КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
C. Этап 3. Подготовка данных
|
|
|
|
B. Этап 2. Постановка задачи
Постановка задачи Data Mining включает следующие шаги: формулировка задачи; затем формализация задачи.
Постановка задачи включает также описание статического и динамического поведения исследуемых объектов. Например, при продвижении нового товара на рынок необходимо определить, какая группа клиентов фирмы будет наиболее заинтересована в данном товаре. Описание статики подразумевает описание объектов и их свойств. Например, клиент является объектом. Свойства объекта "клиент": семейное положение, доход за предыдущий год, место проживания. При описании динамики описывается поведение объектов и те причины, которые влияют на их поведение. Например, клиент покупает товар А. При появлении нового товара В клиент уже не покупает товар А, а покупает только товар В. Появление товара В изменило поведение клиента. Динамика поведения объектов часто описывается вместе со статикой.
Технология Data Mining не может заменить аналитика и ответить на те вопросы, которые не были заданы. Поэтому постановка задачи является необходимым этапом, поскольку именно на этом этапе мы определяем, какую же задачу необходимо решить. Иногда этапы анализа предметной области и постановки задачи объединяют в один этап.
На этом этапе происходит разработка базы данных для Data Mining. Подготовка данных является важнейшим этапом, от качества выполнения которого зависит возможность получения качественных результатов всего процесса Data Mining. Кроме того, на этом этапе, по некоторым оценкам, может быть потрачено до 80% всего времени, отведенного на проект. Данный этап состоит из трех шагов.
1. Определение и анализ требований к данным
На этом шаге осуществляется так называемое моделирование данных, т.е. определение и анализ требований к данным, которые необходимы для осуществления Data Mining. При этом изучаются вопросы распределения пользователей (географическое, организационное, функциональное); вопросы доступа к данным, которые необходимы для анализа, необходимость во внешних и/или внутренних источниках данных; а также аналитические характеристики системы (измерения данных, основные виды выходных документов, последовательность преобразования информации и др.).
2. Сбор данных
Наличие в организации хранилища данных делает анализ проще и эффективней, его использование, с точки зрения вложений, обходится дешевле, чем использование отдельных баз данных или витрин данных. Однако далеко не все предприятия оснащены хранилищами данных. В этом случае источником для исходных данных являются оперативные, справочные и архивные БД, т.е. данные из существующих информационных систем. Также для Data Mining может потребоваться информация из информационных систем руководителей, внешних источников, бумажных носителей, а также знания экспертов или результаты опросов. Следует помнить, что в процессе подготовки данных аналитики и разработчики не должны привязываться к показателям, которые есть в наличии, и описать максимальное количество факторов и признаков, влияющих на анализируемый процесс.
На этом шаге осуществляется кодирование некоторых данных. Допустим, одним из атрибутов клиента является уровень дохода, который должен быть представлен в системе одним из значений: очень низким, низким, средним, высоким, очень высоким. Для определения градации уровня дохода требуется сотрудничество аналитика с экспертом в предметной области. Возможно, для таких преобразований данных потребуется написание специальных процедур.
При определении необходимого количества данных следует учитывать, являются ли данные упорядоченными или нет. Если данные упорядочены и мы имеем дело с временными рядами, желательно знать, включает ли такой набор данных сезонную/цикличную компоненту. В случае присутствия в наборе данных сезонной/цикличной компоненты, необходимо иметь данные как минимум за один сезон/цикл. Если данные не упорядочены, то есть события из набора данных не связаны по времени, в ходе сбора данных следует соблюдать следующие правила.
Недостаточное количество записей в наборе данных может стать причиной построения некорректной модели. С точки зрения статистики, точность модели увеличивается с увеличением количества исследуемых данных. Возможно, некоторые данные являются устаревшими или описывают какую-то нетипичную ситуацию, и их нужно исключить из базы данных.
При использовании многих алгоритмов необходимо определенное (желательное) соотношение входных переменных и количества наблюдений. Количество записей (примеров) в наборе данных должно быть значительно больше количества факторов (переменных). Набор данных должен быть репрезентативным и представлять как можно больше возможных ситуаций. Пропорции представления различных примеров в наборе данных должны соответствовать реальной ситуации.
3. Предварительная обработка данных
Предварительной обработки данных необходима для обеспечения качественного анализа. Данные, полученные в результате сбора, должны соответствовать определенным критериям качества. Таким образом, можно выделить важный подэтап процесса Data Mining - оценивание качества данных.
Качество данных - это критерий, определяющий полноту, точность, своевременность и возможность интерпретации данных. Данные могут быть высокого качества и низкого качества, последние - это так называемые грязные или "плохие" данные. Данные высокого качества - это полные, точные, своевременные данные, которые поддаются интерпретации. Они обеспечивают получение качественного результата: знаний, которые смогут поддерживать процесс принятия решений.
