КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Другие элементы меню 12 страница
|
|
|
|
В следующем образце используется символ * для обозначения итерации. В целом регулярное выражение задает строки, начинающиеся с символа a, заканчивающиеся символом f, между которыми находится возможно пустая последовательность символов из b и d.
Последующие два образца демонстрируют использование диапазонов и escape-последовательностей для представления символов, заданных кодами (в Unicode и шестнадцатеричной кодировке).
Взгляните на результаты, полученные при работе этой процедуры:
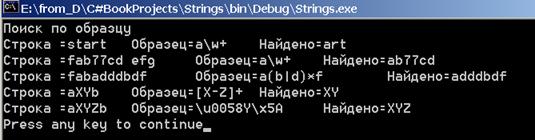
Рис. 15.1. Регулярные выражения. Поиск по образцу
Пример “чет и нечет”
Не всякий класс языков можно описать с помощью регулярных выражений. И даже тогда, когда это можно сделать, могут потребоваться определенные усилия, для корректной записи соответствующего регулярного выражения. Рассмотрим, например, язык L1в алфавите T={0,1}, которому принадлежат пустое слово и слова, содержащие четное число нулей и четное число единиц. В качестве другого примера рассмотрим язык L2, отличающийся от первого тем, что в нем число единиц нечетно. Оба языка можно задать регулярными выражениями, но корректная запись не проста и требует определенного навыка. Давайте запишем регулярные выражения, определяющие эти языки, и покажем, что C# справляется с проблемой их распознавания. Вот регулярное выражение, описывающее первый язык:
(00|11)*((01|10)(00|11)*(01|10)(00|11)*)*
Дадим содержательное описание этого языка. Слова языка представляют возможно пустую последовательность из пар одинаковых символов. Далее может следовать последовательность, начинающаяся и заканчивающаяся парами различающихся символов, между которыми может стоять произвольное число пар одинаковых символов. Такая группа может повторяться многократно. Регулярное выражение короче и точнее передает описываемую структуру слов языка L1.
|
|
|
Язык L2 описать теперь совсем просто. Его слова представляют собой единицу, окаймленную словами языка L1.
Прежде чем перейти к примеру распознавания слов языков L1 и L2, приведу процедуру FindMatches, позволяющую найти все вхождения образца в заданный текст:
void FindMatches(string str, string strpat)
{
Regex pat = new Regex(strpat);
MatchCollection matchcol =pat.Matches(str);
Console.WriteLine("Строка ={0}\tОбразец={1}",
str,strpat);
Console.WriteLine("Число совпадений ={0}",matchcol.Count);
foreach (Match match in matchcol)
Console.WriteLine("Index = {0} Value = {1}, Length ={2}",
match.Index,match.Value, match.Length);
}// FindMatches
Входные аргументы у процедуры те же, что и у функции FindMatch, ищущей первое вхождение. Я не стал задавать выходных аргументов процедуры, ограничившись тем, что все результаты непосредственно выводятся на печать в самой процедуре. Выполнение процедуры также как и в FindMatch начинается с создания объекта pat класса Regex, конструктору которого передается регулярное выражение. Замечу, что класс Regex, также как и класс string относится к неизменяемым (immutable) классам, так что для каждого нового образца нужно создавать новый объект pat. В отличие от FindMatch объект pat вызывает метод Matches, определяющий все вхождения подстрок, удовлетворяющих образцу, в заданный текст. Результатом выполнения метода Matches является автоматически создаваемый объект класса MatchCollection, хранящий коллекцию объектов уже известного нам класса Match, каждый из которых задает очередное вхождение. В процедуре используются свойства коллекции и ее элементов для получения в цикле по элементам коллекции нужных свойств – индекса очередного вхождения подстроки в строку, ее длины и значения.
