КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Индексирование
|
|
|
|
Нормализация
Реляционные отношения между таблицами. Целостность данных
Некоторые правила построения баз данных
Один из важных моментов при работе с БД является разработка ее структуры. И чем больше данных в БД, тем серьезнее надо отнестись к проработке ее структуры.
Существуют стандартные приемы и методы, следование которым позволяет получить хороший результат. Наиболее известными, пожалуй, являются нормализация, индексирование и целостность. Рассмотрим эти методы.
Объектно-связный подход, положенный в основу многих реляционных СУБД, осуществляет поддержку семантической целостности данных при их обновлении на трех уровнях: уровне внешних ключей, внутреннем (первичных ключей) и полей.
Требования целостности на уровне внешних ключей представляет собой основную аксиому целостности, т.е. внешние ключи таблиц БД, отображающие связи, должны ссылаться на актуально существующие в БД объекты (первичные ключи связанных таблиц). Другими словами, между таблицами БД никогда не должно образовываться "висячих ссылок". Таким образом, при вставке новой записи в связную таблицу проводится контроль на существование связываемых объектов в соответствующих объектных таблицах и, наоборот, условием удаления строки из объектной таблицы является отсутствие связей у удаляемого объекта.
Требование внутренней целостности есть требование уникальности ключа. Проверка осуществляется обычно при вставке новой записи.
Наконец, поддержка целостности полей осуществляется при обновляющих операциях (вставка/модификация) записи путем контроля значения каждого атрибута (значения поля) на принадлежность соответствующему типу данных или допустимому диапазону.
|
|
|
Остановимся подробнее на целостности на уровне внешних ключей.
Еще раз повторим, что связь между таблицами осуществляется с помощью внешнего ключа одной таблицы, который содержит значение первичного ключа другой таблицы. При этом первая таблица называется подчиненной (дочерней), а вторая - главной (родительской). При этом между таблицами бывают следующие отношения " один-к-одному ", " один-ко-многим ", " многие-к-одному " и " многие-ко-многим ".
Отношение «один-к-одному»
Отношение " один-к-одному " имеет место, когда одной записи в родительской таблице соответствует одна запись в дочерней таблице. Данное отношение встречается не часто, его используют, если не хотят, чтобы таблица БД «распухала» от ненужной информации. Такая связь приводит к тому, что для чтения связной информации в нескольких таблицах приходится производить несколько операций чтения, что замедляет процесс получения информации. БД, в состав которых входит связь " один-к-одному ", не может считаться полностью нормализованной (о нормализации см. ниже).
Таблица «Сотрудники» Таблица «Информация о
сотрудниках»
| № | ФИО | Должность | Отдел | № | Год рожд. | Кол-во детей | … | |
| Иванов В.В. | инженер | … | ||||||
 2 2
| Петров П.П. | бухгалтер | … | |||||
 3 3
| Васин И.И. | прораб | … | |||||
| … | … | … | … | … | … | … |
Отношение «один-ко-многим»
Связь " один-ко-многим " является самой распространенной для реляционных баз данных. Она позволяет моделировать иерархические структуры данных. Различают две разновидности этой связи: в первом случае всякой записи в родительской таблице должны соответствовать записи в дочерней таблице, во втором случае некоторые записи в родительской таблице могут не иметь записей в дочерней таблице.
|
|
|
Таблица «Товары» Таблица «Отпуск товаров»
| Товар | Ед. изм. | Цена ед. | Товар | Дата | Кол-во (ед) | |
   Сахар Сахар
| кг | Сахар | 10.01.03 | |||
| Макароны | кг | Сахар | 15.01.03 | |||
| Куры | кг | Сахар | 12.02.03 | |||
| Фанта | бут.1 л | Макароны | 20.02.03 | |||
| Макароны | 10.03.03 | |||||
| Фанта | 09.01.03 |
Отношение «многие-ко-многим»
Ниже приведены таблицы, состоящие в отношении " многие-ко-многим ". Каждой учебной группе соответствует несколько преподавателей. Каждый преподаватель может вести, во-первых, несколько разных предметов и, во-вторых, преподавать в разных группах.
Таблица «Группы и предметы» Таблица «Преподаватели»
| Группа | Предмет | № преподавателя | № преподавателя | ФИО | Кафедра | |
  1Ф1 1Ф1
| Информатика | Иванов В.В. | ТИ-1 | |||
 1Ф1 1Ф1
| Теория систем | Петров П.П. | ТИ-1 | |||
  1Ф1 1Ф1
| Информатика | Васин И.И. | РИО | |||
| 1Ф1 | Философия | Лавров И.И. | ТИ-1 | |||
| 1У1 | Социология | Павлов В.А. | ЭИ-1 | |||
| … | … | … | … | … | … |
Ссылочную целостность рассмотрим на примере наиболее часто встречающейся связи между таблицами " один-ко-многим ". Возможны два вида изменений, которые приведут к утере связей между записями в родительской и дочерней таблицах.
