КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Для проверки статистической значимости коэффициентов регрессии используется случайная величина 1 страница
|
|
|
|
Т bi = bi / Sbi, i = 0, 1, 2, …, m, (2.12)
имеющая распределение Стьюдента.
Правило проверки заключается в выполнении следующих действий.
1. Вычисляется наблюдаемое значение критерия для i -го коэффициента (2.12).
2. По заданным уровням значимости 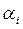 , i = 0, 1, …, m и степени свободы
, i = 0, 1, …, m и степени свободы 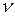 по таблице распределения Стьюдента определяются критические значения распределения t крит(
по таблице распределения Стьюдента определяются критические значения распределения t крит(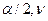 ).
).
3. Сравниваются наблюдаемые и критические значения между собой. Результатом сравнения является вывод о значимости коэффициентов b 0, b 1, b 2, …, bm.
2. Интервальные оценки коэффициентов уравнения регрессии.
Так как объем выборки ограничен, то b 0, b 1, b 2, …, b m – случайные величины, поэтому желательно найти доверительные интервалы для истинных значений 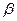 0, 1, 2, …, m. Для этого также используется t – критерий Стьюдента. Интервальные оценки коэффициентов уравнения регрессии определяются по формулам
0, 1, 2, …, m. Для этого также используется t – критерий Стьюдента. Интервальные оценки коэффициентов уравнения регрессии определяются по формулам
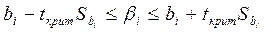 (2.13)
(2.13)
3. Проверка общего качества уравнения регрессии.
Для этой цели, как и в случае парной регрессии, используется коэффициент детерминации R2:
R 2 = 1 - 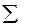 еi 2 /
еi 2 / 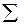 (yi -
(yi - 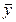 )2. (2.14)
)2. (2.14)
В множественной регрессии каждая новая переменная хi приводит к увеличению R 2, хотя это еще не означает, что уравнение регрессии становится более значимым. Чтобы исключить эту зависимость от числа переменных, иногда используют так называемый скорректированный коэффициент детерминации:
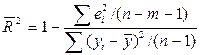 . (2.15)
. (2.15)
Или эту формулу можно преобразовать к виду:
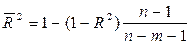 . (2.16)
. (2.16)
4. Анализ статистической значимости коэффициента детерминации.
По величине R 2 можно только предполагать насколько значимо или не значимо уравнение регрессии. Даже при небольшой величине R 2 (< 0,5) не всегда следует отказываться от уравнения регрессии. Для этого необходимо проверить статистическую значимость самого коэффициента детерминации. Для чего проверяются гипотезы
|
|
|
Н 0: R 2 = 0,
Н 1: R 2 > 0.
Для проверки используется распределение Фишера. Вычисляется F – статистика:
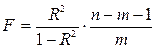 . (2.17)
. (2.17)
При заданном уровне значимости 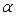 по таблице критических точек Фишера находится fкр, и если F > fкр, то R 2 статистически значим.
по таблице критических точек Фишера находится fкр, и если F > fкр, то R 2 статистически значим.
5. Проверка выполнимости предпосылок МНК с помощью статистики Дар бина-Уотсона.
Статистическая значимость коэффициентов регрессии и близкое к единице значение коэффициента детерминации R 2 еще не гарантируют высокое качество уравнения регрессии. Если не выполняются необходимые предпосылки МНК об отклонениях 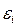 , то коэффициенты регрессии и само уравнение являются не вполне состоятельными, а это значит что внешние признаки «хорошего» уравнения не отвечают действительности. Поэтому следующим этапом проверки качества уравнения регрессии является проверка соответствия выборочных данных предпосылкам МНК. Для этого воспользуемся статистикой Дарбина – Уотсона, которая устанавливает, в частности, наличие или отсутствие статистической зависимости между ошибками . Так как истинные значения неизвестны, то проверка осуществляется в отношении оценок ошибок еi. При этом проверяется некоррелированность соседних значений еi.
, то коэффициенты регрессии и само уравнение являются не вполне состоятельными, а это значит что внешние признаки «хорошего» уравнения не отвечают действительности. Поэтому следующим этапом проверки качества уравнения регрессии является проверка соответствия выборочных данных предпосылкам МНК. Для этого воспользуемся статистикой Дарбина – Уотсона, которая устанавливает, в частности, наличие или отсутствие статистической зависимости между ошибками . Так как истинные значения неизвестны, то проверка осуществляется в отношении оценок ошибок еi. При этом проверяется некоррелированность соседних значений еi.
