КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Другие элементы меню 11 страница
|
|
|
|
//Методы Insert, Append, AppendFormat
StringBuilder strbuild = new StringBuilder();
string str = "это это не ";
strbuild.Append(str); strbuild.Append(true);
strbuild.Insert(4, false); strbuild.Insert(0,"2*2=5 - ");
Console.WriteLine(strbuild);
string txt = "А это пшеница, которая в темном чулане хранится," +
" в доме, который построил Джек!";
StringBuilder txtbuild = new StringBuilder();
int num =1;
foreach (string sub in txt.Split(','))
{
txtbuild.AppendFormat(" {0}: {1} ", num++,sub);
}
str = txtbuild.ToString();
Console.WriteLine(str);
В этом фрагменте кода конструируются две строки. Первая из них создается из строк и булевых значений true и false. Для конструирования используются методы Insert и Append. Вторая строка конструируется в цикле с применением метода AppendFormat. Результатом этого конструирования является строка, в которой простые предложения исходного текста пронумерованы.
Обратите внимание, сконструированная вторая строка передается в обычную строку класса string. Никаких проблем преобразования строк одного класса в другой класс не возникает, поскольку все объекты, в том числе объекты класса StringBuilder обладают по определению методом ToString.
Взгляните, как выглядят результаты работы:

Рис. 14.4. Операции и методы класса StringBuilder
Емкость буфера
Каждый экземпляр строки класса StringBuilder имеет буфер, в котором хранится строка. Объем буфера – его емкость может меняться в процессе работы со строкой. Объекты класса имеют две характеристики емкости – текущую и максимальную емкость. В процессе работы текущая емкость изменяется, естественно, в пределах максимальной емкости, которая реально достаточно высока. Если размер строки увеличивается, то соответственно автоматически растет и текущая емкость. Если же размер строки уменьшается, то емкость буфера остается на том же уровне. По этой причине иногда разумно уменьшать емкость. Следует помнить, что попытка уменьшить емкость до величины, меньшей длины строки, приведет к ошибке.
|
|
|
У класса StringBuilder имеется 2 свойства и один метод, позволяющие анализировать и управлять емкостными свойствами буфера. Напомню, что этими характеристиками можно управлять также еще на этапе создания объекта, – для этого имеется соответствующий конструктор. Рассмотрим свойства и метод класса, связанные с емкостью буфера:
· Свойство Capacity – возвращает или устанавливает текущую емкость буфера.
· Свойство MaxCapacity – возвращает максимальную емкость буфера. Результат один и тот же для всех экземпляров класса.
· Метод int EnsureCapacity(int capacity) – позволяет уменьшить емкость буфера. Метод пытается вначале установить емкость, заданную параметром capacity, если это значение меньше размера хранимой строки, то емкость устанавливается такой, чтобы гарантировать размещение строки. Это число и возвращается в качестве результата работы метода.
Приведу код, в котором проводятся различные эксперименты с емкостью буфера:
//Емкость буфера
int curvol1 = txtbuild.Capacity;
int curvol2 = strbuild.Capacity;
int maxvol1 = txtbuild.MaxCapacity;
int maxvol2 = strbuild.MaxCapacity;
Console.WriteLine("curvol1= {0}",curvol1);
Console.WriteLine("curvol2= {0}",curvol2);
Console.WriteLine("maxvol1= {0}",maxvol1);
Console.WriteLine("maxvol2= {0}",maxvol2);
int sure1 = txtbuild.EnsureCapacity(100);
int sure2 = strbuild.EnsureCapacity(100);
Console.WriteLine("sure1= {0}",sure1);
Console.WriteLine("sure2= {0}",sure2);
curvol2 = strbuild.Capacity;
Console.WriteLine("curvol2= {0}",curvol2);
//ошибка! попытка установить емкость меньше длины строки
//strbuild.Capacity = 25;
strbuild.Capacity = 256; //так можно!