Вот процедура, в которой многократно вызывается FindMatches для различных строк и образцов поиска:
public void TestMultiPat()
{
//поиск по образцу всех вхождений
string str,strpat,found;
Console.WriteLine("Распознавание языков: чет и нечет");
|
|
|
//четное число нулей и единиц
strpat ="((00|11)*((01|10)(00|11)*(01|10)(00|11)*)*)";
str = "0110111101101";
FindMatches(str, strpat);
//четное число нулей и нечетное единиц
string strodd = strpat + "1" + strpat;
FindMatches(str, strodd);
}// TestMultiPat
Коротко прокомментирую работу этой процедуры. Первые два примера связаны с распознаванием языков L1 и L2 (чет и нечет) – языков с четным числом единиц и нулей в первом случае и нечетным числом единиц во втором случае. Регулярные выражения, описывающие эти языки, подробно рассматривались. В полном соответствии с теорией константы задают эти выражения. На вход для распознавания подается строка из нулей и единиц. Для языка L1 метод находит три соответствия. Первое из них задает максимально длинную подстроку, содержащую четное число нулей и единиц, и две пустые подстроки, по определению принадлежащие языку L1. Для языка L2 находится одно соответствие – это сама входная строка. Взгляните на результаты распознавания:
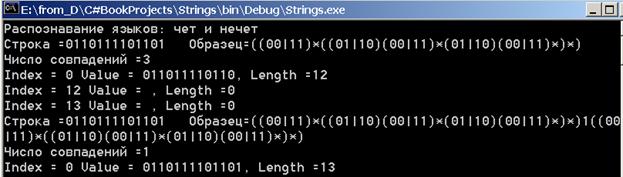
Рис. 15.2. Регулярные выражения. Пример “чет и нечет”
Пример “око и рококо”
Следующий образец в нашем примере позволяет прояснить некоторые особенности работы метода Matches. Сколько раз строка “око” входит в строку “рококо” – один или два? Все зависит от того, как считать. С точки зрения метода Matches один раз, поскольку он разыскивает непересекающиеся вхождения, начиная очередной поиск вхождения подстроки с того места, где закончилось предыдущее вхождение. Еще один пример на эту же тему работает с числовыми строками.
Console.WriteLine("око и рококо");
strpat="око"; str = "рококо";
FindMatches(str, strpat);
strpat="123";
str= "0123451236123781239";
FindMatches(str, strpat);
На рис. 15.3 показаны результаты поисков:
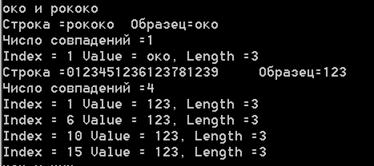
Рис. 15.3. Регулярные выражения. Пример «око и рококо»
Пример “кок и кук”
Этот пример на поиск множественных соответствий навеян словами песни Высоцкого, где говорится, что дикари не смогли распознать, где кок, а где кук. Наше регулярное выражение также не распознает эти слова. Обратите внимание на точку в регулярном выражении, которая соответствует любому символу, за исключением символа конца строки. Все слова в строке поиска – кок, кук, кот и другие будут удовлетворять шаблону, так что в результате поиска найдется множество соответствий.
|
|
|
Console.WriteLine("кок и кук");
strpat="(т|к).(т|к)";
str="кок тот кук тут как кот";
FindMatches(str, strpat);
Вот результаты работы этого фрагмента кода:
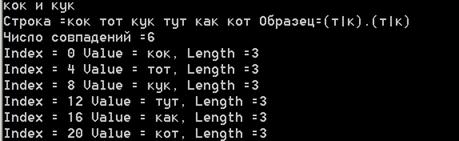
Рис. 15.4. Регулярные выражения. Пример «кок и кук»
Пример “обратные ссылки”
В этом примере рассматривается ранее упоминавшаяся, но не описанная возможность задания в регулярном выражении обратных ссылок. Можно ли описать с помощью регулярных выражений язык, в котором встречаются две подряд идущие одинаковые подстроки? Ответ на это вопрос отрицательный, поскольку грамматика такого языка должна быть контекстно-зависимой, нужна память, чтобы хранить уже распознанные части строки. Аппарат регулярных выражений, предоставляемый классами пространства RegularExpression, тем не менее, позволяет решить эту задачу. Это связано с тем, что расширение стандартных регулярных выражений в Net Framework является не только синтаксическим. Содержательные расширения связаны с введением понятия группы, которой отводится память и дается имя. Это и дает возможность ссылаться на уже созданные группы, что и делает грамматику языка контекстно-зависимой. Ссылка на ранее полученную группу называется обратной ссылкой. Признаком обратной ссылки является пара символов “\k”, после которой идет имя группы. Приведу пример:
Console.WriteLine("Ссылка назад - второе вхождение слова");
strpat = @"\s(?<word>\w+)\s\k'word'";
str = "I know know that, You know that!";
FindMatches(str, strpat);
Рассмотрим более подробно регулярное выражение, заданное строкой strpat. В группе, заданной скобочным выражением, после знака вопроса идет имя группы “word”, взятое в угловые скобки. После имени группы идет шаблон, описывающий данную группу, в данном примере шаблон задает произвольный идентификатор “\w+”. В дальнейшем описании шаблона задается ссылка на группу с именем “word”. Здесь имя группы заключено в одинарные кавычки. Поиск успешно справился с поставленной задачей, подтверждением чему являются результаты работы этого фрагмента кода.

