КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Создание и управление базой данных MS SQL Server
|
|
|
|
Реализация баз данных и таблиц MS SQL Server
Нормализация схем отношений между таблицами и данными
Как же осуществляется нормализация схем отношений между данными и таблицами?
Язык нормальных форм констатирует наличие или отсутствие определенных функциональных зависимостей (ФЗ) в таблицах реляционной базы данных и указывает на уровень избыточности и надежности данных в нормализованных отношениях. Методы нормализации основываются на применении понятия ФЗ и способов манипулирования ими. При выполнении реляционных операций над таблицами в базе данных каждый тип ФЗ может порождать определенный тип аномалий, который будет нарушать целостность данных в базе данных. Нормальная форма (НФ) представляет собой ограничение на схему базы данных, вводимое с целью устранения определенных нежелательных свойств при выполнении реляционных операций.
Различают несколько типов нормальных форм. Каждая из них ограничивает присутствие определенного класса ФЗ в таблице и устраняет присущие этому классу ФЗ аномалии в выполнении реляционных операций.
На практике при работе с базами данных, которые проектировали не профессиональные разработчики, а обычные пользователи, иногда можно столкнуться с таблицами вида:
| Наименование | Город | Адрес | Эл.почта | www | Вид. | Конт.информация |
| Хлебозавод N1 | Санкт-Петербург | Невский пр., д.100 | info@hleb1.ru | www.hleb1.ru | Поставщик | Паутин, зам.директора, т.010 |
| Хлебозавод N1 | Санкт-Петербург | Невский пр., д.100 | info@hleb1.ru | www.hleb1.ru | Поставщик | Мюдведов, нач.отдела сбыта, т.110 |
| ООО «Хлебушко» | Оренбург | Ул.Пушкина, 7 | hleb@hmail.ru | Клиент | Сидоров, директор, т.00900 | |
| ПБОЮЛ «Омега» | Красноярск | Ул.Стальная, 45 | omega@mmaaiill.ru | Клиент | Иванов, директор, т.901091 |
Конечно же, такая структура является неоптимальной по многим причинам:
1) данные в таблице являются избыточными. Например, адрес одной и той же фирмы повторяется несколько раз. Если таблица будет большой, то из-за избыточных данных нам потребуется много места на хранение, а производительность работы с таблицей упадет;
2) очень легко ошибиться, указав разный адрес (или адрес по-разному для одной и той же фирмы);
3) при изменении, к примеру, адреса для фирмы нам потребуется этот адрес поменять во всех записях для данной фирмы.
Кроме того, проблема с нашей таблицей заключается в том, что разнородные данные в столбце «конт.информация» слиты в единое целое. Один из принципов работы с базами данных заключается в том, что обычно очень просто свести в результате запроса вместе данные из разных столбцов, и очень сложно – произвести дальнейшую детализацию, то есть выделить, к примеру, из последнего столбца телефон.
Прежде чем говорить о том, как именно решать рассмотренные проблемы, то есть нормализовать данные, необходимо рассказать о нескольких принципах, которые лежат в основе нормализации.
Первый принцип – декомпозиция без потерь. Это значит, что после разбиения ненормализованной таблицы на несколько более мелких ее можно при желании объединить обратно без потери данных. Такое объединение обычно производится, конечно, не на уровне самой базы данных, а на уровне запросов.
Второй принцип – каждая запись сказать должна быть уникальна, то есть у нас должна быть возможность как-то отличать одну запись от другой. То есть каждая запись должна содержать в себе метку, которая уникально отличает ее от остальных записей. Такая метка называется ключом. Можно дать и более формальное определение ключа: ключ – это набор столбцов таблицы, значения которых уникально определяют строку.
Как выяснить, что в нашей таблице может быть ключом? Казалось бы, ответ прост – достаточно просто выполнить запрос к таблице и посмотреть, значения каких столбцов (или наборов столбцов) являются уникальными. Однако на практике все намного сложнее за счет того, что набор записей в таблице постоянно изменяется, и в нем могут появиться нарушающие значения.
Например, мы занимаемся автоматизацией работы очень маленькой фирмы, в которой всего три сотрудника – Иванов, Петров и Сидоров. Можно сделать ключом просто фамилию, но в этой ситуации мы столкнемся с проблемами, если фирма расширится и на работу придет однофамилец имеющегося сотрудника. Расширение ключа на еще два столбца – с именами и отчествами – также решение проблемы не является по причине того, что в итоге вполне может появиться полный тезка и однофамилец. Кроме того, если, к примеру, сотрудница сменит фамилию, то опять-таки могут возникнуть проблемы – она будет выглядеть для базы данных как новый сотрудник.
