КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Назначение и состав процессора
|
|
|
|
CISC-процессоры
Процессоры Intel 8086
Родоначальником архитектуры процессоров Intel x86 является процессор Intel 8086 (1978 год). Intel 8086 представляет собой 16-битовую архитектуру со всеми внутренними регистрами, имеющими 16-битовую разрядность. К процессорам этого класса относятся микропроцессоры: Intel 80286 (24 битная архитектура), 80386 (32 битная архитектура), 80486 (32-битовые процессоры с внутренней кэш-памятью и встроенным сопроцессором (только DX)), Pentium, Pentium II и т.д.
Особенностью этих процессоров является преемственность на уровне машинных команд: программы, написанные для младших моделей процессоров, без каких-либо изменений могут быть выполнены на более старших моделях. При этом базой является система команд процессора 8086.
Структуру центрального процессора Intel 8086 можно разделить на два логических блока (рис.2.4):
• блок исполнения (EUrExecution Unit);
• блок интерфейса шин (BIU:Bus Interface Unit).
В состав EU входят: арифметическо-логическое устройство ALU, устройство управления CU и десять регистров. Устройства блока EU обеспечивают обработку команд, выполнение арифметических и логических ВШ включает устройство управления шинами, блок очереди команд, регистры сегментов и предназначен для выполнения следующих функций:
• управление обменом данными с EU, памятью и внешними устройствами ввода/вывода;
• адресация памяти;
• выборка команд (осуществляется с помощью блока очереди команд Queue, который позволяет выбирать команды с упреждением). Регистры микропроцессора имеют следующее назначение:
регистры общего назначения - это 16-разрядные регистры АХ, ВХ, СХ, DX, каждый из которых состоит из двух 8-разрядных регистров, например, АХ состоит из АН (старшая часть) и AL (младшая часть).
В общем случае функция, выполняемая тем или иным регистром, определяется командами, в которых он используется. При этом с каждым регистром связано некоторое стандартное его значение:
• регистр АХ служит для временного хранения данных (регистр аккумулятор), часто используется при выполнении операций сложения, вычитания, сравнения и других арифметических и логических операций;
• регистр ВХ служит для хранения адреса некоторой области памяти (базовый регистр), а также используется как вычислительный регистр;
• регистр СХ иногда используется для временного хранения данных, но в основном служит счетчиком, в нем хранится число повторений одной команды или фрагмента программы;• регистр DX используется главным образом для временного хранения данных, часто служит средством пересылки данных между разными программными системами, а также используется в качестве расширителя аккумулятора для вычислений повышенной точности и при умножении и делении.
Регистры указатели - это 16-разрядные регистры ВР (указатель базы), SI (индекс источника), DI (индекс результата), SP (указатель стека), IP (указатель команд).
Регистры SI, DI, BP используются в командах для хранения адресов памяти. При адресации памяти эти регистры могут быть использованы в различных комбинациях, что определяет различные режимами адресации.
Регистр SP определяет смещение текущей вершины стека. Указатель стека SP вместе с сегментным регистром стека SS используется для формирования физического адреса стека.
Регистр указателя команд IP, иначе называемый регистром счетчика команд и хранит адрес ячейки памяти, содержащей начало следующей команды. Микропроцессор использует регистр IP совместно с регистром CS для формирования физического адреса очередной выполняемой команды
Регистры сегментов - это 16-разрядные регистры, которые позволяют организовать память в виде совокупности четырех различных сегментов.
• CS - регистр программного сегмента (сегмента кода) определяет местоположение части памяти, содержащей программу, то есть выполняемые процессором команды;
• DS - регистр информационного сегмента (сегмента данных) идентифицирует часть памяти, предназначенной для хранения данных;
• SS - регистр стекового сегмента (сегмента стека) определяет часть памяти, используемой как системный стек;
• ES - регистр расширенного сегмента (дополнительного сегмента) указывает дополнительную область памяти, используемую для хранения данных.
