КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Принцип метода
|
|
|
|
Предположим, что мы хотим испытать диуретическое действие нового препарата. Мы набираем десять добровольцев, случайным образом разделяем их на две группы — контрольную, которая получает плацебо и экспериментальную, которая получает препарат, а затем определяем суточный диурез. Результаты представлены на рис. 4.2А. Средний диурез в экспериментальной группе на 240 мл больше чем в контрольной. Впрочем, подобными данными мы вряд ли кого-нибудь убедим, что препарат — диуретик. Группы слишком малы. Повторим эксперимент, увеличив число участников. Теперь в обеих группах по 20 человек. Результаты представлены на рис. 4.2Б.
Средние и стандартные отклонения примерно те же, что и в

Рис. 4.2. Результаты испытаний предполагаемого диуретика. А. Диурез после приема плацебо и препарата. В обеих группах по 5 человек. Б. Теперь в обеих группах по 20 человек. Средние и стандартные отклонения остались прежними, однако доверие к результату повысилось.
эксперименте с меньшим числом участников. Кажется, однако, что результаты второго эксперимента заслуживают большего доверия. Почему? Вспомним, что точность выборочной оценки среднего характеризуется стандартной ошибкой среднего (см. гл. 2).
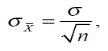
где n — объем выборки, а ó — стандартное отклонение совокупности, из которой извлечена выборка. С увеличением объема выборки стандартная ошибка среднего уменьшается, следовательно уменьшается и неопределенность в оценке выборочных средних. Поэтому уменьшается и неопределенность в оценке их разности. Применительно к нашему эксперименту, мы более уверены в диуретическом действии препарата. Точнее было бы сказать, мы менее уверены в справедливости гипотезы об отсутствии диуретического действия (Будь такая гипотеза верна, обе группы можно было бы считать двумя случайными выборками из нормально распреде-
|
|
|
ленной совокупности).
Чтобы формализовать приведенные рассуждения, рассмотрим отношение:
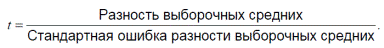
Для двух случайных выборок извлеченных из одной нормально распределенной совокупности это отношение, как правило, будет близко к нулю. Чем меньше (по абсолютной величине) t, тем больше вероятность нулевой гипотезы. Чем больше t, тем больше оснований отвергнуть нулевую гипотезу и считать, что различия статистически значимы.
Для нахождения величины t нужно знать разность выборочных средних и ее ошибку. Вычислить разность выборочных средних нетрудно — просто вычтем из одного среднего другое. Сложнее найти ошибку разности. Для этого обратимся к более общей задаче нахождения стандартного отклонения разности двух чисел, случайным образом извлеченных из одной совокупности.
СТАНДАРТНОЕ ОТКЛОНЕНИЕ РАЗНОСТИ
На рис. 4.ЗА представлена совокупность из 200 членов. Среднее равно 0, стандартное отклонение 1. Выберем наугад два члена совокупности и вычислим разность. Выбранные члены помечены на рис. 4.ЗА черными кружками, полученная разность представлена таким же кружком на рис. 4.ЗБ. Извлечем еще пять пар (на рисунках они различаются штриховкой), вычислим разность для каждой пары, результат снова поместим на рис. 4.ЗБ. Похоже, что разброс разностей больше разброса исходных данных. Извлечем наугад из исходной совокупности еще 100 пар, для каждой из которых вычислим разность. Теперь все разности включая вычисленные ранее изображены на рис. 4.3В. Стандартное отклонение для полученной совокупности разностей — примерно 1,4 то есть на 40% больше чем в исходной совокупности. Можно доказать что дисперсия разности двух случайно извлеченных значении равна сумме дисперсии совокупностей из которых они извлечены*.
