КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Правила построения дерева вероятностей
|
|
|
|
Для построения дерева вероятностей прежде всего необходимо нарисовать само дерево, затем записать на рисунке всю известную для данной задачи информацию и, наконец, воспользоваться основными правилами, чтобы вычислить недостающие числа и закончить дерево.
1. Вероятности указываются в каждой из конечных точек и обводятся кружочками. На каждом уровне дерева сумма этих вероятностей должна равняться 1 (или 100%). Так, например, на рис. 6.5.1 сумма вероятностей на первом уровне составляет 0,20 + 0,80 = 1,00 и на втором уровне — 0,03 + 0,17 + 0,56 + 0,24 = 1,00. Это правило помогает заполнить один пустой кружок в столбце, если значения всех остальных вероятностей этого уровня известны.

Рис. 6.5.1
2. Условные вероятности указываются рядом с каждой из ветвей (кроме,
возможно, ветвей первого уровня). Для каждой из групп ветвей, выходящих из одной точки, сумма этих вероятностей также равна 1 (или 100%).
Например, на рис. 6.5.1 для первой группы ветвей получаем 0,15 + 0,85 =
1,00 и для второй группы — 0,70 + 0,30 = 1,00. Это правило позволяет
вычислить одно неизвестное значение условной вероятности в группе ветвей, исходящих из одной точки.
3. Обведенная кругом в начале ветви вероятность, умноженная на условную
вероятность рядом с этой ветвью, дает вероятность, записанную в круге в
конце ветви. Например, на рис. 6.5.1 для верхней ведущей вправо ветви
имеем 0,20 х 0,15 = 0,03, для следующей ветви — 0,20 х 0,85 = 0,17; аналогичные соотношения выполняются и для других двух ветвей. Это правило можно использовать для вычисления одного неизвестного значения
вероятности из трех, соответствующих некоторой ветви.
4. Записанное в круге значение вероятности равно сумме обведенных кружками вероятностей на концах всех ветвей, выходящих из этого круга
вправо. Так, например, для рис. 6.5.1 из круга со значением 0,20 выходят
две ветви, на концах которых находятся обведенные кружками вероятности, сумма которых равна этому значению: 0,03 + 0,17 = 0,20. Это правило позволяет найти одно неизвестное значение вероятности в группе,
включающей эту вероятность и все вероятности на концах ветвей дерева,
выходящих из соответствующего круга.
|
|
|
Используя эти правила можно, зная все, кроме одного значения вероятности для некоторой ветви или на некотором уровне, находить это неизвестное значение.
37. Какая выборка называется репрезентативной? Каким образом можно извлечь репрезентативную выборку?
Репрезентативность - это способность выборки представлять изучаемую совокупность. Чем точнее состав выборки представляет совокупность по изучаемым вопросам, тем выше ее репрезентативность.
Репрезентативная выборка (representative sample) - одно из ключевых понятий анализа данных. Репрезентативная выборка - это выборка из генеральной совокупности с распределением F (x), представляющая основные особенности генеральной совокупности. Например, если в городе проживает 100 000 человек, половина из которых мужчины и половина женщины, то выборка 1000 человек из которых 10 мужчин и 990 женщин, конечно, не будет репрезентативной. Построенный на ее основе опрос общественного мнения, конечно, будет содержать смещение оценок и приводит к фальсификации результатов.
Необходимым условием построения репрезентативной выборки является равная вероятность включения в нее каждого элемента генеральной совокупности.
Выборочная (эмпирическая) функция распределения 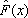 дает при большом объеме выборки достаточно хорошее представление о функции распределения F (x) исходной генеральной совокупности.
дает при большом объеме выборки достаточно хорошее представление о функции распределения F (x) исходной генеральной совокупности.
