 6.10 Обслуживание прерывания.
Естественно, никакого ускорения работы системы прерывание не дает. Его применение позволяет только отказаться от постоянного опроса флага внешнего события и временно, до наступления внешнего события, занять процессор выполнением каких-то других задач.
Прямой доступ к памяти (ПДП, DMA) — это режим, принципиально отличающийся от двух ранее рассмотренных режимов тем, что обмен по системной шине идет без участия процессора. Внешнее устройство, требующее обслуживания, сигнализирует процессору, что режим ПДП необходим, в ответ на это процессор заканчивает выполнение текущей команды и отключается от всех шин, сигнализируя запросившему устройству, что обмен в режиме ПДП можно начинать.
|
|
|
Операция ПДП сводится к пересылке информации из устройства ввода/вывода в память или же из памяти в устройство ввода/вывода. Когда пересылка информации будет закончена, процессор вновь возвращается к прерванной программе, продолжая ее с той точки, где его прервали (рис. 6.11). Это похоже на режим обслуживания прерываний, но в данном случае процессор не участвует в обмене. Как и в случае прерываний, реакция на внешнее событие при ПДП существенно медленнее, чем при программном режиме.
Понятно, что в этом случае требуется введение в систему дополнительного устройства (контроллера ПДП), которое будет осуществлять полноценный обмен по системной магистрали без всякого участия процессора. Причем процессор предварительно должен сообщить этому контроллеру ПДП, откуда ему следует брать информацию и/или куда ее следует помещать. Контроллер ПДП может считаться специализированным процессором, который отличается тем, что сам не участвует в обмене, не принимает в себя информацию и не выдает ее (рис. 6.12).
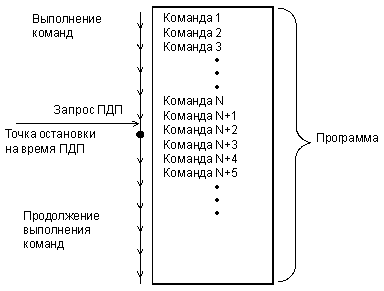
Рис. 6.11 Обслуживание ПДП
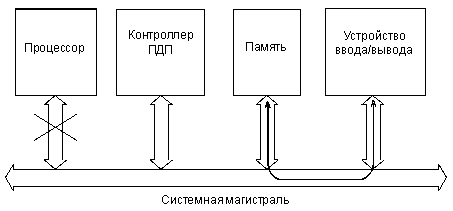
Рис. 6.12 Информационные потоки в режиме ПДП.
В принципе контроллер ПДП может входить в состав устройства ввода/вывода, которому необходим режим ПДП или даже в состав нескольких устройств ввода/вывода.
Теоретически обмен с помощью прямого доступа к памяти может обеспечить более высокую скорость передачи информации, чем программный обмен, так как процессор передает данные медленнее, чем специализированный контроллер ПДП. Однако на практике это преимущество реализуется далеко не всегда. Скорость обмена в режиме ПДП обычно ограничена возможностями магистрали. К тому же необходимость программного задания режимов контроллера ПДП может свести на нет выигрыш от более высокой скорости пересылки данных в режиме ПДП. Поэтому режим ПДП применяется редко. Если в системе уже имеется самостоятельный контроллер ПДП, то это может в ряде случаев существенно упростить аппаратуру устройств ввода/вывода, работающих в режиме ПДП. В этом, пожалуй, состоит единственное бесспорное преимущество режима ПДП.
Классификация процессоров
Итак, именно эволюция ЭВМ с интерпретатором (позже названных машинами с CISC процессорами) сформировала тенденцию использования:
· сложных, длинных команд;
· разнообразных форматов данных;
· разнообразных форматов команд;
· медленное выполнение наиболее простых операций.