|
|
|
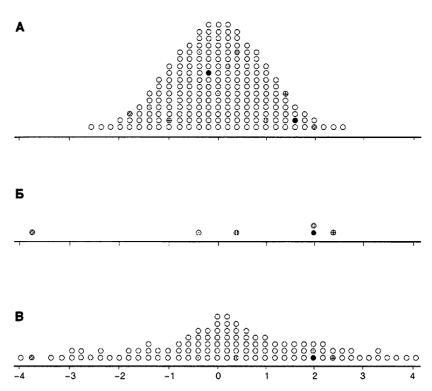
Рис. 4.3 А. Из этой совокупности мы будем извлекать пары и вычислять разности. Б. Разности первых 6 пар. В. Разности еще ста пар. Разброс разностей больше, чем разброс самих значений.
* Интересно, что дисперсия суммы двух случайно извлеченных значений тоже равна сумме дисперсий совокупностей, из которых они извлечены. Отсюда можно вывести формулу для стандартной ошибки среднего:
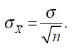
Предположим, что мы случайным образом извлекли n значений из совокупности, имеющей стандартное отклонение 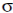 . Выборочное среднее равно
. Выборочное среднее равно
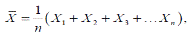 поэтому
поэтому
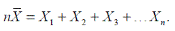
Так как дисперсия каждого из Xi равна 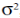 , дисперсия величины
, дисперсия величины  составит
составит
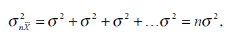
а стандартное отклонение
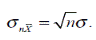
Нам нужно найти стандартное отклонение среднего X тождественно равного  поэтому
поэтому
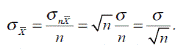
Мы получили формулу, которой неоднократно пользовались в предыдущих главах — формулу для стандартной ошибки среднего. Заметим что, выводя, ее мы, не делали никаких допущений о совокупности, из которой извлечена выборка. В частности мы не требовали, чтобы она имела нормальное распределение.
В частности если извлекать значения из одной совокупности, то дисперсия их разности будет равна удвоенной дисперсии этой совокупности. Говоря формально если значение X извлечено из совокупности, имеющей дисперсию 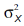 , а значение Y из совокупности имеющей дисперсию
, а значение Y из совокупности имеющей дисперсию 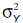 , то распределение всех возможных значений X – Y имеет дисперсию
, то распределение всех возможных значений X – Y имеет дисперсию

Почему дисперсия разностей больше дисперсии совокупности легко понять на нашем примере (см. рис. 4.3): в половине случаев члены пары лежат по разные стороны от среднего, поэтому их разность еще больше отклоняется от среднего, чем они сами.
Продолжим рассматривать рис. 4.3. Все пары извлекали из одной совокупности. Ее дисперсия равна 1. В таком случае дисперсия разностей будет
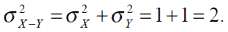
Стандартное отклонение есть квадратный корень из дисперсии. Поэтому стандартное отклонение разностей равно 2, то есть больше стандартного отклонения исходной совокупности примерно на 40%, как и получилось в нашем примере. Чтобы оценить дисперсию разности членов двух совокупностей по выборочным данным нужно в приведенной выше формуле заменить дисперсии их выборочными оценками
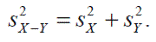
Этой формулой можно воспользоваться и для оценки стандартной ошибки разности выборочных средних. В самом деле, стандартная ошибка выборочного среднего — это стандартное отклонение совокупности средних значений всех выборок объемом n. Поэтому
|
|
|
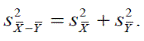
Тем самым искомая стандартная ошибка разности средних
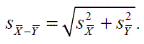
Теперь мы можем вычислить отношение t.
КРИТИЧЕСКОЕ ЗНАЧЕНИЕ t
Напомним, что мы рассматриваем отношение

Воспользовавшись результатом предыдущего раздела, имеем
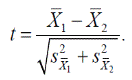
Если ошибку среднего выразить через выборочное стандартное отклонение, получим другую запись этой формулы
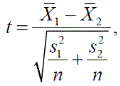
где n — объем выборки.
