КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Архитектуры CISC и RISC
|
|
|
|
Коммуникационный процессор
Коммуникационный процессор целиком выделяется для обработки передаваемой информации, контроля и устранения ошибок, кодирование сообщений, управление линией связи и т.п.)
В отдельные классы следует выделить так называемые систолитические и нейросигнальные процессоры.
Систолические процессоры (процессорные матрицы) - это чипы, как правило, близкие к обычным RISC-процессорам и объединяющие в своём составе некоторое число процессорных элементов. Вся же остальная логика, как правило, должна быть реализована на базе периферийных схем.
У нейросигнальных процессоров ядро представляет собой типовой сигнальный процессор, а реализованная на кристале дополнительная логика обеспечивает выполнение нейросетевых операций (например, дополнительный векторный процессор и т.п.).
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники являются архитектуры CISC и RISC. Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой /360, ядро которой используется с1964 года и дошло до наших дней, например, в таких современных мейнфреймах как IBM ES/9000.
Лидером в разработке микропроцессоров c полным набором команд (CISC - Complete Instruction Set Computer) считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров. Для CISC-процессоров характерно: сравнительно небольшое число регистров общего назначения; большое количество машинных команд, некоторые из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за много тактов; большое количество методов адресации; большое количество форматов команд различной разрядности; преобладание двухадресного формата команд; наличие команд обработки типа регистр-память.
Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд (RISC - Reduced Instruction Set Computer). Зачатки этой архитектуры уходят своими корнями к компьютерам CDC6600, разработчики которых (Торнтон, Крэй и др.) осознали важность упрощения набора команд для построения быстрых вычислительных машин. Эту традицию упрощения архитектуры С. Крэй с успехом применил при создании широко известной серии суперкомпьютеров компании Cray Research. Однако окончательно понятие RISC в современном его понимании сформировалось на базе трех исследовательских проектов компьютеров: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета.
Разработка экспериментального проекта компании IBM началась еще в конце 70-х годов, но его результаты никогда не публиковались и компьютер на его основе в промышленных масштабах не изготавливался. В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой проект и изготовили две машины, которые получили названия RISC-I и RISC-II. Главными идеями этих машин было отделение медленной памяти от высокоскоростных регистров и использование регистровых окон. В 1981 году Дж.Хеннесси со своими коллегами опубликовал описание стенфордской машины MIPS, основным аспектом разработки которой была эффективная реализация конвейерной обработки посредством тщательного планирования компилятором его загрузки.
Эти три машины имели много общего. Все они придерживались архитектуры, отделяющей команды обработки от команд работы с памятью, и делали упор на эффективную конвейерную обработку. Система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт). Сама логика выполнения команд с целью повышения производительности ориентировалась на аппаратную, а не на микропрограммную реализацию. Чтобы упростить логику декодирования команд использовались команды фиксированной длины и фиксированного формата.
Среди других особенностей RISC-архитектур следует отметить наличие достаточно большого регистрового файла (в типовых RISC-процессорах реализуются 32 или большее число регистров по сравнению с 8 - 16 регистрами в CISC-архитектурах), что позволяет большему объему данных храниться в регистрах на процессорном кристалле большее время и упрощает работу компилятора по распределению регистров под переменные. Для обработки, как правило, используются трехадресные команды, что помимо упрощения дешифрации дает возможность сохранять большее число переменных в регистрах без их последующей перезагрузки.
Ко времени завершения университетских проектов (1983-1984 гг.) обозначился также прорыв в технологии изготовления сверхбольших интегральных схем. Простота архитектуры и ее эффективность, подтвержденная этими проектами, вызвали большой интерес в компьютерной индустрии и с 1986 года началась активная промышленная реализация архитектуры RISC. К настоящему времени эта архитектура прочно занимает лидирующие позиции на мировом компьютерном рынке рабочих станций и серверов.
Развитие архитектуры RISC в значительной степени определялось прогрессом в области создания оптимизирующих компиляторов. Именно современная техника компиляции позволяет эффективно использовать преимущества большего регистрового файла, конвейерной организации и большей скорости выполнения команд. Современные компиляторы используют также преимущества другой оптимизационной техники для повышения производительности, обычно применяемой в процессорах RISC: реализацию задержанных переходов и суперскалярной обработки, позволяющей в один и тот же момент времени выдавать на выполнение несколько команд.
