КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Первый этап: разработка ДС
|
|
|
|
Лексический анализатор для М-языка
Вход лексического анализатора - символы исходной программы на М-языке; результат работы - исходная программа в виде последовательности лексем (их внутреннего представления).
Лексический анализатор для модельного языка будем писать в два этапа: сначала построим диаграмму состояний с действиями для распознавания и формирования внутреннего представления лексем, а затем по ней напишем программу анализатора.
Представление лексем: все лексемы М-языка разделим на несколько классов; классы перенумеруем:
à служебные слова - 1,
à ограничители - 2,
à константы (целые числа) - 3,
à идентификаторы - 4.
Внутреннее представление лексем - это пара (номер_класса, номер_в_классе). Номер_в_классе - это номер строки в таблице лексем соответствующего класса.
Соглашение об используемых переменных, типах и функциях:
1) пусть есть переменные:
buf - буфер для накопления символов лексемы;
c - очередной входной символ;
d - переменная для формирования числового значения константы;
TW - таблица служебных слов М-языка;
TD - таблица ограничителей М-языка;
TID - таблица идентификаторов анализируемой программы;
TNUM - таблица чисел-констант, используемых в программе.
Таблицы TW и TD заполнены заранее, т.к. их содержимое не зависит от исходной программы; TID и TNUM будут формироваться в процессе анализа; для простоты будем считать, что все таблицы одного типа; пусть tabl - имя типа этих таблиц, ptabl - указатель на tabl.
2) пусть есть функции:
void clear (void); - очистка буфера buf;
void add (void); - добавление символа с в конец буфера buf;
int look (ptabl Т); - поиск в таблице Т лексемы из буфера buf; результат: номер строки таблицы с информацией о лексеме либо 0, если такой лексемы в таблице Т нет;
|
|
|
int putl (ptabl Т); - запись в таблицу Т лексемы из буфера buf, если ее там не было; результат: номер строки таблицы с информацией о лексеме;
int putnum (); - запись в TNUM константы из d, если ее там не было; результат: номер строки таблицы TNUM с информацией о константе-лексеме;
void makelex (int k, int i); - формирование и вывод внутреннего представления лексемы; k - номер класса, i - номер в классе;
void gc (void) - функция, читающая из входного потока очередной символ исходной программы и заносящая его в переменную с.
Тогда диаграмма состояний для лексического анализатора:
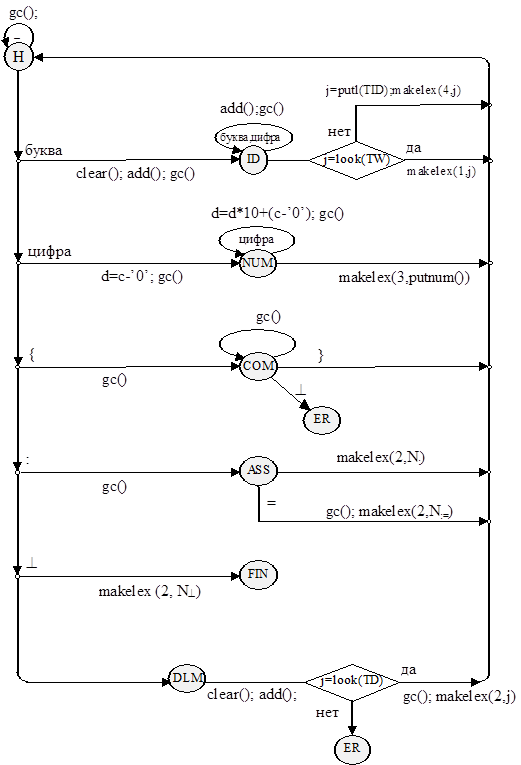
Замечание: символом Nx в диаграмме (и в тексте программы) обозначен номер лексемы x в ее классе.
|
|
|
|
|
Дата добавления: 2015-06-27; Просмотров: 501; Нарушение авторских прав?; Мы поможем в написании вашей работы!