КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Шина USB
|
|
|
|
Шины PCI и PCI Express подходят для соединения высокоскоростных периферийных устройств, но использовать интерфейс PCI для низкоскоростных устройств ввода-вывода (например, мыши и клавиатуры) неэффективно.
Кроме того, для добавления новых устройств использовались свободные ISA- и PCI-слоты, в которые вставлялись платы контроллеров УВВ.
При этом пользователь должен сам установить переключатели и перемычки на, затем должен открыть системный блок, вставить плату, закрыть системный блок и включить компьютер.
Для многих этот процесс очень сложен и часто приводит к ошибкам. Кроме того, количество ISA- и PCI-слотов очень мало (обычно два или три).
В 1993 году представители семи компаний (Compaq, DEC, IBM, Intel, Microsoft, NEC и Nothern Telecom) разработали шину, оптимально подходящую для подсоединения низкоскоростных устройств.
Результатом их работы стала шина USB (Universal Serial Bus — универсальная последовательная шина), удовлетворяющую следующим требованиям:
- пользователи не должны устанавливать переключатели и перемычки на платах и устройствах;
- пользователи не должны открывать компьютер, чтобы установить новые устройства ввода-вывода;
- должен существовать только один тип кабеля, подходящий для соединения всех устройств;
- устройства ввода-вывода должны получать питание через кабель;
- должна быть возможность подсоединения к одному компьютеру до 127 устройств;
- система должна поддерживать устройства реального времени (например,
звуковые устройства, телефон); - должна быть возможность устанавливать устройства во время работы компьютера;
- должна отсутствовать необходимость перезагружать компьютер после установки нового устройства;
- производство новой шины и устройств ввода-вывода для нее не должно требовать больших затрат.
Общая пропускная способность первой версии шины (USB 1.0) составляет 12 Мбит/с.
Версия 2.0 работает на скорости 480 Мбит/с что вполне достаточно для принтеров, цифровых камер и многих других устройств. Предел был выбран для того, чтобы снизить стоимость шипы.
Версия USB 3.0 повышает максимальную скорость передачи информации до 5 Гбит/с — что на порядок больше USB 2.0 (480 Мбит/с). Таким образ, скорость передачи возрастает с 60 Мбайт/с до 600 Мбайт/с
Шина USB состоит из корневого хаба (root hub), который вставляется в разъем главной шины (см, рис. 3.49). Этот корневой хаб (часто называемый корневым концентратором) содержит разъемы для кабелей, которые могут подсоединяться к устройствам ввода-вывода или к дополнительным хабам, чтобы увеличить количество разъемов.
Таким образом, топология шины USB представляет собой дерево с корнем в корневом хабе, который находится внутри компьютера.
Коннекторы (разъемы) кабеля со стороны устройства отличаются от коннекторов со стороны хаба, чтобы пользователь случайно не подсоединил кабель другой стороной.
Кабель состоит из четырех проводов: два из них предназначены для передачи данных, один — для питания (+5 В) и один — для земли. Система передает 0 изменением напряжения, а 1 — отсутствием изменения напряжения» поэтому длинная последовательность нулевых битов порождает поток регулярных импульсов.
Когда соединяется новое устройство ввода-вывода, корневой хаб обнаруживает этот факт и прерывает работу операционной системы.
Затем операционная система запрашивает новое устройство» выясняя, что оно собой представляет и какая пропускная способность шины для него требуется.
Если операционная система решает, что для этого устройства пропускной способности достаточно, она приписывает ему уникальный адрес (1-127) и загружает этот адрес и другую информацию в конфигурационные регистры внутри устройства.
Таким образом, новые устройства могут подсоединяться *ша лету», при этом пользователю не нужно устанавливать новые платы ISA или PCI.
Неинициализированные платы начинаются с адреса 0, поэтому к ним можно обращаться. Многие устройства снабжены встроенными сетевыми концентраторами для дополнительных устройств. Например, монитор может содержать два хаба для правой и левой колонок.
Шипа USB представляет собой ряд каналов между корневым хабом и устройствами ввода-вывода. Каждое устройство может разбить свой канал максимум на 16 подканалов для различных типов данных (например, аудио и видео).
В каждом канале или подканале данные перемещаются от корневого хаба к устройству и обратно- Между двумя устройствами ввода-вывода обмена информацией не происходит.