Если обе выборки извлечены из одной совокупности, то выборочные дисперсии 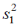 и
и 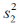 — это оценки одной и той же дисперсии
— это оценки одной и той же дисперсии 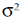 . Поэтому их можно заменить на объединенную оценку дисперсии. Для выборок равного объема объединенная оценка дисперсии вычисляется как
. Поэтому их можно заменить на объединенную оценку дисперсии. Для выборок равного объема объединенная оценка дисперсии вычисляется как
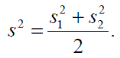
Значение t, полученное на основе объединенной оценки

Если объем выборок одинаков, оба способа вычисления t дадут одинаковый результат. Однако если объем выборок разный, то это не так. Вскоре мы увидим, почему важно вычислять объединенную оценку дисперсии, а пока посмотрим, какие значения t мы будем получать, извлекая случайные пары выборок из одной и той же нормально распределенной совокупности. Так как выборочные средние обычно близки к среднему по совокупности, значение t будет близко к нулю. Однако иногда мы все же будем получать большие по абсолютной величине значения t (вспомним опыты с F в предыдущей главе). Чтобы понять, какую величину t следует считать достаточно «большой», чтобы отвергнуть нулевую гипотезу, проведем мысленный эксперимент, подобный тому, что мы делали в предыдущей главе. Вернемся к испытаниям предполагаемого диуретина. Допустим, что в действительности препарат не оказывает диуретического действия.
Тогда и контрольную группу, которая получает плацебо, и экспериментальную, которая получает препарат, можно считать случайными выборками из одной совокупности. Пусть это будет совокупность из 200 человек, представленная на рис. 4.4А. Члены контрольной и кспериментальной групп различаются штриховкой. В нижней части рисунка данные по этим двум выборкам показаны так, как их видит исследователь. Взглянув на эти данные, трудно подумать, что препарат — диуретик. Полученное по этим выборкам значение t равно –0,2. Разумеется, с не меньшим успехом можно было бы извлечь любую другую пару выборок, что и сделано на рис. 4.4Б. Как и следовало ожидать, две новые выборки отличаются как друг от друга, так и от извлеченных ранее (рис. 4.4А). Интересно, что на этот раз нам «повезло» — средний диурез довольно сильно различается. Соответствующее значение t равно –2,1. На рис. 4.4В изображена еще одна пара выборок. Они отличаются друг от друга и от выборок с рис. 4.4А и 4.4Б. Значение t для них равно 0. Разных пар выборок можно извлечь более 1027. На рис. 4.5А приведено распределение значений t, вычисленных по 200 парам выборок. По нему уже можно судить о распределении t. Оно симметрично относительно нуля, поскольку любую из пары выборок можно счесть «первой». Как мы и предполагали, чаще всего значения t близки к нулю, значения, меньшие –2 и большие +2, встречаются редко.
|
|
|
На рис. 4.5Б видно, что в 10 случаях из 200 (в 5% всех случаев) t меньше –2,1 или больше +2,1. Иначе говоря, если обе выборки извлечены из одной совокупности, вероятность того, что значение
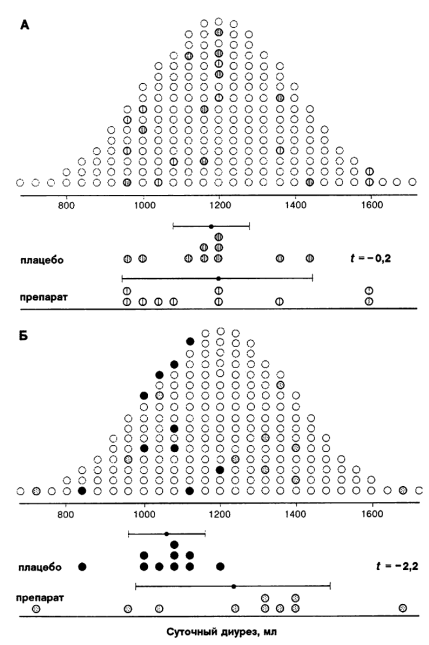
Рис. 4.4.
