КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
|
|
|
|
Интерфейс с шиной ввода/вывода
Тактовые генераторы
Работа всех устройств видеоадаптера VGA синхронизируется сигналом Dot Clock или производными от него тактовыми сигналами. Частота сигнала Dot Clock равна верхней граничной частоте выходного видеосигнала. Кроме того, при заданном разрешении этой же частотой определяются значения частот строчной и кадровой синхронизации.
Синхронизация устройств стандартного видеоадаптера VGA в зависимости от выбранного видеорежима осуществляется тактовым сигналом, формируемым одним из двух встроенных генераторов сигналов фиксированных частот: 25,175 и 28,322 МГц. Кроме того, предусмотрена возможность использования внешнего тактового генератора (в первых видеоадаптерах VGA, интегрированных на материнскую плату). Выбор тактового генератора осуществляется программно.
Видеоадаптер VGA вставляется в 16-битный слот шины ввода/вывода ISA, поэтому он снабжен специальным интерфейсом, выполняющим следующие функции:
СЗ согласование разрядности внутренней 8-разрядной шины видеоадаптера VGA и 16-разрядной шины ISA компьютера;
О согласование частот тактовых сигналов видеоадаптера (Dot Clock) и шины ISA.
Современные видеоадаптеры подключаются к высокоскоростным шинам (РС1, AGP).
Значительное преимущество конвейерной обработки перед последовательной имеет место в идеальном конвейере, в котором отсутствуют конфликты и все команды выполняются друг за другом без перезагрузки конвейера. Наличие конфликтов снижает реальную производительность конвейера по сравнению с идеальным случаем.
Конфликты - это такие ситуации в конвейерной обработке, которые препятствуют выполнению очередной команды в предназначенном для нее такте.
Конфликты делятся на три группы:
- структурные,
- по управлению,
- по данным.
Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Причины структурных конфликтов.
- Не полностью конвейерная структура процессора, при которой некоторые ступени отдельных команд выполняются более одного такта.
Пусть этап выполнения команды i+1 занимает 3 такта. Тогда диаграмма работы конвейера будет иметь вид, представленный в таблица 3.8.
| Таблица 3.8. | |||||||||||
| Команда | Такт | ||||||||||
| i | IF | ID | OR | EX | WB | ||||||
| i+1 | IF | ID | OR | EX | EX | EX | WB | ||||
| i+2 | IF | ID | OR | O | O | EX | WB | ||||
| i+3 | IF | ID | OR | O | O | EX | |||||
| i+4 | IF | ID | OR | O | O |
При этом в работе конвейера возникают так называемые "пузыри" (обработка команд i+2 и следующих за ней, начиная с такта 6), которые снижают производительность процессора.
Эту ситуацию можно было бы ликвидировать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт. Однако при этом существенно снижается эффект конвейерной обработки, так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение данного этапа (например, использовать матричные схемы умножения). Но это приведет к усложнению схемы процессора и невозможности реализации на этой БИС других, функционально более важных, узлов. Так как представленная в таблица 3.8 ситуация возникает при реализации команд, относительно редко встречающихся в программе, то обычно разработчики процессоров ищут компромисс между увеличением длительности такта и усложнением того или иного устройства процессора.
- Недостаточное дублирование некоторых ресурсов.
Одним из типичных примеров служит конфликт из-за доступа к запоминающим устройствам. Из таблица 3.6 видно, что в случае, когда операнды и команды находятся в одном запоминающем устройстве, начиная с такта 3, работу конвейера придется постоянно приостанавливать, поскольку различные команды в одном и том же такте обращаются к памяти на считывание команды, выборку операнда, запись результата.
Борьба с конфликтами такого рода проводится путем увеличения количества однотипных функциональных устройств, которые могут одновременно выполнять одни и те же или схожие функции. Например, в современных микропроцессорах обычно разделяют кэш-память для хранения команд и кэш-память данных, а также используют многопортовую схему доступа к регистровой памяти, при которой к регистрам можно одновременно обращаться по одному каналу для записи, а по другому - для считывания информации. Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав микропроцессора дополнительных блоков. Так, в микропроцессоре Pentium-4 предусмотрено 4 АЛУ для обработки целочисленных данных. Процессоры, имеющие в своем составе более одного конвейера, называются суперскалярными.
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров. В таблица 3.9 представлена последовательность выполнения команд в микропроцессоре, имеющем два конвейера, при условии, что команде К1 требуется 3 такта на этапе EX.
| Таблица 3.9. | |||||||||||||||
| Этап | Такт | ||||||||||||||
| IF | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K7 | K9 | K7 | K10 | K11 | K12 | |
| ID | K1 | K2 | K3 | K4 | K5 | K6 | K5 | K8 | K5 | K9 | K7 | K10 | |||
| OR | K1 | K2 | K3 | K4 | K3 | K6 | K3 | K8 | K5 | K9 | |||||
| EX | K1 | K2 | K1 | K4 | K1 | K6 | K3 | K8 | |||||||
| WB | K2 | K4 | K1 | K6 |
При этом команды будут завершаться в последовательности
К2-К4-К1-К6-...