curvol2 = strbuild.Capacity;
Console.WriteLine("curvol2= {0}",curvol2);
//увеличим строку - емкость увеличится
int len = txtbuild.Length;
txtbuild.Append(txtbuild.ToString());
curvol1 = txtbuild.Capacity;
Console.WriteLine("curvol1= {0}",curvol1);
//уменьшим строку
txtbuild.Remove(len, len);
curvol1 = txtbuild.Capacity;
Console.WriteLine("curvol1= {0}",curvol1);
В этом фрагменте кода анализируются и изменятся емкостные свойства буфера двух объектов. Демонстрируется, как меняется емкость при увеличении и уменьшении размера строки. Результаты работы этого фрагмента кода показаны на рис. 14.5:
|
|
|
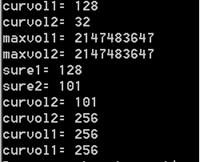
Рис. 14.5. Анализ емкостных свойств буфера
Вариант 1
37. Объект класса string можно создать:
q конструктором по умолчанию;
q без явного вызова конструктора;
q конструктором, которому передается объект string;
q конструктором, которому передается объект char[].
38. Отметьте правильные высказывания:
q при присваивании строк s = s1 создается дополнительная ссылка на объект, связанный с s1;
q присваивание s[i] = ch; где ch – переменная класса char, недопустимо;
q константы “\\c\x58” и @” \cX” эквивалентны;
q методы Join и Split являются статическими;
q форматы в методе Format позволяют задать только ссылку на объекты.
39. Какие высказывания справедливы для класса StringBuilder?
q существуют явные преобразования между классами string и StringBuilder;
q переменные этого класса можно создавать без явного вызова конструктора;
q набор операций класса тот же, что и у класса string;
q классы string и StringBuilder относятся к неизменяемым классам;
q методы Remove, Insert, Replace возвращают строку, представляющую результат операции.
Вариант 2
41. Объект класса string можно создать:
q конструктором, которому передается объект char*;
q конструктором, которому передается объект char;
q конструктором, которому передается строковая константа;
q конструктором, которому передается часть массива символов.
42. Отметьте правильные высказывания:
q эквивалентность строк (s ==s1) означает совпадение ссылок s и s1;
q операция (s+s1) определена, если s и s1 задают числа;
q операция взятия индекса s[i] над строками не определена;
q форматы в методе Format позволяют задать ссылку и способ форматирования объектов, вставляемых в строку;
q у класса string нет динамических методов.
43. Какие высказывания справедливы для класса StringBuilder?
q строки string можно присваивать строкам StringBuilder;
q строки StringBuilder можно создавать конструктором без параметров;
q у класса StringBuilder нет операции «+» – конкатенации;
q классы string и StringBuilder относятся к изменяемым классам;
q емкость буфера автоматически возрастает при увеличении размера строки.
Вариант 3
38. Отметьте правильные объявления:
q string c1= new string();
q string c2= new string(“ABC”);
q string c3= new string (‘a’);
q char[] car = new char[3]; car[1] =’a’; car[2] =’b’; string s =new string(car,0,2);
|
|
|
39. Отметьте правильные высказывания:
q присваивание ch =s[i]; где ch – переменная класса char, недопустимо;
q константы “\c\x58” и @” \cX” эквивалентны;
q метод Join всегда позволяет восстановить исходную строку, расщепленную методом Split;
q форматы в методе Format позволяют задать ширину области для вставляемого объекта.
40. Какие высказывания справедливы для класса StringBuilder?
q строки StringBuilder можно присваивать строкам string;
q строки StringBuilder можно создавать конструктором, передавая ему объект string в качестве параметра;
q недопустимо присваивание s[i] = ch; где s – строка класса StringBuilder, ch – переменная класса char;
q класс StringBuilder принадлежит изменяемым классам;
q емкость буфера автоматически уменьшается при удалении части строки.
Лекция 15. Регулярные выражения
Регулярные выражения. Пространство RegularExpressions и его классы. Регулярные выражения и языки. Теория регулярных выражений. Практика применения регулярных выражений. Разбор текстов и поиск по образцу. Свойства и методы класса Regex и других классов, связанных с регулярными выражениями. Примеры применения регулярных выражений.
Ключевые слова: регулярные выражения; пространство имен RegularExpression; итерация языка; регулярное множество; класс Regex; метод Match; коллекция MatchCollection; класс Match; группы; класс Group.
