КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Определение LL(k)-грамматики
|
|
|
|
Логическим продолжением идеи, положенной в основу метода рекурсивного спуска, является предложение использовать для выбора одной из множества альтернатив не один, а несколько символов входной цепочки. Однако напрямую переложить алгоритм выбора альтернативы для одного символа на такой же алгоритм для цепочки символов не удастся — два соседних символа в цепочке на самом деле могут быть выведены с использованием различных правил грамматики, поэтому неверным будет напрямую искать их в одном правиле. Тем не менее, существует класс грамматик, основанный именно на этом принципе — выборе одной альтернативы из множества возможных на основе нескольких очередных символов в цепочке. Это так называемые LL(k)-грамматики. Правда, алгоритм работы распознавателя для них не так очевидно прост, как рассмотренный выше алгоритм рекурсивного спуска.
Грамматика обладает свойством LL(k), k > 0, если на каждом шаге вывода для однозначного выбора очередной альтернативы МП-автомату достаточно знать символ на верхушке стека и рассмотреть первые k символов от текущего положения считывающей головки во входной цепочке символов.
Грамматика называется LL(k) -грамматикой, если она обладает свойством LL(k) для некоторого k > 0. (Требование k > 0, безусловно, является разумным — для принятия решения о выборе той или иной альтернативы МП-автомату надо рассмотреть хотя бы один символ входной цепочки. Если представить себе LL-грамматику с k = 0, то в такой грамматике вывод совсем не будет зависеть от входной цепочки. В принципе такая грамматика возможна, но в ней будет всего одна-единственная цепочка вывода. Поэтому практическое применение языка, заданного такого рода грамматикой, представляется весьма сомнительным.)
Название «LL(k)» несет определенный смысл. Первая литера «L» происходит от слова «left» и означает, что входная цепочка символов читается в направлении слева направо. Вторая литера «L» также происходит от слова «left» и означает, что при работе распознавателя используется левосторонний вывод. Вместо «k» в названии класса грамматики стоит некоторое число, которое показывает, сколько символов надо рассмотреть, чтобы однозначно выбрать одну из множества альтернатив. Так, существуют LL(1)-грамматики, LL(2)-грамматики и другие классы.
В совокупности все LL(k)-грамматики для всех k>0 образуют класс LL-грамматик.
На рис. 12.1 схематично показано частичное дерево вывода для некоторой LL(k)-грамматики. В нем w обозначает уже разобранную часть входной цепочки a, которая построена на основе левой части дерева у. Правая часть дерева х — это еще не разобранная часть, а А — текущий нетерминальный символ на верхушке стека МП-автомата. Цепочка х представляет собой незавершенную часть цепочки вывода, содержащую как терминальные, так и нетерминальные символы. После завершения вывода символ А раскрывается в часть входной цепочки u, а правая часть дерева х преобразуется в часть входной цепочки t. Свойство LL(k) предполагает, что однозначный выбор альтернативы для символа А может быть сделан на основе k первых символов цепочки ut, являющейся частью входной цепочки a.
Алгоритм разбора входных цепочек для LL(k)-грамматики носит название «k-предсказывающего алгоритма». Принципы его выполнения во многом соответствуют функционированию МП-автомата с той разницей, что на каждом шаге работы этот алгоритм может просматривать k символов вперед от текущего положения считывающей головки автомата.
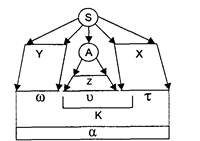
Рис. 12.1. Схема построения дерева вывода для LL(k)-грамматики
Для LL(k)-грамматик известны следующие полезные свойства:
· всякая LL(k)-грамматика для любого k>0 является однозначной;
· существует алгоритм, позволяющий проверить, является ли заданная грамматика LL(k)-грамматикой для строго определенного числа k.
Кроме того, известно, что все грамматики, допускающие разбор по методу рекурсивного спуска, являются подклассом LL(1) -грамматик. То есть любая грамматика, допускающая разбор по методу рекурсивного спуска, является LL(1)-грамматикой (но не наоборот!).
Есть, однако, неразрешимые проблемы для произвольных КС-грамматик:
· не существует алгоритма, который бы мог проверить, является ли заданная КС-грамматика LL(k)-грамматикой для некоторого произвольного числа k;
· не существует алгоритма, который бы мог преобразовать произвольную КС-грамматику к виду LL(k)-грамматики для некоторого k (или доказать, что преобразование невозможно).
Это несколько ограничивает применимость LL(k)-грамматик, поскольку не всегда для произвольной КС-грамматики можно очевидно найти число k, для которого она является LL(k)-грамматикой, или узнать, существует ли вообще для нее такое число k.
Для LL(k)-грамматики при k>l совсем не обязательно, чтобы все правые части правил грамматики для каждого нетерминального символа начинались с k различных терминальных символов. Принципы распознавания предложений входного языка такой грамматики накладывают менее жесткие ограничения на правила грамматики, поскольку k соседних символов, по которым однозначно выбирается очередная альтернатива, могут встречаться и в нескольких правилах грамматики (эти условия рассмотрены ниже). Грамматики, у которых все правые части правил для всех нетерминальных символов начинаются с k различных терминальных символов, носят название «сильно LL(k)-грамматик». Метод построения распознавателей для них достаточно прост, алгоритм разбора очевиден, но, к сожалению, такие грамматики встречаются крайне редко.
Для LL(1)-грамматики, очевидно, для каждого нетерминального символа не может быть двух правил, начинающихся с одного и того же терминального символа. Однако это менее жесткое условие, чем то, которое накладывает распознаватель по методу рекурсивного спуска, поскольку в принципе LL(1)-грамматика допускает в правой части правил цепочки, начинающиеся с нетерминальных символов, а также l-правила. LL(1) -грамматики позволяют построить достаточно простой и эффективный распознаватель, поэтому они рассматриваются далее отдельно в соответствующем разделе.
Поскольку все LL(k) -грамматики используют левосторонний нисходящий распознаватель, основанный на алгоритме с подбором альтернатив, очевидно, что они не могут допускать левую рекурсию. Поэтому никакая леворекурсивная грамматика не может быть LL-грамматикой. Следовательно, первым делом при попытке преобразовать грамматику к виду LL-грамматики необходимо устранить в ней левую рекурсию (соответствующий алгоритм был рассмотрен выше).
Класс LL-грамматик широк, но все же он недостаточен для того, чтобы покрыть все возможные синтаксические конструкции в языках программирования (к ним относим все детерминированные КС-языки). Известно, что существуют детерминированные КС-языки, которые не могут быть заданы LL(k)-грамматикой ни для каких k. Однако LL-грамматики удобны для использования, поскольку позволяют построить распознаватели с линейными характеристиками (линейной зависимостью требуемых для работы алгоритма распознавания вычислительных ресурсов от длины входной цепочки символов).
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 2710; Нарушение авторских прав?; Мы поможем в написании вашей работы!