Следовательно, для обеспечения правильной работы суперскалярного микропроцессора при возникновении затора в одном из конвейеров должны приостанавливать свою работу и другие. В противном случае может нарушиться исходный порядок завершения команд программы. Но такие приостановки существенно снижают быстродействие процессора. Разрешение этой ситуации состоит в том, чтобы дать возможность выполняться командам в одном конвейере вне зависимости от ситуации в других конвейерах. Это приводит к неупорядоченному выполнению команд. При этом команды, стоящие в программе позже, могут завершиться ранее команд, стоящих впереди. Аппаратные средства микропроцессора должны гарантировать, что результаты выполненных команд будут записаны в приемник в том порядке, в котором команды записаны в программе. Для этого в микропроцессоре результаты этапа выполнения команды обычно сохраняются в специальном буфере восстановления последовательности команд. Запись результата очередной команды из этого буфера в приемник результата проводится лишь после того, как выполнены все предшествующие команды и записаны их результаты.
Конфликты по управлению возникают при конвейеризации команд переходов и других команд, изменяющих значение счетчика команд.
Суть конфликтов этой группы наиболее удобно проиллюстрировать на примере команд условного перехода. Пусть в программе, представленной в таблица 3.6, команда i+1 является командой условного перехода, формирующей адрес следующей команды в зависимости от результата выполнения команды i. Команда i завершит свое выполнение в такте 5. В то же время команда условного перехода уже в такте 3 должна прочитать необходимые ей признаки, чтобы правильно сформировать адрес следующей команды. Если конвейер имеет большую глубину (например, 20 ступеней), то промежуток времени между формированием признака результата и тактом, где он анализируется, может быть еще большим. В инженерных задачах примерно каждая шестая команда является командой условного перехода, поэтому приостановки конвейера при выполнении команд переходов до определения истинного направления перехода существенно скажутся на производительности процессора.
Наиболее эффективным методом снижения потерь от конфликтов по управлению служит предсказание переходов. Суть данного метода заключается в том, что при выполнении команды условного перехода специальный блок микропроцессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется. Процессор начинает выбирать из памяти и выполнять команды по предсказанной ветви программы (так называемое исполнение по предположению, или "спекулятивное" исполнение). Однако так как направление перехода может быть предсказано неверно, то получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап WB), а накапливаются в специальном буфере результатов.
Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения, а выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, то буфер результатов очищается. Также очищается и конвейер, содержащий команды, находящиеся на разных этапах обработки, следующие за командой условного перехода. При этом аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы. Так как конвейерная обработка эффективна при большом числе последовательно выполненных команд, то перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех микропроцессоров уделяют большое внимание.
Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается или программистом с помощью специальных средств, имеющихся в некоторых языках программирования, по опыту выполнения аналогичных программ либо результатам тестового выполнения программы, или программой-компилятором по заложенным в ней алгоритмам.
Методы динамического прогнозирования учитывают направления переходов, реализовывавшиеся этой командой при выполнении программы. Например, подсчитывается количество переходов, выполненных ранее по тому или иному направлению, и на основании этого определяется направление перехода при следующем выполнении данной команды.
В современных микропроцессорах вероятность правильного предсказания направления переходов достигает 90-95 %.
Конфликты по данным возникают в случаях, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
При обсуждении этих конфликтов будем предполагать, что команда i предшествует команде j.
Существует несколько типов конфликтов по данным.
- Конфликты типа RAW (Read After Write): команда j пытается прочитать операнд прежде, чем команда i запишет на это место свой результат. При этом команда j может получить некорректное старое значение операнда.
Проиллюстрируем этот тип конфликта на примере выполнения команд, представленных в таблица 3.6. Пусть выполняемые команды имеют следующий вид:
i) ADD R1,R2; R1 = R1+R2
i+1=j) SUB R3,R1; R3 = R3-R1
Команда i изменит состояние регистра R1 в такте 5. Но команда i+1 должна прочитать значение операнда R1 в такте 4. Если не приняты специальные меры, то из регистра R1 будет прочитано значение, которое было в нем до выполнения команды i.
Уменьшение влияния конфликта типа RAW обеспечивается методом обхода (продвижения) данных. В этом случае результаты, полученные на выходах исполнительных устройств, помимо входов приемника результата передаются также на входы всех исполнительных устройств микропроцессора. Если устройство управления обнаруживает, что данный результат требуется одной из последующих команд в качестве операнда, то он сразу же, параллельно с записью в приемник результата, передается на вход исполнительного устройства для использования следующей командой.
Конфликты типа RAW обусловлены именно конвейерной организацией обработки команд.
Главной причиной двух других типов конфликтов по данным является возможность неупорядоченного выполнения команд в современных микропроцессорах, то есть выполнение команд не в том порядке, в котором они записаны в программе.
- Конфликты типа WAR (Write After Read): команда j пытается записать результат в приемник, прежде чем он считается оттуда командой i, При этом команда i может получить некорректное новое значение операнда:
3. i) ADD R1,R2
i+1 =j) SUB R2,R3
Этот конфликт возникнет в случае, если команда j вследствие неупорядоченного выполнения завершится раньше, чем команда i прочитает старое содержимое регистра R2.
- Конфликты типа WAW (Write After Write): команда j пытается записать результат в приемник, прежде чем в этот же приемник будет записан результат выполнения команды i, то есть запись заканчивается в неверном порядке, оставляя в приемнике результата значение, записанное командой i:
5. i) ADD R1,R2
6....
j) SUB R1,R3
Устранение конфликтов по данным типов WAR и WAW достигается путем отказа от неупорядоченного исполнения команд, но чаще всего путем введения буфера восстановления последовательности команд.