Ведущий принцип, лежащий в основе такой процедуры, - это принцип рандомизации, случайности. Выборка называется случайной (иногда мы будем говорить простая случайная или чистая случайная выборка), если выполняется два условия. Во-первых, выборка должна быть построена таким образом, чтобы любой человек или объект в пределах совокупности имел равные возможности быть отобранным для анализа. Во-вторых, выборка должна быть сформирована так, чтобы любое сочетание из n объектов (где n - просто количество объектов, или случаев, в выборке) имело равные возможности быть отобранным для анализа.
|
|
|
При исследовании совокупностей, которые слишком велики, для того чтобы можно было осуществить настоящую лотерею, часто используются простые случайные выборки. Выписать имена нескольких сотен тысяч объектов, сложить их в барабан и выбрать несколько тысяч - это все же нелегкая работа. В таких случаях используется другой, однако столь же надежный способ. Каждому объекту в совокупности присваивается номер. Последовательность чисел в таких таблицах обычно задается компьютерной программой, называемой генератором случайных чисел, который, в сущности, помещает в барабан большое количество чисел, случайным образом вытаскивает их и выпечатывает в порядке получения. Иными словами, имеет место все тот же процесс, характерный для лотереи, однако компьютер, используя не имена, а числа, осуществляет универсальный выбор. Этим выбором можно пользоваться, просто присвоив каждому из наших объектов номер.
Таблица случайных чисел типа той, может использоваться несколькими разными способами, и в каждом случае необходимо принять три Решения. Во-первых, следует решить, сколько разрядов Мы будем использовать, во-вторых, необходимо разработать решающее правило для их использования; в-третьих нужно выбрать исходную точку и способ прохождения по таблице.
Как только это сделано, мы должны разработать правило, которое бы связывало числа в таблице с номерами наших объектов. Здесь существуют две возможности. Самый простой способ (хотя и не обязательно самый правильный) - использовать лишь те числа, которые попадают в число номеров, приписанных нашим объектам. Так, если мы имеем совокупность, состоящую из 250 объектов (и, таким образом, используем трехзначные числа), и решаем начать с левого верхнего угла таблицы и двигаться вниз по столбцам, мы включим в нашу выборку объекты с номерами 100, 084 и 128 и пропустим числа 375 и 990, не соответствующие нашим объектам. Этот процесс будет продолжаться до тех пор, пока не будет определено число объектов, нужных для нашей выборки.
|
|
|
Более трудоемкая, однако методически более правильная процедура основывается на положении, что для сохранения случайности, характерной для таблицы, должно быть использовано каждое число данной размерности (например, каждое трехзначное число). Следуя данной логике и вновь имея дело с совокупностью из 250 объектов, мы должны разбить область трехзначных чисел от 000 до 999 на 250 одинаковых промежутков. Поскольку таких чисел 1000, мы делим 1000 на 250 и находим, что каждая из частей содержит четыре числа. Таким образом, числа таблицы от 000 до 003 будут соответствовать объекту от 004 до 007 - объекту 2 и т.д. Теперь, чтобы установить, какой номер объекта соответствует числу таблицы, следует разделить трехзначное число из таблицы и округлить до ближайшего целого числа.
И наконец, мы должны выбрать в таблице исходную точку и способ прохождения. Исходной точкой может быть верхний левый угол (как в предыдущем примере), нижний правый угол, левый край второй строки или любое другое место. Этот выбор абсолютно произволен. Однако, работая с таблицей, мы должны действовать систематически. Мы могли бы взять три первых знака из каждой пятизначной последовательности, три средних знака, три последних знака или даже первый, второй и четвертый знаки. (Из первой пятизначной последовательности с помощью этих различных процедур получаются, соответственно, числа 100, 009, 097 и 109.) Мы могли бы применить эти процедуры в направлении справа налево, получив 790, 900, 001 и 791. Мы могли бы идти вдоль рядов, рассматривая поочередно каждую следующую цифру и игнорируя разбиение на пятерки (для первого ряда будут получены числа 100, 973, 253, 376 и 520). Мы могли бы иметь дело лишь с каждой третьей группой цифр (например, с 10097, 99019, 04805, 99970). Существует множество самых разнообразных возможностей, и каждая следующая ничуть не хуже предыдущей. Однако как только мы приняли решение о том, или ином способе работы, мы должны систематически следовать ему, чтобы в максимальной степени соблюдать случайность элементов в таблице.
|
|
|
38. Какой интервал мы называем доверительным?
