КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
I. Создание баз данных
|
|
|
|
Типы данных
Character:
CHAR - 1 символ – 1 байт
CHAR(n) - n символов – n байт
VARCHAR(n) - строка переменной длины (n<=255)
Bit:
BIT
BIT (n)
BIT VARING (n) - битовая строка переменной длины
Exact Numeric:
NUM [P[,S]] – P – максимальное количество десятичных чисел; S – максимальное количество цифр после десятичной точки.
DEC [P[,S]]
INTEGER - целочисленный – 4 байта
SHALLINT - короткое целое, стандартный размер – 2 байта.
Approximate Numeric:
FLOAT [(n)] - n – определяет точность представления мантиссы.
REAL - тоже, что и FLOAT, только со стандартной точностью.
DOUBLE - повышенная (удвоенная) точность.
Date Time: (для работы со временем)
DATE - представляет дату в формате: месяц, день, год. Множество значений упорядоченно, и существует некая константа – CURDATE, которая имеет значение текущей даты (всегда).
TIME [(n)] - время, n – точность представления секунд
TIMESTAMP [(n)] - это дата и время.
Interval: - (представление временных отрезков)
INTERVAL - можно задавать точность представления и диапазон представления.
Ко всем типам относится значение NULL, то есть пусто, пустое значение, отсутствие его.
CREATE SCHEMA [<имя1> AUTHORIEATION <имя2>]
<имя1> - имя базы данных
<имя1> - идентификатор автора, создателя
II. Уничтожение баз данных
DROP SCHEMA <имя> - при этом ни одной конкретной таблицы не создается
Иногда используются и другие инструкции создания баз данных.
1). CREATE DATABASE <имя>
DROP DATABASE <имя> - ее удаление
2). DATABASE <имя> - открыть базу данных
CLOSE <имя> - закрыть базу данных
III. Создание таблиц
CREATE TABLE <имя таблицы>
(<имя атрибута> <тип>,
<имя атрибута> <тип>,
-----------------------------
<имя атрибута> <тип>)
Например:
CREATE TABLE Salesman
(ID CHAR(2),
|
|
|
Name VARCHAR(20),
Status NUM(2))
IV. Изменение таблиц
ALTER TABLE <имя таблицы> ADD <имя атрибута> <тип>
Пример: ALTER TABLE Salesman
ADD born DATE (дата рождения)
Здесь мы добавим еще один атрибут: «дата рождения»
V. Исключение таблицы
DROP TABLE <имя>
VI. Создание индекса
CREATE INDEX <имя инд.> ON <имя табл.>
(<имя атр.>[, <имя атр.>, …])
Идентифицировать все подряд не надо, надо там, где часто производим поиск.
CREATE UNIQUEINDEX <имя инд.> ON <имя табл.>
(<имя атр.>[, <имя атр.>, …])
Это уникальный индекс.
VII. Удаление индекса
DROP INDEX <имя инд.>
ОГРАНИЧЕНИЕ НА ДОПУСТИМЫЕ ЗНАЧЕНИЯ ДАННЫХ
SQL позволяет наложить серверные ограничения как на отдельные атрибуты, так и на таблицу.
Виды ограничений:
Ø Ограничения на атрибуты
Ø Ограничения на таблицу
Если накладываем ограничения, то инструкция представляется в расширенном виде:
CREATE TABLE <имя табл.>
(<имя атр.> <тип> [<ограничения>],
<имя атр.> <тип> [<ограничения>],
- - - - - - - - - - - - - - - - - - - - - - - - - -
<имя атр.> <тип> [<ограничения>] [,
<ограничения на таблицу> (<имя атр.> [,
<имя атр.>, …])])
1) Ограничения
исключение № 411 значений:
NOT NULL
Пример:
CREATE TABLE Salesman
(ID CHAD (2) NOT NULL, - т.е. у данного атрибута не должно быть нулевого значения
Name varchar (20) NOT NULL,
Status NUM (2) NOT NULL)
2) ПОДДЕРЖКА УНИКАЛЬНОСТИ ЗНАЧЕНИЙ:
UNTQUE
Пример:
CREATE TABLE Salesman
(ID CHAR (2) NOT NULL UNTQUE
name VARCHAR (20) NOT NULL,
Status NUM (2))
Поддерживает уникальность, т.е. СУБД будет следить за тем, чтобы не возникало два одинаковых значения этого атрибута в различных картинах.
UNTQUE может быть наложено на таблицу.
Можно указывать не один атрибут, а группу атрибутов.
Пример:
CREATE TABLE Salesman
(------------ то же самое,
а в конце:
UNTQUE (ID, Status)
Значения Status повторяться могут, но их комбинации (ID, Status) нет.
3) ОПРЕДЕЛЕНИЕ ПЕРВИЧНОГО КЛЮЧА.
|
|
|
PRIMARY KEY
Пример:
CREATE TABLE Salesman
(ID CHAD (2) NOT NULL PRIMARY KEY,
Name VARCHAR (20) NOT NULL,
Status NULL (2);
UNTQUE (Name, Status)
Не может быть одинаково имя и статус.
Может быть наложено на таблицу, если первичный ключ является составным.
4) ОГРАНИЧЕНИЕ НАЗНАЧЕНИЯ.
CHECK (<предикат>)
Может быть наложен на таблицу и отдельный атрибут.
Примеры:
CHECK (Status ≥ 10)
CHECK (Status > 20 OR City = ‘Tula’)
5) ЗАДАНИЕ ЗНАЧЕНИЯ ПО УМОЛЧАНИЮ.
Первоначально для всех значений устанавливается значение NULL.
Однако для любого атрибута можно установить другое предварительное значение.
DEFAULT = <ЗНАЧЕНИЕ>
Пример:
CREATE TABLE Salesman
(- - - - - - - -
- - - - - - - -
Status NULL (2) DEFAULT = 20,)
Status = 20, если оно не задано
ПОДДЕРЖКА ЦЕЛОСТНОСТИ ПО ВНЕШНИМ КЛЮЧАМ
Это целесообразно делать, если внешний ключ является составным.
На атрибут: ключ является простым
На таблицу: оно накладывается так:
 Это составной внешний ключ
Это составной внешний ключ
FOREIGN KEY (<список атрибутов>) REFERENCES
 <имя таблицы> (<список атрибутов >)
<имя таблицы> (<список атрибутов >)
Это составной первичный ключ таблицы
Если ключ является не составным, то можно по-прежнему доказывать ограничение на имя таблицы или на саму таблицу.