Как отмечалось выше, наличие конфликтов приводит к значительному снижению производительности микропроцессора. Определенные типы конфликтов требуют приостановки конвейера. При этом останавливается выполнение всех команд, находящихся на различных стадиях обработки (до 20 ти команд в Pentium-4). Другие конфликты, например, при неверном предсказанном направлении перехода, ведут к необходимости полной перезагрузки конвейера. Потери будут тем больше, чем более длинный конвейер используется в микропроцессоре. Такая ситуация явилась одной из причин сокращения числа ступеней в микропроцессорах последних моделей. Так, в микропроцессоре Itanium конвейер содержит всего 10 ступеней. При этом его тактовая частота составляет около 1 МГц [[2]]. Однако на каждой ступени выполняется больше функциональных действий, чем в Pentium-4.




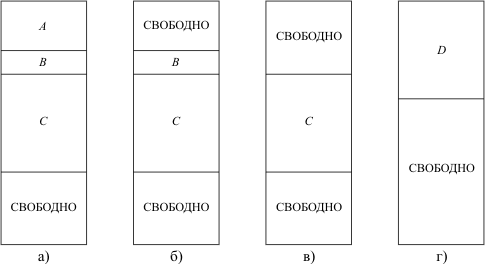 Рис. 4.1. Статическое распределение памяти:a - начальное распределение; б - после завершения программы A;в - после завершения программы B; г - после завершения программы C
Из рисунка видно, что программа D при статическом распределении памяти может быть загружена в оперативную память лишь после завершения выполнения всех предыдущих программ, хотя необходимый для нее объем памяти существовал уже после завершения работы программы A. В то же время для улучшения показателей работы мультипрограммной ЭВМ требуется, чтобы в оперативной памяти постоянно находилось возможно большее количество программ, готовых к выполнению.
Данную проблему можно частично решить перераспределением памяти после завершения выполнения каждой программы с целью формирования единого свободного участка, который может быть выделен новой программе, поступающей на обработку (дефрагментация памяти). Однако это требует трудоемкой работы системных средств и практически не используется.
Современные системы распределения памяти опираются на две концепции: динамического использования ресурсов и виртуализации.
При динамическом распределении памяти каждой программе в начальный момент выделяется лишь часть от всей необходимой ей памяти, а остальная часть выделяется по мере возникновения реальной потребности в ней.Такой подход базируется на следующих предпосылках.
Во-первых, при каждом конкретном исполнении в зависимости от исходных данных некоторые части программы (до 25% ее длины) вообще не используются. Следует стремиться к тому, чтобы эти фрагменты кода не загружались в ОП.
Во-вторых, исполнение программы характеризуется так называемым принципом локальности ссылок. Он подразумевает, что при исполнении программы в течение некоторого относительно малого интервала времени происходит обращение к памяти в пределах ограниченного диапазона адресов (как по коду программы, так и по данным). Следовательно, на протяжении этого времени нет необходимости хранить в ОП другие блоки программы.
При этом системные средства должны отслеживать возникновение требований на обращение к тем частям программы, которые в данный момент отсутствуют в ОЗУ, выделять этой программе необходимый блок памяти и помещать туда из внешнего ЗУ требуемую часть программы. Для этого может потребоваться предварительное перемещение некоторых блоков информации из ОЗУ во внешнюю память. Данные перемещения должны быть скрыты от пользователя и в наименьшей степени замедлять работу его программы.
Перемещение блоков информации из ОЗУ во внешнюю память с целью освобождения места для новой информации происходит обычно по одному из следующих алгоритмов:
LRU (least recently used) - наиболее давно не использовавшийся;
FIFO - самый давний по пребыванию в ОЗУ;
Random - случайным образом.
Динамическое распределение памяти тесно переплетается с понятием виртуальной памяти.
Принцип виртуальной памяти предполагает, что пользователь при подготовке своей программы имеет дело не с физической ОП, действительно работающей в составе компьютера и имеющей некоторую фиксированную емкость, а с виртуальной (кажущейся) одноуровневой памятью, емкость которой равна всему адресному пространству, определяемому размером адресной шины (Lша) компьютера:
Vвирт >> Vфиз,
Vвирт = 2Lша.
Для персональной ЭВМ на основе 32-разрядных микропроцессоров
Vвирт= 232 = 4 Гбайт.
При этом, естественно, в ЭВМ должен быть обеспечен достаточный объем внешней памяти для хранения всех программ, обрабатываемых на компьютере.
Программист имеет в своем распоряжении адресное пространство, ограниченное лишь разрядностью адресной шины, независимо от общего объема оперативной памяти компьютера и объемов памяти, используемых другими программами, параллельно обрабатываемыми в мультипрограммной ЭВМ.
Виртуальная память, обеспечивая возможность программисту обращаться к очень большому объему непрерывного адресного пространства, предоставляемого в его монопольное распоряжение, обладает обычными свойствами: побайтовая адресация, время доступа, сравнимое со временем доступа к оперативной памяти.
На всех этапах подготовки программ, включая загрузку в оперативную память, программа представляется в виртуальных адресах, и лишь при выполнении машинной команды виртуальные адреса преобразуются в физические. Для каждой программы, выполняемой в мультипрограммном режиме, создается своя виртуальная память. Каждая программа использует одни и те же виртуальные адреса от нулевого до максимально большого в данной архитектуре.