Рис. 15.5. Регулярные выражения. Пример «обратные ссылки»
Пример “Дом Джека”
Давайте вернемся к задаче разбора предложения на элементы. В классе string для этого имеется метод Split, который и решает поставленную задачу. Однако у этого метода есть существенный недостаток, – он не справляется с подряд идущими разделителями и создает для таких пар пустые слова. Метод Split класса Regex лишен этих недостатков, в качестве разделителей можно задавать любую пару символов, произвольное число пробелов и другие комбинации символов. Повторим наш прежний пример:
|
|
|
public void TestParsing()
{
string str,strpat;
//разбор предложения - создание массива слов
str = "А это пшеница, которая в темном чулане хранится," +
" в доме, который построил Джек!";
strpat =" +|, ";
Regex pat = new Regex(strpat);
string [] words;
words = pat.Split(str);
int i=1;
foreach (string word in words)
Console.WriteLine("{0}: {1}",i++,word);
}// TestParsing
Регулярное выражение, заданное строкой strpat, определяет множество разделителей. Заметьте, в качестве разделителя задан пробел, повторенный сколь угодно много раз, либо пара символов – запятая и пробел. Разделители задаются регулярными выражениями. Метод Split применяется к объекту pat класса Regex. В качестве аргумента методу передается текст, подлежащий расщеплению. Вот как выглядит массив слов после применения метода Split:
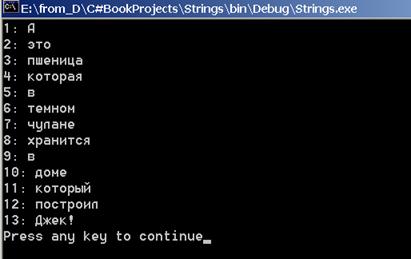
Рис. 15.6. Регулярные выражения. Пример «Дом Джека»
Пример “Атрибуты”
Как уже говорилось, регулярные выражения особенно хороши при разборе сложных текстов. Примерами таких текстов могут быть различные справочники, различные текстовые базы данных, весьма популярные теперь XML-документы, разбором которых приходится заниматься. В качестве заключительного примера рассмотрим структурированный документ, строки которого содержат некоторые атрибуты, например, телефон, адрес и email. Структуру документа можно задавать по-разному, будем предполагать, что каждый атрибут задается парой «имя: Значение» Наша задача состоит в том, чтобы выделить из строки соответствующие атрибуты. В таких ситуациях регулярное выражение удобно задавать в виде групп, где каждая группа соответствует одному атрибуту. Приведу начальный фрагмент кода очередной тестирующей процедуры, в котором описываются строки текста и образцы поиска:
public void TestAttributes()
{
string s1 = "tel: (831-2) 94-20-55 ";
string s2 = "Адрес: 117926 Москва 5-й Донской проезд, стр.10,кв. 7";
string s3 = "email: [email protected] ";
string s4 = s1+ s2 + s3;
string s5 = s2 + s1 + s3;
string pat1 = @"tel:\s(?<tel>\((\d|-)*\)\s(\d|-)+)\s";
string pat2= @"Адрес:\s(?<addr>[0-9А-Яа-я \-\,\.]+)\s";
string pat3 =@"email:\s(?<em>[a-zA-Z.@]+)\s";
string compat = pat1+pat2+pat3;
string tel="", addr = "", em = "";