Примером организации мультипроцессорной супер-ЭВМ может служить отечественная Эльбрус-3, в архитектуре которой использован целый ряд интересных решений (рис. 17).
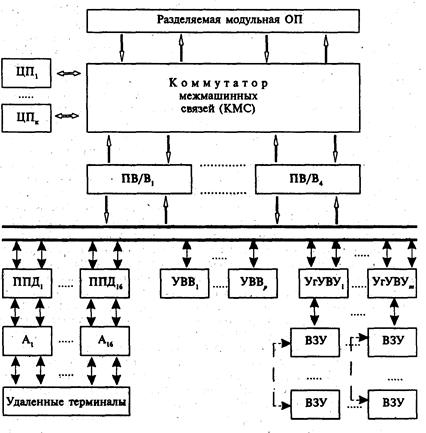
Рис. 17.
Супер-ЭВМ Эльбрус-3 содержит до 16 ЦП, исполнительные устройства (сложения, умножения, деления, логической обработки, десятичных преобразований, обработки строк, вызова и записи операндов, программ и индексаций), которые работают в максимально допустимом режиме распараллеливания, обеспечивая быстродействие ВС при 16 ЦП порядка 5 млрд оп/с на векторных операциях и 1.5 млрд оп/с на скалярных; тисовая производительность отдельного ЦП на базе БИС ИЗООБ составляет порядка 600 млн оп/с и в 16-процессорном варианте — 10 млрд оп/с. Следует отметить, что качество отечественной элементной базы может свести на нет многие оригинальные архитектурные и системотехнические решения супер-ЭВМ, подобно ЭВМ более низких классов. Каждый из процессоров супер-ЭВМ обеспечивает эффективную трансляцию и выполнение программ за счет аппаратной реализации наиболее массовых алгоритмов языков высокого уровня и операционной системы, а также мультипрограммный режим с аппаратной защитой данных пользователя и операционной системы, а высокую производительность порядка 12 млн оп/с обеспечивают современная интегральная технология, высокий уровень параллельной организации и совмещения выполнения команд. ЦП аппаратно реализует стековую сверхоперативную память, поточную обработку команд (одновременно до 14 команд) и безадресную систему команд, базирующуюся на польской инверсной записи. Управляющая информация имеет формат слова (64 бита), числовые данные имеют длину в полслова (32 бита), слово (64 бита) и двойное слово (128 бит). Каждое слово снабжено 6-битным тегом, определяющим его тип. Допускается работа с нечисловой информацией форматов битового, цифрового или байтового наборов. Уже сравнительный временней анализ отдельного ЦП Эльбрус-2 и процессора супер-ЭВМ Сrау-ХМР показал лучшую архитектурно-структурную организацию первого.
Оперативная память Эльбрус-2 имеет модульную- организацию (8 модулей по 18 Мбайт) с общим объемом 144 Мбайт максимальной скоростью обмена с процессорами порядка 180 Мбайт/с. Память поддерживает режим групповой обработки, позволяющий за одно обращение записать/считать 4 слова; коммутатор ОП обеспечивает ей эффективный интерфейс со всеми ЦП системы. Система ввода/вывода состоит из процессоров ввода/вывода (ПВ/В; до 4) и до 1024 периферийных устройств. ПВ/В представляет собой специализированный процессор со своей буферной памятью, арифметико-логическими схемами и обеспечивает интерфейс внешних устройств (ВУ) с основными узлами системы посредством КМС (рис. 17). Работа ВС через линии связи с удаленными терминалами производится через специальные процессоры передачи данных (ППД1—ППД16), подключаемых к ПВ/В, и адаптеры (A1—A16); отдельные устройства ввода/вывода (УВВ) подключаются непосредственно к ПВ/В, а групповые ВЗУ — через УгУВУ. ПВ/В освобождают ЦП от управления операциями ввода/вывода. Общая операционная система (ОС) Эльбрус, являясь первой отечественной универсальной системой для мультипроцессорных ВС, эффективно обеспечивает функционирование супер-ЭВМ и поддерживает ряд важных режимов распараллеливания. При этом проблемы синхронизации процессов решаются на основе аппаратной реализации механизма семафоров. Супер-ЭВМ Эльбрус-3 — одна из немногих ВС этого класса, реализующая виртуальную память, состоящую из отдельных сегментов объектного кода и массивов данных; большие массивы разбиваются на страницы. Сегменты и страницы характеризуются тем, что смежность внутри них по виртуальным адресам совпадает со смежностью в ОП по физическим адресам.