Для преобразования виртуальных адресов в физические физическая и виртуальная память разбиваются на блоки фиксированной длины, называемые страницами. Объемы виртуальной и физической страниц совпадают. Страницы виртуальной и физической памяти нумеруются.
Виртуальный (логический) адрес в этом случае представляет собой номер виртуальной страницы и смещение внутри этой страницы.В свою очередь, физический адрес - это номер физической страницы и смещение в ней.
Вначале в ОП загружается первая страница программы и ей передается управление. Когда в ходе выполнения программы происходит обращение за пределы загруженной страницы, операционная система прерывает выполнение данной программы, загружает требуемую страницу в ОП, после чего передает управление прерванной программе.
Правила перевода номеров виртуальных страниц в номера физических страниц обычно задаются в виде таблицы страничного преобразования. Такие таблицы формируются системой управления памятью и модифицируются каждый раз при перераспределении памяти.
Перевод виртуальных адресов в физические проиллюстрирован на рис. 4.2.
Рис. 4.1. Статическое распределение памяти:a - начальное распределение; б - после завершения программы A;в - после завершения программы B; г - после завершения программы C
Из рисунка видно, что программа D при статическом распределении памяти может быть загружена в оперативную память лишь после завершения выполнения всех предыдущих программ, хотя необходимый для нее объем памяти существовал уже после завершения работы программы A. В то же время для улучшения показателей работы мультипрограммной ЭВМ требуется, чтобы в оперативной памяти постоянно находилось возможно большее количество программ, готовых к выполнению.
Данную проблему можно частично решить перераспределением памяти после завершения выполнения каждой программы с целью формирования единого свободного участка, который может быть выделен новой программе, поступающей на обработку (дефрагментация памяти). Однако это требует трудоемкой работы системных средств и практически не используется.
Современные системы распределения памяти опираются на две концепции: динамического использования ресурсов и виртуализации.
При динамическом распределении памяти каждой программе в начальный момент выделяется лишь часть от всей необходимой ей памяти, а остальная часть выделяется по мере возникновения реальной потребности в ней.Такой подход базируется на следующих предпосылках.
Во-первых, при каждом конкретном исполнении в зависимости от исходных данных некоторые части программы (до 25% ее длины) вообще не используются. Следует стремиться к тому, чтобы эти фрагменты кода не загружались в ОП.
Во-вторых, исполнение программы характеризуется так называемым принципом локальности ссылок. Он подразумевает, что при исполнении программы в течение некоторого относительно малого интервала времени происходит обращение к памяти в пределах ограниченного диапазона адресов (как по коду программы, так и по данным). Следовательно, на протяжении этого времени нет необходимости хранить в ОП другие блоки программы.
При этом системные средства должны отслеживать возникновение требований на обращение к тем частям программы, которые в данный момент отсутствуют в ОЗУ, выделять этой программе необходимый блок памяти и помещать туда из внешнего ЗУ требуемую часть программы. Для этого может потребоваться предварительное перемещение некоторых блоков информации из ОЗУ во внешнюю память. Данные перемещения должны быть скрыты от пользователя и в наименьшей степени замедлять работу его программы.
Перемещение блоков информации из ОЗУ во внешнюю память с целью освобождения места для новой информации происходит обычно по одному из следующих алгоритмов:
LRU (least recently used) - наиболее давно не использовавшийся;
FIFO - самый давний по пребыванию в ОЗУ;
Random - случайным образом.
Динамическое распределение памяти тесно переплетается с понятием виртуальной памяти.
Принцип виртуальной памяти предполагает, что пользователь при подготовке своей программы имеет дело не с физической ОП, действительно работающей в составе компьютера и имеющей некоторую фиксированную емкость, а с виртуальной (кажущейся) одноуровневой памятью, емкость которой равна всему адресному пространству, определяемому размером адресной шины (Lша) компьютера:
Vвирт >> Vфиз,
Vвирт = 2Lша.
Для персональной ЭВМ на основе 32-разрядных микропроцессоров
Vвирт= 232 = 4 Гбайт.
При этом, естественно, в ЭВМ должен быть обеспечен достаточный объем внешней памяти для хранения всех программ, обрабатываемых на компьютере.
Программист имеет в своем распоряжении адресное пространство, ограниченное лишь разрядностью адресной шины, независимо от общего объема оперативной памяти компьютера и объемов памяти, используемых другими программами, параллельно обрабатываемыми в мультипрограммной ЭВМ.
Виртуальная память, обеспечивая возможность программисту обращаться к очень большому объему непрерывного адресного пространства, предоставляемого в его монопольное распоряжение, обладает обычными свойствами: побайтовая адресация, время доступа, сравнимое со временем доступа к оперативной памяти.
На всех этапах подготовки программ, включая загрузку в оперативную память, программа представляется в виртуальных адресах, и лишь при выполнении машинной команды виртуальные адреса преобразуются в физические. Для каждой программы, выполняемой в мультипрограммном режиме, создается своя виртуальная память. Каждая программа использует одни и те же виртуальные адреса от нулевого до максимально большого в данной архитектуре.
Для преобразования виртуальных адресов в физические физическая и виртуальная память разбиваются на блоки фиксированной длины, называемые страницами. Объемы виртуальной и физической страниц совпадают. Страницы виртуальной и физической памяти нумеруются.
