КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лексический анализ
|
|
|
|
Рассмотрим методы и средства, которые обычно используются при построении лексических анализаторов. В основе таких анализаторов лежат регулярные грамматики, поэтому рассмотрим грамматики этого класса более подробно.
Соглашение: в дальнейшем, если особо не оговорено, под регулярной грамматикой будем понимать леволинейную грамматику.
Напомним, что грамматика G = (VT, VN, P, S) называется леволинейной, если каждое правило из Р имеет вид A ® Bt либо A ® t, где A Î VN, B Î VN, t Î VT.
Соглашение: предположим, что анализируемая цепочка заканчивается специальным символом ^ - признаком конца цепочки.
Для грамматик этого типа существует алгоритм определения того, принадлежит ли анализируемая цепочка языку, порождаемому этой грамматикой (алгоритм разбора):
(1) первый символ исходной цепочки a1a2...an^ заменяем нетерминалом A, для которого в грамматике есть правило вывода A ® a1 (другими словами, производим "свертку" терминала a1 к нетерминалу A)
(2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: полученный на предыдущем шаге нетерминал A и расположенный непосредственно справа от него очередной терминал ai исходной цепочки заменяем нетерминалом B, для которого в грамматике есть правило вывода B ® Aai (i = 2, 3,.., n);
Это эквивалентно построению дерева разбора методом "снизу-вверх": на каждом шаге алгоритма строим один из уровней в дереве разбора, "поднимаясь" от листьев к корню.
При работе этого алгоритма возможны следующие ситуации:
(1) прочитана вся цепочка; на каждом шаге находилась единственная нужная "свертка"; на последнем шаге свертка произошла к символу S. Это означает, что исходная цепочка a1a2...an^ Î L(G).
|
|
|
(2) прочитана вся цепочка; на каждом шаге находилась единственная нужная "свертка"; на последнем шаге свертка произошла к символу, отличному от S. Это означает, что исходная цепочка a1a2...an^ Ï L(G).
(3) на некотором шаге не нашлось нужной свертки, т.е. для полученного на предыдущем шаге нетерминала A и расположенного непосредственно справа от него очередного терминала ai исходной цепочки не нашлось нетерминала B, для которого в грамматике было бы правило вывода B ® Aai. Это означает, что исходная цепочка a1a2...an^ Ï L(G).
(4) на некотором шаге работы алгоритма оказалось, что есть более одной подходящей свертки, т.е. в грамматике разные нетерминалы имеют правила вывода с одинаковыми правыми частями, и поэтому непонятно, к какому из них производить свертку. Это говорит о недетерминированности разбора. Анализ этой ситуации будет дан ниже.
Допустим, что разбор на каждом шаге детерминированный.
Для того, чтобы быстрее находить правило с подходящей правой частью, зафиксируем все возможные свертки (это определяется только грамматикой и не зависит от вида анализируемой цепочки).
Это можно сделать в виде таблицы, строки которой помечены нетерминальными символами грамматики, столбцы - терминальными. Значение каждого элемента таблицы - это нетерминальный символ, к которому можно свернуть пару "нетерминал-терминал", которыми помечены соответствующие строка и столбец.
Например, для грамматики G = ({a, b, ^}, {S, A, B, C}, P, S), такая таблица будет выглядеть следующим образом:
| P: S ® C^ С ® Ab | Ba A ® a | Ca B ® b | Cb |
| a | b | ^ | |
| C | A | B | S |
| A | - | C | - |
| B | C | - | - |
| S | - | - | - |
Знак "-" ставится в том случае, если для пары "терминал-нетерминал" свертки нет.
Но чаще информацию о возможных свертках представляют в виде диаграммы состояний (ДС) - неупорядоченного ориентированного помеченного графа, который строится следующим образом:
|
|
|
(1) строят вершины графа, помеченные нетерминалами грамматики (для каждого нетерминала - одну вершину), и еще одну вершину, помеченную символом, отличным от нетерминальных (например, H). Эти вершины будем называть состояниями. H - начальное состояние.
(2) соединяем эти состояния дугами по следующим правилам:
a) для каждого правила грамматики вида W ® t соединяем дугой состояния H и W (от H к W) и помечаем дугу символом t;
б) для каждого правила W ® Vt соединяем дугой состояния V и W (от V к W) и помечаем дугу символом t;
Диаграмма состояний для грамматики G (см. пример выше):
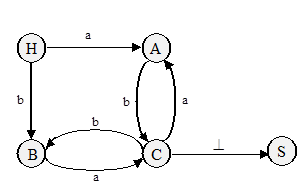
Алгоритм разбора по диаграмме состояний:
(1) объявляем текущим состояние H;
(2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: считываем очередной символ исходной цепочки и переходим из текущего состояния в другое состояние по дуге, помеченной этим символом. Состояние, в которое мы при этом попадаем, становится текущим.