Ровно через каждую миллисекунду (±0,05 мс) корневой хаб передает новый кадр, чтобы синхронизировать все устройства во времени. Кадр состоит из пакетов, первый из которых передается от хаба к устройству. Следующие пакеты кадра могут передаваться в том же направлении, а могут и в противоположном (от устройства к хабу). На рис. 3,55 показаны четыре последовательных кадра.
В 1998 году была создана высокоскоростная версии USB, названной USB 2.0. Этот стандарт во многом аналогичен USB 1A и совместим с ним, однако к двум прежним скоростям в нем добавляется новая — 480 Мбайт/с.
3 Организации памяти в ЭВМ
3.1 Иерархическая организация памяти и принцип локальности ссылок
Память — совокупность устройств, служащих для приема, хранения и выдачи данных в центральный процессор или внешнюю среду компьютера. Основные операции с памятью — запись и чтение.
В вычислительных системах память является одним из основных компонентов, определяющим как быстродействие, так и функциональные возможности всей системы.
Организация памяти имеет сложный характер и строится по иерархическому принципу. Основная идея иерархии памяти - согласование скоростей работы операционных устройств, в первую очередь процессора, с запоминающими устройствами.
Иерархическая организация памяти имеет вид, представленный на рис. 3.1, где показаны диапазоны значений емкости и производительности устройств памяти для современных компьютеров.
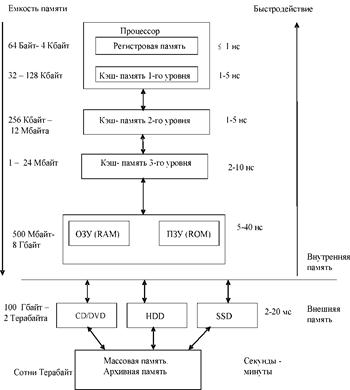 |
Р и с. 3.1. Иерархическая организация памяти
ОЗУ - оперативное запоминающее устройство;
ПЗУ - постоянное запоминающее устройство;
CD/DVD - накопитель на оптических дисках;
HDD (Hard Disk Drive) - накопитель на жестком магнитном диске;
SSD (Solid State Drive) - накопитель на«твердом» диске
На рис. 3.1 видно, что на более высоких уровнях иерархии расположены устройства с меньшей емкостью памяти, но с большим быстродействием.
Регистровая память или регистровый файл изготавливается в кристалле процессора по такой же технологии и имеет такое же быстродействие, как и операционные элементы процессора.
Кэш-память первого уровня также выполняется внутри процессора, что дает возможность обращения к командам и данным с тактовой частотой работы процессора.
Во многих моделях процессоров кэш- память второго уровня интегрирована в ядро процессора.
Кэш-память третьего уровня выполняется в виде отдельной микросхемы с высоким быстродействием, либо в процессоре, как в архитектуре Nehalem.
Эффективность иерархической организации связана с важнейшим принципом локальности ссылок или принципом локальности по обращению.
При выполнении большинства программ было замечено, что адрес следующей команды будет расположен либо непосредственно за адресом выполняемой команды, либо недалеко от него.
При этом с очень высокой вероятностью данные, используемые этими командами, обычно структурированы и расположены в последовательных ячейках памяти.
Кроме того, программы содержат множество небольших циклов и подпрограмм, которые многократно повторяются в течение интервала времени.
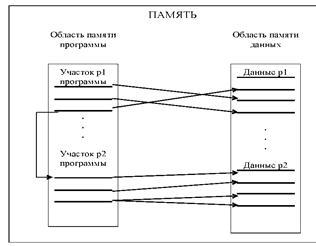 |
На рис. 3.2 показаны размещенные в памяти два участка программы и соответствующие им области данных.
Р и с. 3.2. Расположение программы и данных в памяти и локальность ссылок
Это явление называется локальность ссылок или локальность по обращению. Известно правило «90/10» - то есть 90% времени работы программы связано с обращением к 10% адресного пространства этой программы.
3.2 Взаимодействие процессора и различных уровней памяти
Уровни иерархии памяти взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне и так далее.
В каждый момент времени идет обмен с двумя близлежащими уровнями. Минимальная единица информации, которая может либо присутствовать, либо отсутствовать в двухуровневой иерархии, называется блоком.
Размер блока может быть либо фиксированным, либо переменным. Если этот размер зафиксирован, то объем памяти является кратным размеру блока.
Успешное или неуспешное обращение к более высокому уровню называются соответственно попаданием (hit) или промахом (miss).
Попадание - обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне.
Доля попаданий или коэффициент попаданий есть доля обращений, найденных на более высоком уровне.