Виртуальный (логический) адрес в этом случае представляет собой номер виртуальной страницы и смещение внутри этой страницы.В свою очередь, физический адрес - это номер физической страницы и смещение в ней.
Вначале в ОП загружается первая страница программы и ей передается управление. Когда в ходе выполнения программы происходит обращение за пределы загруженной страницы, операционная система прерывает выполнение данной программы, загружает требуемую страницу в ОП, после чего передает управление прерванной программе.
Правила перевода номеров виртуальных страниц в номера физических страниц обычно задаются в виде таблицы страничного преобразования. Такие таблицы формируются системой управления памятью и модифицируются каждый раз при перераспределении памяти.
Перевод виртуальных адресов в физические проиллюстрирован на рис. 4.2.
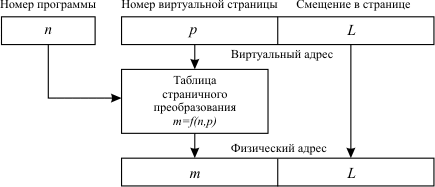 Рис. 4.2. Преобразование виртуального адреса в физический
Рассмотрим пример преобразования адреса виртуальной страницы в адрес физической страницы. Пусть компьютер имеет оперативную память VОЗУ=3 и адресное пространство, предполагающее разбиение на страницы объемом Vстр=1. Каждая программа, в свою очередь, разбивается на виртуальные страницы того же объема. Пусть коэффициент мультипрограммирования данной ЭВМ равен четырем, то есть на компьютере могут одновременно выполняться до четырех программ. Переключение между программами происходит через tk = 1. Время выполнения каждой страницы любой программы составляет t = 2tk. Полагаем, что страницы программ загружаются в оперативную память по мере их необходимости и, по возможности, в свободные области ОЗУ. Если вся память занята, то новая страница замещает ту, к которой дольше всего не было обращений (механизм замещения LRU). Пусть выполняемые программы имеют следующее количество страниц: VA=2, VB=1, VC=3, VD=2. Тогда таблица загрузки оперативной памяти и таблицы страничного преобразования для каждой программы будут иметь следующий вид:
Рис. 4.2. Преобразование виртуального адреса в физический
Рассмотрим пример преобразования адреса виртуальной страницы в адрес физической страницы. Пусть компьютер имеет оперативную память VОЗУ=3 и адресное пространство, предполагающее разбиение на страницы объемом Vстр=1. Каждая программа, в свою очередь, разбивается на виртуальные страницы того же объема. Пусть коэффициент мультипрограммирования данной ЭВМ равен четырем, то есть на компьютере могут одновременно выполняться до четырех программ. Переключение между программами происходит через tk = 1. Время выполнения каждой страницы любой программы составляет t = 2tk. Полагаем, что страницы программ загружаются в оперативную память по мере их необходимости и, по возможности, в свободные области ОЗУ. Если вся память занята, то новая страница замещает ту, к которой дольше всего не было обращений (механизм замещения LRU). Пусть выполняемые программы имеют следующее количество страниц: VA=2, VB=1, VC=3, VD=2. Тогда таблица загрузки оперативной памяти и таблицы страничного преобразования для каждой программы будут иметь следующий вид:
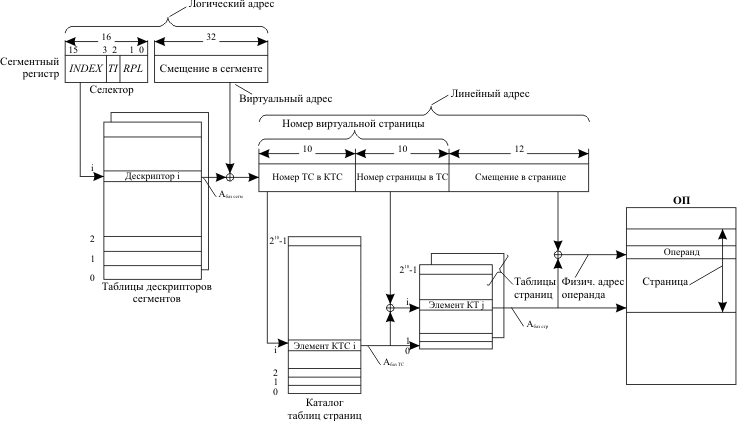 Рис. 4.3. Формирование физического адреса при сегментно-страничной организация памяти в 32-разрядном микропроцессоре
Основой получения физического адреса, выдаваемого на адресную шину микропроцессора, служит логический адрес. Он состоит из двух частей: селектора, являющегося идентификатором сегмента, и смещения в сегменте.
Смещение в сегменте (32 разряда) (эффективный адрес) вычисляется по задаваемому в команде режиму адресации операнда и является виртуальным адресом операнда. При обращении к команде в качестве смещения выступает значение регистра-указателя команд.
Селектор размещается в сегментном регистре (см. рис. 4.3). Основная его часть представляет собой номер (INDEX), по которому в одной из специальных таблиц дескрипторов можно найти дескриптор (описатель) данного сегмента. Вид используемой таблицы определяется битом TI (table indicator) селектора. Селектор содержит также двухразрядное поле RPL, используемое при организации защиты памяти по привилегиям.