При работе этого алгоритма возможны следующие ситуации (аналогичные ситуациям, которые возникают при разборе непосредственно по регулярной грамматике):
(1) прочитана вся цепочка; на каждом шаге находилась единственная дуга, помеченная очередным символом анализируемой цепочки; в результате последнего перехода оказались в состоянии S. Это означает, что исходная цепочка принадлежит L(G).
(2) прочитана вся цепочка; на каждом шаге находилась единственная "нужная" дуга; в результате последнего шага оказались в состоянии, отличном от S. Это означает, что исходная цепочка не принадлежит L(G).
(3) на некотором шаге не нашлось дуги, выходящей из текущего состояния и помеченной очередным анализируемым символом. Это означает, что исходная цепочка не принадлежит L(G).
(4) на некотором шаге работы алгоритма оказалось, что есть несколько дуг, выходящих из текущего состояния, помеченных очередным анализируемым символом, но ведущих в разные состояния. Это говорит о недетерминированности разбора. Анализ этой ситуации будет приведен ниже.
Диаграмма состояний определяет конечный автомат, построенный по регулярной грамматике, который допускает множество цепочек, составляющих язык, определяемый этой грамматикой. Состояния и дуги ДС - это графическое изображение функции переходов конечного автомата из состояния в состояние при условии, что очередной анализируемый символ совпадает с символом-меткой дуги. Среди всех состояний выделяется начальное (считается, что в начальный момент своей работы автомат находится в этом состоянии) и конечное (если автомат завершает работу переходом в это состояние, то анализируемая цепочка им допускается).
|
|
|
Определение: конечный автомат (КА) - это пятерка (K, VT, F, H, S), где
K - конечное множество состояний;
VT - конечное множество допустимых входных символов;
F - отображение множества K ´ VT ® K, определяющее поведение автомата; отображение F часто называют функцией переходов;
H Î K - начальное состояние;
S Î K - заключительное состояние (либо конечное множество заключительных состояний).
F(A, t) = B означает, что из состояния A по входному символу t происходит переход в состояние B.
Определение: конечный автомат допускает цепочку a1a2...an, если F(H,a1) = A1; F(A1,a2) = A2;...; F(An-2,an-1) = An-1; F(An-1,an) = S, где ai Î VT, Aj Î K, j = 1, 2,...,n-1; i = 1, 2,...,n; H - начальное состояние, S - одно из заключительных состояний.
Определение: множество цепочек, допускаемых конечным автоматом, составляет определяемый им язык.
Для более удобной работы с диаграммами состояний введем несколько соглашений:
a) если из одного состояния в другое выходит несколько дуг, помеченных разными символами, то будем изображать одну дугу, помеченную всеми этими символами;
b) непомеченная дуга будет соответствовать переходу при любом символе, кроме тех, которыми помечены другие дуги, выходящие из этого состояния.
c) введем состояние ошибки (ER); переход в это состояние будет означать, что исходная цепочка языку не принадлежит.
По диаграмме состояний легко написать анализатор для регулярной грамматики.
Например, для грамматики G = ({a,b, ^}, {S,A,B,C}, P, S), где
P: S ® C^
С ® Ab | Ba
A ® a | Ca
B ® b | Cb
анализатор будет таким:
|
|
|
#include <stdio.h>
int scan_G(){
enum state {H, A, B, C, S, ER}; /* множество состояний */
state CS; /* CS - текущее состояние */
FILE *fp; /* указатель на файл, в котором находится анализируемая цепочка */
int c;
CS=H;
fp = fopen ("data","r");
c = fgetc (fp);
do {switch (CS) {
case H: if (c == 'a') {c = fgetc(fp); CS = A;}
else if (c == 'b') {c = fgetc(fp); CS = B;}
else CS = ER;
break;
case A: if (c == 'b') {c = fgetc(fp); CS = C;}
else CS = ER;
break;
case B: if (c == 'a') {c = fgetc(fp); CS = C;}
else CS = ER;
break;
case C: if (c =='a') {c = fgetc(fp); CS = A;}
else if (c == 'b') {c = fgetc(fp); CS = B;}
else if (c == '^') CS = S;
else CS = ER;
break;
}
} while (CS!= S && CS!= ER);
if (CS == ER) return -1; else return 0;
}
|
|
|
|
|
Дата добавления: 2015-06-27; Просмотров: 503; Нарушение авторских прав?; Мы поможем в написании вашей работы!