Пять нормальных форм
Таблица находится в первой нормальной форме (1НФ), если все атрибуты таблица являются простыми (требование атомарности атрибутов в реляционной модели), т.е. не имеют компонентов. Иными словами, атрибут (точнее, как мы покажем дальше, его домен) должен состоять из неделимых значений и не может включать в себя множество значений из более элементарных доменов. Так, например, дата не может считаться простым атрибутом. В большинстве случаев выполнить это требование достаточно просто. Каждый простой атрибут должен иметь свою колонку в таблице. Однако это часто приводит к дублированию данных в таблице.
Типичным примером неатомарности атрибута являются так называемые повторяющиеся группы, представляющие массив значений атрибута.
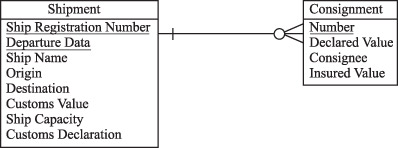
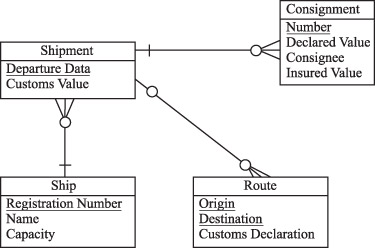
На следующем рисунке представлено ненормализованная таблица SHIPMENT (ОТГРУЗКА). Она содержит повторяющиеся группы, представляющие массив значений, 1st Consignments, 2st Consignments, 3st Consignments (три партии грузов).

Атрибуты, характеризующие партию грузов (показаны на следующем рисунке), – Consignee (грузополучатель), Insured Value (застрахованная стоимость) и Declared Value (объявленная стоимость), - повторяются для каждой такой партии. Отметим, что для такой таблицы следует ввести бизнес-правило, требующее, чтобы груз состоял не более чем из трех партий, поскольку четвертую партию вставить в этой таблице некуда.
Использование таблицы, представленной не в 1НФ, может породить в нашем случае следующие проблемы:
· если груз аннулируется и строка, связанная с грузом, удаляется из таблицы, то вместе с ней удаляются все сведения о партиях груза на борту судна;
· если на склад прибывает новая партия груза, и она еще не включена в состав груза, подлежащего отправке, то сведения о партии заносить некуда;
· необходимо вводить ограничение: в грузе не может быть более трех партий.
Приведение таблицы SHIPMENT к 1НФ заключается в изъятии данных о партиях груза из таблицы SHIPMENT и создании для них связанной подчиненной таблицы CONSIGNMENT (ПАРТИЯ_ГРУЗА). Результат приведения таблицы SHIPMENT к 1НФ представлен на предыдущем рисунке. Для такого представления сущности SHIPMENT не требуется вводить ограничительное бизнес-правило.
Таким образом, процедура приведения таблицы к 1НФ состоит в вынесении неатомарных атрибутов в отдельную подчиненную таблицу.
Будем считать атрибут таблицы ключевым, если он является элементом какого-либо ключа таблицы. В противном случае атрибут будет считаться неключевым атрибутом. Так в таблице (Город, Адрес, Почтовый_индекс) все атрибуты являются ключевыми, поскольку при заданных ФЗ «город, адрес -> почтовый_индекс» и «почтовый_индекс -> город» ключами являются пары (город, адрес) и (адрес, почтовый_индекс).
Таблицв находится во второй нормальной форме (2НФ), если оно находится в 1НФ, и все неключевые атрибуты функционально полно зависят от составного ключа таблицы. Иными словами, 2НФ требует, чтобы таблица не содержала частичных ФЗ.
Вновь обратимся к рассмотрению таблицы SHIPMENT, представленного на предыдущем рисунке. Она содержит частичную ФЗ: неключевой атрибут Ship Capacity (грузоподъемность корабля) не зависит от ключевого атрибута Departure Date (даты убытия), а зависит от ключевого атрибута Ship Registration Number (регистрационный номер корабля).
Использование таблицы, представленной не во 2НФ, может породить следующие проблемы:
· невозможно занести в базу данных название и грузоподъемность корабля, который не доставил еще ни одного груза, - можно только ввести для него фиктивный груз;
· если удалить кортеж из Shipment после отправки груза, то потеряются все данные о кораблях, для которых в настоящее время нет груза;
· невозможно отразить факт переоборудования корабля и получения им новой грузоподъемности; если переписать все предыдущие кортежи об этом корабле, то получится, что он в прошлом плавал недогруженным или перегруженным.
Приведение таблицы SHIPMENT ко 2НФ заключается в изъятии атрибутов частичной ФЗ из нее и создании связанной подчиненной таблицы SHIP. Результат приведения SHIPMENT ко 2НФ представлен на следующем рисунке.