· изменение значения поля связи в записи родительской таблицы без изменения значений полей связи в соответствующих записях дочерней таблицы;
· изменение значения поля связи в одной из записей дочерней таблицы без соответствующего изменения значения поля связи в родительской и дочерней таблицах;
Рассмотрим первый случай: заменим в таблице «Товары» в поле «Товар» «Сахар» на «Рафинад». В результате в дочерней таблице «Отпуск товаров» для поля «Рафинад» нет сведений об его отпуске со склада и некоторые записи таблицы «Отпуск товаров» содержат сведения об отпуске товара «Сахар», о котором нет информации в таблице «Товары».
Рассмотрим второй случай: заменим в одной из записей таблицы «Отпуск товаров» значение поля связи «Сахар» на «Рафинад». В результате в дочерней таблице «Отпуск товаров» недостоверны сведения об отпуске товара «Сахар» и одна из записей таблицы «Отпуск товаров» содержат сведения об отпуске товара «Рафинад», данные о котором отсутствуют в таблице «Товары».
|
|
|
И в первом, и во втором случае произошло нарушение целостности базы данных, информация, хранящаяся в ней, становится недостоверной.
СУБД обычно блокирует действия, которые нарушают целостность связей между таблицами, т.е. нарушают ссылочную целостность. Когда говорят о ссылочной целостности, имеют в виду совокупность связей между отдельными таблицами во всей БД. Нарушение хотя бы одной такой связи делает информацию в БД недостоверной. Чтобы предотвратить потерю ссылочной целостности, используют механизм каскадных изменений. На этапе формирования связей (например, СУБД Access) надо установить флажок «Обеспечение целостности данных» и далее флажки «Каскадное обновление связанных полей» и «Каскадное удаление связанных полей».
Для правильной организации данных в таблицы используется понятие нормализации. Нормализация данных - процесс исключения избыточной информации, при котором достигается то, что каждый элемент информации запоминается только один раз. Теория и практические рекомендации по нормализации рассматриваются в книгах по реляционным базам данных.
Кроме того, нормализация нужна для повышения эффективности БД. Сразу следует оговориться, что нормализуется вся база, при этом вносятся изменения в отдельные таблицы, при необходимости создаются новые, устанавливаются связи между ними и т.д.
В общем случае, нормализация - это процесс приведения базы к нормальным формам. Их несколько, приведение происходит последовательно. Известно, что нормальных форм существует 6, но обычно останавливаются на третьей, иногда на второй.
Первая нормальная форма. Первая нормальная форма требует, чтобы каждое поле таблицы было неделимым и не содержало повторяющихся групп.
Неделимость означает, что поле является атомарным и не должно делиться на более мелкие.
Неповторяемость означает, что нет повторяемых значений полей в одной записи. Имеется в виду не та ситуация, когда указано несколько полей с одинаковыми значениями. Например, записная книжка. Какие поля здесь необходимы? Фамилия, имя, телефон, e-mail... А может несколько телефонов, e-mail? В наше время почти у каждого есть и рабочий, и домашний, и мобильный... Так сколько таких полей ввести? Правильнее всего будет создать еще одну таблицу с телефонами, а в ней поместить ссылку на первую. Тогда можно будет для каждого абонента указать произвольное число телефонов.
|
|
|
| Код | Фамилия | Адрес.... | Чей | Какой | Номер | |
| Иванов | Рабочий 1 | 23-45-67 | ||||
| Петров | Рабочий 2 | 23-45-98 | ||||
| Домашний | 11-34-98 | |||||
| Домашний | 45-09-87 | |||||
| ... | ... | ... |
Этот процесс называется разбиением таблицы на главную и подчиненную. Эти две таблицы находятся в отношении " один-ко-многим ".
Вторая нормальная форма. Вторая нормальная форма требует, во-первых соответствия первой нормальной форме. А во-вторых, чтобы каждая строка таблицы однозначно и неизбыточно определялась первичным ключем.
Третья нормальная форма. Третья нормальная форма требует, во-первых, соответствия второй. А во-вторых - чтобы значение любого поля, не входящего в первичный ключ не зависело от других полей, не входящих в первичный ключ.
Рассмотрим пример приведения БД к третьей нормальной форме на примере накладной. Пусть необходимо автоматизировать процесс отпуска товаров со склада по накладной. Сведем имеющиеся данные в одну таблицу:
ОТПУСК-ТОВАРОВ-СО-СКЛАДА
| Дата Покупатель Город Адрес Товар Ед_измерения Цена_за_ед_изм Отпущено_ед Общая_стоимость Номер_накладной |
Далее на схеме та же БД, приведенная к третьей нормальной форме.