Доверительный интервал - это допустимое отклонение наблюдаемых значений от истинных. Размер этого допущения определяется исследователем с учетом требований к точности информации. Если увеличивается допустимая ошибка, размер выборки уменьшается, даже если уровень доверительной вероятности останется равным 95%.
Доверительный интервал показывает, в каком диапазоне расположатся результаты выборочных наблюдений (опросов). Если мы проведем 100 одинаковых опросов в одинаковых выборках из единой генеральной совокупности (например, 100 выборок по 1000 человек в каждой в городе с населением 5 миллионов человек), то при 95%-й доверительной вероятности, 95 из 100 результатов попадут в пределы доверительного интервала (например, от 28% до 32% при истинном значении 30%).
Например, истинное количество курящих жителей города составляет 30%. Если мы 100 раз подряд выберем по 1000 человек и в этих выборках зададим вопрос "курите ли Вы?", в 95 из этих 100 выборок при 2%-м доверительном интервале значение составит от 28% до 32%.
39 Что называется уровнем доверительности (confidence level)?
Доверительный уровень отражает количество данных, необходимых оценщику для того, чтобы утверждать, что обследуемая программа имеет должный эффект. В общественных науках традиционно используется 95% доверительный уровень. Однако для большинства общественных программ уровень в 95% является излишним. Доверительный уровень в интервале 80-90% является достаточным для адекватной оценки программы. Таким образом, можно уменьшить размер репрезентативной группы, тем самым уменьшив и затраты на проведение оценки.
В процессе статистической оценки проверяется нулевая гипотеза, которая состоит в том, что программа не имела должного эффекта. Если полученные результаты значительно отличаются от изначальных предположений о правильности нулевой гипотезы, то последняя отклоняется.
40. Какой из двух доверительных интервалов больше: двусторонний 99% или двусторонний 95%? Объясните.
Двусторонний доверительный интервал 99% больше, чем 95%, так как в него попадает больше значений. Док-во:
С помощью z-значений можно точнее оценить доверительный интервал и определить общую форму доверительного интервала. Точная формулировка доверительного интервала для выборочного среднего имеет следующий вид:
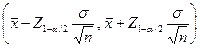 .
.
Таким образом, для случайной выборки 25 наблюдений, удовлетворяющих нормальному распределению, с 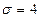 доверительный интервал выборочного среднего имеет следующий вид:
доверительный интервал выборочного среднего имеет следующий вид:
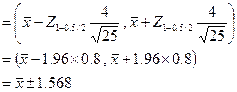
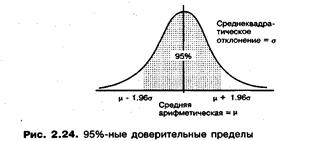 Таким образом, на 95% можно быть уверенным, что значение
Таким образом, на 95% можно быть уверенным, что значение 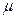 лежит в пределах ±1,568 единицы от выборочного среднего. С помощью такого же метода можно определить, что 99%-ный доверительный интервал лежит в пределах ±2,0608 единицы от выборочного среднего
лежит в пределах ±1,568 единицы от выборочного среднего. С помощью такого же метода можно определить, что 99%-ный доверительный интервал лежит в пределах ±2,0608 единицы от выборочного среднего
значение 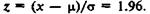 Таким образом, имеем
Таким образом, имеем 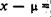
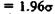 и отсюда
и отсюда 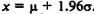 , Аналогично получаем нижний предел, который равен
, Аналогично получаем нижний предел, который равен 
|
|
|
|
|
Дата добавления: 2015-04-23; Просмотров: 8312; Нарушение авторских прав?; Мы поможем в написании вашей работы!