КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм бустинга для построения детектора
|
|
|
|
Основная идея бустинга заключается в создании сильного классификатора из набора слабых классификаторов используя аддитивную модель (2) путем минимзации экспоненциальной фунции ошибки (3). На каждой итерации алгоритма бустинга, примеры из тренировочного набора которые были классифицированы корректно получают меньший весовой коэффициент 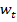 , а те, которые часто классифицировались неправильно, получают больший вес . Из формулы (3) видно, что если результат классификации детектором
, а те, которые часто классифицировались неправильно, получают больший вес . Из формулы (3) видно, что если результат классификации детектором 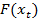 совпадает по знаку с фактическим наличием микрочастицы на изображении, то функция ошибки
совпадает по знаку с фактическим наличием микрочастицы на изображении, то функция ошибки 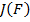 минимизируется.
минимизируется.
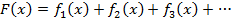 (2)
(2)
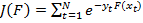 (3)
(3)
где  - слабые классификаторы,
- слабые классификаторы, 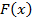 - сильный классификатор,
- сильный классификатор, 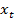 - тренировочные изображения,
- тренировочные изображения, 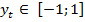 - объект или фон представлен на тренировочном изображении
- объект или фон представлен на тренировочном изображении 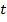 ,
, 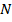 - количество тренировочных изображений.
- количество тренировочных изображений.
Существует множество вариаций бустинга, в данной работе мы остановились на версии алгоритма GentleBoost, который можно описать следующим образом:
1. Инициализация: веса для каждого тренировочного примера задаются равными друг другу 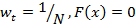
2. На каждой итерации алгоритма 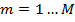
2.1. Выбрать оптимальный слабый классификатор 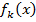 и параметры ступенчатой функции слабого классификатора
и параметры ступенчатой функции слабого классификатора 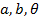 которые решают взвешенную задачу наименьших квадратов:
которые решают взвешенную задачу наименьших квадратов:
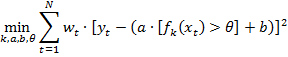
2.2. Определить оптимальный слабый классификатор в форме регрессионной ступенчатой функции 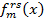 из предыдущего шага:
из предыдущего шага:
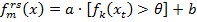
2.3. Обновить сильный классификатор:
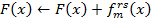
2.4. Обновить веса для примеров, веса неверно классифицированных примеров увеличиваются, а веса верно классифицированных примеров уменьшаются. Это требуется для того чтобы следующий слабый детектор был выбран более специализированным именно под неверно классифицированные примеры:

3. Определить сильный классификатор в виде:
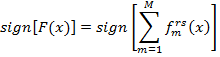
На Рис.4 можно видеть, как изменяются ROC-кривые детектора. ROC-кривая (операционная характеристика приемника) - зависимость процента корректных позитивных срабатываний детектора (микрочастица присутствует на изображении и детектор подтверждает это) от процента ложных позитивных срабатываний (частица отсутствует на изображении, но детектор определяет микрочастицу).
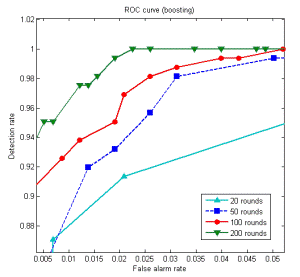
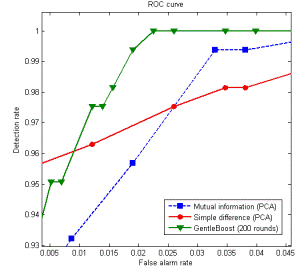
Рис.4 ROC-кривые для классификатора на основе бустинга с разым количеством слабых детекторов (слева), сравнение ROC-кривых классификатора на основе бустинга с классификатором на основе метода главных компонент (справа)
Одним из основных преимуществ бустинг алгоритмов относительно других методов построения классификаторов является то, что они практически невоспреимчивы к перетренированности. Чем больше итераций бустинга мы используем, т.е. чем больше порядок классификатора, тем лучше получаются результаты не только на тренировочном, но и на контрольном множестве примеров. Также из Рис.4 слева видно, что точность детектирования улучшается с увеличением количество слабых детекторов (итераций бустинга) в сильном детекторе.
Как видно из Рис.4 справа, ROC-кривая, соответствующая детектору построенному с помощью бустинга, имеет значительно более высокий процент детектирования при значительно меньшем количестве ложных срабатываний, чем кривые для детектора на основе метода главных компонент. Остается открытым вопрос, почему детектор на основе метода главных компонент работает несколько лучше при малой частоте ложных срабатываний.[тут большая картинка с найденными шарами]
|
|
|
|
|
Дата добавления: 2014-12-10; Просмотров: 1035; Нарушение авторских прав?; Мы поможем в написании вашей работы!