REFERENCES <имя таблицы> (<имя атрибутов>)
Манипулирование данными DML включает в себя четыре инструкции:
SELECT
INSERT
DELETE
UPDATE
Select – выбор, определяет таблицу, которую надо выбрать из базы данных
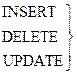 приводят к изменению базы данных
приводят к изменению базы данных
INSERT - вставка
DELETE - уничтожение
UPDATE – изменение, обновление
SELECT
Инструкция определяет некоторое отклонение, которое выбирается из базы данных.
Используется не только самостоятельно.
На базе SELECT строятся все отчеты.
Общая конструкция, которая используется
SELECT:
SELECT <список атрибутов>
FROM <имя таблицы>
WHERE <предикат>
В первой строке – перечень атрибутов, которые включаются в выборку.
Вторая строка – имя таблицы, из которой делают выборку.
Третья строка – условие истинности, по которым делается выборка.
Пример:
Дано три отношения

Поставщики (S) (Код.пост., имя, катег. пост., город)
Деталь (Р) (Код.дет., наимен., вес, цвет, город)
Поставки (SР) (Код.пост.; Код.дет., количество)
S
| Код пост. | имя | Катег. пост | город |
| S1 S2 S3 S4 S5 | Иванов Петров Сидоров Круглов Смирнов | Москва Тула Тула Москва Орел |
|
|
|
Р
| Код дет. | наименование | вес | цвет | город |
| Р1 Р2 Р3 Р4 Р5 Р6 | Сайка Виски Кольцо Винт Шайба Винт | Красный Зеленый Синий Красный Желтый Красный | Москва Тула Москва Москва Тула Рязань |
SP
| Код пост. | Код дет. | количество |
| S1 S1 S1 S2 S2 S2 S2 S3 S3 S5 S5 S5 | Р1 Р3 Р6 Р1 Р2 Р5 Р6 Р2 Р4 Р4 Р5 Р6 |
SELECT *
FROM <имя таблицы>
___________________
SELECT код дет.
FROM SP
Возможна перестановка столбцов таблицы.
Пример:
SELECT город, имя Москва Иванов
FROM S Тула Петров
… …
Орел Смирнов
Результатом любой выборки является отношение, т.е. множество картежей.
DISTINCT – устраняет повторы картежей (устраняют повторяющие значения).
SELECT DISTINCT код дет. Р1
FROM SP P3
_________________________
Р2
Р5
Р4
Вместо атрибута в строке (селект) может быть записано выражение.
Пример:
SELECT наим., вес*1000
FROM P
_____________________
гайка 10000
винт 12000
- - - - - - - - - - - - - - -
винт 10000
поскольку значение является выражением, то в списке атрибутов, т.е. в списке SELECT, может быть записано значение строкового типа.
Пример:
SELECT наим., вес*1000, ‘грамм’
FROM P
_______________________________
гайка 10000 грамм
- - - - - - - - - - - - - -
винт 10000 грамм
ВЫБОРКА С ОГРАНИЧЕНИЕМ
Примеры:
Пусть требуется выбрать коды поставщиков, проживающих в Туле и имеющих категорию больше 20.
SELECT код пост. S3
FROM S
WHERE Тула = город
AND катег. > 20
________________________
Пусть требуется выбрать цвета деталей, которые либо являются винтами, либо весят больше 17. Код выборки не более одного раза.
SELECT DISTINCT цвет зеленый
FROM Р синий
WHERE наим.= ‘винт’ красный
OR вес > 17 желтый
Новые команды для ограничений:
IN – принадлежит
BETWEEN - между
LIKE – соответствует шаблону
IN
Пусть требуется выбрать фамилии поставщиков, проживающих в Туле или в Москве.
SELECT имя
FROM S
WHERE город IN (‘Тула’, ‘Москва’)
________________________________
Иванов
Петров
Сидоров
Круглов
BETWEEN
Пусть требуется выбрать коды и названия деталей, вес которых заключен между 16 и 25.
SELECT код.дет., наим.
FROM Р
WHERE вес BETWEEN 16 AND 25
P3 Кольцо
P5 Шайба
Граничные значения при употреблении BETWEEN попадают в выборку.
|
|
|
LIKE
К атрибутам типа CHAR и VARCHAR группе символьных атрибутов
LIKE <шаблон> – конкретное значение
Кроме него в шаблоне могут использоваться символы:
(_) – любой символ,
(%) - все количество всех символов.
M _ _ K – все строки из 4-х символов, первый из которых М, последний К
М % - все строковые значения, которые начинаются с М
М % К – любое строковое значение, которое начинается с М и заканчивается К.
Пример:
Пусть требуется выбрать города, в которых производятся детали, наименования которых заканчиваются на А.
SELECT DISTINCT город
FROM Р
WHERE наим. LIKE ’% a’
_______________________
Москва
Тула
Использование NULL значений.
Сравнение с NULL невозможно.
Если хотим распознать это значение, то используем IS NULL.
Пример:
Пусть требуется выбрать те номера деталей, для которых еще не определен код деталей.
SELECT DISTINCT код дет.
FROM SР
WHERE количество IS NULL
IS NOT NULL – если не равно нулю,
Not IN (…) - не принадлежит множеству.
УПОРЯДОЧЕННЫЕ ВЫБОРКИ:
ORDER BY <имя атрибутов>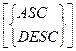 , <имя атрибутов>…
, <имя атрибутов>…
ASC – по возрастанию (по умолчанию)
DESC – по убыванию.
В строке ORDER BY вместо имени атрибута может быть использован порядковый номер.
В ORDER BY могут быть указаны те атрибуты, которые попадают в выборку (указаны в строке ‘SELECT’).
Пример:
Требуется выбрать коды, цвет, вес деталей, которые производятся не в Туле, упорядочив их по весу, по возрастанию, а в случае цвета по убыванию.
SELECT код дет., цвет, вес
FROM Р
WHERE город NOT IN (‘Тула’)
ORDER BY вес, цвет DESC
__________________________
P1, красный, 10
P6, красный, 10
P3, синий, 24
P4, красный, 40
ИСПОЛЬЗОВАНИЕ АГРЕГИРОВАННЫХ ФУНКЦИЙ
COUNT – количество картежей
SUM
AVG – среднее значение атрибута
MIN
MAX
Стандартом наложен запрет вычисления функций от функций.
