КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Иерархическая модель данных
|
|
|
|
МОДЕЛИ ДАННЫХ И ПОДЪЯЗЫКИ ДАННЫХ
Ядром любой системы базы данных является модель данных (концептуальная модель). Это ясно из архитектуры БнД. Диапазон структур данных, поддерживаемый в концептуальной модели, является тем фактором, который существенно влияет на все другие компоненты системы. Этот диапазон диктует конструкцию соответствующих подъязыков данных, т. к. для каждой операции подъязыка данных.
Ранняя модель, широко используемая, соответствует системам управления – иерархическая модель данных. Ей соответствует организация данных в иерархические файлы. В них записи связаны в (иерархические) древовидные структуры.
Один способ хранения:
Для хранения в ЗУ используется последовательный файл в виде левосписковой структуры. Показанная структура приводиться к виду А В1С1 С2 С3 В2 С4 С5 В3 С6 С7. Другой способ – использование встроенных указателей. В записи А должны иметься указатели на записи В1,В2,В3. В записи В1 – на записи С1 ,С2,С3 и т. д.
Помимо указателей на порожденные записи могут использоваться указатели на исходные записи: в записях С1 ,С2,С3 – на запись В1, в записи В1 – на А и т. д. Наибольшее удобство достигается в работе с иерархическими файлами в случае дополнения систем указателей двух указанных типов указателями на следующую подобную запись. Запись В1 содержит указатель на В2, В2 – на В3. Запись С1 à С2 à С3 , С4 à С5 , С6 à С7 .
В иерархической модели данных действуют наиболее жесткие внутренние ограничения на представление связей между сущностями. Основные внутренние ограничения иерархической модели данных:
- все типы связей функциональные типа 1:1, 1:M, M:1
- структура связей древовидная.
Древовидная структура данных, представленная в виде графа, включает набор элементов, распределенных по уровням следующим образом:
1) на первом уровне только один элемент – корень
2) к каждому элементу i-го уровня ведёт только один адрес связи от предыдущего элемента
3) к каждому элементу i-го уровня ведёт адрес связи только от элемента (i – 1)-го уровня. Любое нарушение условий означает, что структура является сетевой
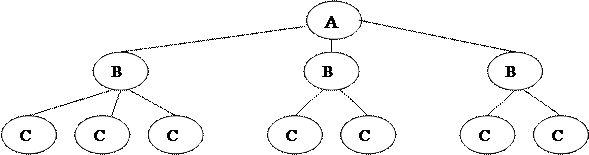 | |||||||
 | |||||||
 | |||||||
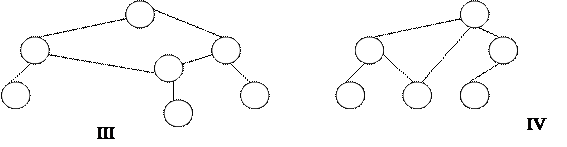 |
ОСНОВНЫЕ ПОНЯТИЯ
Сегмент тип сегмента экземпляр сегмента поле данных
Исходный и порожденный сегменты
Зависимый экземпляр сегмента
Подобные сегменты цепочка подобных сегментов
Корневой сегмент
Иерархический путь
Запись базы данных база данных
Ключевое поле поисковое поле
 |
| НАИМЕНОВАНИЕ | АДРЕС | НОМЕР ТЕЛЕФОНА |
Для пользователя
| НАИМЕНОВАНИЕ (КЛЮЧ) | ДАННЫЕ |
В базе данных
Информация представлена в виде “перевернутой” древовидной структуры. Это представление известно под названием иерархической схемы базы данных. Информация организована в сегменты. Сегмент представляет собой наименьшую единицу информации, которую может получить пользователь. Сегмент содержит поля данных.
База данных – содержит все корневые и все зависимые от них сегменты.
Внутри каждого сегмента содержатся поля. Некоторые поля называются ключевыми, некоторые – поисковыми.
Ключевое поле – поле упорядочения.
Ключевое поле служит для поддержания экземпляров сегмента в возрастающей последовательности. В каждом сегменте может быть только одно ключевое поле. Однако в общем случае не требуется. Поля упорядочения могут быть определены как уникальные или неуникальные.
Поисковое поле – используется для поиска данных. Может быть до 255 поисковых полей.
Существуют понятия тип сегмента и экземпляр сегмента.
IMS не более 255-типов сегментов, глубина иерархии – 15 уровней.