С другой стороны, именно эволюция CISC (Complex Instruction Set Computer) процессоров послужила мощным стимулом для возникновения концепции RISC (Reduced Instruction Set Computer) архитектуры. Дело в том, что в начале 80-х архитектура CISC стала серьезным препятствием на пути реализации идеи «один процессор в одном кристалле», поскольку для работы с традиционным расширенным списком команд требуется очень сложное устройство управления (микропрограммный интерпретатор), занимающее свыше 60% площади кристалла. К тому времени стали известны результаты статистических исследований ученых IBM – правило 20/80.
На 20% команд программы приходится 80% времени исполнения задания.
В 1980 году группа разработчиков университета Беркли во главе с Девидом Паттерсоном и Карлом Секуин начали разработку процессора без использования интерпретации. Именно они и придумали термин RISC архитектура и выпустили RISC I, RISC II, которые эволюционировали в процессоры SPARC, а уже в 1981 году появились и знаменитые процессоры MIPS (Джон Хенноси – Стенфорд). Концепция RISC – архитектуры базируется на почти очевидной логической формуле: если быстрые технологии и параллельная обработка недостижимы для всего списка команд из-за высокого уровня затрат, необходимо оставить в системе команд несколько десятков простых, наиболее универсальных и часто употребляемых инструкций, исключив сложные и редко используемые.
Результатом должно было стать существенное упрощение центрального управления, а значит высвобождения значительной поверхности кристалла процессора для размещения более мощных средств обработки данных. Так возникла философия RISC – меньше команд, выше скорость и одна команда за один такт.
Первоначально RISC – процессоры действительно существенно вырвались вперед, сравните:
· процессор 80386, технология КМОП, частота 25 МГц, число транзисторов 275 000, производительность – 5 млн.оп.в сек (CISC);
· процессор R3000, технология КМОП, частота 25 МГц, число транзисторов 11500, производительность – 20 млн.оп.в сек (RISC). Сегодня условны и эти названия и различия между ними. Те и другие заимствовали лучшие черты конкурентов.
Для CISC процессоров характерно:
· небольшое число РОН (до 16);
· большое количество машинных команд (свыше 200);
· большое количество разнообразных форматов команд и методов адресации;
· преобладание двухадресного и безадресного формата команд;
· наличие команд типа «регистр - память»;
· команда выполняется за несколько тактов;
· использование механизма интерпретации.
Для RISC процессоров характерно:
· все обычные команды непосредственно выполняются аппаратным обеспечением, они не интерпретируются микрокомандами;
· в повышении производительности главную роль играет параллелизм, одновременное выполнение большого числа команд и одновременная обработка большого количества данных;
· большое количество РОН (свыше 32), лучший способ избежать транзакций – иметь достаточное количество регистров;
· сокращенный набор команд (несколько десятков);
· единообразие форматов команд, одинаковая длина и минимум адресных форматов;
· наличие и преобладание форматов команд «регистр - регистр», к памяти должны обращаться только команды загрузки и сохранения;
· команды выполняются за один такт, а, как правило, несколько команд за один такт;
· использование механизма компиляции.
И, само собой разумеется, все перечисленные базовые принципы RISC – архитектуры не существуют вне основного закона RISC: система команд должна содержать минимум наиболее часто используемых и наиболее простых инструкций.
При построении большинства CISC – процессоров используется аккумуляторная архитектура («память-регистр»). При этой архитектуре, в общем случае, требуется кроме собственно команды (например – сложение) еще две, по крайней мере, операции пересылки данных. При построении большинства RISC – процессоров применяется исключительно архитектура «регистр-регистр». При таком подходе любая из команд процессора может быть 3-х операндной, и выполнена за один такт. Реализация полной Гарвардской архитектуры, предсказание переходов и введение конвейеров команд и конвейеров обработки данных позволило на долгие годы RISC архитектуре стать лидером высокопроизводительных процессоров для серверов и рабочих станций.
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 493; Нарушение авторских прав?; Мы поможем в написании вашей работы!