КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Транслятор
|
|
|
|
Транслятор для входного языка, порождаемого грамматикой предшествования можно построить по классической схеме, в которой чётко выделяются 3 части: лексический анализатор, распознаватель (синтаксический анализатор) и генератор (семантический анализатор);

Цель лексического анализа состоит в переводе исходной программы на стандартный входной язык компилятора и преобразовании её к виду, удобному для дальнейшей обработки на этапах синтаксического и семантического анализа.
В процессе лексического анализа обычно собираются из отдельных знаков (букв и цифр) простые синтаксические конструкции – лексемы. Лексемы – минимальные единицы информации, наделённые смыслом (идентификаторы, цифры, служебные слова и т.д.). При дальнейшей обработке такие простые конструкции рассматриваются как неделимые, поэтому оставлять их распознавание и сборку до этапа синтаксического анализа невыгодно.
В общем случае, в процессе лексического анализа необходимо выполнить следующее:
1) Перекодировать исходную программу, рассматриваемую как входная строка, и привести её к стандартному входному языку.
2) Выделить и собрать из отдельных знаков основные символы языка – лексемы.
Распознаватель решает задачу разбора. Алгоритм для грамматик предшествования уже рассмотрен. В процессе синтаксического анализа распознаватель использует матрицу предшествования (или функции предшествования) и таблицу порождающих правил грамматики входного языка. Каждая запись этой таблицы содержит одно из порождающих правил и (для некоторых правил) имя семантической подпрограммы, которую нужно выполнить, когда это правило применяется для редукции.
Результат работы распознавателя – разбор входной программы.
Генератор получает на вход разбор и, используя семантические подпрограммы, отвечающие применённым при разборе правилам, генерируют машинные команды или предложения другого входного языка.
Возможны 2 схемы работы транслятора.
Первая – использует блочный принцип, при котором части транслятора вызываются в последовательности: лексический анализатор, распознаватель, генератор. Каждая часть обрабатывает всю программу от начала до конца и только после этого работает следующая часть.
Во второй схеме используется принципы подпрограмм, когда все части транслятора работают совместно, каждый очередной входной символ лексического анализатора немедленно обрабатывается распознавателем, а каждый элемент разбора, если нужно, тут же вызывает требуемую семантическую подпрограмму генератора. Первую схему применяют, когда все части транслятора одновременно не умещаются в быстрой памяти машины, а вторую когда весь транслятор можно разместить в быстрой памяти.
На практике обе схемы часто комбинируют. Например, в начале работает только блок лексического анализа, а затем – блок, объединяющий распознаватель и генератор, построенный по схеме подпрограмм.
Описываемый транслятор можно использовать для перевода с  входного языка, грамматика которого является грамматикой предшествования. Для этого нужно прежде всего стандартизировать лексику входного языка, т.е. правила записи служебных слов, идентификаторов, констант и алфавита. Тогда алгоритм лексического анализатора будет определяться только особенностями устройств, применяемых для подготовки и ввода программ, и принятым стандартам ввода программ, и принятым стандартам входного языка распознавателя. Алгоритм распознавателя универсален в классе грамматик предшествования. Алгоритм генератора предельно прост – генератор вызывает требуемую семантическую подпрограмму и передаёт ей аргумент, определяемые элементом разбора.
входного языка, грамматика которого является грамматикой предшествования. Для этого нужно прежде всего стандартизировать лексику входного языка, т.е. правила записи служебных слов, идентификаторов, констант и алфавита. Тогда алгоритм лексического анализатора будет определяться только особенностями устройств, применяемых для подготовки и ввода программ, и принятым стандартам ввода программ, и принятым стандартам входного языка распознавателя. Алгоритм распознавателя универсален в классе грамматик предшествования. Алгоритм генератора предельно прост – генератор вызывает требуемую семантическую подпрограмму и передаёт ей аргумент, определяемые элементом разбора.
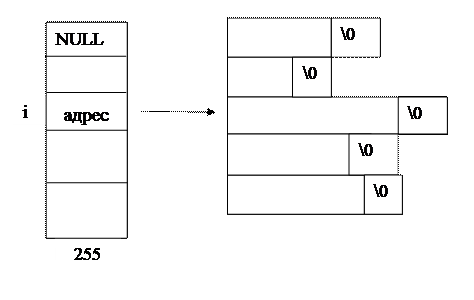
Может быть предложена следующая структура данных грамматик простого предшествования для быстрой работы.
Таблица терминалов:
Число терминалов 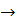 255 длинна терминала не >31, но неограниченна
255 длинна терминала не >31, но неограниченна
Таблица нетерминалов:
Начальный нетерминальный символ найти и поставит первым. После этого создать таблицу правил и правых частей и расширив таблицу нетерминалов.