Регистр флагов - это 16-разрядный регистр, содержащий биты, определяющие код условия, установленный последней выполненной командой или состояние микропроцес^ сора. Эти биты называются флагами.
| В | А | ||||||||||||||
| X | X | X | X | OF | DF | IF | TF | SF | ZF | X | AF | X | PF | X | CF |
Биты регистра флагов имеют следующее назначение:
OF (признак переполнения) - равен единице, если возникает арифметическое переполнение, то есть когда объем результата превышает размер ячейки назначения;
DF (признак направления) - устанавливается в единицу для автоматического декремента в командах обработки строк, и в ноль - для инкремента;
IF (признак разрешения прерывания) - прерывания разрешены, если IF=1. Если IF=0, то распознаются лишь немаскированные прерывания;
TF (признаков трассировки) - если TF=1, то процессор переходит в состояние прерывания INT 3 после выполнения каждой команды;
SF (признак знака) - SF=1, когда старший бит результата равен единице. Иными словами, SF=0 для положительных чисел, и SF=1 для отрицательных чисел; ZF (признак нулевого результата) - ZF=1, если результат равен нулю;
AF (признак дополнительного переноса) - этот флаг устанавливается в единицу во время выполнения команд десятичного сложения и вычитания при возникновении переноса или заема между полубайтами;
PF (признак четности) - этот признак устанавливается в единицу, если результат имеет четное число единиц;
CF (признак переноса) - этот флаг устанавливается в единицу, если имеет место перенос или заем из старшего бита результата, он полезен для произведения операций над числами длиной в несколько слов, которые сопряжены с переносами и заемами из слова в слово;
Х- зарезервированные биты. Процессоры Pentium
Архитектура микропроцессора Pentium значительно отличается от приведенной выше, что обуславливает следующие преимущества указанного класса процессоров:
• двухпотоковая суперскалярная организация, допускающая параллельное выполнение пары простых команд;
• наличие двух независимых двухканальных множественно-ассоциативных кэшей для команд и для данных, обеспечивающих выборку данных для двух операций в каждом такте;
• динамическое прогнозирование переходов;
• конвейерная организация устройства плавающей точки с 8 ступенями;
• двоичная совместимость с существующими процессорами семейства 80x86.
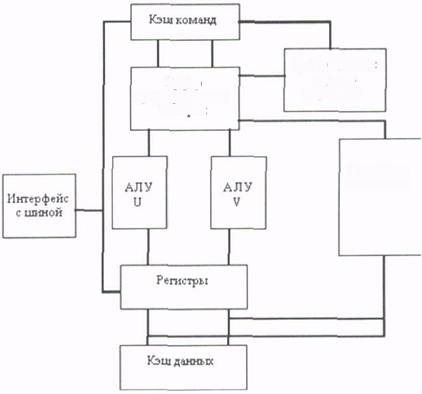
Упрощенная структура процессора Pentium представлена на рис. 2.5. Прежде всего,
новая микроархитектура этого процессора базируется на идее суперскалярной обработки.
Основные команды распределяются по двум независимым исполнительным устройствам
(конвейерам U и V). Конвейер U может выполнять любые команды семейства х86, вклю
чая целочисленные команды и команды с плавающей точкой. Конвейер V предназначен
для выполнения простых целочисленных команд и некоторых команд с плавающей точ
кой. Команды могут направляться в каждое из этих устройств одновременно, причем при
выдаче устройством управления в одном такте пары команд более сложная команда по
ступает в конвейер U, а менее сложная - в конвейер V (при этом, однако, не все команды
совместимы). Остальные устройства процессора предназначены для снабжения конвейе
ров необходимыми командами и данными
В процессоре Pentium используется раздельная кэш-память команд и данных, что обеспечивает независимость обращений. За один такт из каждой кэш-памяти могут считываться два слова. Для повышения эффективности перезагрузки кэш-памяти в процессоре применяется 64-битовая внешняя шина данных.
В процессоре предусмотрен механизм динамического прогнозирования направления переходов. С этой целью на кристалле размещена небольшая кэш-память, которая называется буфером целевых адресов переходов (ВТВ), и две независимые пары буферов предварительной выборки команд (по два 32-битовых буфера на каждый конвейер). Буфер целевых адресов переходов хранит адреса команд, которые находятся в буферах предварительной выборки. Работа буферов предварительной выборки организована таким образом, что в каждый момент времени осуществляется выборка команд только в один из буферов соответствующей пары. При обнаружении в потоке команд операции перехода вычисленный адрес перехода сравнивается с адресами, хранящимися в буфере ВТВ. В случае совпадения предсказывается, что переход будет выполнен, и разрешается работа другого буфера предварительной выборки, который начинает выдавать команды для выполнения в соответствующий конвейер. При несовпадении считается, что переход выполняться не будет и буфер предварительной выборки не переключается, продолжая обычный порядок выдачи команд. Это позволяет избежать простоев конвейеров при правильном прогнозе направления перехода. Упрощенная структура процессора Pentium приведена на Рис.2.2.
|
Рис 2.2. Упрощенная структура процессора Pentium.
