КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Стандартный ДП-распознаватель
|
|
|
|
Стандартная система распознавания речи на основе ДП-процедуры и ЛПК имеет параметры. Входной речевой сигнал 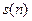 , записанный по стандартному телефонному каналу, ограничивается с помощью широкополосного фильтра в полосе 100 – 3200 Гц и оцифровывается с частотой квантования 6,67 кГц. Первый шаг – предобработка с помощью подчеркивания высоких частот. Далее речевой сигнал сегментируется в 45 мсек блоки (по 300 отсчетов), разделенных на 15 мсек части (по 100 отсчетов). Восьмиполюсный ЛПК анализ (автокорреляционный метод) работает на длине слова (после выделения конца слова детектором конца слова). Каждый полученный ЛПК-вектор далее используется или непосредственно, или обрабатывается процедурой ВК с помощью кодовой книги размерности M*. Полученная последовательность ЛПК-векторов, называемая тестовым образом, сравнивается с каждым образом эталонного множества с помощью ДП выравнивающего алгоритма, который последовательно вычисляет расстояние, связанное с текущим эталонным образом. Расстояния, вычисленные для всех эталонных образов, обрабатываются решающим правилом, которое классифицирует входное слово, или, возможно, упорядочивает по расстоянию b лучших кандидатов.
, записанный по стандартному телефонному каналу, ограничивается с помощью широкополосного фильтра в полосе 100 – 3200 Гц и оцифровывается с частотой квантования 6,67 кГц. Первый шаг – предобработка с помощью подчеркивания высоких частот. Далее речевой сигнал сегментируется в 45 мсек блоки (по 300 отсчетов), разделенных на 15 мсек части (по 100 отсчетов). Восьмиполюсный ЛПК анализ (автокорреляционный метод) работает на длине слова (после выделения конца слова детектором конца слова). Каждый полученный ЛПК-вектор далее используется или непосредственно, или обрабатывается процедурой ВК с помощью кодовой книги размерности M*. Полученная последовательность ЛПК-векторов, называемая тестовым образом, сравнивается с каждым образом эталонного множества с помощью ДП выравнивающего алгоритма, который последовательно вычисляет расстояние, связанное с текущим эталонным образом. Расстояния, вычисленные для всех эталонных образов, обрабатываются решающим правилом, которое классифицирует входное слово, или, возможно, упорядочивает по расстоянию b лучших кандидатов.
Эталонные образы слов распознавателя создаются с помощью обучающей процедуры. Для распознавателя, настраивающегося на диктора, обычно создается один эталон на слово словаря. Для независимого от диктора распознавателя множество из Q эталонных образов создается для каждого слова словаря с помощью процедуры кластеризации. Обычно около 12 произнесений на слово, выбранных на основе гомогенной популяции дикторов носителей языка, достаточно.
Если используется ВК кодовая книга на M* входов, как описано в разделе 5.1, можно хранить таблицу из M*x M* расстояний между всеми парами входов кодовой книги. В этом случае вычисление расстояний между любой парой входов кодовой книги становится простым нахождением пересечения. Таким образом, если мы обрабатываем с помощью ВК ЛПК-вектор тестовой последовательности и все эталонные образы, тогда вычисление расстояний с помощью ДП-процедуры становится тривиальным.
Новая методика уменьшения дисперсии ВК была предложена Сакое. В этом случае тестовый вектор не квантуется. Вместо этого вычисляется таблица расстояний между всеми тестовыми векторами и всеми входами кодовой книги, и далее используется для вычисления расстояний ДП-процедуры. В этом случае уменьшается дисперсия, потребный объем памяти (по сравнению с традиционным ВК), и главное, не требуется вычислений для определения локальных расстояний (это тоже табличный метод).
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 386; Нарушение авторских прав?; Мы поможем в написании вашей работы!