SELECT <имя атрибутов>, <имя функций> (<имя атрибутов>)
FROM <имя таблицы>
Пример:
Надо вычислить среднюю категорию поставщика.
SELECT AVG (катег.)
FROM S
Количество категорий поставщиков.
SELECT COUNT (катег.)
FROM S
____________________________
SEKECT COUNT (DISTINCT катег.)
FROM S
____________________________
SELECT COUNT (*) все картежи, включая NULL, значения повторяющиеся
FROM S
ALL
SELECT COUNT (ALL катег.)
FROM S
Будут подсчитаны все повторяющие значения, значения NULL подсчитываться не будут.
ИСПОЛЬЗОВАНИЕ ПАРАМЕТРА GROUP BY
Позволяет вычислить агрегированную функцию для каждой из группировок картежей, при этом картежи группируются по некоторому атрибуту, указанному в строке SELECT
Пример:
Пусть требуется для каждого кода деталей вычислить MAX объем поставки.
SELECT код дет., МАХ (кол)
FROM SP
GROUP BY код дет.
____________________________
P1 200
P3 200
P6 300
P2 300
P5 200
P4 300
Пример:
Пусть требуется вычислить минимальный вес для каждой из группы деталей, совпадающей наименованием и цветом.
SELECT Наим., цвет, MIN (вес)
FROM P
GROUP BY Наим., цвет
_________________
Гайка красный 10
Винт зеленый 12
Кольцо синий 24
Винт красный 10
Шайба желтый 25
Параметр НАVING, который позволяет наложить ограничение на целую группу и, таким образом, исключить из рассмотрения некоторые группировки.
Пример:
Выбрать для каждой детали средний объем поставки, включая в выборку только те детали, которые присутствуют более чем в одной поставке.
SELECT код дет., АVG (Кол.)
FROM SP
GROUP BY код дет.
НАVING COUNT (Код пост.) > 1
_____________________
Р1 150
Р6 500/3
Р2 300
Р5 200
Р4 200
Очень часто требуется построить запрос, где требуется много таблиц.
Join – присоединение таблиц
Join S. Город Р. Город
<имя табл.> <имя атр.>
Пример:
Пусть требуется вывести информацию об именах поставщиков и наименовании товаров при условии, что поставщик проживает в том же городе, где производится товар.
SELECT S.имя, Р.наим., S.Город
FROM SP
WHERE S.Город = P.Город
______________________________
Иванов Гайка Москва
Иванов Кольцо Москва
Иванов Винт Москва
Петров Винт Тула
Петров Шайба Тула
Сидоров Винт Тула
Сидоров Шайба Тула
Круглов Гайка Москва
Круглов Кольцо Москва
Круглов Винт Москва
Можно строить следующие сложные запросы с использованием более сложных предикатов.
Пример:
Требуется вывести информацию о поставщиках и городах, в которых они проживают для тех поставщиков, для которых объем поставки больше 200.
SELECT S. имя, S. город
FROM S, SP
WHERE S. код пост. = SP. код пост.
AND SP. Кол. > 200
________________
Петров Тула
Сидоров Тула
Сидоров Тула
Смирнов Орел
Если хотим устранить дублирование картежей, то надо добавить DISTINCT.
Пример:
Надо вывести поставки поставщиков, которые проживают не в том городе, где делаются детали.
SELECT S. имя, P. наим., SP. количество
FROM S, P, SP
WHERE SP. Код пост. = S. Код пост.
AND SP. Код дет. = P. Код дет.
AND S. город < > P. город
_____________________
Иванов винт 100
Петров гайка 200
Петров винт 100
Сидоров винт 300
Смирнов винт 100
Смирнов шайба 200
МИРНОВ ВИНТ 300
СОЕДИНЕНИЕ КОПИЙ ОДНОЙ ТАБЛИЦЫ
Алиасы
В одном запросе SELECT можно использовать копии одной и той же таблицы, указанная в FROM – это алнаса.
Имя Алиаса образуется следующим образом:
<имя табл.> <имя Алиаса >
S first S second
P a P b
Пример:
Требуется найти все пары поставщиков, имеющие одинаковые категории.
SELECT а. имя, b. Имя, а. Катег.
FROM S а, S b
WHERE а. Катег. = b. Катег.
____________________________
Ø Иванов Иванов 10
Иванов Круглов 10
Ø Петров Петров 20
Ø Сидоров Сидоров 30
Сидоров Смирнов 30
Ø Круглов Иванов 10
Ø Круглов Круглов 10
Ø Смирнов Сидоров 30
Ø Смирнов Смирнов 30
Ø - это то, что нам не надо. Для его удаления нужно добавить условие:
AND а. имя < b. имя
ВЛОЖЕННЫЕ ЗАПРОСЫ
Пусть требуется выбрать все поставки, в которых поставляется кольцо.
SELECT SP. Код пост., SP. Код дет., SP. Кол-во
FROM SP, P
WHERE SP. Код дет. = P. код дет.
AND P. наим. = ‘кольцо’
______________________
SELECT *
FROM SP
WHERE код дет. =
(SELECT код дет.
FROM P
WHERE наим. = ‘кольцо’)
Сначала вычисляется внутренний SELECT, а затем обрабатывается внешний запрос.
В результате первого шага у нас получится одно значение: Р3.
Сравним по эффективности эти два запроса.
Вложенный запрос является более эффективным, чем первый, в конструкции соединения.
Можно использовать операцию In (если вместо кольцо – винт).
SELECT *
FROM SP
WHERE код дет. IN
(SELECT код дет.
FROM P
WHERE наим. = ‘винт’)
Но так как мы используем множественную операцию IN, то внешний запрос обрабатывается неправильно.
Пример:
Нужно найти имена всех поставщиков, имеющих суммарный объем поставок более 400.
 SELECT имя
SELECT имя
FROM S внешний запрос
WHERE код пост. IN
 (SELECT код пост.
(SELECT код пост.
FROM SP outer
WHERE 400 < внутренний запрос
(SELECT SUM (кол.)
FROM SP inner
WHERE outer. Код пост.= inner. Код пост.))