Пространство имен RegularExpression и классы регулярных выражений
Стандартный класс String позволяет выполнять над строками различные операции, в том числе поиск, замену, вставку и удаление подстрок. Есть специальные операции, такие как Join, Split, которые облегчают разбор строки на элементы. Тем не менее, есть классы задач по обработке символьной информации, где стандартных возможностей явно не хватает. Чтобы облегчить решение подобных задач, в Net Framework встроен более мощный аппарат работы со строками, основанный на регулярных выражениях. Специальное пространство имен RegularExpression, содержит набор классов, обеспечивающих работу с регулярными выражениями. Все классы этого пространства доступны для C# и всех языков, использующих каркас Net Framework. В основе регулярных выражений лежит хорошая теория и хорошая практика их применения. Полное описание, как теоретических основ, так и практических особенностей применения этого аппарата в C#, требует отдельной книги. Придется ограничиться введением в эту интересную область работы со строками, не рассматривая подробно все классы, входящие в пространство имен RegularExpression.
|
|
|
Немного теории
Пусть T= {a1, a2, ….an} – алфавит символов. Словом в алфавите T называется последовательность подряд записанных символов, а длиной слова – число его символов. Пустое слово, не содержащее символов, обычно обозначается как e. Алфавит T можно рассматривать как множество всех слов длины 1. Рассмотрим операцию конкатенации над множествами, так что конкатенация алфавита T с самим собой дает множество всех слов длины 2. Обозначается конкатенация ТТ как Т2. Множество всех слов длины k обозначается – Tk, его можно рассматривать как k-кратную конкатенацию алфавита T. Множество всех непустых слов произвольной длины, полученное объединением всех множеств Tk, обозначается T+, а объединение этого множества с пустым словом называется итерацией языка и обозначается T*. Итерация описывает все возможные слова, которые можно построить в данном алфавите. Любое подмножество слов L(T), содержащееся в T*, называется языком в алфавите T.
Определим класс языков, задаваемых регулярными множествами. Регулярное множество определяется рекурсивно следующими правилами:
Пустое множество, множество, содержащее пустое слово, одноэлементные множества, содержащие символы алфавита, являются регулярными базисными множествами.
Если множества P и Q являются регулярными, то множества, построенные применением операций объединения, конкатенации и итерации – 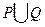 , PQ, P*, Q* – тоже являются регулярными.
, PQ, P*, Q* – тоже являются регулярными.
Регулярные выражения представляют удобный способ задания регулярных множеств. Аналогично множествам, они определяются рекурсивно:
Регулярные базисные выражения задаются символами и определяют соответствующие регулярные базисные множества, например, выражение f задает одноэлементное множество {f} при условии, что f символ алфавита T.
Если p и q – регулярные выражения, то операции объединения, конкатенации и итерации – p+q, pq, p*, q* являются регулярными выражениями, определяющими соответствующие регулярные множества.
По сути, регулярные выражения – это более простой и удобный способ записи в виде обычной строки регулярных множеств. Каждое регулярное множество, а, следовательно, и каждое регулярное выражение задает некоторый язык L(T) в алфавите T. Этот класс языков достаточно мощный, с его помощью можно описать интересные языки, но устроены они довольно просто – их можно определить также с помощью простых грамматик, например, правосторонних грамматик. Более важно, что для любого регулярного выражения можно построить конечный автомат, который распознает, принадлежит ли заданное слово языку, порожденному регулярным выражением. На этом основана практическая ценность регулярных выражений.
С точки зрения практика регулярное выражение задает образец поиска. После чего можно проверить, удовлетворяет ли заданная строка или ее подстрока данному образцу. В языках программирования синтаксис регулярного выражения существенно обогащается, что дает возможность более просто задавать сложные образцы поиска. Такие синтаксические надстройки, хотя и не меняют сути регулярных выражений, крайне полезны для практиков, избавляя программиста от ненужных сложностей.
В Net Framework эти усложнения, на мой взгляд, чрезмерны. Выигрывая в мощности языка, проигрываем в простоте записи его выражений.
Синтаксис регулярных выражений
Регулярное выражение на C# задается строковой константой. Это может быть обычная константа или @-константа. Чаще всего, следует использовать именно @-константу. Дело в том, что символ “\” широко используется в регулярных выражениях как для записи escape-последовательностей, так и в других ситуациях. Обычные константы в таких случаях будут выдавать синтаксическую ошибку, а @-константы не выдают ошибок и корректно интерпретируют запись регулярного выражения.
Синтаксис регулярного выражения простой формулой не описать, здесь используются набор разнообразных средств:
символы и escape-последовательности,
символы операций и символы, обозначающие специальные классы множеств,
имена групп и обратные ссылки,
символы утверждений и другие средства.