Дескриптор (рис. 4.4) содержит сведения о сегменте. В одном из его полей содержится базовый адрес сегмента. В остальных полях записана дополнительная информация о сегменте: длина, допустимый уровень прав доступа к данному сегменту с целью защиты находящейся в нем информации, тип сегмента (сегмент кода, сегмент данных, специальный системный сегмент и т.д.) и некоторые другие атрибуты.
Рис. 4.3. Формирование физического адреса при сегментно-страничной организация памяти в 32-разрядном микропроцессоре
Основой получения физического адреса, выдаваемого на адресную шину микропроцессора, служит логический адрес. Он состоит из двух частей: селектора, являющегося идентификатором сегмента, и смещения в сегменте.
Смещение в сегменте (32 разряда) (эффективный адрес) вычисляется по задаваемому в команде режиму адресации операнда и является виртуальным адресом операнда. При обращении к команде в качестве смещения выступает значение регистра-указателя команд.
Селектор размещается в сегментном регистре (см. рис. 4.3). Основная его часть представляет собой номер (INDEX), по которому в одной из специальных таблиц дескрипторов можно найти дескриптор (описатель) данного сегмента. Вид используемой таблицы определяется битом TI (table indicator) селектора. Селектор содержит также двухразрядное поле RPL, используемое при организации защиты памяти по привилегиям.
Дескриптор (рис. 4.4) содержит сведения о сегменте. В одном из его полей содержится базовый адрес сегмента. В остальных полях записана дополнительная информация о сегменте: длина, допустимый уровень прав доступа к данному сегменту с целью защиты находящейся в нем информации, тип сегмента (сегмент кода, сегмент данных, специальный системный сегмент и т.д.) и некоторые другие атрибуты.
 Рис. 4.4. Структура дескриптора сегмента
Сумма полученного из дескриптора базового адреса сегмента и вычисленного смещения дает линейный адрес операнда, который при включенном механизме страничного преобразования представляет собой номер виртуальной страницы (старшие 20 разрядов) и смещение операнда в странице (младшие 12 разрядов линейного адреса в соответствии с объемом страницы в 4 Кбайт).
При преобразовании номера виртуальной страницы в номер физической используются следующие системные объекты: каталог таблиц страниц (КТС) и таблицы страниц (ТС). Структуры этих таблиц сходны между собой (рис. 4.5).
Рис. 4.4. Структура дескриптора сегмента
Сумма полученного из дескриптора базового адреса сегмента и вычисленного смещения дает линейный адрес операнда, который при включенном механизме страничного преобразования представляет собой номер виртуальной страницы (старшие 20 разрядов) и смещение операнда в странице (младшие 12 разрядов линейного адреса в соответствии с объемом страницы в 4 Кбайт).
При преобразовании номера виртуальной страницы в номер физической используются следующие системные объекты: каталог таблиц страниц (КТС) и таблицы страниц (ТС). Структуры этих таблиц сходны между собой (рис. 4.5).
 Рис. 4.5. Элемент каталога таблиц страниц (таблицы страниц)
Преобразование проводится в два этапа.
Сначала по разрядам А31-А22 линейного адреса в КТС выбирается нужный элемент. Каталог таблиц страниц всегда присутствует в ОП и содержит указания по размещению таблицы страниц, относящейся к тому или иному процессу.
Элемент КТС содержит
Рис. 4.5. Элемент каталога таблиц страниц (таблицы страниц)
Преобразование проводится в два этапа.
Сначала по разрядам А31-А22 линейного адреса в КТС выбирается нужный элемент. Каталог таблиц страниц всегда присутствует в ОП и содержит указания по размещению таблицы страниц, относящейся к тому или иному процессу.
Элемент КТС содержит
 Рис. 4.6. Сохранение дескрипторов сегментов в "теневых" регистрах микропроцессора
При страничном преобразовании номера виртуальной страницы в номер физической страницы используется кэш-буфер ассоциативной трансляции (TLB), содержащий физические адреса 32-х наиболее активно используемых страниц (рис. 4.7) и расположенный непосредственно в микропроцессоре.
Рис. 4.6. Сохранение дескрипторов сегментов в "теневых" регистрах микропроцессора
При страничном преобразовании номера виртуальной страницы в номер физической страницы используется кэш-буфер ассоциативной трансляции (TLB), содержащий физические адреса 32-х наиболее активно используемых страниц (рис. 4.7) и расположенный непосредственно в микропроцессоре.
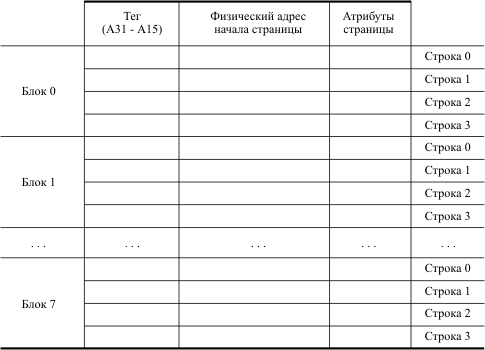 Рис. 4.7. Формат буфера ассоциативной трансляции адреса страницы
Номер виртуальной страницы представляет собой старшие 20 разрядов линейного адреса, полученного при сегментном преобразовании (А31 - А12). По младшим разрядам (А14 - А12) этого номера выбирается блок в буфере ассоциативной трансляции. Содержимое поля тэгов каждой из четырех строк этого блока ассоциативным образом (одновременно) сравнивается с разрядами (А31 - А15) линейного адреса. Если значения для одной из строк выбранного блока совпали, значит, номер этой виртуальной страницы уже преобразовывался в номер физической страницы и результат этого преобразования находится в найденной строке TLB. Если сравнение не было успешным, то преобразование номера виртуальной страницы в номер физической проходит обычным образом через обращения к каталогу таблиц страниц и к таблице страниц, а полученное значение заносится в TLB. При этом в поле тэгов заносятся старшие 17 разрядов линейного адреса этой страницы (A31-A15). Если нет свободной строки в блоке, определяемом разрядами А14 - А12 линейного адреса, то из блока вытесняется строка, информация в которой дольше всего не использовалась (механизм LRU).