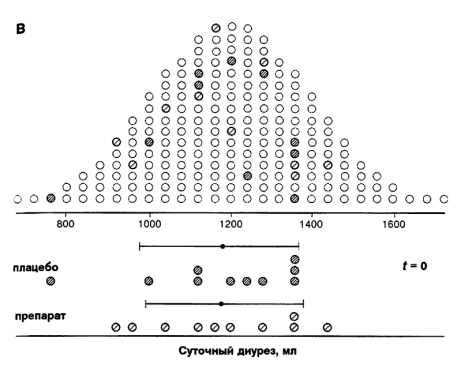
Рис. 4.4. Испытания предполагаемого диуретика. А. В действительности препарат не обладает диуретическим действием, поэтому обе группы — просто две случайные выборки из совокупности, показанной в верхней части рисунка. Члены совокупности, которым посчастливилось принять участие в исследовании, помечены штриховкой. В нижней части рисунка данные показаны такими, какими их видит исследователь. Вряд ли он решит, что препарат — диуретик: средний диурез в группах различается очень незначительно. Б. Исследователю могла бы попасться и такая пара выборок. В этом случае он наверняка бы счел препарат диуретиком. В. Еще две выборки из той же совокупности.
t лежит вне интервала от –2,1 до +2,1, составляет 5%. Продолжая извлекать пары выборок, мы увидим, что распределение принимает форму гладкой кривой, показанной на рис. 4.5В. Теперь 5% крайних значений соответствуют закрашенным областям графика левее –2,1 и правее +2,1. Итак, мы нашли, что если две выборки извлечены из одной и той же совокупности, то вероятность получить значение t, большее +2,1 или меньшее –2,1, составляет всего 5%. Следовательно, если значение t находится вне
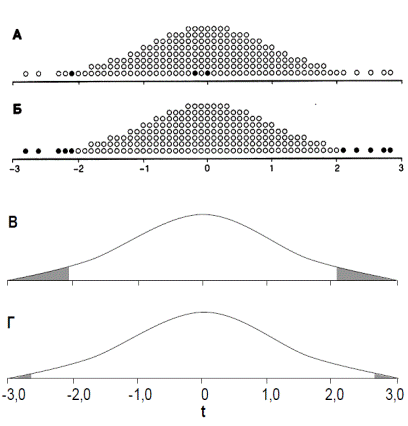
Рис. 4.5. А. Из совокупности, показанной на рис. 4.4, извлекли 200 пар случайных выборок по 10 членов в каждой, для каждой пары рассчитали значение t и нанесли его на график. Значения для t трех пар выборок с рис. 4.4 помечены черным. Большая часть значений сгруппирована вокруг нуля, однако некоторые значения по абсолютной величине превышают 1,5 и даже 2. Б. Число значений, по абсолютной величине превышающих 2,1 составляет 5%. В. Продолжая извлекать пары выборок, в конце концов мы получим гладкую кривую. 5% наибольших (по абсолютной величине) значений образуют две заштрихованные области (сумма заштрихованных площадей как раз и составляет 5% всей площади под кривой). Следовательно «большие» значения t начинаются там, где начинается заштрихованная область, то есть с t = ア2,1. Вероятность получить столь высокое значение t, извлекая случайные выборки из одной совокупности, не превышает 5%. Г. Описанный способ выбора критического значения t предопределяет возможность ошибки: в 5% случаев мы будем находить различия там, где их нет. Чтобь снизить вероятность ошибочного заключения, мы можем выбрать более высокое критическое значение. Например, чтобы площадь заштрихованной области составляла 1% от обшей площади под кривой, критическое значение должно составлять 2,878.