Строки s4 и s5 представляют строку разбираемого документа. Их две, для того чтобы можно было проводить эксперименты, когда атрибуты представлены в документе в произвольном порядке. Каждая из строк pat1, pat2, pat3 задает одну именованную группу в регулярном выражении, имена групп – tel, Адрес, email – даются в соответствии со смыслом атрибутов. Сами шаблоны подробно описывать не буду, сделаю лишь одно замечание. Например, шаблон телефона исходит из того, что номеру телефона предшествует код, заключенный в круглые скобки. Поскольку сами скобки играют особую роль, то для задания скобки как символа используется пара – “\(“. Это же касается и многих других символов, используемых в шаблонах – точки, дефиса и других. Строка compat представляет составное регулярное выражение, содержащее все три группы. Строки tel, addr и em нам понадобятся для размещения в них результатов разбора. Применим вначале к строкам s4 и s5 каждый из шаблонов pat1, pat2, pat3 в отдельности и выделим соответствующий атрибут из строки. Вот код, выполняющий эти операции:
Regex reg1 = new Regex(pat1);
Match match1= reg1.Match(s4);
Console.WriteLine("Value =" + match1.Value);
tel= match1.Groups["tel"].Value;
Console.WriteLine(tel);
Regex reg2 = new Regex(pat2);
Match match2= reg2.Match(s5);
Console.WriteLine("Value =" + match2.Value);
addr= match2.Groups["addr"].Value;
Console.WriteLine(addr);
Regex reg3 = new Regex(pat3);
Match match3= reg3.Match(s5);
Console.WriteLine("Value =" + match3.Value);
em= match3.Groups["em"].Value;
Console.WriteLine(em);
Все выполняется нужным образом, – создаются именованные группы, к ним можно получить доступ и извлечь найденный значения атрибутов. А теперь попробуем решить ту же задачу одним махом, используя составной шаблон compat:
Regex comreg = new Regex(compat);
Match commatch= comreg.Match(s4);
tel= commatch.Groups["tel"].Value;
Console.WriteLine(tel);
addr= commatch.Groups["addr"].Value;
Console.WriteLine(addr);
em= commatch.Groups["em"].Value;
Console.WriteLine(em);
}// TestAttributes
И эта задача успешно решается. Взгляните на результаты разбора текста:
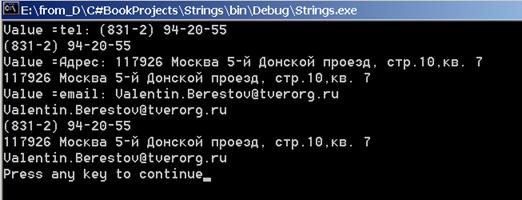
Рис. 15.7. Регулярные выражения. Пример «Атрибуты»
На этом и завершим рассмотрение регулярных выражений и лекции, посвященные работе с текстами в C#.
Вариант 1
40. Отметьте правильные высказывания:
q регулярные выражения задают специальный класс языков;
q для работы с регулярными выражениями в.Net Framework включен класс RegularExpressions;
q объекты класса Match создаются конструктором с параметрами;
q группа – это совокупность регулярных выражений, объединенных знаком +;
q регулярное выражение задает шаблон поиска подстроки в строке текста.
41. Классу Regex принадлежат следующие свойства и методы:
q Match;
q Success;
q Index;
q Group;
q GetGroupNames.
42. Какие слова принадлежат языку, заданному регулярным выражением: @“[A-Za-z]\w+=\w+[\+|\-|\*]\w+”
q x=u+v+w;
q xyz=2x*y5;
q a = b-c;
q U=v+w;
q Agent007=James-Bond.
