КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм максимального расстояния
|
|
|
|
Характерная особенность алгоритма – выбор наиболее удалённых кластеров.
Дано:
1. множество точек во входном пространстве X
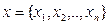
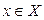
Данный алгоритм сводится к следующей последовательности действий:
1) Выбираем случайным образом точку, соответствующую центру первого кластера. (z1)
2) Из множества точек X выбираем такую точку, которая наиболее удалена от точки, соответствующей центру z1, и определяем эту точку как центр второго кластера.
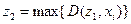
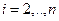
3) Для каждой из точек 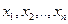 вычисляются расстояния от данной точки до всех центров кластеров
вычисляются расстояния от данной точки до всех центров кластеров 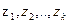 , созданных на данный момент времени.
, созданных на данный момент времени.
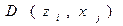
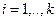
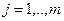
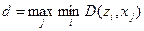
То есть для каждой точки xj множества X определяется кластер («свой» кластер), расстояние до которого будет минимальным. Далее выбирается точка x*, наиболее удалённая от данного («своего») кластера.
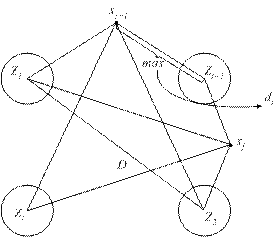
На каждом шаге алгоритма t= 1,2,3,…вычисляется величина: 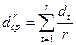
Если значение d составляет существенную часть (не менее половины) от величины 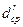 , то тогда x* объявляется центром нового кластера. В противном случае (значение d менее половины от величины ) процесс завершается, а все оставшиеся точки множества X разносятся по ближайшим кластерам.
, то тогда x* объявляется центром нового кластера. В противном случае (значение d менее половины от величины ) процесс завершается, а все оставшиеся точки множества X разносятся по ближайшим кластерам.
Недостатки алгоритма:
2. случайный выбор начального кластера
3. увеличение уровня сложности на каждом шаге работы алгоритма
3. Алгоритм внутригруппового среднего (метод K-средних, K-means clustering, C-means clustering)
Данный алгоритм минимизирует сумму квадратов расстояний между точками кластеров в процессе разбиения исходного пространства на q кластеров.
Дано:
1. множество точек во входном пространстве X
Алгоритм сводится к следующей последовательности действий:
1) Произвольно выбираются q центров кластеров (в качестве центров кластеров берутся точки из входного множества).
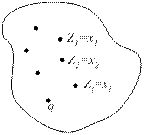
2) Все образы (точки из входного множества), не являющиеся центрами кластеров, «разносятся» по кластерам в соответствии с принципом минимального расстояния до центра кластера.
Образ х принадлежит кластеру Kj, если расстояние от точки х до центра zj(r) данного кластера меньше расстояния от х до центра любого другого кластера (q- 1). Kj определяет множество, состоящее из точек, включённых в него до r -ого шага.
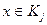 , если
, если 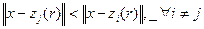
3) Определяются новые центры кластеров zj(r+ 1 ), j= 1 … q таким образом, чтобы минимизировать показатель качества J.
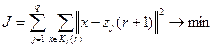
В данном случае используется евклидово расстояние.
Новый центр кластера вычисляется по следующей формуле:
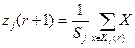 , где
, где 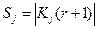 – количество точек, включенных в пространство Kj к r-ому шагу итерации.
– количество точек, включенных в пространство Kj к r-ому шагу итерации.
4) Алгоритм заканчивает свою работу, если выполняется равенство: 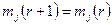 , то есть не изменяются центры кластеров. В противном случае, переход к пункту 2.
, то есть не изменяются центры кластеров. В противном случае, переход к пункту 2.
Пример реализации алгоритма К-средних
Дано:
Х ={x1, x2,…,x10}
q =3
Положим, что Z1 = X1; Z2 = X3; Z3 = X4
В технике оптимизации используется приём "мультстарт": алгоритм оптимизации реализуется несколько раз из различных начальных точек, а затем из полученных решений выбирается наилучшее.
Шаг 1. Определяем минимальное расстояние от каждой точки до каждого кластера.
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | |
| коорд. | (2;2) | (2;4) | (3;4) | (3;8) | (4;7) | (5;9) | (6;1) | (6;8) | (7;1) | (8;1) |
| Z1 | - | - | 5,4 | 7,6 | 4,1 | 7,2 | 5,1 | 6,05 | ||
| Z2 | - | - | 3,2 | 5,4 | 4,2 | 5,8 | ||||
| Z3 | - | 4,1 | - | 1,4 | 2,3 | 7,6 | 8,05 | 8,6 |
Шаг 2. По критерию минимального расстояния определяем, какие точки относятся к какому кластеру.
| кластер | точки |
| X1, X7 | |
| X2, X3, X9, X10 | |
| X4, X5, X6, X8 |
Шаг 3. Пересчёт всех кластерных центров Z i
Z1 = (4; 1,5)
Z2 = (5; 2,5)
Z3 = (4,5; 8)
Шаг 4.
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | |
| Z11 | 3,2 | 2,7 | 6,6 | 5,5 | 7,6 | 6,8 | ||||
| Z21 | 3,35 | 2,5 | 5,85 | 4,6 | 6,5 | 1,8 | 5,6 | 2,5 | 3,4 | |
| Z31 | 3,5 | 4,7 | 4,3 | 1,5 | 1,1 | 1,1 | 7,2 | 1,5 | 7,4 | 7,8 |
Шаг 5.
| кластер | точки |
| X1, X2 | |
| X3, X7, X9, X10 | |
| X4, X5, X6, X8 |
Шаг 6.
Z12 = (2; 3)
Z22 = (6; 1,75)
Z32 = (4.5; 8)
Шаг 7.
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | |
| Z12 | 1,4 | 5,1 | 4,47 | 6,7 | 4,47 | 6,4 | 5,4 | 6,3 | ||
| Z22 | 4,6 | 3,75 | 6,9 | 5,6 | 7,1 | 0,75 | 6,25 | 1,25 | 2,1 | |
| Z32 | 6,5 | 4,7 | 4,3 | 1,5 | 1,1 | 1,1 | 7,2 | 1,5 | 7,4 | 7,8 |
Шаг 8.
| кластер | точки |
| X1, X2, X3 | |
| X7, X9, X10 | |
| X4, X5, X6, X8 |
Если проводить дальнейшее разбиение, центры кластеров изменяться не будут.
4. Алгоритм нечётких K-средних (fuzzy C-means clustering)
Алгоритм предложен американским учёным Bezdek.
Fuzzy ISODATA
 Твёрдые алгоритмы С-means (CM)
Твёрдые алгоритмы С-means (CM)
Hard C- means (HCM)
Основу алгоритма HCM составляет введение некоторой функции качества при заданных ограничениях.
Пусть U – матрица, определяющая принадлежность множества векторов X некоторым кластерам.
|
|
|
|
Дата добавления: 2014-01-15; Просмотров: 1190; Нарушение авторских прав?; Мы поможем в написании вашей работы!