интервала от –2,1 до +2,1, нулевую гипотезу следует отклонить, а наблюдаемые различия признать статистически значимыми. Обратите внимание, что таким образом мы выявляем отличия экспериментальной группы от контрольной как в меньшую, так и в большую сторону — именно поэтому мы отвергаем нулевую гипотезу как при t < –2,1 так и при t > +2,1. Этот вариант критерия Стьюдента называется двусторонним, именно его обычно и используют. Существует и односторонний вариант критерия Стьюдента. Используется он гораздо реже, и в дальнейшем говоря о критерии Стьюдента, мы будем иметь в виду двусторонний вариант. Вернемся к рис. 4.4Б. На нем показаны две случайные выборки из одной и той же совокупности при этом t = – 2,2. Как мы только что выяснили, нам следует отвергнуть нулевую гипотезу и признать исследуемый препарат диуретиком, что самой собой неверно. Хотя все расчеты были выполнены правильно, вывод ошибочен. Увы, такие случаи возможны. Разберемся подробнее. Если значение t меньше –2,1 или больше +2,1, то при уровне значимости 0,05 мы сочтем различия статистически значимыми. Это означает, что если бы наши группы представляли собой две случайные выборки из одной и той же совокупности, то вероятность получить наблюдаемые различия (или более сильные) равна 0,05. Следовательно, ошибочный вывод о существовании различии мы будем делать в 5% случаев. Один из таких случаев и показан на рис. 4.4Б. Чтобы застраховаться от подобных ошибок, можно принять уровень значимости не 0,05, а скажем 0,01. Тогда, как видно из рис. 4.5Г, мы должны отвергать нулевую гипотезу при t < –2,88 или t > +2,88. Теперь-то рис. 4.4Б нас не проведет — мы не признаем подобные различия статистически значимыми. Однако во первых ошибочные выводы о существовании различий все же не исключены просто их вероятность снизилась до 1% и во вторых вероятность не найти различии там где они есть теперь повысилась. Критические значения t (подобно критическим значениям F они сведены в таблицу) зависят не только от уровня значимости, но и от числа степеней свободы  . Если объем обеих выборок — n, то число степеней свободы для критерия Стьюдента равно 2 (n – 1). Чем больше объем выборок, тем меньше критическое значение t. Это и понятно — чем больше выборка, тем менее выборочные оценки зависят от случайных отклонении и тем точнее представляют исходную совокупность.
. Если объем обеих выборок — n, то число степеней свободы для критерия Стьюдента равно 2 (n – 1). Чем больше объем выборок, тем меньше критическое значение t. Это и понятно — чем больше выборка, тем менее выборочные оценки зависят от случайных отклонении и тем точнее представляют исходную совокупность.
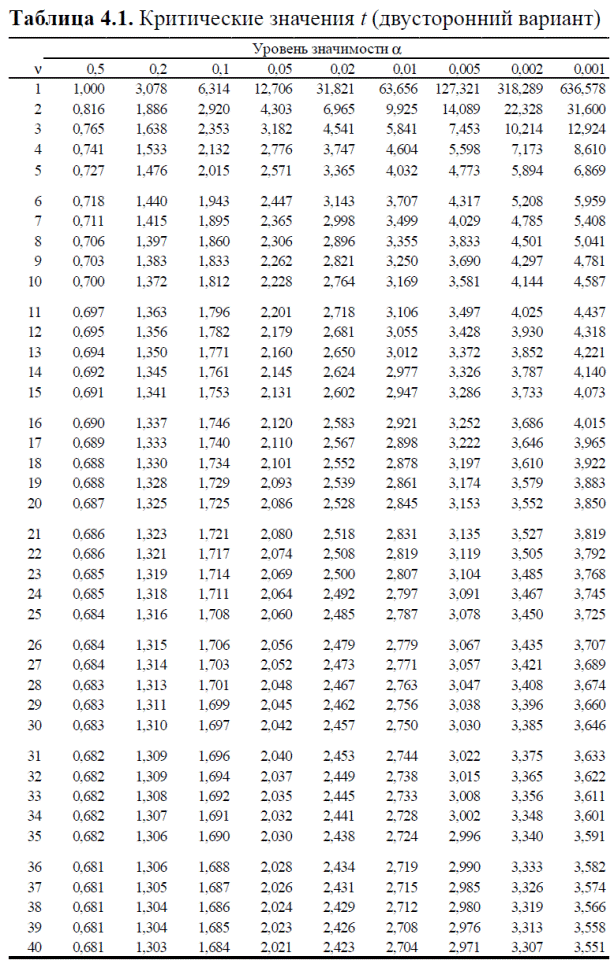

ВЫБОРКИ ПРОИЗВОЛЬНОГО ОБЪЕМА__
Критерий Стьюдента легко обобщается на случай, когда выборки содержат неодинаковое число членов. Напомним, что по определению