Вариант 2
44. Отметьте правильные высказывания:
q класс Regex является корневым классом в пространстве имен RegularExpressions;
q объект Match создается при вызове метода Match;
q регулярное выражение состоит из совокупности групп;
q объект Capture описывает подстроку, найденную в процессе поиска;
q каждый объект Match содержит коллекцию групп.
45. Укажите правильный вариант отношения между классами:
q класс Match – родительский класс, его непосредственные потомки – классы Capture и Group;
q класс Regex – родительский класс, его непосредственные потомки – классы Match, Capture и Group;
q класс Capture – родительский класс, его непосредственные потомки – классы Match и Group;
q класс Capture – родительский класс, его непосредственный потомок – класс Group, потомком которого является класс Match.
46. Какие слова принадлежат языку, заданному регулярным выражением: @ “[a-zA-z]\w*\s*=\s*\w+(\s*\+\s*\w+)+”
q x=y+z;
q XYZ = 2 + 3 + 7;
q Agent007 = James + Bond;
q x5 = 5x;
q 5y= y5.
Вариант 3
41. Отметьте правильные высказывания:
q регулярное выражение позволяет определить, является ли одна строка частью другой строки;
q регулярное выражение позволяет определить, принадлежит ли строка языку, заданному регулярным выражением;
q регулярное выражение позволяет определить, есть ли в строке подстрока, удовлетворяющая шаблону, заданному регулярным выражением;
q регулярные выражения позволяют найти все вхождения подстрок, удовлетворяющие шаблону;
q регулярные выражения позволяют найти все непересекающиеся вхождения подстрок, удовлетворяющие шаблону.
42. Чтобы получить объект Match можно:
q создать его, передав конструктору регулярное выражение;
q создать объект класса Regex, вызвать метод Matches и выбрать нужный объект из коллекции;
q объявить объект Match без инициализации, создать объект класса Regex, вызвать метод Match и его результат присвоить объекту Match;
q объявить объект Match без инициализации, создать объект класса Regex, вызвать свойство Group и у полученной группы вызвать свойство Match, результат которого присвоить объекту Match.
43. Какие слова принадлежат языку, заданному регулярным выражением: @“\w\s=\s\w+(\+|\-\w+)+”
q x=y+z;
q 5 = 3+2;
q 7 = 5-2;
q x = 2 + y – 7;
q x1 = z-x
Лекция 16. Классы
Две роли класса в ООП. Синтаксис описания класса. Поля и методы класса. Конструкторы и деструкторы. Статические поля и методы. Статические конструкторы. Поля только для чтения. Закрытые поля. Стратегии доступа к полям класса. Процедуры свойства. Индексаторы. Примеры.
Ключевые слова: класс – это тип данных; класс – это модуль; проектирование от данных; синтаксис описания класса; поля класса; свойства объектов класса; модификатор доступа; методы класса; закрытые методы; методы-свойства; синтаксис методов-свойств; индексатор; операции; бинарная или унарная операция; статические поля; статические методы; константы; конструкторы класса; деструкторы класса; атрибут readonly.
Классы и ООП
Объектно-ориентированное программирование и проектирование построено на классах. Любую программную систему, построенную в объектном стиле, можно рассматривать как совокупность классов, возможно объединенных в проекты, пространства имен, решения, как это делается при программировании в Visual Studio.Net.
Две роли классов
У класса две различные роли: модуля и типа данных. Класс – это модуль, архитектурная единица построения программной системы. Модульность построения – основное свойство программных систем. В ООП программная система, строящаяся по модульному принципу, состоит из классов, являющихся основным видом модуля. Модуль может не представлять собой содержательную единицу, его размер и содержание определяется архитектурными соображениями, а не семантическими. Ничто не мешает построить монолитную систему, состоящую из одного модуля, – она может решать ту же задачу, что и система, состоящая из многих модулей.
Вторая роль класса не менее важна. Класс – это тип данных, задающий реализацию некоторой абстракции данных, характерной для задачи, в интересах которой создается программная система. С этих позиций классы, это не просто кирпичики, из которых строится система. Каждый кирпичик теперь имеет важную содержательную начинку. Представьте себе современный дом, построенный из кирпичей, и дом будущего, где каждый кирпич выполняет определенную функцию, один следит за температурой, другой – за составом воздуха в доме. ОО-программная система напоминает дом будущего.