Статистика Дарбина – Уотсона DW рассчитывается по формуле:
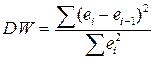 . (2.18)
. (2.18)
По таблицам критических точек Дарбина – Уотсона, входными параметрами которых являются: n – число наблюдений; m – количество объясняющих переменных; - уровень значимости, определяются два числа: d 1 – нижняя граница; du – верхняя граница.
Выводы осуществляются по следующей схеме.
Если DW < d 1, то это свидетельствует о положительной автокорреляции остатков.
Если DW > 4 - d 1, то это свидетельствует об отрицательной автокорреляции остатков.
При du < DW < 4 – du принимается гипотеза об отсутствии автокорреляции остатков.
|
|
|
Если d 1 < DW < du или 4 – du < DW < 4 – d 1, то остается неопределенность по вопросу наличия или отсутствия автокорреляции остатков.
В случае обнаружения признака автокорреляции необходимо скорректировать уравнение регрессии в соответствии с рекомендациями Главы IV
6. Прогноз значений зависимой переменной.
По аналогии с парной регрессией может быть построена интервальная оценка для среднего значения прогноза. Здесь речь идет о возможных значениях Yр при определенных значениях вектора объясняющей переменной Хр = (1, х 1 р , х 2 р , …, хmр)т.
Интервальный прогноз для среднего значения вычисляется следующим образом:
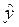 р
р 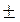 tкр S
tкр S 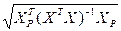 , (2.19)
, (2.19)
где р = b 0 + b 1 x 1 р + b 2 x 2 р + …+ bm xmр; t кр – критическое значение, полученное по распределению Стьюдента при количестве степеней свободы = n - m- 1 и заданной вероятности 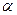 /2.
/2.
2.2. Реализация задания на компьютере с помощью ППП Ехсеl
Здесь так же, как и в парной регрессии необходимо выполнить задание в двух вариантах:
ВНИМАНИЕ! Каждый студент должен выполнить индивидуальное задание с использованием компьютера в двух вариантах:
3) Реализовать формулы (2.1) – (2.19) с помощью одиночных функций ППП Ехсеl.
4) Использовать «комплексные» функции, выходом которых являются не только коэффициенты регрессии, но и дополнительная регрессионная статистика (среднеквадратические отклонения, коэффициент детерминации и т.д.).
3) Реализация регрессионных формул (2.1) – (2.19) с помощью одиночных функций.
В первую очередь необходимо представить данные наблюдений в матричной форме (см. рис.2.1). Затем используя матричные функции из Мастер функций: МОБР, МУМНОЖ, ТРАНСП реализуем формулу (2.8), результатом которой будет вектор оценок коэффициентов регрессии В.
Примечание. Вышеперечисленные функции должны быть введены, как функции массивов в интервал с необходимым количеством строк и столбцов (см. реализацию функции ЛИНЕЙН в парной регрессии).
Для вычисления дисперсий 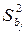 необходимо вычислить S 2 в соответствие с формулой (2.10). На основании Т -статистик делается вывод о значимости коэффициентов регрессии их доверительные интервалы. Значения tкр можно получить, используя статистическую функцию СТЬЮДРАСПОБР. По соответствующим формулам вычисляются коэффициент детерминации R 2 и F – критерий, на основании которых делается вывод о значимости уравнения регрессии в целом. Для нахождения критической точки fкр нужно воспользоваться функцией FРАСПОБР.
необходимо вычислить S 2 в соответствие с формулой (2.10). На основании Т -статистик делается вывод о значимости коэффициентов регрессии их доверительные интервалы. Значения tкр можно получить, используя статистическую функцию СТЬЮДРАСПОБР. По соответствующим формулам вычисляются коэффициент детерминации R 2 и F – критерий, на основании которых делается вывод о значимости уравнения регрессии в целом. Для нахождения критической точки fкр нужно воспользоваться функцией FРАСПОБР.
|
|
|
Проверка соответствия предпосылкам МНК осуществляется по критерию Дарбина – Уотсона. Критические значения распределения определяются из таблицы (электронного варианта таблицы нет).