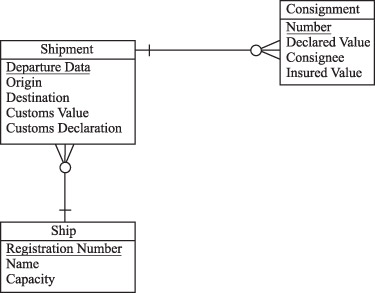
Таким образом, процедура приведения таблицы ко 2НФ состоит в выполнении двух проекций: проекции без атрибутов частичной ФЗ и проекции на часть составного ключа и те атрибуты, которые от него зависят.
Таблицы находится в третьей нормальной форме (3НФ), если она находится во 2НФ, и все неключевые атрибуты зависят только от первичного ключа. Иными словами, 3НФ требует, чтобы таблица не содержала транзитивных ФЗ неключевых атрибутов от ключа.
Формально это требование можно сформулировать следующим образом: схема таблицы R находится в 3НФ, если не существует ключа Х для R, множества атрибутов 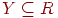 и неключевого атрибута А из R, не принадлежащего Х или Y, таких, что: 1)
и неключевого атрибута А из R, не принадлежащего Х или Y, таких, что: 1) 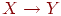 имеет место в R, 2)
имеет место в R, 2) 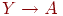 имеет место в R, но 3)
имеет место в R, но 3) 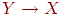 не имеет места в R.
не имеет места в R.
ФЗ представляют не только ограничения целостности, налагаемые на таблицы, но и связи между атрибутами, если они (связи) сохраняются в базе данных. Если таблица содержит частичную зависимость 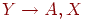 - ключ и
- ключ и 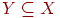 , то в каждом кортеже, используемом для хранения связи значений Х со значениями какого-либо другого атрибута, кроме А и Х, должна появиться связь между Y и A. Так, например, адрес поставщика дублируется для каждого поставляемого товара в таблице ПОСТАВКИ. Использование 3НФ исключает возможность возникновения такой ситуации (см. условие 3 в формальном определении 3НФ).
, то в каждом кортеже, используемом для хранения связи значений Х со значениями какого-либо другого атрибута, кроме А и Х, должна появиться связь между Y и A. Так, например, адрес поставщика дублируется для каждого поставляемого товара в таблице ПОСТАВКИ. Использование 3НФ исключает возможность возникновения такой ситуации (см. условие 3 в формальном определении 3НФ).
Наличие транзитивной зависимости 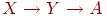 не позволяет связать значения Y и Х, если не существует значения А, связанного со значением Y. Это затрудняет вставку и обновление данных, которые необходимо выполнить сразу для пары связей, а в случае удаления данных приводит к потере связи.
не позволяет связать значения Y и Х, если не существует значения А, связанного со значением Y. Это затрудняет вставку и обновление данных, которые необходимо выполнить сразу для пары связей, а в случае удаления данных приводит к потере связи.
Вновь обратимся к рассмотрению таблицы SHIPMENT, представленной на предыдущем рисунке. Оно содержит транзитивную ФЗ: атрибут Customs Declaration (таможенная декларация) является по своей сути свойством атрибутов Origin (пункт отправления) и Destination (пункт назначения). Результат приведения SHIPMENT к 3НФ представлен на следующем рисунке.
Таким образом, процедура приведения таблицы к 3НФ состоит в выполнении двух проекций: проекции по правой части транзитивной ФЗ и проекции по левой части транзитивной ФЗ.
3НФ упрощает решение проблем контроля избыточности данных, интерпретации пустых значений, контроля за операциями модификации данных, только если в таблицах отсутствуют какие-либо другие ФЗ, в частности обратные ФЗ неключевого атрибута на один из атрибутов составного первичного ключа или многозначные ФЗ. В противном случае вышеперечисленные проблемы остаются неразрешенными. Для устранения таких проблем, связанных с существованием обратных ФЗ неключевых атрибутов на часть составного ключа, была предложена усиленная 3НФ или НФ Бойса-Кодда.
Таблица находится в нормальной форме Бойса-Кодда (НФБК), если она находится в 3НФ, и в ней отсутствуют зависимости ключевых атрибутов от неключевых атрибутов. Иными словами, НФБК допускает наличие только таких нетривиальных ФЗ, в которых ключ определяет один или более других атрибутов:  , где
, где 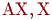 включает некоторый ключ.
включает некоторый ключ.
Таким образом, схема таблицы в НФБК обладает теми же достоинствами, что и схема в 3НФ, но устраняет некоторые дополнительные аномалии, не устраняемые 3НФ. Например, в таблицах (Город, Адрес, Почтовый_индекс), находящихся в 3НФ, невозможно записать кортеж для города с известным почтовым индексом, если не известен адрес с этим почтовым индексом. Данная таблица не находится в НФБК, так как имеет место ФЗ Почтовый_индекс  Город, а атрибут Почтовый_индекс не является ключом этой таблицы.