Рис. 4.7. Формат буфера ассоциативной трансляции адреса страницы
Номер виртуальной страницы представляет собой старшие 20 разрядов линейного адреса, полученного при сегментном преобразовании (А31 - А12). По младшим разрядам (А14 - А12) этого номера выбирается блок в буфере ассоциативной трансляции. Содержимое поля тэгов каждой из четырех строк этого блока ассоциативным образом (одновременно) сравнивается с разрядами (А31 - А15) линейного адреса. Если значения для одной из строк выбранного блока совпали, значит, номер этой виртуальной страницы уже преобразовывался в номер физической страницы и результат этого преобразования находится в найденной строке TLB. Если сравнение не было успешным, то преобразование номера виртуальной страницы в номер физической проходит обычным образом через обращения к каталогу таблиц страниц и к таблице страниц, а полученное значение заносится в TLB. При этом в поле тэгов заносятся старшие 17 разрядов линейного адреса этой страницы (A31-A15). Если нет свободной строки в блоке, определяемом разрядами А14 - А12 линейного адреса, то из блока вытесняется строка, информация в которой дольше всего не использовалась (механизм LRU).
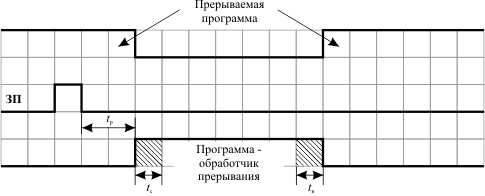 Рис. 5.1. Выполнение прерывания в компьютере: tр - время реакции процессора на запрос прерывания; tс - время сохранения состояния прерываемой программы и вызова обработчика прерывания; tв - время восстановления прерванной программы
После появления сигнала запроса прерывания ЭВМ переходит к выполнению программы - обработчика прерывания. Обработчик выполняет те действия, которые необходимы в связи с возникшей особой ситуацией. Например, такой ситуацией может быть нажатие клавиши на клавиатуре компьютера. Тогда обработчик должен передать код нажатой клавиши из контроллера клавиатуры в процессор и, возможно, проанализировать этот код. По окончании работы обработчика управление передается прерванной программе.
Время реакции - это время между появлением сигнала запроса прерывания и началом выполнения прерывающей программы (обработчика прерывания) в том случае, если данное прерывание разрешено к обслуживанию.
Время реакции зависит от момента, когда процессор определяет факт наличия запроса прерывания. Опрос запросов прерываний может проводиться либо по окончании выполнения очередного этапа команды (например, считывание команды, считывание первого операнда и т.д.), либо после завершения каждой команды программы.
Первый подход обеспечивает более быструю реакцию, но при этом необходимо при переходе к обработчику прерывания сохранять большой объем информации о прерываемой программе, включающей состояние буферных регистров процессора, номера завершившегося этапа и т.д. При возврате из обработчика также необходимо выполнить большой объем работы по восстановлению состояния процессора.
Во втором случае время реакции может быть достаточно большим. Однако при переходе к обработчику прерывания требуется запоминание минимального контекста прерываемой программы (обычно это счетчик команд и регистр флагов). В настоящее время в компьютерах чаще используется распознавание запроса прерывания после завершения очередной команды.
Время реакции определяется для запроса с наивысшим приоритетом.
Глубина прерывания - максимальное число программ, которые могут прерывать друг друга. Глубина прерывания обычно совпадает с числом уровней приоритетов, распознаваемых системой прерываний. Работа системы прерываний при различной глубине прерываний (n) представлена на рис. 5.2. Здесь предполагается, что с увеличением номера запроса прерывания увеличивается его приоритет.
Рис. 5.1. Выполнение прерывания в компьютере: tр - время реакции процессора на запрос прерывания; tс - время сохранения состояния прерываемой программы и вызова обработчика прерывания; tв - время восстановления прерванной программы
После появления сигнала запроса прерывания ЭВМ переходит к выполнению программы - обработчика прерывания. Обработчик выполняет те действия, которые необходимы в связи с возникшей особой ситуацией. Например, такой ситуацией может быть нажатие клавиши на клавиатуре компьютера. Тогда обработчик должен передать код нажатой клавиши из контроллера клавиатуры в процессор и, возможно, проанализировать этот код. По окончании работы обработчика управление передается прерванной программе.
Время реакции - это время между появлением сигнала запроса прерывания и началом выполнения прерывающей программы (обработчика прерывания) в том случае, если данное прерывание разрешено к обслуживанию.
Время реакции зависит от момента, когда процессор определяет факт наличия запроса прерывания. Опрос запросов прерываний может проводиться либо по окончании выполнения очередного этапа команды (например, считывание команды, считывание первого операнда и т.д.), либо после завершения каждой команды программы.