Базовое СПО супер-ЭВМ Эльбрус базируется на машинном языке ЭЛЬ-76 высокого уровня и ОС Эльбрус; включает СУБД; компиляторы с языков программирования: Fortran-IV, Fortran-77, Algol-60, Simula-67, Pascal, PL/I, Lisp, Cobol, Snobol, Refal, Algol-68, КЛУ; ППП машинной графики, включая пакет ГРАФОР, и пакеты для специальных приложений. Дополнительно реализованы ОС UNIX, языки программирования Prolog, ADA. Наконец, для автоматизации разработки ПО и аппаратных средств был создан специальный имитационный комплекс (ИК), позволяющий вести эффективную разработку ПО при его максимальной совместимости с аппаратными средствами ВС.
Имитационный комплекс Эльбрус включает следующие основные компоненты:
— интерпретатор системы команд ЦП и ПВ/В;
— компилятор с языка ЭЛЬ-76 и текстовый редактор;
— средства организации и хранения информации на ВЗУ;
— командный язык работы в диалоговом и пакетном режимах;
— развитый набор сервисных средств.
Из наиболее известных зарубежных мультипроцессорных супер-ЭВМ можно отметить такие серии, как: Cray-3, Cray-4, Cray Y-MP фирмы Cray Research; AFP фирмы CDC; FACOM, VP-200 фирмы Fujitsu; HEP фирмы Denelcor; iPSC фирмы Intel; при этом последнюю можно с полным основанием рассматривать в качестве одной из первых коммерчески доступных персональных супер-ЭВМ с пиковой производительностью в 1 мегафлоп, параллельная архитектура которой на первых порах была реализована на процессорах Intel 80286/287.
Глава 8. Организация связей в ЭВМ.
Вернемся к типовой ЭВМ. Классически она состоит из АЛУ, управления, памяти, периферийных устройств.
В вычислительной системе, состоящей из множества подсистем, необходим механизм для их взаимодействия. Эти подсистемы должны быстро и эффективно обмениваться данными. Например, процессор, с одной стороны, должен быть связан с памятью, с другой стороны, необходима связь процессора с устройствами ввода/вывода. Одним из простейших механизмов, позволяющих организовать взаимодействие различных подсистем, является единственная центральная шина, к которой подсоединяются все подсистемы. Доступ к такой шине разделяется между всеми подсистемами. Подобная организация имеет два основных преимущества: низкая стоимость и универсальность. Поскольку такая шина является единственным местом подсоединения для разных устройств, новые устройства могут быть легко добавлены, и одни и те же периферийные устройства можно даже применять в разных вычислительных системах, использующих однотипную шину. Стоимость такой организации получается достаточно низкой, поскольку для реализации множества путей передачи информации используется единственный набор линий шины, разделяемый множеством устройств.
Главным недостатком организации с единственной шиной является то, что шина создает узкое горло, ограничивая, возможно, максимальную пропускную способность ввода/вывода. Если весь поток ввода/вывода должен проходить через центральную шину, такое ограничение пропускной способности весьма реально. В суперкомпьютерах, где необходимые скорости ввода/вывода очень высоки из-за высокой производительности процессора, одним из главных вопросов разработки является создание системы нескольких шин, способной удовлетворить все запросы.
Одна из причин больших трудностей, возникающих при разработке шин, заключается в том, что максимальная скорость шины главным образом лимитируется физическими факторами: длиной шины и количеством подсоединяемых устройств (и, следовательно, нагрузкой на шину). Эти физические ограничения не позволяют произвольно ускорять шины. Требования быстродействия (малой задержки) системы ввода/вывода и высокой пропускной способности являются противоречивыми. В современных крупных системах используется целый комплекс взаимосвязанных шин, каждая из которых обеспечивает упрощение взаимодействия различных подсистем, высокую пропускную способность, избыточность (для увеличения отказоустойчивости) и эффективность.