Количество экземпляров сегментов ограничено физической емкостью ЗУ.
Для описания связей сегментов в иерархической БД используются термины исходный и порожденный. Один и тот же сегмент может быть и исходным, и порожденным. Порожденный сегмент называется также зависимым, но это название относится больше к экземплярам сегментов.
Подобный – все экземпляры конкретного типа сегмента, расположенные под одним экземпляром исходного сегмента.
Совокупность всех подобных сегментов, относящихся к одному исходному, называется цепочкой подобных сегментов. Один сегмент является только исходным, не подчинен никакому другому сегменту. Он называется корневым. Через него осуществляется доступ ко всем зависимым сегментам.
Поиск сегментов осуществляется всегда по иерархическим путям. Путь начинается всегда от корневого сегмента и заканчивается всегда на самом нижнем уровне.
Запись – один экземпляр корневого сегмента и все зависимые от него сегменты (запись базы данных). После определения сегментов, принятие решения о виде иерархической структуры и выбора ключевых и поисковых полей проводится процесс генерации базы данных. Для этого создается управляющий блок, называемый описанием базы данных. (DBD – data base description). Это выполняется с помощью ЯОД.
ОПИСАНИЕ СТРУКТУРЫ ИЕРАРХИЧЕСКОЙ БД
DBD NAME = HOSPDBD, ACCESS = HISAM
DATASET DD1 = PRIME, OVFLW = OVERFLW, DEVICE = 3330
SEGM NAME = HOSPITAL, PARENT = 0, BYTES = 60
FIELD NAME = (HOSPNAME,SEQ,U), BYTES = 20,START = 1, TYPE = C
SEGM NAME = WARD, PARENT = HOSPITA L, BYTES = 31
FIELD NAME = (WARDNO,SEQ,U), BYTES = 2,START = 1, TYPE = C
FIELD NAME = BEDAVAIL, BYTES = 3,START = 9, TYPE = C
FIELD NAME = WARDTYPE, BYTES = 20,START = 12, TYPE = C
SEGM NAME = PATIENT, PARENT = WARD, BYTES = 125
FIELD NAME = (BEDIDENT,SEQ,U), BYTES = 4,START = 61, TYPE = C
FIELD NAME = PATNAME, BYTES = 20,START = 1, TYPE = C
FIELD NAME = DATEADMT, BYTES = 6,START = 65, TYPE = C
SEGM NAME = SYMPTOM, PARENT = PATIENT, BYTES = 77
FIELD NAME = (SYMPDATE,SEQ,U), BYTES = 6,START = 21, TYPE = C
FIELD NAME = DIAGNOSE, BYTES = 20,START = 1, TYPE = C
FIELD NAME =, BYTES = 20,START = 1, TYPE = C
SEGM NAME = TREATMNT, PARENT = PATIENT, BYTES = 113
FIELD NAME = (TRDATE,SEQ), BYTES = 6,START = 21, TYPE = C
FIELD NAME = TRTYPE, BYTES = 20,START = 1, TYPE = C
SEGM NAME = DOCTOR, PARENT = PATIENT, BYTES = 80
FIELD NAME = DOCTNAME, BYTES = 20,START = 1, TYPE = C
FIELD NAME = SPECIALT, BYTES = 20,START = 61, TYPE = C
SEGM NAME = FACILITY, PARENT = HOSPITAL, BYTES = 26
FIELD NAME = FACTYPE, BYTES = 20,START = 1, TYPE = C
Операнды PARENT определяют иерархическую структуру базы данных. Предложения SEGM кодируются в иерархической последовательности, которая строится в соответствии с правилом сверху вниз и слева направо.
В предложении FIELD операнд NAME от одного до трех подпараметров. Первый присваивает имя полю. Если других подпараметров нет, поле объявляется поисковым. Если SEQ – ключевое поле или поле упорядочения. Если U – уникальное ключевое поле.
С помощью DBD описали физическую базу данных. Для объединения двух или нескольких баз данных в новую иерархическую структуру применяется для описания логической базы данных. Это объединение осуществляется с помощью логических связей. Логические связи позволяют определить новые иерархические связи, не создавая новую физическую базу данных. Это является мощным средством для установления связи между данными, хранимыми в более чем одной физической базе данных, с тем, чтобы они были доступны в одной иерархической структуре. Кроме того, появляется возможность уменьшить дублирование информации.
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 540; Нарушение авторских прав?; Мы поможем в написании вашей работы!