______________________________________
Иванов
Петров
Сидоров
Смирнов
СВЯЗАННЫЕ ПОДЗАПРОСЫ
Специфика состоит в том, что в строке внутреннего подзапроса имеется ссылка на таблицу внешнего запроса.
Пример:
Пусть требуется выбрать все поставки, в которых поставляют 200 деталей одного наименования.
(*- выбрать все)
SEKECT *
FROM S
WHERE 200 IN
(SELECT Количество
FROM SP
WHERE S.Код пост. = SP.код пост.)
Конструкция «вложенный цикл» имеет трудоемкость n2.
____________________
S1 Иванов 10 Москва
S2 Петров 20 Тула
S5 Смирнов 30 Орел
Как можно сконструировать этот запрос, чтобы получился запрос – соединение
SELECT DISTINCT S.Код пост., S.имя, S.катег., S.город
FROM S, SP
WHERE S.Код пост. = SP.код пост.
AND SP.Кол-во = 200
Пример:
Пусть требуется выбрать все поставки с объемом большим, чем средний объем для данной детали.
SELECT DISTINCT *
FROM SP out
WHERE out.Кол. >
(SELECT AVG (Кол.)
FROM SP inn
WHERE inn.Код дет. = out.код дет.)
______________________________________________________
S2 P1 200
S5 P6 300
S2 P1 200
S5 P6 300
S3 P4 300
S3 P4 300
S5 P6 300
Для того, чтобы не было повторов, нужно добавить DISTINCT.
ИСПОЛЬЗОВАНИЕ ЗАПРОСОВ SELECT ПАРАМЕТРА EXISTS
EXISTS может быть применен к внутренней выборке и генерирует булева значения.
True - если выборка не пустая,
False - если выборка пустая.
Пример:
Нужно выбрать код и имя поставщиков при условии, что в S есть хотя бы один поставщик из Москвы.
SELECT S.Код пост., S.имя
FROM S
WHERE EXISTS
(SELECT *
FROM S
WHERE Город = ‘Москва’)
Здесь алиасы не используются, так как внутренние и внешние запросы не связаны.
Результат: два первых столбца таблицы S (полностью).
EXISTS может использоваться и в связанных запросах, при этом EXISTS вычисляется отдельно для каждого подзапроса.
Пример:
Нужно найти коды поставщиков, которые имеют несколько поставок.
SELECT DISTINCT Код out.Код пост.
FROM SP out
WHERE EXISTS
(SELECT *
FROM SP inn
WHERE inn.Код пост. = out.код пост.
AND inn.Код дет.< > out.код дет.)
__________________
S1, S2, S3, S5.
Этот запрос не будет работать, если в таблице задано, что один поставщик поставляет одну и ту же деталь только разного объема.
Но это невозможно в нашем случае, так как таблица SP имеет первичный ключ код пост., код дет., следовательно, повтора не может быть в этих столбцах.
Пример:
Надо выбрать данные о всех поставщиках, которые поставляют детали в нескольких поставках.
SELECT *
FROM S
WHERE EXISTS
(SELECT *
FROM SP out
WHERE S.Код пост. = out код пост.
AND 1<
(SELECT COUNT (*)
FROM SP inn
WHERE out.Код дет. = inn.код дет.))
Использование параметров ANY, SOME, ALL.
Параметры ANY и SOME в SQL выполняются одинаково. Различие лишь в смысле этих слов.
ANY - какой-нибудь;
SOME - какой-либо.
Пример:
Нужно выбрать поставщиков, проживающих в тех городах, где производятся детали.
SELECT *
FROM S
WHERE город = ANY
(SELECT город принимает значение true, если какой-либо город,
FROM P) выбранный из внутреннего цикла совпадает с городом из внешней выборки.
Можно еще и так.
SELECT *
FROM S
WHERE город IN
(SELECT город
FROM P)
Можно построить запрос и с использованием EXISTS:
SELECT *
FROM S
WHERE EXISTS
(SELECT *
FROM P
WHERE S. город = P. город)
Предикат ALL принимает значение true, если каждое из выбранных в подзапросе значений удовлетворяет внешнему запросу.
Пример:
Выбрать поставщиков, категория которых выше, чем категория всех из поставщиков, проживающих в Москве.
SELECT *
FROM S
WHERE катег. > ALL
(SELECT катег.
FROM S
WHERE город = ‘Москва’)
Параметр UNION позволяет объединить результаты двух независимых выборков в одну таблицу.
При выполнении операции UNION дублирование картежей исключается.
Пример:
Выбрать детали, которые производятся в Москве, и поставщиков, которые живут там же.
SELECT код пост., имя
FROM S
WHERE город = ‘Москва’
UNION
SELECT код дет., наим.
FROM P
WHERE город = ‘Москва’
S1 Иванов
S4 Круглов
P1 гайка
P3 кольцо
P4 винт
На этом мы заканчиваем инструкцию SELECT.
ИЗМЕНЕНИЕ ДАННЫХ В БАЗЕ ДАННЫХ
CREATE – создает таблицу
ALTER
SELECT – работает с готовыми таблицами, исполненными данными
Итого три инструкции, которые позволяют изменять данные (работать с ними) в базе данных:
INSERT работают с целыми комплектами
DELETE
UPDATE позволяют изменить значение
INSERT
INSERT INTO <имя табл.> [(<имя атр.>, …)]
VALUES (<знач.>, …)
В таблицу добавляется картеж, записанный в строке VALUES.
Если в строке INSERT указан список атрибутов, в который входят не все атрибуты, то список значений в строке VALUES должен быть согласован по количеству, порядку следования, при этом значение отсутствующих атрибутов формируется по умолчанию (NULL).
Пример:
Нужно добавить картеж в таблицу.
INSERT INTO S
VALUES (‘S6’, ‘Стеклов‘, 20, ‘Орел’)
Пример:
(Когда вводятся не все атрибуты).
INSERT INTO P (Код дет., наим., город)
VALUES (‘P7’, ‘кольцо‘, ‘Тула‘)
А атрибуты все и цвет формируются по умолчанию.
Если при определении этой таблицы для этих атрибутов не сформировано значение по умолчанию, то устанавливается для них значение NULL.
Если для цвет – NULL, то эта конструкция ошибочна.