Традиционно шины делятся на шины, обеспечивающие организацию связи процессора с памятью, и шины ввода/вывода. Шины ввода/вывода могут иметь большую протяженность, поддерживать подсоединение многих типов устройств, и обычно следуют одному из шинных стандартов. Шины процессор-память, с другой стороны, сравнительно короткие, обычно высокоскоростные и соответствуют организации системы памяти для обеспечения максимальной пропускной способности канала память-процессор. На этапе разработки системы, для шины процессор-память заранее известны все типы и параметры устройств, которые должны соединяться между собой, в то время как разработчик шины ввода/вывода должен иметь дело с устройствами, различающимися по задержке и пропускной способности.
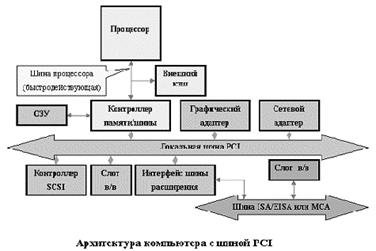
Как уже было отмечено, с целью снижения стоимости некоторые компьютеры имеют единственную шину для памяти и устройств ввода/вывода. Такая шина часто называется системной. Персональные компьютеры раньше строились на основе одной системной шины в стандартах ISA. Необходимость сохранения баланса производительности по мере роста быстродействия микропроцессоров привела к двухуровневой организации шин в персональных компьютерах на основе локальной шины. Локальной шиной называется шина, электрически выходящая непосредственно на контакты микропроцессора. Она обычно объединяет процессор, память, схемы буферизации для системной шины и ее контроллер, а также некоторые вспомогательные схемы. Типичными примерами локальных шин является PCI.
Главное устройство шины - это устройство, которое может инициировать транзакции чтения или записи. ЦП, например, всегда является главным устройством шины. Шина имеет несколько главных устройств, если имеется несколько ЦП или когда устройства ввода/вывода могут инициировать транзакции на шине. Если имеется несколько таких устройств, то требуется схема арбитража, чтобы решить, кто следующий захватит шину.
bus masters и bus slaves. Bus masters - это устройства, способные управлять работой шины, т.е инициировать запись/чтение и т.д. Bus slaves - соответственно, устройства, которые могут только отвечать на запросы.
Используются два типа шин, отличающиеся способом коммутации: шины с коммутацией цепей (circuit-switched bus) и шины с коммутацией пакетов (packet-switched bus), получившие свои названия по аналогии со способами коммутации в сетях передачи данных. Шина с коммутацией пакетов при наличии нескольких главных устройств шины обеспечивает значительно большую пропускную способность по сравнению с шиной с коммутацией цепей за счет разделения транзакции на две логические части: запроса шины и ответа. Такая методика получила название "расщепления" транзакций (split transaction). (В некоторых системах такая возможность называется шиной соединения/разъединения (connect/disconnect) или конвейерной шиной (pipelined bus). Транзакция чтения разбивается на транзакцию запроса чтения, которая содержит адрес, и транзакцию ответа памяти, которая содержит данные. Каждая транзакция теперь должна быть помечена (тегирована) соответствующим образом, чтобы ЦП и память могли сообщить что есть что.
Шина с коммутацией цепей не делает расщепления транзакций, любая транзакция на ней есть неделимая операция. Главное устройство запрашивает шину, после арбитража помещает на нее адрес и блокирует шину до окончания обслуживания запроса. Большая часть этого времени обслуживания при этом тратится не на выполнение операций на шине (например, на задержку выборки из памяти). Таким образом, в шинах с коммутацией цепей это время просто теряется. Расщепленные транзакции делают шину доступной для других главных устройств пока память читает слово по запрошенному адресу. Это, правда, также означает, что ЦП должен бороться за шину для посылки данных, а память должна бороться за шину, чтобы вернуть данные. Таким образом, шина с расщеплением транзакций имеет более высокую пропускную способность, но обычно она имеет и большую задержку, чем шина, которая захватывается на все время выполнения транзакции. Транзакция называется расщепленной, поскольку произвольное количество других пакетов или транзакций могут использовать шину между запросом и ответом.
Последний вопрос связан с выбором типа синхронизации и определяет является ли шина синхронной или асинхронной. Если шина синхронная, то она включает сигналы синхронизации, которые передаются по линиям управления шины, и фиксированный протокол, определяющий расположение сигналов адреса и данных относительно сигналов синхронизации. Поскольку практически никакой дополнительной логики не требуется для того, чтобы решить, что делать в следующий момент времени, эти шины могут быть и быстрыми, и дешевыми. Однако они имеют два главных недостатка. Все на шине должно происходить с одной и той же частотой синхронизации, поэтому из-за проблемы перекоса синхросигналов, синхронные шины не могут быть длинными. Обычно шины процессор-память синхронные.
