КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методы получения случайных чисел и их машинная генерация
|
|
|
|
При построении стохастических имитационных моделей и их исследовании необходимо обеспечить возможность генерирования случайных величин. Для этой цели используются случайные числа, равномерно распределенные в интервале [0,1]. Естественно, что, если имитационная модель просчитывается на ЭВМ, необходимо 1) получать равномерно распределенные случайные числа и 2) использовать эти случайные числа для генерации случайных величин с требуемыми характеристиками.
Заметим, что получить на ЭВМ случайное число, равномерно распределенное в интервале [0,1], строго говоря, в принципе невозможно из-за конечной разрядности любой ЭВМ. Однако отличие получаемых реализаций случайной величины от равномерно распределенной оказывается незначительным для ЭВМ с высокой разрядностью.
Методы получения значений случайной величины, равномерно распределенной в интервале [0,1], можно разделить на три большие группы:
1) Использование физических датчиков (генераторов) случайных чисел.
2) Использование таблиц случайных чисел.
3) Получение псевдослучайных чисел.
Первая группа методов основана на использовании специальных устройств, являющихся источником собственно случайности. В качестве таких устройств могут использоваться генераторы шума, источники радиоактивного излучения и др. В них случайные импульсы формируются с помощью электронных схем (амплитудных селекторов, формирователей импульсов и т.п.) из случайного входного процесса. Эти устройства могут сопрягаться с ЭВМ. Для этого случайные импульсы на выходе генератора кодируются набором значений случайных двоичных чисел, которые заполняют разрядную сетку ЭВМ.
Общий недостаток физических датчиков случайных чисел – малое быстродействие и невозможность повторения последовательности случайных чисел, что существенно ограничивает область применения этих датчиков.
Вторая группа методов получения случайных чисел связана с использованием таблиц случайных чисел. Подобные таблицы составляются с помощью специальных технических устройств - " электронных рулеток " и могут иметь очень большой объем.
Основной недостаток использования таблиц случайных чисел при статистическом моделировании на ЭВМ - большая загрузка памяти вычислительной машины. В оперативной памяти такие таблицы обычно не располагаются ввиду их слишком большого объема. Размещение же чисел на внешних носителях существенно снижает быстродействие ЭВМ.
Поэтому таблицы случайных чисел очень редко используются при моделировании на ЭВМ.
Третья группа методов получения случайных чисел основана на использовании специальных алгоритмов генерации псевдослучайных последовательностей чисел. Подобные алгоритмы имеют рекуррентную структуру и жестко детерминированы. Задав начальные значения последовательности, мы однозначно определим все ее элементы. Однако полученный на выходе генератора массив чисел, можно рассматривать как совокупность реализаций случайной величины, так как числа имеют равномерное распределение и проходят все статистические тесты. Последовательности, полученные с помощью таких алгоритмов, называют псевдослучайными и обращаются с ними как с массивами реализаций случайной величины, используя для их анализа все методы математической статистики.
Объем массива чисел псевдослучайной последовательности всегда ограничен. В любой ЭВМ с конечной разрядностью N число возможных значений величины, лежащей в интервале [0,1], составляют 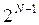 (один разряд знаковый). Следовательно, в последовательности чисел
(один разряд знаковый). Следовательно, в последовательности чисел 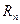 рано или поздно появится такое число
рано или поздно появится такое число 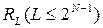 , которое уже там было. Начиная с этого числа, все предыдущие числа последовательности начнут повторяться.
, которое уже там было. Начиная с этого числа, все предыдущие числа последовательности начнут повторяться.
Таким образом, массив получаемых чисел псевдослучайной последовательности ограничен величиной L - отрезком апериодичности. Длина отрезка апериодичности зависит от метода генерации псевдослучайных чисел и типа ЭВМ, на которой этот генератор реализуется.
К настоящему времени разработано довольно много генераторов псевдослучайных чисел. Рассмотрим некоторые наиболее известные из них.
Мультипликативный конгруэнтный метод. Метод представляет собой арифметическую процедуру для генерирования конечной последовательности равномерно распределенных чисел. Основная формула метода имеет вид:
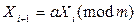
где a и m - неотрицательные целые числа. Согласно этому выражению мы должны взять случайное последнее число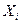 , умножить его на постоянный коэффициент a и взять модуль полученного числа по m (т.е. разделить на
, умножить его на постоянный коэффициент a и взять модуль полученного числа по m (т.е. разделить на 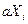 и остаток считать как
и остаток считать как 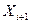 ). Поэтому для генерирования последовательности чисел необходимы начальное значение
). Поэтому для генерирования последовательности чисел необходимы начальное значение 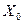 , множитель a и модуль m. Эти параметры выбирают так, чтобы обеспечить максимальный период и минимальную корреляцию между генерируемыми числами.
, множитель a и модуль m. Эти параметры выбирают так, чтобы обеспечить максимальный период и минимальную корреляцию между генерируемыми числами.
Правильный выбор модуля не зависит от системы счисления, используемой в данной ЭВМ. Для ЭВМ, где применяется двоичная система счисления, 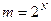 (N - число двоичных цифр в машинном слове). Тогда максимальный период (который получается при правильном выборе a и ) равен
(N - число двоичных цифр в машинном слове). Тогда максимальный период (который получается при правильном выборе a и ) равен
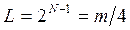 (N>2).
(N>2).
Выбор и a зависит также от типа ЭВМ. Для двоичной машины
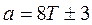 ,
,
где T может быть любым целым положительным числом, а - любым положительным, но нечетным числом. Следует заметить, что указанный выбор констант ускоряет и упрощает вычисления, но не обеспечивает получение периода максимальной длины. Большой период можно получить, если взять m, равное простому наибольшему числу, которое меньше, чем 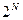 , и a, равное корню из m. Максимальная длина последовательности будет увеличена от m / 4 до (m - 1). (Метод Хатчинсона). Изложенный алгоритм в виде подпрограммы на языке Фортран с именем RANDU имеется в математическом обеспечении ЭВМ. При этом константы, используемые в подпрограмме, для 32-разрядного машинного слова имеют значения:
, и a, равное корню из m. Максимальная длина последовательности будет увеличена от m / 4 до (m - 1). (Метод Хатчинсона). Изложенный алгоритм в виде подпрограммы на языке Фортран с именем RANDU имеется в математическом обеспечении ЭВМ. При этом константы, используемые в подпрограмме, для 32-разрядного машинного слова имеют значения:
a = 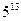 = 1220703125, 1/m = 0.4656613Е-9.
= 1220703125, 1/m = 0.4656613Е-9.
Смешанные конгруэнтные методы. На основе конгруэнтной формулы были созданы и испытаны десятки генераторов псевдослучайных чисел. Работа этих генераторов основана на использовании формулы
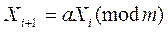 ,
,
где a, c, m - константы, обычно автоматически вычисляемые в подпрограмме.
Грин, Смит и Клем предложили аддитивный конгруэнтный метод. Он основан на использовании рекуррентной формулы
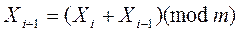 .
.
При Xo = 0 и 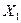 = 1 этот алгоритм приводит к особому случаю, называемому последовательностью Фибоначчи.
= 1 этот алгоритм приводит к особому случаю, называемому последовательностью Фибоначчи.
Другие алгоритмы основаны на комбинации двух конгруэнтных генераторов с перемешиванием получаемых последовательностей.
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 3480; Нарушение авторских прав?; Мы поможем в написании вашей работы!