Конечно, регулярное выражение может быть совсем простым, например, строка “abc” задает образец поиска, так что при вызове соответствующего метода будут разыскиваться одно или все вхождения подстроки “abc” в искомую строку. Но могут быть и очень сложно устроенные регулярные выражения. Приведу таблицу, в которой дается интерпретация символов, в соответствии с их делением на группы. Таблица не полна, в ней отражаются не все группы, а описание группы не содержит всех символов. Она позволяет дать общее представление о синтаксисе, которое будет дополнено большим числом примеров. За деталями придется обращаться к справочной системе, которая, к сожалению, далеко не идеальна для данного раздела.
Таблица 15-1. Символы, используемые в регулярных выражениях
| Символ | Интерпретация |
| Категория: escape-последовательности | |
| \b | При использовании его в квадратных скобках соответствует символу “обратная косая” с кодом - \u0008 |
| \t | Соответствует символу табуляции \u0009. |
| \r | Соответствует символу возврата каретки \u000D. |
| \n | Соответствует символу новой строки \u000A. |
| \e | Соответствует символу escape \u001B. |
| \040 | Соответствует символу ASCII, заданному кодом до трех цифр в восьмеричной системе. |
| \x20 | Соответствует символу ASCII, заданному кодом из двух цифр в шестнадцатеричной системе |
| \u0020 | Соответствует символу Unicode, заданному кодом из четырех цифр в шестнадцатеричной системе |
| Категория: подмножества (классы) символов | |
| . | Соответствует любому символу, за исключением символа конца строки. |
| [aeiou] | Соответствует любому символу из множества, заданного в квадратных скобках. |
| [^aeiou] | Отрицание. Соответствует любому символу за исключением символов, заданных в квадратных скобках. |
| [0-9a-fA-F] | Задание диапазона символов, упорядоченных по коду. Так 0-9 задает любую цифру. |
| \p{name} | Соответствует любому символу, заданному множеству с именем name, например, имя Ll задает множество букв латиницы в нижнем регистре. Поскольку все символы разбиты на подмножества, задаваемые категорией Unicode, то в качестве имени можно задавать имя категории. |
| \P{name} | Отрицание. Большая буква всегда задает отрицание множества, заданного малой буквой. |
| \w | Множество символов, используемых при задании идентификаторов – большие и малые символы латиницы, цифры и знак подчеркивания. |
| \s | Соответствует символам белого пробела. |
| \d | Соответствует любому символу из множества цифр |
| Категория: Операции (модификаторы) | |
| * | Итерация. Задает ноль или более соответствий; например, \w* или (abc)*. Аналогично {0,}. |
| + | Положительная итерация. Задает одно или более соответствий, например, \w+ или (abc)+. Аналогично {1,}. |
| ? | Задает ноль или одно соответствие; например, \w? или (abc)?. Аналогично {0,1}. |
| {n} | Задает в точности n соответствий; например, \w{2}. |
| {n,} | Задает по меньшей мере n соответствий; например, (abc){2,}. |
| {n,m} | Задает по меньшей мере n, но не более m соответствий; например, (abc){2,5}. |
| Категория: Группирование | |
| (?<Name>) | При обнаружении соответствия выражению, заданному в круглых скобках, создается именованная группа, которой дается имя Name. Например, (?<tel> \d{7}). При обнаружении последовательности из семи цифр будет создана группа с именем tel. |
| () | Круглые скобки разбивают регулярное выражение на группы. Для каждого подвыражения, заключенного в круглые скобки, создается группа, автоматически получающая номер. Номера следуют в обратном порядке, поэтому полному регулярному выражению соответствует группа с номером 0. |
| (?imnsx) | Включает или выключает в группе любую из пяти возможных опций. Для выключения опции перед ней ставится знак минус. Например, (?i-s:) включает опцию i, задающую нечувствительность к регистру, и выключает опцию s – статус single-line. |
Повторяю, данная таблица не полна. В ней не отражены, например, такие категории, как подстановки, обратные ссылки, утверждения. Для приведенных категорий также не дан полный список возможных символов.
Знакомство с классами пространства RegularExpressions
В данном пространстве расположено семейство из одного перечисления и восьми связанных между собой классов.