Асинхронная шина, с другой стороны, не тактируется. Вместо этого обычно используется старт-стопный режим передачи и протокол "рукопожатия" (handshaking) между источником и приемником данных на шине. Эта схема позволяет гораздо проще приспособить широкое разнообразие устройств и удлинить шину без беспокойства о перекосе сигналов синхронизации и о системе синхронизации. Если может использоваться синхронная шина, то она обычно быстрее, чем асинхронная, из-за отсутствия накладных расходов на синхронизацию шины для каждой транзакции. Выбор типа шины (синхронной или асинхронной) определяет не только пропускную способность, но также непосредственно влияет на емкость системы ввода/вывода в терминах физического расстояния и количества устройств, которые могут быть подсоединены к шине. Асинхронные шины по мере изменения технологии лучше масштабируются. Шины ввода/вывода обычно асинхронные.
Одной из наиболее популярных шин ввода-вывода в настоящее время является шина SCSI. Под термином SCSI - Small Computer System Interface (Интерфейс малых вычислительных систем) обычно понимается набор стандартов, разработанных Национальным институтом стандартов США (ANSI) и определяющих механизм реализации магистрали передачи данных между системной шиной компьютера и периферийными устройствами.
Глава 9. Основные классы современных параллельных компьютеров.
9.1. Симметричные мультипроцессорные системы (SMP)
(Symmetric Multi-Processing)
Симметричный многопроцессорный (SMP) узел содержит два или более одинаковых процессора, используемых равноправно. Все процессоры имеют одинаковый доступ к вычислительным ресурсам узла. Поскольку процессоры одновременно работают с данными, хранящимися в единой памяти узла, в SMP-архитектурах обязательно должен быть механизм, поддержки когерентности данных. Когерентность данных означает, что в любой момент времени для каждого элемента данных во всей памяти узла существует только одно его значение несмотря на то, что одновременно могут существовать несколько копий элемента данных, расположенных в разных видах памяти и обрабатываемых разными процессорами. Механизм когерентности должен следить за тем, чтобы операции с одним и тем же элементом данных выполнялись на разных процессорах последовательно, удаляя, в частности, устаревшие копии. В современных SMP-архитектурах когерентность реализуется аппаратными средствами.
Механизм когерентности является критичным для эффективной параллельной работы узла SMP и должен иметь малое время задержки. До сегодняшнего дня самые крупные SMP-системы содержали максимум 32 процессора на узел, что объяснялось требованием малых задержек когерентных связей, приводящим к архитектуре с одной объединительной платой, а это физически ограничивает возможное число подсоединенных процессоров и плат памяти. Поэтому для дальнейшего увеличения числа процессоров в узле приходится вместо аппаратно реализованной техники когерентности применять более медленную программную реализацию, что очень существенно сказывается на программируемости систем и их производительности.
SMP-узлы очень удобны для разработчиков приложений: операционная система почти автоматически масштабирует приложения, давая им возможность использовать наращиваемые ресурсы. Само приложение не должно меняться при добавлении процессоров и не обязано следить за тем, на каких ЦПУ оно работает. Временная задержка доступа от любого ЦПУ до всех частей памяти и системы ввода-вывода одна и та же. Разработчик оперирует с однородным адресным пространством. Все это приводит к тому, что SMP-архитектуры разных производителей выглядят в основном одинаково: упрощается переносимость программного обеспечения между SMP-системами. Переносимость программ - одно из основных достоинств SMP-платформ.
Типичные SMP-архитектуры в качестве аппаратной реализации механизма поддержки когерентности используют шину слежения (snoopy bus). Каждый процессор имеет свой собственный локальный кэш, где он хранит копию небольшой части основной памяти, доступ к которой наиболее вероятен. Для того чтобы все кэши оставались когерентными, каждый процессор "подглядывает" за шиной, осуществляя поиск тех операций считывания и записи между другими процессорами и основной памятью, которые влияют на содержимое их собственных кэшей. Если процессор "В" запрашивает ту часть памяти, которая обрабатывается процессором "А", то процессор "А" перехватывает этот запрос и помещает свои значения области памяти на шину, где "В" их считывает. Когда процессор "А" записывает измененное значение обратно из своего кэша в память, то все другие процессоры видят, как эта запись проходит по шине и удаляют устаревшие значения из своих кэшей.