ТОВАРЫ ПОКУПАТЕЛИ
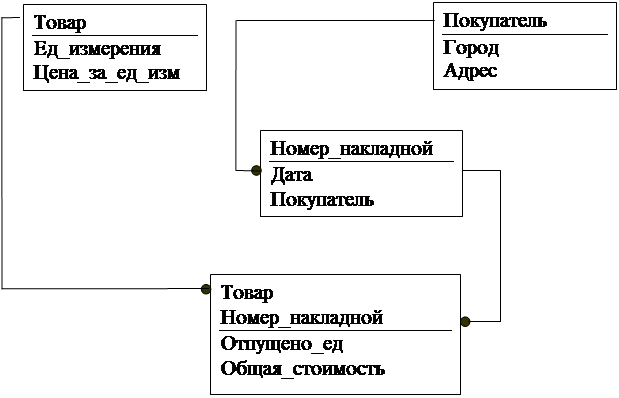 |
НАКЛАДНЫЕ
ОТПУСК_ТОВАРОВ_СО_СКЛАДА
Рассмотрим все плюсы и минусы нормализации данных:
«+»:
· информация нигде не дублируется, здесь присутствует только один элемент избыточных данных – поля связи
· в случае изменений в данных эти изменения нужно проводить только в одном месте
«-»:
· чем шире число сущностей, охватываемых предметной областью, тем из большего числа таблиц будет состоять нормализованная БД
· уменьшается целостное восприятие БД как системы взаимосвязанных данных
· при составлении запросов необходимо считывать связанные данные из нескольких таблиц
При работе с данными большого объема необходимо искать компромисс между требованиями нормализации, что экономит дисковое пространство, и необходимостью улучшения быстродействия системы. Считается что первых трех нормальных форм достаточно для большинства практических применений.
По заданным в таблицах ключам СУБД автоматически строит индексы, которые представляют собой механизмы быстрого доступа к хранящимся в таблицах данных. Индексирование записей файла позволяет заменить физическую реорганизацию файла (перестановки записей и др.) изменением индексов. Используя индекс, можно реорганизовывать индекс без реорганизации самого файла. Это значительно увеличивает скорость обработки больших объемов информации.
Чтобы создать индекс, вначале задается массив целых чисел, в котором каждый элемент содержит один (свой) номер записи файла прямого доступа. Этот массив используется для определения номера записи, к которой нужно обратиться. Такая организация хранения записи файла называется индексированием записи. Записи одного файла могут иметь несколько разных индексов для организации различных алгоритмов работы с одним и тем же файлом. Сущность индексов состоит в том, что они хранят отсортированные значения индексных полей и указатель на запись в таблице.
Пример:
| Порядковый номер записи | Товар | Дата | Кол-во (ед) |
| Сахар | 10.01.03 | ||
| Картофель | 15.01.03 | ||
| Свекла | 12.02.03 | ||
| Сахар | 20.02.03 | ||
| Свекла | 10.03.03 | ||
| Сливы | 19.03.03 |
С логической точки зрения ее индексы выглядят так:
| Индекс по дате прихода товара | Индекс по наименованию товара | Индекс по количеству | |||
| Дата | Порядко-вый номер записи | Товар | Порядко-вый номер записи | Кол-во (ед) | Порядко-вый номер записи |
| 10.01.03 | Картофель | ||||
| 15.01.03 | Сахар | ||||
| 12.02.03 | Сахар | ||||
| 20.02.03 | Свекла | ||||
| 10.03.03 | Свекла | ||||
| 19.03.03 | Сливы |
| Индекс по наименованию товара будет выглядеть следующим образом | Индекс по количеству будет выглядеть следующим образом | |
| Index(1)=2 Index(2)=1 Index(3)=4 Index(4)=3 Index(5)=5 Index(6)=6 | Index(1)=3 Index(2)=5 Index(3)=2 Index(4)=1 Index(5)=4 Index(6)=6 |
Рассмотрим правила индексирования.
· Индекс по первичному ключу позволяет быстро найти нужную запись. Это пожалуй самый быстрый способ перейти к нужной записи. Кроме того, он не заменим при связывании таблиц. Есть и другие достоинства у индексов по первичным ключам. Так что первое правило - каждой таблице по первичному ключу.
· Существует следующее правило - поля, по которым часто приходится искать, должны быть проиндексированы
· При каждом обновлении таблицы индексы также модифицируются. Если их слишком много, это займет много времени. Понятие "слишком" сильно зависит от СУБД, но обычно считается, что 5 индексов на таблицу - нормально. Правило - не загромождайте таблицу лишними индексами
· При связывании таблиц нам нужно, чтобы при перемещении по главной таблице записи в подчиненной искались как можно быстрее. Поле, по которому мы связываем таблицы, называется внешним ключем. Итак, следующее правило - индексы для внешних ключей как правило не нужны.
Приведенные таблицы являются исходными (базовыми) для задания данных и связей между ними. Такие таблицы физически существуют в памяти ЭВМ, хотя их вид необязательно соответствует приведенному (физическое представление данных, т.е. то, как данные реально хранятся на носителях, отличается от их логического представления в виде рассмотренных таблиц и зависит от типа ЭВМ и носителя данных).
Важное дополнение к таблицам представляют запросы. В результате информационного запроса (query) к реляционной базе данных также получается некоторая таблица, которая является представлением существующих данных. Заложенные в исходных таблицах отношения позволяют конструировать различные логические представления данных. Результат выполнения запроса не хранится, хранятся только таблицы.
Дадим еще одно определение баз данных:под базой данных теперь мы будем понимать совокупность таблиц, ключей, индексов, форм, запросов и т.д.
|
|
|
|
|
Дата добавления: 2017-01-13; Просмотров: 412; Нарушение авторских прав?; Мы поможем в написании вашей работы!