Картеж, описываемый в INSERT, уже существует в таблице, то вместо строки VALYES, используется запрос SELECT в существующей базе данных.
Пример:
Нужно в таблицу поставок добавить всех поставщиков, которые проживают в городах, в которых производится деталь, без указания объема детали.
INSERT INTO SP (код пост., код дет.)
SELECT S. код пост., P. Код дет.
FROM S, P
WHERE S. город = P. Город
Значение атрибута количество будет сформировано по умолчанию.
Пример:
Если мы хотим создать таблицу с суммарным объемом поставок для каждого из поставщиков.
INSERT INTO SM
SELECT код пост., SUM (кол-во)
FROM SP
GROUP BY код пост.
Удаление таблицы:
DELETE FROM <имя табл.>
WHERE <предикат >
Пример:
DELETE FROM SP
DROP SP - удаляется вся таблица SP, и с ней больше работать нельзя.
___________________
DELETE FROM SP
WHERE кол. > 200
Следующая инструкция обновления UPDATE. Она обновляет только некоторые картежи.
Пример:
Пусть требуется установить категории поставщиков в 30.
UPDATE S
SET катег. = 30
Пример:
Надо повысить категорию поставщиков до 30, у которых она была равна 20.
UPDATE S
SEТ катег. = 30
WHERE катег. = 20
Пример:
Нужно всех москвичей, у которых категория меньше 30 переселить в Томск и повысить до 30.
UPDATE S
SET катег. = 30, город =’Томск’
WHERE катег. < 30
AND город = ’Москва’
Пример:
Нужно увеличить на 10 категорию всех поставщиков, проживающих не в Москве.
UPDATE S
SET катег. = катег. + 10
WHERE город < > ‘Москва’
В строке SET можно использовать и значение NULL, присваивая его какому-либо атрибуту.
Пример:
Нужно всем (каким-либо) москвичам аннулировать категорию.
UPDATE S
SET катег.= NULL Это присваивание
WHERE город < > ‘Москва’ Это отношение
В этой инструкции может использоваться и подзапрос.
Пример:
Пусть мы создаем таблицу, в которой хотим поместить всех поставщиков из Москвы.
CREATE TABLE MS
(Код пост. CHAR(2),
- - - - - - - - - - - - - - - - -)
___________________
INSERT INTO MS
SELECT *
FROM S
WHERE город = ‘Москва’
Пример:
Пусть мы хотим копировать всех поставщиков, которые поставляют детали, которые создаются в Москве, но неважно, где они проживают.
INSERT INTO MS
SELECT *
FROM S
WHERE код пост. IN
(SELECT код пост.
FROM SP
WHERE код дет. IN
(SELECT код дет.
FROM P
WHERE город = ‘Москва’))
Пример:
Пусть нужно удалить все поставки деталей, которые производятся в Туле.
ANY – любой.
DELETE FROM SP
WHERE код дет. = ANY
(SELECT код дет.
FROM P
WHERE город = ‘Тула’)
Пример:
Увеличить на 10 категорию всех поставщиков, имеющих более одной поставки.
UPDATE S
SET катег. = катег. + 10
WHERE 1<
(SELECT COUNT (*)
FROM SP
WHERE S. код пост. = SP. Код пост.)
Ограничение:
Нельзя ссылаться в строке FROM подзапроса на изменяемую таблицу команды обновления.
Пример:
Нужно удалить всех поставщиков с категорией ниже среднего.
 DELETE FROM S
DELETE FROM S
 WHERE Катег. <
WHERE Катег. <
(SELECT AVG (Катег.) ТАК НЕЛЬЗЯ
FROM S)
Представления VIEW
Это создание виртуальной подсхемы для разработки приложения. Если мы создаем таблицы с помощью команды CREATE, то они будет избыточными. Чтобы этого избежать существует понятие представления VIEW.
CREATE VIEW – создаем виртуальную таблицу заполненную данными, и эти данные выбираются из физических таблиц.
Пример
Пусть мы хотим создать представление о немосковских поставщиках.
CREATE VIEW NMS
AS SELECT * (создать как выборку)
FROM S
WHERE город<>’Москва’
Не существует никаких ограничений на SELECT, но существует ограничения на UPDATE и DELETE.
Реально никакая физическая таблица не создается. При добавлении в нее картежей, удалении и д.т. одновременно меняется и представление. Представление ограничивает видимость таблицы.
Пример
CREATE VIEW NKS
AS SELECT код. пост, имя, город
FROM S
Здесь атрибут «категория» будет невиден, поэтому доступ к нему ограничен.
Пример
Пусть мы хотим решить задачу о переезде поставщика S2 в Рязань.
UPDATE NKS
SET город = ’Рязань’
WHERE код. пост = ‘S2’
Можно создавать групповые представления.
Пример
Хотим создать представление о поставках, в которых для каждого поставщика отражалась количество поставщиков в суммарном и среднем объеме.
CREATE VIEW TOTSP(код. пост, кол-во пост, сумм пост, сред. пост)
AS SELECT код. пост, COUNT(код. дет.), SUM(кол-во), AVG(кол-во)
FROM SP
GROUP BY код. пост.
Чтобы получить соответственно отчет о поставках:
SELECT *
FROM TOTSP
Пример
Нужно создать представление, аналогичное таблице SP, однако, вместо код. пост. и код. дет., в нем должна стоять имя и наименование детали.
CREATE VIEW NAMESP
AS SELECT S.имя, P.наим, SP.код.дет
FROM S, P, SP
WHERE S.код. пост. = SP.код. пост.
AND P.код.дет.=SP.код.дет.
Удаление представления: DROP VIEW <имя представления>
Пример
DROP TOTSP
Неоднозначность при обновлении представления
Пример
Создать представление, в котором будут собраны пары городов, в которых проживают поставщики и производят деталь, у которой категория больше 10.
CREATE VIEW CSP(S.город,P.город)
AS SELECT DISTINCT S.город, P.город
FROM S, P
WHERE категория>10
| Тула | Москва | Орел | Москва | |
| Тула | Тула | Орел | Тула | |
| Тула | Рязань | Орел | Рязань |
Если сделать UPDATE, то могут возникнуть неоднозначности. Т.к. одному картежу представления может существовать несколько пар картежей базовых таблиц S и P, на которых на которых определено это представление.