Класс Regex
Это основной класс всегда создаваемый при работе с регулярными выражениями. Объекты этого класса определяют регулярные выражения. Конструктор класса, как обычно, перегружен. В простейшем варианте ему передается в качестве параметра строка, задающая регулярное выражение. В других вариантах конструктора ему может быть передан объект, принадлежащий перечислению RegexOptions, задающий опции, действующие при работе с данным объектом. Среди опций отмечу одну, – позволяющую компилировать регулярное выражение. В этом случае создается программа, которая и будет выполняться при каждом поиске соответствия. При разборе больших текстов скорость работы в этом случае существенно повышается.
Рассмотрим четыре основных метода класса Regex:
Метод Match запускает поиск соответствия. В качестве параметра методу передается строка поиска, в которой разыскивается первая подстрока, удовлетворяющая образцу, заданному регулярным выражением. В качестве результата метод возвращает объект класса Match, описывающий результат поиска. При успешном поиске свойства объекта будут содержать информацию о найденной подстроке.
Метод Matches позволяет разыскать все вхождения, то есть все подстроки, удовлетворяющие образцу. У алгоритма поиска есть важная особенность, – разыскиваются непересекающиеся вхождения подстрок. Можно считать, что метод Matches многократно запускает метод Match, каждый раз начиная поиск с того места, на котором закончился предыдущий поиск. В качестве результата возвращается объект MatchCollection, представляющий коллекцию объектов Match.
Метод NextMatch запускает новый поиск, начиная с того места, на котором остановился предыдущий поиск.
Метод Split является обобщением метода Split класса string. Он позволяет, используя образец, разделить искомую строку на элементы. Поскольку образец может быть устроен сложнее, чем простое множество разделителей, то метод Split класса Regex эффективнее, чем его аналог класса string.
Классы Match и MatchCollection
Как уже говорилось, объекты этих классов создаются автоматически при вызове методов Match и Matches. Коллекция MatchCollection, как и все коллекции, позволяет получить доступ к каждому ее элементу – объекту Match. Можно, конечно, организовать цикл for each для последовательного доступа ко всем элементам коллекции.
Класс Match является непосредственным наследником класса Group, который, в свою очередь, является наследником класса Capture. При работе с объектами класса Match наибольший интерес представляют не столько методы класса, сколько его свойства, большая часть которых наследована от родительских классов. Рассмотрим основные свойства:
Свойства Index, Length и Value наследованы от прародителя Capture. Они описывают найденную подстроку,– индекс начала подстроки в искомой строке, длину подстроки и ее значение.
Свойство Groups класса Match возвращает коллекцию групп – объект GroupCollection, который позволяет работать с группами, созданными в процессе поиска соответствия.
Свойство Captures, наследованное от объекта Group, возвращает коллекцию CaptureCollection. Как видите, при работе с регулярными выражениями реально приходится создавать один объект класса Regex, объекты других классов автоматически появляются в процессе работы с объектами Regex.
Классы Group и GroupCollection
Коллекция GroupCollection возвращается при вызове свойства Group объекта Match. Имея эту коллекцию, можно добраться до каждого объекта Group, входящего в коллекцию. Класс Group является наследником класса Capture и, одновременно, является родителем класса Match. От своего родителя он наследует свойства Index, Length и Value, которые и передает своему потомку.
Давайте рассмотрим чуть более подробно, когда и как создаются группы в процессе поиска соответствия. Если внимательно проанализировать предыдущую таблицу, описывающую символы, используемые в регулярных выражениях, в частности символы группирования, то можно понять несколько важных фактов, связанных с группами:
При обнаружении одной подстроки, удовлетворяющей условию поиска, создается не одна группа, а коллекция групп.
Группа с индексом 0 содержит информацию о найденном соответствии.
Число групп в коллекции зависит от числа круглых скобок в записи регулярного выражения. Каждая пара круглых скобок создает дополнительную группу, которая описывает ту часть подстроки, которая соответствует шаблону, заданному в круглых скобках.
Группы могут быть индексированы, но могут быть и именованными, поскольку в круглых скобках разрешается указывать имя группы.
В заключение отмечу, что создание именованных групп крайне полезно при разборе строк, содержащих разнородную информацию. Примеры разбора подобных текстов будут даны.
