КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Иерархическая модель
|
|
|
|
Даталогическая модель
Инфологическая модель должна быть отображена в даталогическую модель, «понятную» СУБД.
Даталогическая модель – описание на языке конкретной СУБД.
Сначала стали использовать иерархические даталогические модели. Эта модель представляет собой совокупность связанных элементов, образующих иерархическую структуру. К основным понятиям иерархии относятся уровень, узел и связь. Узлом называется совокупность атрибутов данных, описывающих некоторый объект. Каждый узел связан с одним узлом более высокого уровня и с любым количеством узлов нижнего уровня. Исключением является узел самого высокого уровня, который не связан ни с одним узлом более высокого уровня.
Количество деревьев в БД определяется количеством корней деревьев. К каждой записи БД существует единственный путь от корневой записи.
Примером иерархической модели данных может служить адрес. На первом уровне (корне дерева) лежит наша планета – Земля. На втором – страна. На третьем – регион (республика, край, район), затем – населенный пункт, улица, дом, квартира.
Еще один пример – это система доменных имен в Интернете.
Типичным представителем СУБД (наиболее известным и распространенным), основанной на иерархической модели, является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г.
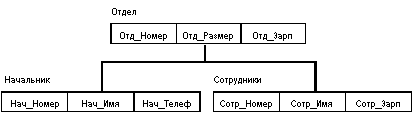
Рис. 5 Пример иерархической модели
ЗдесьОтдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники - потомки Отдел. Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом (мы показываем один экземпляр дерева):
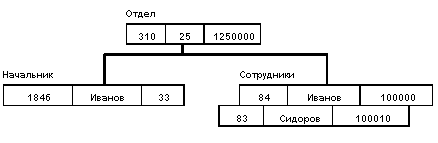
Рис. 6 Пример иерархической модели
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо.
1.2.2. Сетевая модель [3, 4]
В основе сетевой модели данных лежат те же понятия, что и в основе иерархической модели – узел, уровень и связь. Однако существенным различием является то, что в иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Сетевой подход к организации данных является расширением иерархического.
В сетевой модели данных любой объект может быть одновременно и главным, и подчиненным, и может участвовать в образовании любого числа взаимосвязей с другими объектами. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно - из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи (см. рис. 7).
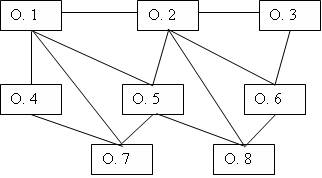
Рис. 7. Схема сетевой модели
Задание – нарисовать схему сетевой модели БД, в которой хранится информация о членстве ученых в научных организациях. Каждый ученый может состоять во множестве организаций. В свою очередь в одной организации может состоять множество ученых.
Сетевые модели также создавались для мало ресурсных ЭВМ. Это достаточно сложные структуры, состоящие из "наборов" – поименованных двухуровневых деревьев. "Наборы" соединяются с помощью "записей-связок", образуя цепочки и т.д. При разработке сетевых моделей было выдумано множество "маленьких хитростей", позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п.
Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем. Архитектура системы основана на предложениях Data Base Task Group (DBTG), Комитета по языкам программирования Conference on Data Systems Languages (CODASYL), организации, ответственной за определение языка программирования Кобол. Отчет DBTG был опубликован в 1971 г., а в 70-х годах появилось несколько систем, среди которых IDMS.
СУБД на основе инвертированных файлов [5]
Сложность практического использования иерархических и сетевых СУБД заставляла искать иные способы представления данных. В конце 60-х годов появились СУБД на основе инвертированных файлов, отличающиеся простотой организации и наличием весьма удобных языков манипулирования данными.
К числу наиболее известных и типичных представителей таких систем относятся Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на использование на машинах основного класса фирмы IBM, и Adabas компании Software AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам).
База данных, организованная с помощью инвертированных списков, похожа на реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям. При этом:
1. Строки таблиц упорядочены системой в некоторой физической последовательности.
2. Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB).
3. Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
Поддерживаются два класса операторов:
1. Операторы, устанавливающие адрес записи, среди которых:
1.1. прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа);
1.2. операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа.
2. Операторы над адресуемыми записями
Типичный набор операторов:
LOCATE FIRST - найти первую запись таблицы T в физическом порядке; возвращает адрес записи;
LOCATE FIRST WITH SEARCH KEY EQUAL - найти первую запись таблицы T с заданным значением ключа поиска K; возвращает адрес записи;
LOCATE NEXT - найти первую запись, следующую за записью с заданным адресом в заданном пути доступа; возвращает адрес записи;
LOCATE NEXT WITH SEARCH KEY EQUAL - найти cледующую запись таблицы T в порядке пути поиска с заданным значением K; должно быть соответствие между используемым способом сканирования и ключом K; возвращает адрес записи;
LOCATE FIRST WITH SEARCH KEY GREATER - найти первую запись таблицы T в порядке ключа поиска K cо значением ключевого поля, большим заданного значения K; возвращает адрес записи;
RETRIVE - выбрать запись с указанным адресом;
UPDATE - обновить запись с указанным адресом;
DELETE - удалить запись с указанным адресом;
STORE - включить запись в указанную таблицу; операция генерирует адрес записи.
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
Однако такие СУБД обладают рядом ограничений на количество файлов для хранения данных, количество связей между ними, длину записи и количество ее полей.
Пример
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 575; Нарушение авторских прав?; Мы поможем в написании вашей работы!