Доля промахов есть доля обращений, которые не найдены на более высоком уровне.
Потери на промах - время для замещения блока в более высоком уровне на блок из более низкого уровня плюс время для пересылки этого блока в требуемое устройство (обычно в процессор).
Потери на промах включают в себя две компоненты: время доступа - время обращения к первому слову блока при промахе, и время пересылки - дополнительное время для пересылки оставшихся слов блока.
Время доступа связано с задержкой памяти более низкого уровня, в то время как время пересылки связано с полосой пропускания канала между устройствами памяти двух смежных уровней.
Инициатором обращения к памяти практически всегда является процессор. Исключение - режим прямого доступа к памяти, когда организуется процесс передачи файлов между ОП и внешней памятью через соответствующую шину, минуя процессор.
В процессе выполнения программы процессор обрабатывает каждую команду и определяет исполнительный адрес Аисп операнда.
При этом процессор «не знает», на каком уровне памяти находится этот исполнительный адрес, поэтому сразу формируется обращение к ОП.
Далее происходит поиск данных по исполнительному адресу на различных уровнях памяти. Сложность в том, что на каждом уровне данные представлены различными способами.
Будем рассматривать блочную организацию данных.
· В регистровой памяти данные записываются блоками в виде слов длиной 16, 32, 64 и 128 бит.
· В кэш-памяти блоком является строка длиной 16, 32 или 64 байта. В ОП чаще всего используются страницы по 4 - 8 Кб.
· На жестких дисках блоки - это сектора по 512 байт. Как правило, размер страницы ОП кратен длине сектора винчестера.
Если в системе есть кэш-память, то контроллер кэша проверяет, содержит ли кэш запрашиваемый адрес Аисп. Если данные с таким адресом есть, то блок с этими данными считывается из кэш-памяти в процессор, а обращение к ОП блокируется.
Если в кэш-памяти нет данных с адресом Аисп, то нужный блок ищется в оперативной памяти, затем загружается в кэш-память и одновременно передается в процессор.
Аналогично, при обращении к основной памяти при попадании блок данных передается в процессор. При промахе данные загружаются с жесткого или оптического диска в ОП.
При обращении к архивной памяти блок данных, то есть искомый диск, автоматически передается из хранилища и устанавливается в дисковод компьютера.
3.3 Адресная память
В адресном запоминающем устройстве (ЗУ) каждый запоминающий элемент памяти - ячейка, имеет адрес, который показывает его расположение в адресном пространстве.
Поиск информации производится по номеру (адресу) запоминающей ячейки, хранящей данные.
Совокупность N запоминающих ячеек образует запоминающую матрицу ЗМ.
Для компактного расположения запоминающих ячеек и упрощения доступа к ним ЗМ организуется как трехмерный куб.
В нем имеются две адресные координаты A1 и A2, а по третьей координате располагаются
n-разрядные слова.
Если адрес, поступающий с ША, имеет разрядность к, то он разделяется на две компоненты по k/2 адресных бита:
M= 2k/2 х 2k/2 = 2k.
В этом случае вместо одного ДША с M выходами используются два дешифратора с 2k/2 выходами, что значительно упрощает схемную реализацию.
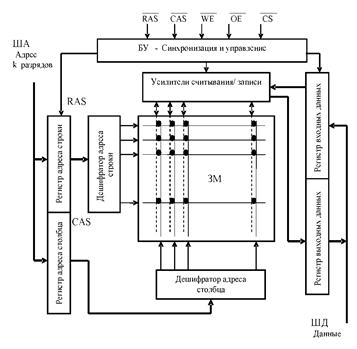
На рис. 3.3. показана структурная схема адресного запоминающего устройства.
Запоминающая матрица ЗМ имеет две координаты: строки и столбцы. Блок управления (БУ) управляет устройствами ЗУ, получая извне сигналы: RAS, CAS, СЕ, WE и OE.
Сигнал выбора микросхемы СЕ разрешает работу именно этой микросхемы памяти.
Режим чтения или записи определяется сигналом WE. На все время, пока микросхема не использует шину данных ШД, информационные выходы регистров переводятся сигналом OE в третье состояние с высоким выходным сопротивлением.
Адрес строки на шине ША сопровождается сигналом RAS, разрешающим прием адреса и его дешифрацию. После этого сигнал CAS разрешает прием и дешифрацию адреса столбца.
Каждый столбец имеет вторую линию чтения/записи, - для данных. Эти линии на рис. 3.3 показаны пунктиром.