Примерный вид реализации задачи на компьютере представлен на рис.2.2.
|
Рис.2.1
|

Рис.2.2
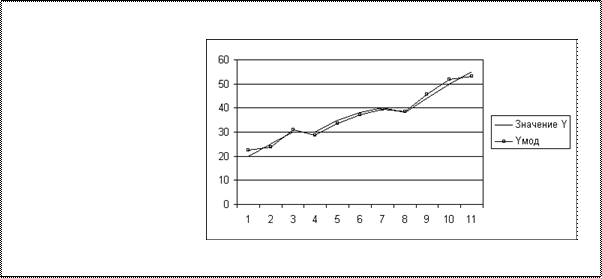
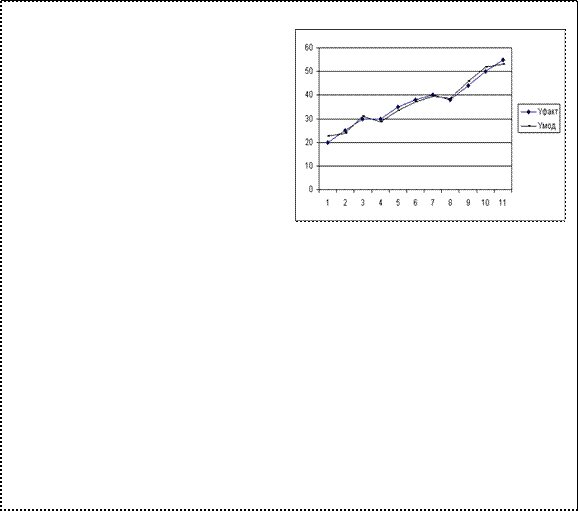
Для графической иллюстрации приближения корреляционной функции и выборочных данных yi воспользуемся Мастером диаграмм (График) (см. рис.2.3).
 |
| Значение Y | Yмод | |||||||||||
| 22,48852 | ||||||||||||
| 23,7304085 | ||||||||||||
| 31,009917 | ||||||||||||
| 28,6979627 | ||||||||||||
| 33,4936941 | ||||||||||||
| 37,0475369 | ||||||||||||
| 39,531314 | ||||||||||||
| 38,4612482 | ||||||||||||
| 45,7407567 | ||||||||||||
| 51,7783766 | ||||||||||||
| 53,0202652 | ||||||||||||
Рис.2.3
На рис.2.2 в ячейке с названием «S(Yp)» была вычислена стандартная ошибка прогноза объясняемой переменной по формуле:
S (Yр) = S 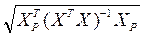 ,
,
которую необходимо использовать для определения интервальной оценки среднего значения предсказания.
4) Использование «Комплексных» функций.
В качестве такой функции может быть использована встроенная статистическая функция ЛИНЕЙН.
|
|
|
Дополнительная регрессионная статистика (в случае ее инициализации) будет выводиться в порядке, указанном на рис.2.4.
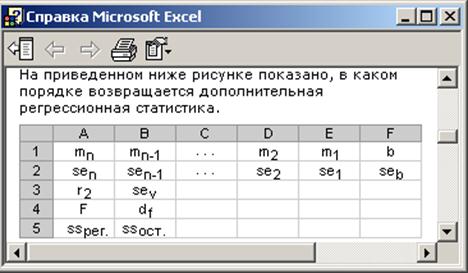
Рис.2.4.
Обозначения на рисунке следующие: b – свободный коэффициент линейной регрессии; mi – коэффициенты при хi; Se – стандартные ошибки коэффициентов регрессии; r2 - коэффициент детерминации; Sey - стандартная ошибка для оценки у; F – F - статистика; df – количество степеней свободы; Ssрег – регрессионная сумма квадратов; Ssост – остаточная сумма квадратов.
Для лучшей наглядности можно нужные значения из этой таблицы выбирать индивидуально и размещать в нужных форматах документа. Для этого можно воспользоваться функцией ИНДЕКС из категории Ссылки и массивы. Выделите ячейку, в которую хотите поместить отдельный элемент массива и введите формулу, например: Индекс (Линейн (Y;Х;1;1);1;2). В результате в данную ячейку будет записан элемент (1,2) регрессионной таблицы. Таким образом, можно создать более наглядную таблицу.