Intel Pentium 4 — это первый процессор в семействе 32-битных процессоров седьмого поколения от Intel. Несмотря на то что Intel Pentium 4 является процессором с архитектурой IA-32, последняя сильно отличается от архитектуры процессоров семейства Р6 (в него входят процессоры Intel Pentium Pro, Intel Pentium II, Intel Pentium III, Intel Celeron и Intel Xeon) и даже получила специальное название — Net Burst. К основным новшествам архитектуры Net Burst являются:
• Hyper-Pipelined Technology,
• Execution Trace Cache,
• Rapid Execution Engine,
• 400 MHz System Bus,
• Advanced Dynamic Execution,
• Advanced Transfer Cache,
• Streaming SIMD Extensions 2 (SSE2).
Hyper-Pipelined Technology. Суть технологии гиперконвеерной технологии заключается в том, что Intel Pentium 4 имеет очень длинный конвейер, состоящий из 20 стадий. Для сравнения: конвейер у процессоров семейства Р6 состоит всего из 10 стадий. Преимущества от использования такого новшества далеко не очевидны.
С одной стороны, более длинный конвейер позволяет упростить логику работы каждой отдельной стадии, а значит, более просто реализовать ее аппаратно, что приводит к уменьшению времени выполнения каждой отдельно взятой стадии. А это в конечном счете приводит к тому, что тактовая частота процессора может быть значительно увеличена.
С другой стороны, при обнаружении неправильно предсказанного перехода весь конвейер останавливается вместе с одновременным сбросом его содержимого, после чего разгоняется заново — и чем длиннее конвейер, тем больше времени занимает его разгон.
Поэтому при увеличении длины конвейера для обеспечения роста производительности нужно повышать эффективность алгоритмов предсказания переходов.
Execution Trace Cache - это название и способ реализации Ll-кэша инструкций в архитектуре Net Burst. Смысловое содержание этого термина можно перевести как «кэщ трассировки выполняемых микроопераций».
В Execution Trace Cache хранятся микрооперации, полученные в результате декодирования входного потока инструкций исполняемого кода и готовые для передачи на выполнение конвейеру. Емкость Execution Trace Cache составляет 12 Кбайт.
Execution Trace Cache устроен таким образом, что вместе с кодом каждой микрооперации в нем хранятся результаты выполнения ветвей кода для этой микрооперации — в той же строке кэша (cache line), что и сама микрооперация. Это позволяет легко и своевременно выявлять микрооперации, которые никогда не будут выполнены, и быстро удалять их из Ll-кэша инструкций, а также оперативно «вычищать» Execution Trace Cache от «лишних» микроопераций в случае обнаружения ошибочно предсказанного перехода. Последнее обстоятельство особенно важно, так как позволяет сократить общее время реини-циализации конвейера после его остановки в результате выполнения перехода, который был предсказан неправильно.
Rapid Execution Engine. Так, в архитектуре NetBurst назван блок выполнения арифметико-логических операций. Rapid Execution Engine, во-первых, состоит из двух ALU-модулей, работающих параллельно, во-вторых, рабочая тактовая частота этих ALU-модулей в два раза выше тактовой частоты процессора — это достигается за счет регистрации как переднего, так и заднего фронта задающего тактового сигнала. Таким образом, каждый ALU-модуль способен выполнить до двух целочисленных операций за один рабочий такт процессора, а весь Rapid Execution Engine в целом — до четырех таких операций.
400 MHz System Bus. Физически системная шина у Intel Pentium 4 тактируется частотой в 100 МГц, однако благодаря использованию технологии Quad Pumping по этой шине передается четыре блока данных за один такт (аналогично тому, как это делается при передаче данных в режиме AGP 4X по AGP-шине). Так что эффективная рабочая частота системной шины у Intel Pentium 4 (которую также называют Quad Pumped Bus) составляет 400 МГц, а пропускная способность — 3,2 Гбайт/с.