Состав класса, его размер определяется не архитектурными соображениями, а той абстракцией данных, которую должен реализовать класс. Если вы создаете класс Account, реализующий такую абстракцию как банковский счет, то в этот класс нельзя добавить поля из класса Car, задающего автомобиль.
Объектно-ориентированная разработка программной системы основана на стиле, называемом проектированием от данных. Проектирование системы сводится к поиску подходящих для данной задачи абстракций данных. Каждая из них реализуется в виде класса, которые и становятся модулями – архитектурными единицами построения нашей системы. В основе класса лежит абстрактный тип данных.
В хорошо спроектированной ОО-системе каждый класс играет обе роли, так что каждый модуль нашей системы имеет вполне определенную смысловую нагрузку. Типичная ошибка – рассматривать класс, только как архитектурную единицу, объединяя под обложкой класса разнородные поля и функции, после чего становится неясным, какой же тип данных задает этот класс.
Синтаксис класса
Ни одна из предыдущих лекций не обходилась без появления классов и обсуждения многих деталей связанных с ними. Сейчас попробуем сделать некоторые уточнения, подвести итоги и с новых позиций взглянуть на уже знакомые вещи. Начнем с синтаксиса описания класса:
[атрибуты][модификаторы]class имя_класса[:список_родителей]
{тело_класса}
Атрибутам будет посвящена отдельная лекция. Возможными модификаторами в объявлении класса могут быть модификаторы new, abstract, sealed, о которых подробно будет говориться при рассмотрении наследования, четыре модификатора доступа, два из которых – private и protected могут быть заданы только для вложенных классов. Обычно класс имеет атрибут доступа public, являющийся значением по умолчанию. Так что в простых случаях объявление класса выглядит так:
public class Rational {тело_класса}
В теле класса могут быть объявлены:
константы;
поля;
конструкторы и деструкторы;
методы;
события;
делегаты;
классы (структуры, интерфейсы, перечисления).
О событиях и делегатах предстоит подробный разговор в последующих лекциях. Из синтаксиса следует, что классы могут быть вложенными. Такая ситуация довольно редкая. Ее стоит использовать, когда некоторый класс носит вспомогательный характер, разрабатывается в интересах другого класса и есть полная уверенность, что внутренний класс никому не понадобится кроме класса, в который он вложен. Как уже упоминалось, внутренние классы обычно имеют модификатор доступа, отличный от public. Основу любого класса составляют его конструкторы, поля и методы.
Поля класса
Поля класса синтаксически являются обычными переменными (объектами) языка Их описание удовлетворяет обычным правилам объявления переменных, о чем подробно говорилось в лекции 5. Содержательно поля задают представление той самой абстракции данных, которую реализует класс. Поля характеризуют свойства объектов класса. Напомню, что когда создается новый объект класса (в динамической памяти или в стеке), то этот объект представляет собой набор полей класса. Два объекта одного класса имеют один и тот же набор полей, но разнятся значениями, хранимыми в этих полях. Все объекты класса Person могут иметь поле, характеризующее рост персоны, но один объект может быть высокого роста, другой – низкого, а третий – среднего роста.
Доступ к полям
Каждое поле имеет модификатор доступа, принимающий одно из четырех значений: public, private, protected, internal. Атрибутом доступа по умолчанию является атрибут private. Независимо от значения атрибута доступа все поля доступны для всех методов класса. Они являются для методов класса глобальной информацией, с которой работают все методы, извлекая из полей нужные им данные и изменяя значения полей в ходе работы. Если поля доступны только для методов класса, то тогда они имеют атрибут доступа private, который можно опускать. Такие поля считаются закрытыми. Но часто желательно, чтобы некоторые поля были доступны в более широком контексте. Если некоторые поля класса A должны быть доступны для методов класса B, являющегося потомком класса A, то такие поля следует снабдить атрибутом protected. Такие поля называются защищенными. Если некоторые поля должны быть доступны для методов классов B1, B2, и так далее, дружественных по отношению к классу A, то такие поля следует снабдить атрибутом internal, а все дружественные классы B поместить в один проект (assembly). Такие поля называются дружественными. Наконец, если некоторые поля должны быть доступны для методов любого класса B, которому доступен сам класс A, то такие поля следует снабдить атрибутом public. Такие поля называются общедоступными или открытыми.
