КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Внутримашинная организация экономической информации
|
|
|
|
Организация данных в базах
Оглавление
1. Внутримашинная организация экономической информации. 1
2. Трехуровневая модель организации баз данных. 5
3. Иерархическая и сетевая модели данных. 9
4. Реляционная модель данных. 11
5. Логические связи между отношениями. 12
6. Нормализация отношений. 13
7. Операции над отношениями. 16
В первые годы автоматизированной обработки информации, в 50-х – начале 60-х годов, использовалась файловая организация данных. Данные хранились в файлах последовательного доступа.В 60-е годы, когда широко распространились устройства прямого доступа – магнитные диски, приобрели популярность файлы произвольного доступа.
По мере совершенствования методов управления народным хозяйством и его звеньями все яснее осознается необходимость создания АИС. Поначалу АИС имели файловую организацию данных. Такие системы обладали рядом недостатков:
1) дублирование данных;
2) жесткая связь данных и прикладных программ. При программировании задач описание данных включалось непосредственно в программу. Если изменялась организация данных, то переделывалась и программа, что требовало больших затрат труда программиста. Программы оказывались узкоспециализированными;
3) ограниченный контроль данных;
4) недостаточные возможности управления данными.
Эти недостатки файловой организации данных обусловили появление баз данных (БД), которые позволяют обеспечивать более эффективный доступ к данным и их обработку.
База данных – это компьютерный термин, употребляемый для обозначения совокупности информации по определенной тематике, используемой в определенной прикладной области.
Компьютерная БД – это автоматизированная версия системы заполнения, хранения и извлечения информации любой структуры – от простого текста до сложной структуры данных, включая рисунки, звуки и видеоизображения.
База данных – поименованная и структурированная совокупность взаимосвязанных данных, которые отражают состояние объектов конкретной предметной области, их свойства и взаимоотношения и находятся под общим программным управлением. Объектом может быть предмет, вещество, событие, лицо, явление, абстрактное понятие, то есть все то, что может характеризоваться набором значений некоторой совокупности атрибутов. Атрибут – это информационное отображение свойства объекта.Например, объект «книга» характеризуется атрибутами: «наименование», «авторы», «количество страниц», «тираж», «цена» и др. Предметная область - часть реального мира, которая описывается и моделируется с помощью БД.
Преимущества использования БД заключаются в следующем:
1. Возможность расширения и модификации данных.
2. Возможность обеспечения независимости данных в БД от программ их обрабатывающих.
3. Возможность вести быстрый поиск необходимых данных по запросам пользователя.
4. Возможность обеспечения защиты секретных данных от постороннего вмешательства.
5. Возможность обеспечения целостности данных и др.
Базы данных могут быть классифицированы по технологии обработки данных и по способам доступа к данным (рис.1)

Рисунок 1 – Классификация БД
По технологии обработки базы данных подразделяются на централизованные и распределенные.
Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования БД часто применяется в локальных сетях ПК.
Распредленная база данных состоит из нескольких, возможно, пересекающихся и даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным (сетевым) доступом
Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры подобных систем:
• файл-сервер;
• клиент-сервер.
Файл-сервер. Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На ней хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочей станции, с помощью которых поддерживается доступ пользовательской системы к централизованной БД. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность системы падает. Схема обработки информации в БД по принципу файл-сервер представлена на рис. 2.
|
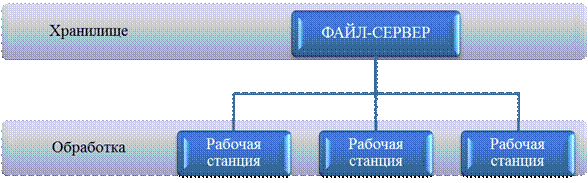
Рисунок 2 – Схема обработки информации в БД по принципу файл-сервер
Клиент-сервер. Вархитектуре Клиент-сервер подразумевается, что помимо хранения централизованной БД центральная машина (сервер базы данных) должна обеспечивать выполнение основного объёма обработки данных. Пользователи обращаются к центральному серверу с помощью специального языка структурированных запросов (SQL). Запрос на данные клиента, порождает поиск и извлечение данных на сервере. Извлечённые данные (но не файлы) транспортируются по сети от сервера к клиенту.
Схема обработки информации в БД о принципу клиент-сервер представлена на рисунке 3.
|

Современные базы данных большого объема. Для его измерения применяются такие единицы, как Терабайт и Петабайт. 1 Терабайт равен 1012 байтов, 1 Петабайт равен 1015 байтов.
Размещение БД осуществляется на устройствах для хранения больших объемов данных: жестких магнитных дисках, оптических компакт-дисках, оптических библиотеках. Так, оптические библиотеки позволяют организовать динамический доступ к информации объемом от нескольких десятков Гигабайт до 5-6 Терабайт. В этих устройствах может быть установлено свыше 500 компакт-дисков разного формата.
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 651; Нарушение авторских прав?; Мы поможем в написании вашей работы!