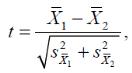
где 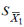 и
и  — стандартные ошибки средних для двух выборок. Если объем первой выборки равен n 1, а объем второй — n 2, то
— стандартные ошибки средних для двух выборок. Если объем первой выборки равен n 1, а объем второй — n 2, то
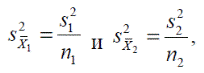
где s1 и s2 — стандартные отклонения выборок.
Перепишем определение t, используя выборочные стандартные отклонения:
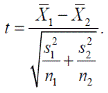
Объединенная оценка дисперсии для выборок объема n 1 и n 2 равна
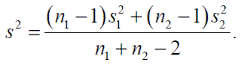
Тогда
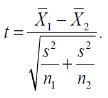
Это определение t для выборок произвольного объема. Число степеней свободы 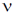 = n 1 + n 2 – 2.
= n 1 + n 2 – 2.
Заметим, что если объемы выборок равны, то есть n 1 = n 2 = n, то мы получим ранее использовавшуюся формулу для t.
ПРОДОЛЖЕНИЕ ПРИМЕРОВ
Применим теперь критерий Стьюдента к тем данным, которые рассматривались при изучении дисперсионного анализа. Выводы, которые мы получим, не будут отличаться от прежних, по-скольку как говорилось критерий Стьюдента есть частный случай дисперсионного анализа.
Позволяет ли правильное лечение сократить срок госпитализации?
Обратимся к рис. 3.7. Средняя продолжительность госпитализации 36 больных пиелонефритом, получавших правильное (соответствующее официальным рекомендациям) лечение, составила 4,51 сут, а 36 больных, получавших неправильное лечение 6,28 сут. Стандартные отклонения для этих групп — соответственно 1,98 сут и 2,54 сут. Так как численность групп одна и та же, объединенная оценка дисперсии s2 =1/2 (1,98 2+ 2,54 2) =5,18. Подставив эту величину в выражение для t, получим
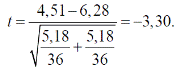
Число степеней свободы 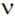 = 2 (n – 1) = 2 (36 – 1) = 70. По таблице 4.1 находим, что для 1% уровня значимости критическое значение t составляет 2,648, то есть меньше чем мы получили (по абсолютной величине). Следовательно, если бы наши группы представляли собой две случайные выборки из одной совокупности, то вероятность получить наблюдаемые различия, была бы меньше 1%. Итак различия в сроках госпитализации статистически значимы.
= 2 (n – 1) = 2 (36 – 1) = 70. По таблице 4.1 находим, что для 1% уровня значимости критическое значение t составляет 2,648, то есть меньше чем мы получили (по абсолютной величине). Следовательно, если бы наши группы представляли собой две случайные выборки из одной совокупности, то вероятность получить наблюдаемые различия, была бы меньше 1%. Итак различия в сроках госпитализации статистически значимы.
|
|
|
|
|
Дата добавления: 2014-12-23; Просмотров: 1076; Нарушение авторских прав?; Мы поможем в написании вашей работы!