В последнее время многие компании стали обращать больше внимания на качество данных, поскольку низкое качество данных ведет к снижению производительности, принятию неправильных бизнес-решений и невозможности получить желаемый результат. И если раньше менеджеры обращали основное внимание на инструменты оценки качества, считая, что "собственник" данных должен решать проблему на уровне источника, например, очищая данные и переобучая сотрудников. То сейчас понятие качества данных гораздо шире, чем просто их аккуратное введение в систему на первом этапе. Сегодня уже многие понимают, что качество данных должно обеспечиваться процессами извлечения, преобразования и загрузки, а также получения данных из источников, которые подготавливают данные для анализа.
Рассмотрим понятия качества данных более детально.
Данные низкого качества, или грязные данные - это отсутствующие, неточные или бесполезные данные с точки зрения практического применения (например, представленные в неверном формате, не соответствующем стандарту). Грязные данные возникли одновременно с системами ввода данных. Грязные данные могут появиться по разным причинам, таким как ошибка при вводе данных, использование иных форматов представления или единиц измерения, несоответствие стандартам, отсутствие своевременного обновления, неудачное обновление всех копий данных, неудачное удаление записей-дубликатов и т.д. Среди различных типов грязных данных можно выделить следующие группы:
Ø грязные данные, которые могут быть автоматически обнаружены и очищены;
Ø данные, появление которых может быть предотвращено;
Ø данные, которые непригодны для автоматического обнаружения и очистки;
Ø данные, появление которых невозможно предотвратить.
Рассмотрим наиболее распространенные виды грязных данных.
a) Пропущенные значения. Некоторые значения данных могут быть пропущены в связи с тем, что:
ü данные вообще не были собраны (например, при анкетировании скрыт возраст);
ü некоторые атрибуты могут быть неприменимы для некоторых объектов (например, атрибут "годовой доход" неприменим к ребенку).
С пропущенными данными можно поступить следующим образом:
ü Исключить объекты с пропущенными значениями из обработки.
ü Рассчитать новые значения для пропущенных данных.
ü Игнорировать пропущенные значения в процессе анализа.
ü Заменить пропущенные значения на возможные значения.
b) Дублирование данных. Набор данных может включать продублированные данные, т.е. дубликаты. Дубликатами называются записи с одинаковыми значениями всех атрибутов. Наличие дубликатов в наборе данных может являться способом повышения значимости некоторых записей. Такая необходимость иногда возникает для особого выделения определенных записей из набора данных. Однако в большинстве случаев, продублированные данные являются результатом ошибок при подготовке данных.
Существует два варианта обработки дубликатов. При первом варианте удаляется вся группа записей, содержащая дубликаты. Этот вариант используется в том случае, если наличие дубликатов вызывает недоверие к информации, полностью ее обесценивает. Второй вариант состоит в замене группы дубликатов на одну уникальную запись.
c) 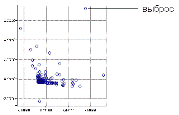 Шумы и выбросы. Выбросы - резко отличающиеся объекты или наблюдения в наборе данных. Шумы и выбросы являются достаточно общей проблемой в анализе данных. Выбросы могут как представлять собой отдельные наблюдения, так и быть объединенными в некие группы. Задача аналитика - не только их обнаружить, но и оценить степень их влияния на результаты дальнейшего анализа. Достаточно распространена практика проведения двухэтапного анализа - с выбросами и с их отсутствием - и сравнение полученных результатов.
Шумы и выбросы. Выбросы - резко отличающиеся объекты или наблюдения в наборе данных. Шумы и выбросы являются достаточно общей проблемой в анализе данных. Выбросы могут как представлять собой отдельные наблюдения, так и быть объединенными в некие группы. Задача аналитика - не только их обнаружить, но и оценить степень их влияния на результаты дальнейшего анализа. Достаточно распространена практика проведения двухэтапного анализа - с выбросами и с их отсутствием - и сравнение полученных результатов.
Визуализация данных позволяет представить данные, в том числе и выбросы, в графическом виде. Пример наличия выбросов изображен на диаграмме рассеивания на рисунке: мы видим несколько наблюдений, резко отличающихся от других (находящихся на большом расстоянии от большинства наблюдений).
Очевидно, что результаты Data Mining на основе грязных данных не могут считаться надежными и полезными. Однако наличие таких данных не обязательно означает необходимость их очистки или же предотвращения появления. Всегда должен быть разумный выбор между наличием грязных данных и временем, необходимым для их очистки.
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 2958; Нарушение авторских прав?; Мы поможем в написании вашей работы!