SMP система состоит из нескольких однородных процессоров и массива общей памяти. Один из часто используемых в SMP архитектурах подходов для формирования масштабируемой, общедоступной системы памяти, состоит в однородной организации доступа к памяти посредством организации масштабируемого канала память-процессоры.
Каждая операция доступа к памяти интерпретируется как транзакция по шине процессоры - память. Когерентность кэшей поддерживается аппаратными средствами. Недостатком данной архитектуры является необходимость организации канала процессоры - память с очень высокой пропускной способностью.
| Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка. |
| Модель программирования Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания. |
9.2. Массивно-параллельные системы (МРР)
(Massively Parallel Processing)
Узлы в архитектуре MPP обычно состоят из одного ЦПУ, небольшой памяти и нескольких устройств ввода-вывода. В каждом узле работает своя копия OC, а узлы объединяются между собой специализированным соединением. Взаимосвязи между узлами (и между копиями ОС, принадлежащими каждому узлу) не требуют аппаратно поддерживаемой когерентности, так как каждый узел имеет собственную ОС и, следовательно, свое уникальное адресное пространство физической памяти. Когерентность реализуется программными средствами, с использованием техники передачи сообщений.
Задержки, которые присущи программной поддержке когерентности на основе сообщений, обычно в сотни и тысячи раз больше, чем те, которые получаются в системах с аппаратными средствами. С другой стороны, их реализация значительно менее дорогая. В некотором смысле в МРР-узлах задержкой приходится жертвовать, чтобы подсоединить большее число процессоров - сотни и даже тысячи узлов.
Известно, что производительность МРР-систем весьма чувствительна к задержкам, определяемым программной реализацией протоколов и аппаратной реализацией среды передачи сообщений (будь то коммутатор, или сеть). Вообще говоря, настройка производительности МРР-систем включает распределение данных для того, чтобы минимизировать трафик между узлами.
МРР-архитектуры привлекательны в первую очередь для разработчиков аппаратных средств, так как в этом случае возникает меньше проблем и ниже стоимость аппаратуры. Из-за того, что нет аппаратной поддержки ни для разделенной памяти, ни для когерентности кэшей, подсоединить большое число процессоров очень просто. Такие системы обеспечивают высокий уровень производительности для приложений с большой интенсивностью вычислений, со статистически разделяемыми данными и с минимальным обменом данными между узлами. Для большинства коммерческих приложений МРР-системы подходят плохо из-за того, что структура базы данных меняется со временем и слишком велики затраты на перераспределение данных.
Ключевым различием между одиночным SMP-узлом и МРР-системой является то, что внутри SMP-узла когерентность данных поддерживается исключительно аппаратными средствами. Это действительно быстро, но и дорого. В МРР-системе с таким же числом процессоров когерентность между узлами реализуется программными средствами. Поэтому происходит это более медленно, однако и цена значительно ниже.
MPP система состоит из нескольких однородных вычислительных узлов, включающих один или несколько процессоров, локальную для каждого узла память, коммуникационный процессор или сетевой адаптер. Узлы объединяются через высокоскоростную сеть или коммутатор.
| Существуют два основных варианта: ü Полноценная ОС работает только на управляющей машине (front-end), на каждом узле работает сильно урезанный вариант ОС, обеспечивающие только работу расположенной в нем ветви параллельного приложения. Пример: Cray T3E. ü На каждом узле работает полноценная UNIX-подобная ОС (вариант, близкий к кластерному подходу). Пример: IBM RS/6000 SP + ОС AIX, устанавливаемая отдельно на каждом узле. |
| Модель программированияПрограммирование в рамках модели передачи сообщений |
9.3. Системы с неоднородным доступом к памяти (NUMA)
(non uniform memory access)
Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной.
В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре cc-NUMA (cache-coherent NUMA)
Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000)
|
|
|
|
|
Дата добавления: 2015-04-25; Просмотров: 2392; Нарушение авторских прав?; Мы поможем в написании вашей работы!