КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Реализация алгоритма распознавателя с подбором альтернатив
|
|
|
|
Существует масса способов реализации алгоритма, моделирующего работу этого МП-автомата. Рассмотрим один из примеров реализации алгоритма нисходящего распознавателя с возвратом.
Для работы алгоритма используется МП-автомат, построенный на основе исходной грамматики G(VT,VN,P,S). Для удобства работы все правила из множества Р в грамматике G представим в виде A->a1|a2|…|an, то есть пронумеруем все возможные альтернативы для каждого нетерминального символа AÎVN. Входная цепочка символов имеет вид a=a1a2…an, |a| = n. В алгоритме используется также еще дополнительное состояние автомата b (от «back» — «назад»), которое сигнализирует о выполнении возврата к уже прочитанной части входной цепочки. Для хранения уже выбранных альтернатив используется дополнительный стек L2, который может содержать следующую информацию:
символы aÎVT входного языка автомата;
символы вида Aj, где A ÎVN — это означает, что среди всех возможных правил для символа А была выбрана альтернатива с номером j.
В итоге алгоритм работает с двумя стеками: l1 — стек МП-автомата и L2 — стек возвратов. Оба они представлены в виде цепочек символов. Символы в цепочку стека l1 помещаются слева, а в цепочку стека L2 — справа. В целом состояние алгоритма на каждом шаге определяется четырьмя параметрами: (Q, i, L1, L2), где Q — текущее состояние автомата (q или b); i — положение считывающей головки во входной цепочке символов a (1 < i <= n+1); L1 — содержимое стека МП-автомата; L2 — содержимое дополнительного стека.
Начальным состоянием алгоритма является состояние (q, 1, S, l), где S — целевой символ грамматики. Алгоритм начинает свою работу с начального состояния и циклически выполняет шесть шагов до тех пор, пока не перейдет в конечное состояние или не обнаружит ошибку. На каждом шаге алгоритма проверяется, соответствует ли текущее состояние алгоритма заданному для данного шага исходному состоянию, и выполняются ли заданные дополнительные условия. Если это требование выполняется, алгоритм переходит в следующее состояние, установленное для этого шага, если нет — шаг пропускается, алгоритм переходит к следующему шагу.
Алгоритм предусматривает циклическое выполнение следующих шагов.
Шаг 1 (Разрастание), (q, i, Аb, a) —> (q, i, g1b, aA1), если A->g1 — это первая из всех возможных альтернатив для символа А.
Шаг 2 (Успешное сравнение), (q, i, ab, a) -> (q, i+1, b, aа), если а = аi, aÎVT.
Шаг 3 (Завершение). Если состояние соответствует (q, n+1, l, a), то разбор завершен, алгоритм заканчивает работу, иначе (q, i, l, a) -> (b, i, l, a), когда i¹n+1.
Шаг 4 (Неуспешное сравнение), (q, i, аb, a) —> (b, i, аb, a), если а ¹ai, aÎVT.
Шаг 5 (Возврат по входу), (b, i, b, aа) —> (q, i-1, ab, a)), "aÎVT.
Шаг 6 (Другая альтернатива). Исходное состояние (b, i, gjb, aAj), действия:
· перейти в состояние (q, i, gj+1b, aAj+1), если еще существует альтернатива A—>gj+1 для символа A ÎVN;
· сигнализировать об ошибке и прекратить выполнение алгоритма, если AºS и не существует больше альтернатив для символа S;
· иначе перейти в состояние (q, i, Аb, a).
В случае успешного завершения алгоритма цепочку вывода можно построить на основе содержимого стека L2, полученного в результате выполнения алгоритма. Цепочка вывода строится следующим образом: поместить в цепочку номер правила m, соответствующий альтернативе А—>gj, если в стеке содержится символ Aj; все символы aÎVT, содержащиеся в стеке L2, игнорируются.
Этот алгоритм может быть напрямую использован для построения распознавателей. Следует помнить, что для применения этого алгоритма исходная грамматика не должна быть леворекурсивной. Если это условие не удовлетворяется, то грамматику предварительно надо преобразовать к нелеворекурсивному виду.
Рассмотрим в качестве примера грамматику G ({+.-,/,*, a, b}, {S, R, T, F, E}, P, S) с правилами (это нелеворекурсивная грамматика):
Р:
S -> Т | TR
R -> +T | -Т | +TR | -TR
Т -> Е | EF
F -> *Е | /Е | *EF | /EF
Е -> (S) | а | b
Проследим разбор цепочки а+(а*b) из языка этой грамматики с помощью алгоритма нисходящего распознавателя с возвратами. Работу алгоритма будем представлять в виде последовательности его состояний, взятых в скобки {} (фигурные скобки используются, чтобы не путать их с круглыми скобками, предусмотренными в правилах грамматики). Альтернативы будем нумеровать слева направо, правила — слева направо и сверху вниз. Для пояснения каждый шаг работы сопровождается номером шага алгоритма, который был применен для перехода в очередное состояние (записывается перед состоянием через символ «:» — двоеточие).
Алгоритм работы нисходящего распознавателя с возвратами при разборе цепочки а+(а*b) будет выполнять следующие шаги:


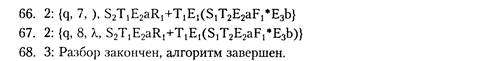
На основании полученной цепочки номеров альтернатив S2T1E2R1T1E1S1T2E2F1E3
построим последовательность номеров примененных правил: 2, 7, 14, 3, 7, 13, 1, 8, 14, 9, 15. Получаем левосторонний вывод: S => TR => ER => aR => a+T => a+E => a+(S) => a+(T) => a+(EF) => a+(aF) => a+(a*E) => a+(a*b). Соответствующее ему дерево вывода приведено на рис. 11.2.