Управление операциями с памятью осуществляется контроллером памяти. На каждую операцию требуется, как минимум, пять тактов.
• Указание типа операции (чтение или запись) и установка адреса строки.
• 
Формирование сигнала RAS.
• Установка адреса столбца.
• Формирование сигнала CAS.
• Запись или выдача данных и возврат сигналов RAS и CAS в неактивное состояние.
Р и с. 3.3. Адресное запоминающее устройство
ЗМ - запоминающая матрица;
RAS - сигнал строба строки (Row Address Strobe);
CAS - сигнал строба столбца(Column Address Strobe);
WE - разрешение записи (Write Enable);
OE - разрешение выдачи выходных сигналов (Output Enable);
CS - выбор микросхемы (Chip Select)
Латентность памяти и тайминги [20]
Под латентностью понимают задержку между поступлением команды в память и ее выполнением. Память не может мгновенно переходить из одного состояния в другое. Для стабильного функционирования памяти необходим пропуск нескольких циклов при изменении состояния ячейки памяти.
Например, после выполнения команды чтения должна следовать задержка CAS (CAS Latency). Это и есть латентность (CL) - наиболее важная характеристика памяти.
Очевидно, чем меньше латентность, тем быстрее работает память.
Латентность памяти определяется ее таймингами, то есть задержками, измеряемыми в количестве тактов между отдельными командами.
Существует несколько видов таймингов памяти.
• CL: CAS Latency - время, проходящее от момента подачи команды в память до начала ответа на этот запрос. Это время, которое проходит между запросом процессора на получение некоторых данных из памяти и моментом выдачи этих данных памятью.
• RAS-to-CAS (tRCD): задержка от RAS до CAS - время, которое должно пройти с момента обращения к строке матрицы (RAS), до момента обращения к ее столбцу матрицы (CAS), с целью выборки данных в которых хранятся нужные данные.
• RAS Precharge(tRP) - интервал времени между моментом закрытия доступа к одной строке и началом доступа к другой строке данных.
• Active to Precharge или Cycle Time (tRAS) - пауза, которая нужна памяти, чтобы вернуться в состояние ожидания следующего запроса.
• CMD: Скорость поступления команды (Command Rate) - время с момента активации чипа памяти до момента, когда первая команда может обратиться к ней. Обычно это T1 (один тактовый цикл) или T2 (два тактовых цикла).
Производительность памяти растет быстро, а ее латентность практически не улучшается.
В некоторых новых типах памяти с большей пропускной способностью латентность оказывается выше, чем в предыдущих реализациях.
В течение последних 25-ти лет латентность оперативной памяти уменьшилась всего в три раза. При этом тактовая частота процессоров возросла в сотни раз.
3.4 Ассоциативная память
Понятие «ассоциация» относится, прежде всего, к памяти, в которой выборка осуществляется не по адресному принципу, а по содержанию.
Ассоциативная память использует запись и чтение данных таким образом, чтобы обеспечить выборку слов, имеющих заданное содержание определенных полей.
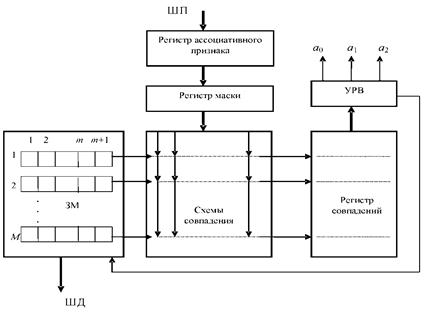
Поиск ведется с использованием ассоциативных признаков. Структура такой памяти представлена на рис. 3.4 [1].
Р и с. 3.4. Ассоциативная память
ЗМ - запоминающая матрица;
ШП - шина признака;
ШД - шина данных
Память хранит M ячеек для m+1 -разрядных слов, имеющих значения признаков.
Служебный m +1-й разряд показывает: «0» - ячейка свободна для записи, «1» - ячейка занята. Значения ассоциативного признака формируются регистром маски из полей признаков, поступающих из шины признаков ШП в регистр ассоциативного признака.
Поиск в запоминающей матрице выполняется за один такт одновременно по полям ассоциативных признаков всех хранящихся слов.
Это является отличительной чертой ассоциативных устройств памяти.
Реализация такого поиска осуществляется комбинационными схемами совпадения на базе элементов «сложение по модулю 2».
|
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 1715; Нарушение авторских прав?; Мы поможем в написании вашей работы!