Advanced Dynamic Execution — это обобщенное название механизма динамического выполнения команд (dynamic execution), используемого в NetBurst, построенного на трех базовых концепциях: предсказание переходов (branch prediction), динамический анализ потока данных (dynamic dataflow analysis) и спекулятивное выполнение инструкции (out-of-order execution). Аналогичный механизм, названный Dynamic Execution, используется в процессорах семейства Р6, однако в Intel Pentium 4 он улучшен.
Так, например, емкость пула, в котором хранятся готовые для обработки инструкции (out-of-order instruction window), у Intel Pentium 4 увеличена до 126 инструкций — против 42 у процессоров семейства Р6.
Кроме того, в Intel Pentium 4 интегрирован более совершенный механизм предсказания переходов и количество ошибочно предсказанных переходов у него в среднем на 33% меньше, чем у процессоров с архитектурой Р6.
Advanced Transfer Cache - это, в архитектуре NetBurst, Ь2-кэш процессора емкостью 256 Кбайт. Ширина шины, по которой идет обмен данными между Advanced Transfer Cache и процессором, составляет 256 бит (32 байта), а ее тактовая частота совпадает с тактовой частотой ядра процессора.
Совместимые с Intel процессоры выпускают следующие производители Advanced Micro Devices (AMD), Cyrix Corp и Nex Gen.
RISC-процессоры
Особенности процессоров с архитектурой SPARC
Масштабируемая процессорная архитектура компании Sun Microsystems (SPARC -Scalable Processor Architecture) является наиболее широко распространенной RISC-архитектурой, отражающей доминирующее положение компании на рынке UNIX-рабочих станций и серверов. Процессоры с архитектурой SPARC лицензированы и изготавливаются по спецификациям Sun несколькими производителями, среди которых следует отметить компании Texas Instruments, Fujitsu, LSI Logic, Bipolar International Technology, Philips и Cypress Semiconductor. Процессоры с архитектурой SPARC занимают лидирующие позиции на рынке RISC-кристаллов (по данным независимой компании ЮС за 1992 год архитектура SPARC занимала 56% рынка, далее следовали MIPS - 15% и PA-RISC - 12.2%).
Первоначально архитектура SPARC была разработана с целью упрощения реализации 32-битового процессора. В последствии по мере улучшения технологии изготовления интегральных схем она постепенно развивалось и в настоящее время имеется 64-битовая версия этой архитектуры.
В отличие от большинства RISC архитектур SPARC использует регистровые окна, которые обеспечивают удобный механизм передачи параметров между программами и возврата результатов. Архитектура SPARC была первой коммерческой разработкой, реализующей механизмы отложенных переходов и аннулирования команд. Это давало компилятору большую свободу заполнения времени выполнения команд перехода командой, которая выполняется в случае выполнения условий перехода и игнорируется в случае, если условие перехода не выполняется.
Процессоры SuperSPARC
Процессор SuperSPARC (один из первых процессоров серии SPARC) компании Texas Instruments стал основой серии рабочих станций и серверов SPARCstation/SPARCserver 10 и SPARCstation/SPARCserver 20. Имеется несколько версий этого процессора, позволяющего в зависимости от смеси команд обрабатывать до трех команд за один машинный такт, отличающихся тактовой частотой. Процессор SuperSPARC имеет сбалансированную производительность на операциях с фиксированной и плавающей точкой. Он имеет внутренний кэш емкостью 36 Кб (20 Кб - кэш команд и 16 Кб - кэш данных), раздельные конвейеры целочисленной и вещественной арифметики и при тактовой частоте 75 МГц обеспечивает производительность около 205 MIPS (миллион команд в секунду). Для сравнения: Intel Pentium 66 МГц обеспечивает производительность 112 MIPS.
Развитием SPARC-процессоров стали процессоры hyperSPARC, 64-битовые процессоры UltraSPARC I, UltraSPARC II и т.д.
Процессоры HyperSPARC
Одной из главных задач, стоявших перед разработчиками микропроцессора hyperSPARC, было повышение производительности, особенно при выполнении операций с плавающей точкой. Поэтому особое внимание разработчиков было уделено созданию простых и сбалансированных шестиступенчатых конвейеров целочисленной арифметики и плавающей точки. Логические схемы этих конвейеров тщательно разрабатывались, количество логических уровней вентилей между ступенями выравнивалось, чтобы упростить вопросы дальнейшего повышения тактовой частоты.