Таблица нетерминалов:
| Адрес нетерминала | Индекс в таблице правил | Количество правил |
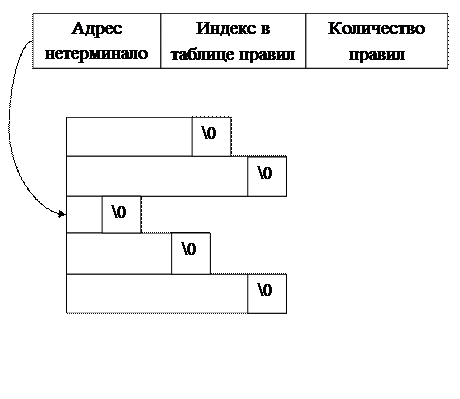
Таблица правил
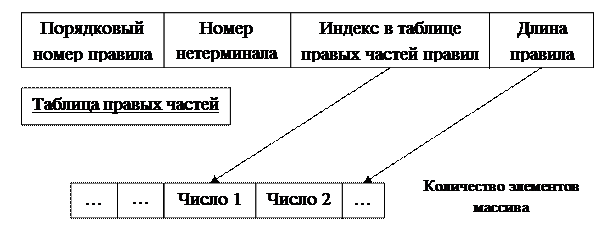
Где число =(+) код терминала (индекс в таблице терминалов), =(-) код нетерминала (-индекс в таблице - нетерминалов). Таблица правил сортируется в порядке возрастания кодов нетерминалов.
А программа распознавателя с известным алгоритмом с помощью приведённых таблиц, матрицы предшествования и цифровой свёртки терминальной цепочки лексическим анализатором может построить дерево разбора, из которого выброшены терминальные элементы, а метки вершин «нетерминалы» заменены на соответствующие номера правил. Дерево разбора может быть представлено матрицей, каждая строка которой хранит следующую информацию:
| Номер правила | Левая часть | количество | отец | Сын 1 | Сын 2 | … |
23.11.Синтаксис входного языка задается таблицей порождающих правил. Используя эту таблицу, матрица предшествования строится автоматически.
Семантика входного языка в терминах выходного языка отражена в семантических подпрограммах, которые составляются в ручную. В принципе, описываемый транслятор пригоден для перевода с нескольких входных языков, грамматики которых – грамматики простого предшествования, на несколько выходных языков. За универсальность транслятора в классе грамматик предшествования приходится платить невысокой эффективностью алгоритмов трансляции.
Рассмотрим применение метода предшествования для преобразования в польскую обратную запись предложения языка, порождаемые грамматикой G'1. Чтобы язык был более реалистичен, будем считать, что в качестве идентификаторов в языке может использоваться 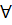 строчная латинская буква. Каждая такая буква воспринимается распознавателем, как идентификатор И.
строчная латинская буква. Каждая такая буква воспринимается распознавателем, как идентификатор И.
Составим таблицу порождающих правил, дополнив её семантическими подпрограммами для перевода её в польскую обратную запись:
| Номер правила | Порождающее правило | Семантическая подпрограмма для перевода. |
П → 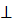 B
B→B'
B'→T
B'→B'+T
T→T'
T'→M
T'→T'xM
M→И
M→ (B) B
B→B'
B'→T
B'→B'+T
T→T'
T'→M
T'→T'xM
M→И
M→ (B)
| «Записать символ '+' в выходную строку» «Записать символ 'х' в выходную строку» «Записать идентификатор в выходную строку» |
Трансляции a + b x c в польскую обратную запись, используя распознаватель предшествования, таблицу порождающих правил и семантических подпрограмм и матрицу предшествования, получаем:
| Запись в выходную строку | Стек распознавателя | Отношение предшествования | Входная строка | N правила | Семантическая подпрограмма |
| а |
| 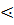
| a+bxc
| - | - |
 а а
| 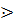
| +bxc
| u в выходную строку в выходную строку
| ||
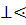 М М
|
| +bxc
| - | ||
| Т'
|
| +bxc
| - | ||
| Т
|
| +bxc
| - | ||
| В'
| 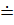
| +bxc
| - | - | |
В'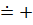
|
| bxc
| - | - | |
| В'b
|
| xc
| uв выходную строку
| ||
| b | B'+M
B'+T'
B'+T'X
B'T'XC
|
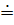
| xc
xc
c
| - - | -
-
-
uв выходную строку
|
| c | B'+T'X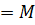
|
|
| xв выходную строку
| |
| x | B'+T'
B'+'T
|
|
| -
xв выходную строку
| |
| + | B'
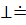 B B
|
|
| - - | |
| M |
Если последовательно выписать символы, записываемые в ходе анализа в стек распознавателя и при успешном разборе дополнить полученную строку парой П, то получим (,-разделитель):
⊥,а, М, T',T,B',+,b,M,T',x,c,M,T’,T, ,П – которая представляет собой ОПЗ разбора, полученную обходом дерева разбора: 
Cтроку можно записать короче, если заменить нетерминал номерами правил, применяемых для их получения: ,a,8,+,b,8,x,c,8,7,4.