Если мы захотим скорректировать представление, то неопределенно где изменить данные в S или P, т.к. картежу Тула Москва соответствует три пары картежей, т.к. мы используем DISTINCT, то создается не обновляемое представление
UPDATEBLE – обновляемое.
Стандартом ANSI определяется набор требований к представлениям, которые обеспечивают его обновляемость:
1. представление базируется на одной таблице
2. в представление не входят атрибуты, определяется с помощью функции агрегирования
3. отсутствует параметр DISTINCT
4. отсутствует GROUP BU и HAVING
5. отсутствует подзапросы в определенном представлении
6. представление может быть определено на базе другого представления, если оно является обновляемым
7. представление должно включать в себя атрибут, являющийся первичным ключом базовой таблицы.
Пример
По таблице SP определить представление, в котором для каждого из поставщиков определено количество поставок.
CREATE VIEW POST(код. пост., код. пост.)
AS SELECT код. пост, COUNT(*)
FROM SP
GROUP BY код. пост.
Не обновляемо, т.к. есть COUNT и GROUP BY, и нет первичного ключа.
CREATE VIEW MSK
AS SELECT *
FROM S
WHERE город = ‘Москва’
Обновляемо, т.к. все условия выполнены.
Пример
Создать представление, в которое входит информация о поставщиках, среди поставок объемом 200, причем категория не входит.
CREATE VIEW PST
AS SELECT код. пост., имя, город
WHERE код. пост. IN
(SELECT код. пост.
FROM SP
WHERE кол=200)
Не обновляемое, т.к. содержит запрос.
Пример
Выбрать поставщиков с категорией равной 30.
CREATE VIEW SNK
AS SELECT *
FROM S
WHERE катег=30
В это представление попадут не все картежи, следовательно это представление можно обновлять.
Добавим в него картеж с помощью INSERT
INSERT INTO SNK
VALUES (‘S6’,’Орлов’,20,’Тула’)
Через представление мы видим атрибут с категорией 30. Этот картеж попадает в базовую таблицу, а в представление его не будет.
Для избежания такой ситуации имеется параметр WITH CHECK OPTION
WITH CHECK OPTION
Данное представление можно обновлять, но при обновлении запрещается выполнение команды, которая не удовлетворяет определению представления (не видны в нем).
Пример
Создать представление, в которое войдут поставщики из Москвы, т.к. значение атрибута ‘город’ будет одинаковым, то не целесообразно его представлять в представлении.
CREATE VIEW MSK
AS SELECT (код. пост., имя, катег.)
FORM S
WHERE город =’Москва’
Оно обновляемо.
Если мы хотим обновить, то по умолчанию будет ‘Москва’, если нет, то результат такого представления будет невидим. Но добавляемый картеж не будет противоречить определению представления, т.к. в нем город не используется, поэтому лучше описывать в определении представлении Москва, т.к. параметр WITH CHECK OPTION будет защищать.
Механизм защиты SQL
1. Данные необходимо защищать от разрушения (сбой программ, неквалифицированное использование и т.д.)
2. Защита от несанкционированного доступа.
Имеется три механизма защиты данных:
1. Механизм представлений
2. Механизм привилегий
3. Механизм транзакций
Механизм представлений
Позволяет приложению работать с виртуальным представлением данных; ограничивает доступ из приложения к данным.
Каждый пользователь имеет свой ID (идентификационный номер) и под ним он регистрируется в системе. USER – общий идентификатор. Для каждого используется определенный набор привилегий. Привилегии определяю действия или данные, которые доступны пользователю. Пользователь, создает таблицу, является ее владельцем, может назначать привилегии другим пользователям по работе с таблицей.
Стандартный набор привилегий SQL включает в себя:
| 1. INSERT | Право выполнять с таблицей соответствующие операции |
| 2. DELETE | |
| 3. UPDATE | |
| 4. SELECT | |
| 5. REFERENCES | Право использовать атрибуты таблиц в качестве внешних ключей других таблиц |
Кроме того есть не стандартные привилегии:
GRANT – назначение привилегий
REVOKE - лишение привилегий
Конструкция для GRANT:
GRANT <имя правила> ON <имя таблицы> TO <ID пользователя>
Может быть указан список привилегий после GRANT, и привилегию можно назначать списку пользователей (после TO)
Пример
Право выборки из таблицы S
GRANT SELECT ON S TO Петров
Выбрать эту инструкцию может тот пользователь, который обладает такой привилегией.
GRANT INSERT, SELECT NO S TO Sidorov
GRANT позволяет назначать привилегии на отдельные атрибуты таблицы.
GRANT UPDATE ON SP(кол) TO Petrov
GRANT UPDATE ON S(город, категория) TO Ivanov
Можно передать все свои привилегии другому пользователю, также можно сделать некоторую привилегию общедоступной.
GRANT ALL ON P TO Sidoriv
GRANT SELECT ON S TO PUBLIC
Некто является владельцем таблицы, и передает свои привилегии другому лицу, и чтобы он мог в свою очередь передать выданные привилегии, то это возможно при определенном описании.
IVANOV S
GRANT INSERT ON S TO PETROV
WITH GRANT OPTION
Чтобы PETROV мог передать право передачи соответствующих атрибутов.
Как менять привилегии? Структура команды REVOKE.
REVOKE <имя привилегии> ON <имя таблицы> FROM <имя пользователя>
REVOKE SELECT, INSERT ON S FORM IVANOV
Лишить привилегий может тот, кто ее предоставил.
Три базовых уровня привилегий
1. CONNECT
2. RESOURCE
3. DBA
CONNECT – право входить в систему
RESOURCE – право создавать базовые таблицы
DBA – право полностью распоряжаться базой данных, и назначать привилегии.
Есть еще один уровень: SYSADM. Он выше, чем уровень DBA.
GRANT RESOURCE TO IVANOV
Во многих системах, пользователь, который впервые подключился к системе, получает пароль, не зная которого он не может войти в систему.
GRANT CONNECT TO IVANOV IDENTIFIED BY PAROL
Администратор и Иванов могут теперь изменить пароль.
Механизм транзакций
Транзакция – группа команд, которые либо выполняются все вместе, либо не выполняется ни одной.
Основная цель транзакций – это предотвратить непоправимые последствия ошибок, которые вызывают сбой в системе.