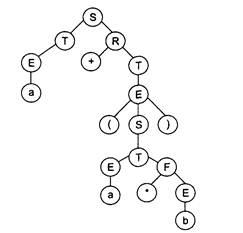
Рис. 11.2. Дерево вывода для грамматики без левых рекурсий
Из приведенного примера очевиден недостаток алгоритма нисходящего разбора с возвратами — значительная временная емкость: для разбора достаточно короткой входной цепочки (всего 7 символов) потребовалось 68 шагов работы алгоритма. Такого результата и следовало ожидать, исходя из экспоненциальной зависимости необходимых для работы алгоритма вычислительных ресурсов от длины входной цепочки. Это существенный недостаток данного алгоритма.
Преимуществом данного алгоритма можно считать простоту его реализации. Практически этот алгоритм разбора можно использовать только тогда, когда известно, что длина исходной цепочки символов заведомо не будет большой (не больше нескольких десятков символов). Для реальных компиляторов такое условие невыполнимо, но для некоторых небольших распознавателей вполне допустимо, и здесь данный алгоритм разбора может найти применение именно благодаря своей простоте.
Еще одно преимущество алгоритма — его универсальность. На его основе можно распознавать входные цепочки языка, заданного любой КС-грамматикой, достаточно лишь привести ее к нелеворекурсивному виду (а это можно сделать с любой грамматикой, см. раздел «Преобразование КС-грамматик. Приведенные грамматики»). Интересно, что грамматика даже не обязательно должна быть однозначной — для неоднозначной грамматики алгоритм найдет один из возможных ле-носторонних выводов.
Сам по себе алгоритм разбора с подбором альтернатив, использующий возвраты, • не находит применения в реальных компиляторах. Однако его основные принципы лежат в основе многих нисходящих распознавателей, строящих левосторонние выводы и работающих без использования возвратов. Методы, позволяющие строить такие распознаватели для некоторых классов КС-языков, рассмотрены далее. Эти распознаватели будут более эффективны в смысле необходимых вычислительных ресурсов, но алгоритмы их работы уже более сложны, кроме того, они не являются универсальными.
3.2.3 Распознаватель на основе алгоритма «сдвиг-свертка»
3.2.3.1. Принцип работы восходящего распознавателя по алгоритму «сдвиг-свертка»
Этот распознаватель строится на основе расширенного МП-автомата с одним состоянием q: R({q},V,Z,d,q,S,{q}). Автомат распознает цепочки КС-языка, заданного КС-грамматикой G(VT,VN,P,S). Входной алфавит автомата содержит терминальные символы грамматики: V = VT; а алфавит магазинных символов строится из терминальных и нетерминальных символов грамматики: Z = VTÈVN.
Начальная конфигурация автомата определяется так: (q,a, l) — автомат пребывает в своем единственном состоянии q, считывающая головка находится в начале входной цепочки символов aÎVT*, стек пуст.
Конечная конфигурация автомата определяется так: (q, l, S) — автомат пребывает в своем единственном состоянии q, считывающая головка находится за концом входной цепочки символов, в стеке лежит символ, соответствующий целевому символу грамматики S.
Функция переходов МП-автомата строится на основе правил грамматики:
1. (q,A) Îd(q, l, g), AÎVN, gÎ(VTÈVN)*, если правило А->g содержится во множестве правил Р грамматики G: А->gÎ Р.
2. (q, a)Îd(q, a, l) "aÎVT.
Неформально работу этого расширенного автомата можно описать так: если на верхушке стека находится цепочка символов g, то ее можно заменить на нетерминальный символ А, если в грамматике языка существует правило вида А—>g, не сдвигая при этом считывающую головку автомата (этот шаг работы называется «свертка»); с другой стороны, если считывающая головка автомата обозревает некоторый символ входной цепочки а, то его можно поместить в стек, сдвинув при этом головку на одну позицию вправо (этот шаг работы называется «сдвиг» или «перенос»). Сам алгоритм, моделирующий работу такого расширенного автомата, называется алгоритмом «сдвиг-свертка» или «перенос-свертка» (по названиям основных действий алгоритма).
Данный расширенный МП-автомат строит правосторонние выводы для грамматики. Для моделирования такого автомата необходимо, чтобы грамматика G(VT, VN, P, S) не содержала l-правил и цепных правил (иначе, автомат может войти в бесконечный цикл из сверток). Поскольку произвольную КС-грамматику всегда можно преобразовать к виду без l-правил и цепных правилБ о этот алгоритм применим для любой КС-граматики, следовательно, им можно распознавать цепочки любого КС-языка.
Этот расширенный МП-автомат строит правосторонние выводы и читает цепочку входных символов слева направо. Поэтому для него естественным является построение дерева вывода снизу вверх. Такой распознаватель называется восходящим.
Данный расширенный МП-автомат потенциально имеет больше неоднозначностей, чем рассмотренный выше МП-автомат, основанный на алгоритме подбора альтернатив. На каждом шаге работы автомата надо решать следующие вопросы:
· что необходимо выполнять: сдвиг или свертку;
· если выполнять свертку, то какую цепочку g выбрать для поиска правил (цепочка g должна встречаться в правой части правил грамматики);
· какое правило выбрать для свертки, если окажется, что существует несколько правил вида А->g (несколько правил с одинаковой правой частью).
Чтобы промоделировать работы этого расширенного МП-автомата, надо на каждом шаге запоминать все предпринятые действия, чтобы иметь возможность вернуться к уже сделанному шагу и выполнить эти же действия по-другому. Этот процесс должен повторяться до тех пор, пока не будут перебраны все возможные варианты.
|
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 1292; Нарушение авторских прав?; Мы поможем в написании вашей работы!