Запись разбора в таком виде поступает на вход генератора кода. (см. схему)
Этап лексического анализа подготавливает исходную программу к синтаксическому анализу: убирает из текста программы комментарии, распознаёт и отделяет трансляционные директивы, выделяет и осуществляет свёртку лексем входного языка, что существенно влияет на выбор алгоритмов синтаксического анализа, который осуществляется не для входного языка L(G), а для преобразованного L(G’). Лексемы, наиболее часто выделяемые в языках программирования:
<идентификатор>, <служебные слова>, <целое число>, <вещественное число>, <одномерные разделители>, <двумерные разделители>, <комментарии>, <трансляционные дерективы> и т.п.
Если класс лексем L(Gk)(автоматный язык) бесконечен(например –идентификатор) или конечен, но достаточно велик, то выделяемые в программе лексемы tk 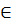 L(Gk), заполняются в специальной таблице к, они являются элементами справочника транслятора и могут обслуживаться в зависимости от реализации специальными программами обслуживания таблиц, либо стандартными программами обслуживания справочника (метод хеширования).
L(Gk), заполняются в специальной таблице к, они являются элементами справочника транслятора и могут обслуживаться в зависимости от реализации специальными программами обслуживания таблиц, либо стандартными программами обслуживания справочника (метод хеширования).
Лексический анализатор – это следующие отображение:
lex: 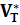 → (V'T)* - преобразование, реализуемое сканером для входного языка L(G). На входе сканер lex воспринимает цепочку х VT*, а на входе выдаёт цепочку лексем у (V'T)*
→ (V'T)* - преобразование, реализуемое сканером для входного языка L(G). На входе сканер lex воспринимает цепочку х VT*, а на входе выдаёт цепочку лексем у (V'T)*
Построение сканера осуществляется за несколько шагов:
1) Выделить во входном языке L(G) на основании описания его синтаксиса с помощью КС – грамматики G множество классов лексем Lk, 1≤k≤i, i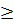 1.
1.
2) Видоизменить КС – грамматику G входного языка L(G), так чтобы она удовлетворяла следующим требованиям:
а) 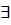 подмножество { U1,U2,…,Ui} VN (множество нетерминалов) i1, такое что, каждому, нетерминалу Uk можно поставить в соответствие автоматную грамматику Gk=(
подмножество { U1,U2,…,Ui} VN (множество нетерминалов) i1, такое что, каждому, нетерминалу Uk можно поставить в соответствие автоматную грамматику Gk=( 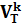 ,
, 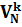 , Pk, Uk), порождающую автоматный язык фраз L(Gk)={tk|tk
, Pk, Uk), порождающую автоматный язык фраз L(Gk)={tk|tk 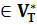 ,Uk=>*tk}.
,Uk=>*tk}.
б) Языки L(Gk) (k=1,…,i)попарно не пересекаются. Т.е. k,j [1,i],k 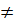 i, L(Gk)
i, L(Gk) 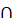 L(Gi)=
L(Gi)= 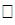 .
.
в) Каждая цепочка x 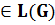 однозначно представляется как конкатенация подцепочек из языков L(Gk), т.е. x=tk1,tk2,…, tkn, n1 tkj L(Gkj) 1≤j≤n, 1≤kj≤i.
однозначно представляется как конкатенация подцепочек из языков L(Gk), т.е. x=tk1,tk2,…, tkn, n1 tkj L(Gkj) 1≤j≤n, 1≤kj≤i.
Определим новую КС – грамматику G'=(VT', VN', P',S'), где VN'=VN \{U1,…,Ui}. VT'={V1,…,Vi}, P'=P\ 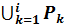
Очевидно, что для каждого предложения x найдётся!-ная цепочка y z;
b) S'=>*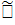 B->xαy;
B->xαy;
c) Fk(y)=Fk(z)
Следует x'Ay= 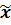 B
B 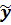 , т.е. x'= ,A=B, =y,
, т.е. x'= ,A=B, =y,  VT*.
VT*.
В определении отображено требование детерминированности выделения правой границы основы α, её однозначности и однозначности выбора А→α, для «свёртки» основы в анализируемой части х=x'α цепочки wi+1 =xy. Решение принимаемое на основании информации о правостороннем выводе цепочки x=x' и префиксе U цепочки y=Uy', U=Fk(u).
LR(k) грамматика впервые была изучена Кнутом, который нашёл для них эффективный метод построения детерминированных алгоритмов анализа.
Поведение МП автомата определяется верхним символом Tj магазина и k первыми символами (префикс u) непроанализированной части у цепочки wi+1 .
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 587; Нарушение авторских прав?; Мы поможем в написании вашей работы!