Пример
Если мы хотим удалить поставщика, то надо удалить его из таблицы S, однако может оказаться, что среди поставок может оказаться поставки этого поставщика, следовательно, нужно отменить его поставки, либо передать их другому поставщику.
Для решения этой проблемы нужно:
1. обновление таблицы поставок
2. удаление поставщика
Если после выполнения первой команды произойдет сбой, то удаление поставщика не выполнилось до конца, следовательно, получилось, что поставки скорректированы, а поставщик не удален.
Для управления транзакций в SQL существуют две конструкции:
1. COMMIT WORK – зафиксировать все изменения, выполненные в ходе транзакции
2. ROLLBACK WORK – отменить все изменения, выполненные в ходе транзакции
Режим автоматического фиксирования правильных транзакций SET AUTOCOMMIT ON, отмена SET AUTOCOMMIT OFF
Параллельное выполнение транзакций на уровне SQL также рассматривается.
Если выполняются две параллельные транзакции, которые не используют один и тот же ресурс, то проблем нет.
В SQL вводится понятии блокировки LOCK.
Блокировка накладывает ограничения на некоторые операции базы данных, если при этом выполняются другие операции.
Существуют два вида блокировки:
1. S-Locks – распределяемая блокировка
2. X-Locks – исключительная блокировка
S-Locks в единицу времени может выполняться более чем одним пользователем, предоставляет многим пользователям доступ к одним и тем же данным, не изменяя их
X-Locks запрещает доступ к данным пользователям, кроме того, чья блокировка выполняется в данный момент.
Использование встроенного SQL
С самого начала определен механизм расширения SQL (механизм встраивания SQL в некоторый язык третьего поколения).
Стандартом ANSI определены четыре:
1. Pascal
2. Fortran
3. Cobol
4. Pl1
Правило, которое положено в строенный SQL:
1. Перед каждой командой SQL запроса нужно писать EXEC SQL
2. Исходный запрос SQL обрабатывается препроцессором.
|

|


|
Модуль доступа обеспечивает интерпретация SQL кода. Для одной конкретной программы может существовать один модуль доступа. С использованием программы, но встроенном SQL связан механизм привилегий:
Каждой программе ставится в соответствие некоторая привилегия (ID). Для того чтобы использовать встроенный SQL нужно соблюдение типов.
В запросах SQL разрешается использовать переменные высокого уровня везде, где в соответствии с синтаксисом могут быть выражения. Использование в запросах SQL языков высокого уровня должно удовлетворять четырем правилам:
1. Эти переменные должны быть объявлены в SQL Decelerate Section
2. Должна быть обеспечена совместимость по типу данных
3. Когда соответствующая переменная, используется в SQL команде, должна быть инициализирована
4. Перед именем переменной при ее использовании в SQL команде ставится «:»
Пример
EXEC SQL
INSERT INTO S
VALUES (:Id,:Name,:Категория,:Sity)
while not eof(Input) do
begin
readln(:id,:name,:lex,:sity)
EXEC SQL
INSERT INTO S
VALUES(:id,:name,:lex,:sity);
end;
Раздел SQL Decelerate Section помещается в любом месте. Все переменные помещаются в этом разделе.
Пример
EXEC SQL BEGIN DECELERATE SECTION;
VAR
ID, …
EXEC SQL END DECELERATE SECTION;
Понятие о курсоре SQL
1. Первое определение курсора
2. Активизировать курсор
3. Прочитать соответствующий курсор, переместить курсор
4. Закрыть курсор
Рассмотрим эти инструкции на конкретных примерах. Курсор определяется также как представление – с помощью SELECT.
Пример
Мы хотим рассматривать таблицу S, обрабатывать ее, рассматривать поставщиков из Москвы.
EXEC SQL DECELERATE CURSOR MS FOR
SELECT *
FROM S
WHERE Город=’Москва’;
Эта функция определяет курсор, но никакого значение курсор не принимает.
Пример
Если мы хотим обрабатывать этих поставщиков, то должны открыть курсор.
EXEC SQL OPEN CURSOR MS
Открывается и принимает значения соответствующие данным из картежа, где установлен курсор. Начинается обработка данных, соответствующих определенному курсору.
EXEC SQL FETCH CURSOR MS
INTO:id,:name,:lex,:sity
Где id, name, lex, sity – это переменные языка высокого уровня. При этом происходят два действия:
1. Перечисленным переменным присваиваются значения активного картежа
2. Курсор перемещается к следующему картежу
При использовании этой инструкции курсор можно не писать.
Пример
Напечатать данные обо всех поставщиках проживающих в Москве.
KEY:=’Y’
EXEC SQL OPEN CURSOR MS;
WHILE KEY=’Y’ DO {(KEY=’Y’)AND(SQLCODE=0) DO}
BEGIN
EXEC SQL FETCH MS
INTO:id,:name,:lex,:sity
WRITELN(id, name, lex, sity);
WRITE(‘ПРОДОЛЖИТЬ? (Y/N)’);
READLN(KEY)
END;
EXEC SQL CLOSE CURSOR MS;
Для того чтобы управлять этим циклом в SQL есть специальная переменная SQLCODE. Эта переменная формируется каждый раз, когда исполняется FETCH. Она принимает значение 0, когда курсор не пуст.
Основные функции и структура СУБД
В составе основных можно выделить четыре элемента, которые и составляют структуру: ядро, компиляторы, подсистемы поддержки времени выполнения, утилиты.
Компиляторы: все необходимые средства, которые поддерживают язык. Основные проблемы:
1. Языки баз данных являются непроцедурными языками следовательно работа ведётся в режиме интерпретации.
2. Оптимализация кода.
Подсистема: компиляторы получают на выход некоторый объектный код. И это не интерпретатор этого кода.
Утилиты: состав производный. Стандартные:
1. Средства загрузки и выгрузки.
2. Диагностика целостности.
3. Статическая обработка по запросам и самим данным.
4. Средства архивации.
Ядро: часть управления базами данных, которые реализуют основные механизмы работы с базами данных. Мы выделяем 4 основных функции ядра:
1. Управление данными внешней памяти
2. Управление буферами оперативной памяти.
3. Управление транзакциями.
4. Журнализация.
В состав ядра могут входить 4 компонента, каждый из которых обеспечивает одну функцию:
1. Менеджер данных.
2. Менеджер буферов.