Методы класса
Методы класса синтаксически являются обычными процедурами и функциями языка. Их описание удовлетворяет обычным правилам объявления процедур и функций, о чем подробно говорилось в лекции 9. Содержательно методы определяют ту самую абстракцию данных, которую реализует класс. Методы описывают операции, доступные над объектами класса. Два объекта одного класса имеют один и тот же набор методов.
Доступ к методам
Каждый метод имеет модификатор доступа, принимающий одно из четырех значений: public, private, protected, internal. Атрибутом доступа по умолчанию является атрибут private. Независимо от значения атрибута доступа все методы доступны для вызова при выполнении метода класса. Если методы имеют атрибут доступа private, возможно опущенный, то тогда они доступны только для вызова только внутри методов самого класса. Такие методы считаются закрытыми. Понятно, что класс, у которого все методы закрыты, абсурден, поскольку никто не смог бы вызвать ни один из его методов. Как правило, у класса есть открытые методы, задающие интерфейс класса, и закрытые методы. Интерфейс – это лицо класса, именно он определяет, чем класс интересен своим клиентам, что он может делать, какие сервисы предоставляет клиентам. Закрытые методы составляют важную часть класса, позволяя клиентам класса не вникать во многие детали реализации класса. Эти методы клиентам класса недоступны, они о них могут ничего не знать, и, самое главное, изменения в закрытых методах класса никак не отражаются на клиентах класса при условии корректной работы открытых методов класса.
Если некоторые методы класса A должны быть доступны для вызовов в методах класса B, являющегося потомком класса A, то такие методы следует снабдить атрибутом protected. Если некоторые методы должны быть доступны только для методов классов B1, B2, и так далее, дружественных по отношению к классу A, то такие методы следует снабдить атрибутом internal, а все дружественные классы B поместить в один проект. Наконец, если некоторые методы должны быть доступны для методов любого класса B, которому доступен сам класс A, то такие методы снабжаются атрибутом public.
Методы-свойства
Методы, называемые свойствами (Properties), представляют специальную синтаксическую конструкцию, предназначенную для обеспечения эффективной работы со свойствами. При работе со свойствами объекта (полями) часто нужно решить, какой модификатор доступа использовать, чтобы реализовать нужную стратегию доступа к полю класса. Перечислю пять наиболее употребительных стратегий:
чтение, запись (Read, Write);
чтение, запись при первом обращении (Read, Write-once);
только чтение (Read-only);
только запись (Write-only);
ни чтения, ни записи (Not Read, Not Write).
Открытость свойств (атрибут public) позволяет реализовать только первую стратегию. В языке C# принято, как и в других объектных языках, свойства объявлять закрытыми, а нужную стратегию доступа организовать через методы. Для эффективности этого процесса и введены специальные методы-свойства.
Приведу вначале пример, а потом уточню синтаксис этих методов. Рассмотрим класс Person, у которого пять полей: fam, status, salary, age, health, характеризующих фамилию, статус, зарплату, возраст и здоровье персоны. Для каждого из этих полей может быть разумной своя стратегия доступа. Возраст доступен для чтения и записи, фамилию можно задать только один раз, статус можно только читать, зарплата недоступна для чтения, а здоровье закрыто для доступа, только специальные методы класса могут сообщать некоторую информацию о здоровье персоны. Вот как на C# можно обеспечить эти стратегии доступа к закрытым полям класса:
public class Person
{
//поля (все закрыты)
|
|
|
|
|
Дата добавления: 2014-12-25; Просмотров: 597; Нарушение авторских прав?; Мы поможем в написании вашей работы!