Классы Capture и CaptureCollection
Коллекция CaptureCollection возвращается при вызове свойства Captures объектов класса Group и Match. Класс Match наследует это свойство у своего родителя – класса Group. Каждый объект Capture, входящий в коллекцию характеризует соответствие, захваченное в процессе поиска – соответствующую подстроку. Но поскольку свойства объекта Capture передаются по наследству его потомкам, то можно избежать непосредственной работы с объектами Capture. По крайней мере, в моих примерах не встретится работа с этим объектом, хотя за кулисами он непременно присутствует.
Перечисление RegexOptions
Объекты этого перечисления описывают опции, влияющие на то, как устанавливается соответствие. Обычно такой объект создается первым и передается конструктору объекта класса Regex. В вышеприведенной таблице, в разделе, посвященном символам группирования, говорится о том, что опции можно включать и выключать, распространяя, тем самым, их действие на участок шаблона, заданный соответствующей группой. Об одной из этих опций – Compiled, влияющей на эффективность работы регулярных выражений, уже упоминалось. Об остальных говорить не буду, при необходимости можно посмотреть справку.
Класс RegexCompilationInfo
При работе со сложными и большими текстами полезно предварительно скомпилировать используемые в процессе поиска регулярные выражения. В этом случае необходимо будет создать объект класса RegexCompilationInfo и передать ему информацию о регулярных выражениях, подлежащих компиляции, и о том, куда поместить оттранслированную программу. Дополнительно в таких ситуациях следует включить опцию Compiled. К сожалению, соответствующих примеров на эту тему не будет.
Примеры работы с регулярными выражениями
Полагаю, что примеры дополнят краткое описание возможностей регулярных выражений и позволят лучше понять, как с ними работать. Начну с функции FindMatch, производящей поиск первого вхождения подстроки, соответствующей образцу:
string FindMatch(string str, string strpat)
{
Regex pat = new Regex(strpat);
Match match =pat.Match(str);
string found = "";
if (match.Success)
{
found =match.Value;
Console.WriteLine("Строка ={0}\tОбразец={1}\tНайдено={2}",
str,strpat,found);
}
return (found);
}// FindMatch
В качестве входных аргументов функции передается строка str, в которой ищется вхождение, и строка patstr, задающая образец – регулярное выражение. Функция возвращает найденную в результате поиска подстроку. Если соответствия нет, то возвращается пустая строка. Функция начинает свою работу с создания объекта pat класса Regex, конструктору которого передается образец поиска. Затем вызывается метод Match этого объекта, создающий объект match класса Match. Далее анализируются свойства этого объекта. Если соответствие обнаружено, то найденная подстрока возвращается в качестве результата, а соответствующая информация выводится на печать.
Чтобы спокойно работать с классами регулярных выражений, я не забыл добавить в начало проекта предложение: using System.Text.RegularExpressions;
Поскольку запись регулярных выражений вещь, привычная не для всех программистов, я приведу достаточно много примеров:
public void TestSinglePat()
{
//поиск по образцу первого вхождения
string str,strpat,found;
Console.WriteLine("Поиск по образцу");
// образец задает подстроку, начинающуюся с символа a,
//далее идут буквы или цифры.
str ="start"; strpat =@"a\w+";
found = FindMatch(str,strpat);
str ="fab77cd efg";
found = FindMatch(str,strpat);
//образец задает подстроку,начинающуюся с символа a,
//заканчивающуюся f с возможными символами b и d в середине
strpat = "a(b|d)*f"; str = "fabadddbdf";
found = FindMatch(str,strpat);
//диапазоны и escape-символы
strpat = "[X-Z]+"; str = "aXYb";
found = FindMatch(str,strpat);
strpat = @"\u0058Y\x5A"; str = "aXYZb";
found = FindMatch(str,strpat);
}// TestSinglePat
Некоторые комментарии к этой процедуре:
Регулярные выражения задаются @-константами, описанными в лекции 14. Здесь они как нельзя кстати.
В первом образце используется последовательность символов \w+, обозначающая, как следует из таблицы 15-1, непустую последовательность латиницы и цифр. В совокупности образец задает подстроку, начинающуюся символом a, за которым следуют буквы или цифры (хотя бы одна). Этот образец применяется к двум различным строкам.
|
|
|
|
|
Дата добавления: 2014-12-25; Просмотров: 424; Нарушение авторских прав?; Мы поможем в написании вашей работы!