3. Менеджер транзакций.
4. Менеджер журналов.
Кроме 4 основных имеется род дополнительных функций, основное назначение которых – связь 4 основных функций. Все системы БД являются многопользовательскими.
Внутренний интерфейс ядра, который недоступен пользователю.
Управление данными во внешней памяти.
Эта функция включает в себя весь набор функций.
Работа с данными на физическом уровне.
Сюда входят функции:
1. Хранилище.
2. Доступ к ним.
3. Хранение и использование дополнительных данных, необходимых для ускорения доступа к структурам БД.
Некоторые СУБД активно используют вход в ОС уже имеющиеся механизмы файловых систем. Другие СУБД полностью берут эту функцию без связи с ОС вплоть до связи с внешними устройствами на физическом уровне. Серьёзные СУБД используют свою собственную системы именования объектов БД.
Управление буферами оперативной памяти.
БД обычно работают со структурой данных обычного размера. Обычно является таблица, в которую входят 106 кортежей. Структура, как правило, не может быть размещена в ОП. Обмен с внешней памяти должен быть сведён к минимуму. Единственным способом реально увеличить способ работы с данными является буферизация данных в оперативной памяти. Обмен данными происходит не отдельными большими порциями, а сразу целыми буферами. При этом, если происходит обращение к внешней памяти, с той или иной целью, то сначала инициализируется обращение к буферу. Если в буфере нет обходимых данных, то происходит считывание данных с внешнего устройства.
Управление транзакией.
Транзакция – это последовательность операций которые БД рассматривает как единое целое. Основное свойство транзакций – это перевод из одного целостного состояния в другое. Поддержка механизма транзакций – это обязательное условие даже для однопользовательских СУБД. Транзакция рассматривается как единица активности пользователя по отношению к БД. В многопользовательских СУБД возникает проблема обработки параллельных транзакций. С этим понятием связаны понятия сериализации, сериального плана.
Сериализация – это смешение транзакций при котором суммарный эффект равен эффекту последовательного выполнения. Их выполняют псевдопараллельно.
Сериализация транзакций выполняется с помощью построения сериального плана. Он приводит к смещению транзакций.
Существует насколько способов постарения сериального плана. Наиболее распространенных подход – это подход на синхронных захватах. При выполнении механизма сериализации возможно возникновение конфликтом между транзакциями. В этом случае для поддержания сериализации выполняются откаты.
Журнализация
Под надежностью хранения мы понимаем следующие требования: СУБД должна быть в состоянии восстановить последнее целостное состояние данных после нестандартного вмешательства.
Две разновидности сбоев:
1. Мягкий (происходит в результате программных ошибок: внезапного аварийного отключения питания. В результате БД может оказаться в логически противоречивом состоянии, но потери БД и разрушение на внешних носителях не происходит)
2. Жесткий (сопровождается нарушением данных на внешних устройствах.)
Для того чтобы восстановить состояние БД должна поддерживаться некоторая избыточность хранения данных. Причем очевидно, что те данные должны храниться особым образом. Наиболее распространенным способом организации такой избыточной информации является ведение журнала изменений в БД. Хранится особо тщательно, одновременно ведется две копии журнала. В разных СУБД записи в журнал осуществляются разных уровнях. Например: фиксируется как операция удаления картежа, так и изменения и добавления.
Выполнение журнала поддерживается WAL стратегией. Это стратегия упреждающей записи. Перед тем как фиксируют изменение во внешней памяти, запись об этих изменениях заносится в журнал. Если WAL протокол в СУБД ведется корректно, то восстановление БД возможно после любого сбоя. Самая простая ситуация восстановления – это откат транзакции (индивидуальный). Для того, чтобы выполнить этот откат достаточно поддерживать в СУБД лишь локальный журнал. Он хранит лишь записи о последней выполняемой транзакции после поспешного завершения транзакции журнал как бы обнуляется и следующая транзакция начинается с начала. Некоторые достаточно простые СУБД ведут локальный журнал. Однако во многих СУБД записи записываются в общесистемных журнал. При этом записи относящиеся к одной транзакции в общесистемном журнале связываются в обратный список.
Есть системы, которые комбинируют общесистемные и локальные журналы. При жестком сбое восстановление происходит так: возможно, что после жесткого сбоя можно восстановить систему из журнала. После жесткого сбоя восстановления архивированных БД. СУБД поддерживает систему архивирования данных.
Архивирование – это выгрузка данных на внешние носители. Одновременно должно храниться несколько последних суток, в месте с архивом и хранится журнал. Механизм журнализации тесно связан с механизмом транзакции.
Архитектура многопользовательских СУБД
Любая БД должна быть многопользовательской.

Все на одном компьютере, возможно большом, возможно много процессорном. Это многопользовательская система с централизованной архитектурой. Когда все централизованно, то легко выполнить такую функцию как администрирование и защита. Недостатки схемы: такая высокая централизация в обработке информации предъявляет очень высокие требования к оборудованию. Сначала были терминалы у него не было ресурсов, они пользовались данными из одного компьютера. Потом появилась распределенная вычислительная среда следовательно появилась возможность подключения компьютера к различным ресурсам. При этом каждый из этих компьютеров обладает своими собственными ресурсами, обладает процессором, обладает памятью (в этой среде имеются общие ресурсы, которые могут использовать несколько пользователей: данные, почтовые услуги и т.д.).
Сеть – это некая среда обмена информацией между компьютерами.
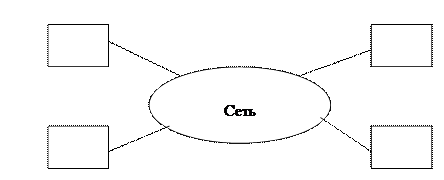
Поскольку ресурсы в этой системе распределены неравномерно, то появляются ситуации, в которых компьютеры оказываются неэквивалентны. Некоторые из них являются обладателями какого то общего ресурса причем у одного компьютера один ресурс, а у другого – другой. Могут быть компьютеры не обладающие общими ресурсами. Компьютер, который является обладателем какого либо ресурса называется сервером (сервер данных). Так как ресурс общий, то потребность использования этого ресурса возникает у других компьютеров. Компьютер, который обращается к серверу называется клиент.
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 1407; Нарушение авторских прав?; Мы поможем в написании вашей работы!