Производительность процессоров hyperSPARC может меняться независимо от скорости работы внешней шины (MBus). Набор кристаллов hyperSPARC обеспечивает как синхронные, так и асинхронные операции с помощью специальной логики кристалла RT625. Отделение внутренней шины процессора от внешней шины позволяет увеличивать тактовую частоту процессора независимо от частоты работы подсистем памяти.
Процессор RT620
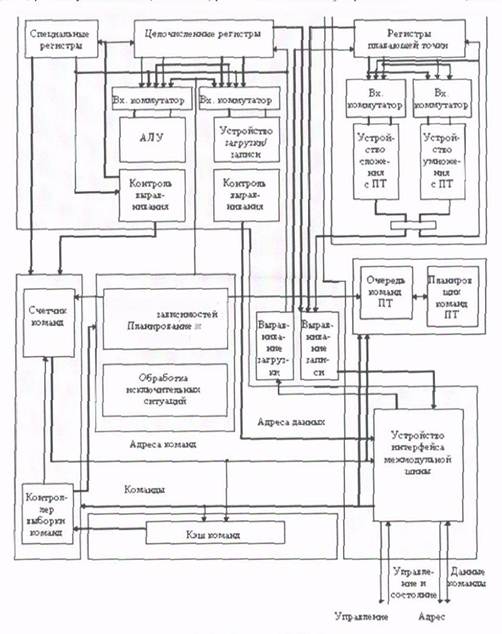
Центральный процессор RT620 (рис. 2.3) состоит из целочисленного устройства, устройства с плавающей точкой, устройства загрузки/записи, устройства переходов и двухканальной множественно-ассоциативной памяти команд емкостью 8 Кбайт. Целочисленное устройство включает АЛУ и отдельный тракт данных для операций загрузки/записи, которые представляют собой два из четырех исполнительных устройств процессора. Устройство переходов обрабатывает команды передачи управления, а устройство плавающей точки, реально состоит из двух независимых конвейеров - сложения и умножения чисел с плавающей точкой. Для увеличения пропускной способности процессора команды плавающей точки, проходя через целочисленный конвейер, поступают в очередь, где они ожидают запуска в одном из конвейеров плавающей точки. В каждом такте выбираются две команды. В общем случае, до тех пор, пока эти две команды требуют для своего выполнения различных исполнительных устройств при отсутствии зависимостей по данным, они могут запускаться одновременно. RT620 содержит два регистровых файла: 136 целочисленных регистров, сконфигурированных в виде восьми регистровых окон, и 32 отдельных регистра плавающей точки, расположенных в устройстве плавающей точки.
|
| Гпобианий дешифратор Контроль к упр-пленке |
Рис. 2.3. Процессор RT 620
Кэш-память второго уровня в процессоре hyperSPARC строится на базе RT625 CMTU, который представляет собой комбинированный кристалл, включающий контроллер кэш-памяти и устройство управления памятью, которое поддерживает разделяемую внешнюю память и симметричную многопроцессорную обработку.
RT627 представляет собой статическую память 16К, специально разработанную для удовлетворения требований hyperSPARC. Она организована как четырехканальная статическая память в виде четырех массивов с логикой побайтной записи и входными и выходными регистрами-защелками. RT627 для ЦП является кэш-памятью с нулевым состоянием ожидания без потерь (т.е. приостановок) на конвейеризацию для всех операций загрузки и записи, которые попадают в кэш-память.
Команды загрузки и записи одновременно генерируют два обращения: одно к кэшпамяти команд первого уровня емкостью 8 Кбайт и другое к кэш-памяти второго уровня. Если адрес команды найден в кэш-памяти первого уровня, то обращение к кэш-памяти второго уровня отменяется и команда становится доступной на стадии декодирования конвейера. Если же во внутренней кэш-памяти произошел промах, а в кэш-памяти второго уровня обнаружено попадание, то команда станет доступной с потерей одного такта, который встроен в конвейер. Такая возможность позволяет конвейеру продолжать непрерывную работу до тех пор, пока имеют место попадания в кэш-память либо первого, либо второго уровня, которые составляют 90% и 98% соответственно для типовых прикладных задач рабочей станции.
|
|
|
|
|
Дата добавления: 2014-01-15; Просмотров: 541; Нарушение авторских прав?; Мы поможем в написании вашей работы!