Пример решения задания на компьютере с использованием функции ЛИНЕЙН представлен на рисунках 2.5, 2.6.
|
Рис.2.5
 |
| № изм. | Yфакт | Yмод | ||||||||
| 22,48852 | ||||||||||
| 23,73041 | ||||||||||
| 31,00992 | ||||||||||
| 28,69796 | ||||||||||
| 33,49369 | ||||||||||
| 37,04754 | ||||||||||
| 39,53131 | ||||||||||
| 38,46125 | ||||||||||
| 45,74076 | ||||||||||
| 51,77838 | ||||||||||
| 53,02027 | ||||||||||
| Определение Т-стат. для коэффициентов bi | ||||||||||
| и доверительных интервалов | ||||||||||
| b0 | b1 | b2 | ||||||||
| Т-статистика | 1,56470182 | 5,84952 | 3,5025331 | |||||||
| Нижн.гран.дов.инт. | -1,4032731 | 0,075231 | 1,2140558 | |||||||
| Верх.гран.дов.инт. | 7,32717092 | 0,173147 | 5,8936299 | |||||||
Рис.2.6
Так же, как и в парной регрессии для оценки коэффициентов множественной регрессии и получения дополнительной статистики кроме функции Линейн можно воспользоваться Статистическим пакетом анализа данных.
Установка пакета анализа достаточно подробно описана в п. 1.2. В диалоговом окне Анализ данных в списке Инструменты анализа выберите строку Регрессия и заполните диалоговое окно ввода данных и параметров вывода. Результаты регрессионного анализа для данных выше использованного примерапредставлены на рис.2.7.
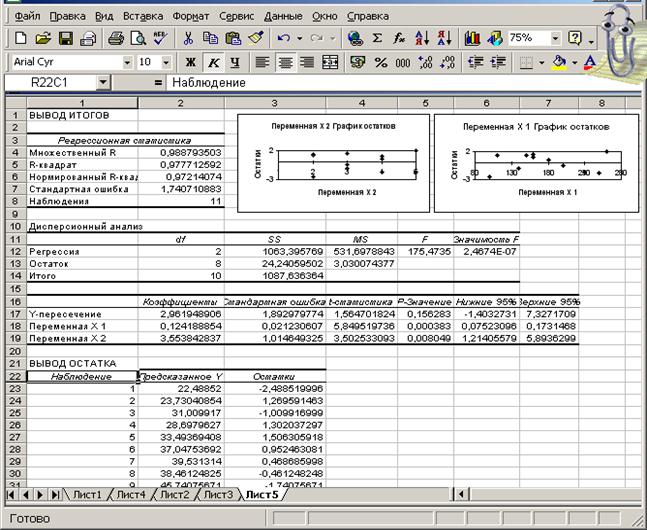
Рис.2.7
2.3. Контрольные задания
Задача 1. Предполагается, что объем Q предложения некоторого блага для функционирующей в условиях конкуренции фирмы зависит линейно от цены Р данного блага и заработной платы W сотрудников фирмы, производящих данное благо:
Q = 0 + 1 Р + 2 W + 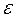 .
.
Статистические данные, собранные за 12 месяцев, занесены в таблицу.
Задание.
1. По МНК оценить коэффициенты линейной регрессии i, i = 0, 1, 2;
2. Оценить статистическую значимость найденных эмпирических коэффициентов регрессии b i, i =0, 1, 2;
3. В соответствие с заданным значением 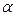 построить доверительные интервалы для найденных коэффициентов;
построить доверительные интервалы для найденных коэффициентов;
4. Вычислить коэффициент детерминации R 2 и оценить его статистическую значимость при заданном значении ;
5. Определить какой процент разброса зависимой переменной объясняется данной регрессией;
6. Сравнить коэффициент детерминации R 2 со скорректированным коэффициентом детерминации;
7. Вычислить статистику DW Дарбина-Уотсона и оценить наличие автокорреляции;
8. Посредством коэффициентов bi, i = 1, 2, оценить в % отношении влияние объясняющих переменных P и W на изменение объясняемой переменной;
9. Спрогнозировать значение объясняемой переменной Q прогн для прогнозных значений Р прогн, W прогн и определить доверительный интервал для Q прогн;
10. Сделать обобщающие выводы по регрессионной модели.
Вариант 1.1
| Q | ||||||||||||
| P | ||||||||||||
| W |
Р прогн = 60, W прогн = 2, = 0,01.
Вариант 1.2
| Q | ||||||||||||
| P | ||||||||||||
| W |
Р прогн = 75, W прогн = 1, = 0,02.
Вариант 1.3
| Q | ||||||||||||
| P | ||||||||||||
| W |
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 1804; Нарушение авторских прав?; Мы поможем в написании вашей работы!