Первый подход обеспечивает более быструю реакцию, но при этом необходимо при переходе к обработчику прерывания сохранять большой объем информации о прерываемой программе, включающей состояние буферных регистров процессора, номера завершившегося этапа и т.д. При возврате из обработчика также необходимо выполнить большой объем работы по восстановлению состояния процессора.
Во втором случае время реакции может быть достаточно большим. Однако при переходе к обработчику прерывания требуется запоминание минимального контекста прерываемой программы (обычно это счетчик команд и регистр флагов). В настоящее время в компьютерах чаще используется распознавание запроса прерывания после завершения очередной команды.
Время реакции определяется для запроса с наивысшим приоритетом.
Глубина прерывания - максимальное число программ, которые могут прерывать друг друга. Глубина прерывания обычно совпадает с числом уровней приоритетов, распознаваемых системой прерываний. Работа системы прерываний при различной глубине прерываний (n) представлена на рис. 5.2. Здесь предполагается, что с увеличением номера запроса прерывания увеличивается его приоритет.
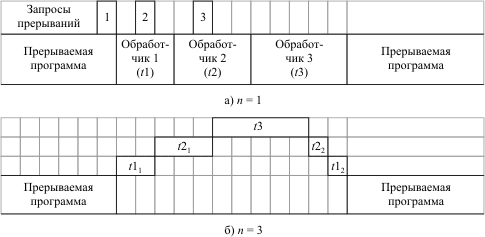 Рис. 5.2. Работа системы прерываний при различной глубине прерываний
Без учета времени реакции, а также времени запоминания и времени восстановления:
t11+t12=t1,t21+t22=t2. Прерывания делятся на аппаратные и программные [[4]]
Аппаратныепрерывания используются для организации взаимодействия с внешними устройствами. Запросы аппаратных прерываний поступают на специальные входы микропроцессора. Они бывают:
Рис. 5.2. Работа системы прерываний при различной глубине прерываний
Без учета времени реакции, а также времени запоминания и времени восстановления:
t11+t12=t1,t21+t22=t2. Прерывания делятся на аппаратные и программные [[4]]
Аппаратныепрерывания используются для организации взаимодействия с внешними устройствами. Запросы аппаратных прерываний поступают на специальные входы микропроцессора. Они бывают:
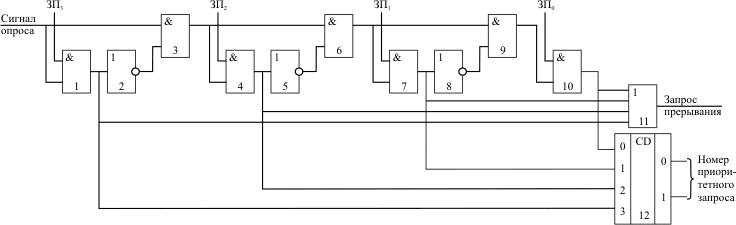 Рис. 5.3. Схема определения номера наиболее приоритетного запроса прерывания
Обработка прерываний в персональной ЭВМ
Микропроцессоры типа х86 имеют два входа запросов внешних аппаратных прерываний:
Рис. 5.3. Схема определения номера наиболее приоритетного запроса прерывания
Обработка прерываний в персональной ЭВМ
Микропроцессоры типа х86 имеют два входа запросов внешних аппаратных прерываний:
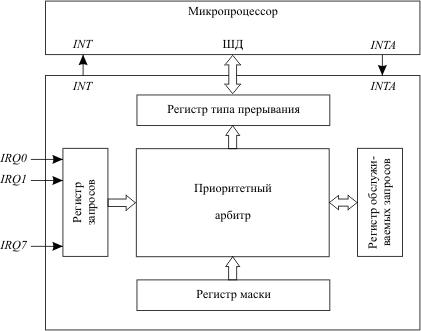 Рис. 5.4. Структура контроллера приоритетных прерываний
Единственный вход запроса маскируемых прерываний микропроцессора не позволяет подключить к нему напрямую сигналы запросов от большого числа различных внешних устройств, которые входят в состав современного компьютера: таймера, клавиатуры, "мыши", принтера, сетевой карты и т.д. Для их подключения к одному входу INT микропроцессора используется контроллер приоритетных прерываний (рис. 5.4). Его функции:
Рис. 5.4. Структура контроллера приоритетных прерываний
Единственный вход запроса маскируемых прерываний микропроцессора не позволяет подключить к нему напрямую сигналы запросов от большого числа различных внешних устройств, которые входят в состав современного компьютера: таймера, клавиатуры, "мыши", принтера, сетевой карты и т.д. Для их подключения к одному входу INT микропроцессора используется контроллер приоритетных прерываний (рис. 5.4). Его функции:
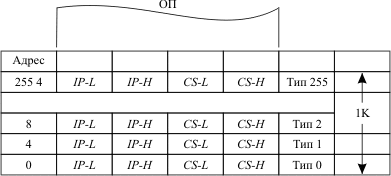 Рис. 5.5. Структура таблицы векторов прерываний
Обращение к элементам таблицы осуществляется по 8-разрядному коду - типу прерывания (таблица 5.1).
Рис. 5.5. Структура таблицы векторов прерываний
Обращение к элементам таблицы осуществляется по 8-разрядному коду - типу прерывания (таблица 5.1).