Город, а атрибут Почтовый_индекс не является ключом этой таблицы.
В отличие от 3НФ, исходные таблицы не всегда могут быть приведены в НФБК.
Предположим, что экипаж судна разделен на команды, каждая из которых отвечает за разные виды работ. Члены экипажа могут входить в разные команды, но в каждую команду входит только один руководитель. Команда может иметь несколько руководителей. Каждый член экипажа может руководить только одной командой. Это задается следующей таблицей:
| Таблица КОМАНДА | ||
| Член экипажа | команда | Руководитель |
| Иванов | Наблюдение | Прохоров |
| Иванов | Питание | Макаров |
| Петров | Наблюдение | Леонтьев |
| Модин | Наблюдение | Прохоров |
| Васин | Питание | Лазарев |
| Фролов | Обслуживание | Сидоров |
| Ивлев | Обслуживание | Сидоров |
Таблица находится в 3НФ, однако содержит аномалию удаления. Если Петрова удалить из команды наблюдения, то будет потеряна информация о том, что Леонтьев является руководителем команды наблюдения, и при назначении нового члена экипажа в команду наблюдения не будет известно, что у нее есть еще один руководитель, кроме Прохорова.
Заметим, что в предыдущих случаях разбиение происходило без создания избыточности данных из-за обратной зависимости атрибута на часть ключа. Приведение таблиц к НФБК заключается в создании дополнительной таблицы, содержащего сведения о руководителях команд (следующая таблица).
| Таблица РУКОВОДИТЕЛЬ_КОМАНДЫ | |
| Команда | Руководитель |
| Наблюдение | Прохоров |
| Питание | Макаров |
| Наблюдение | Леонтьев |
| Питание | Лазарев |
| Обслуживание | Сидоров |
Результат приведения таблицы КОМАНДА к НФБК представлен на следующем рисунке.

Таблица находится в четвертой нормальной форме (4НФ), если она находится в 3НФ или НФБК и все независимые многозначные ФЗ разнесены в отдельные таблицы с одним и тем же ключом. Иными словами, 4НФ применяется при наличии в таблицах более чем одной многозначной ФЗ и требует, чтобы они не содержали независимых многозначных ФЗ.
Рассмотрим таблицу, содержащую сведения о кораблях (Ship), совершаемых ими рейсах (Voyage) и капитанах (Captain). Это представлено в таблице ниже и на следующем рисунке.
| Таблица КАПИТАН_КОРАБЛЬ_РЕЙС | ||
| Акбар | Иванов | Красноярск – Дудинка |
| Акбар | Петров | Красноярск - Дудинка |
| Акбар | Ивлев | Красноярск - Дудинка |
| Акбар | Прохоров | Красноярск - Дудинка |
| Акбар | Лазарев | Дудинка - Мурманск |
| Акбар | Прохоров | Дудинка - Лондон |
| Жучка | Петров | Дудинка - Марсель |
| Жучка | Фролов | Дудинка – Стокгольм |
| Жучка | Ивлев | Дудинка – Стокгольм |

Таблица находится в НФБК и содержит только многозначные ФЗ. Однако имеет место аномалия удаления: если капитан Петров уйдет в отставку, и все кортежи о нем будут удалены, то будут потеряны сведения о том, что корабль «Жучка» совершает рейсы Дудинка - Марсель. Если добавить новый рейс, то, возможно, придется ввести несколько кортежей в наши таблицы.
Приведение таблиц к 4НФ заключается в выделении для каждой многозначной ФЗ своей таблице, как показано на следующем рисунке.

Таким образом, процедура приведения таблиц к 4НФ сводится к выполнению нескольких проекций, в данном случае двух проекций.
Как можно заметить, нормализация выполнялась путем разложения (декомпозиции) схем таблиц. Очевидно, что при таком подходе должен соблюдаться принцип обратимости: соединение проекций должно приводить к исходным таблицам. Это предполагает отсутствие потери кортежей; появление ранее не существовавших кортежей; сохранение ФЗ (семантика взаимосвязей между данными не должна нарушаться).
На самом же деле декомпозиция схем не всегда гарантирует обратимость. Это обстоятельство связано с существованием класса ФЗ по соединению. Если таблица удовлетворяет ФЗ по соединению, то оно может быть восстановлено по своим проекциям. Таблицы, содержащие более трех МФЗ, требуют особого внимания при построении логической модели реляционной базы данных. Также 4НФ не устраняет избыточность данных полностью, поэтому требуется дальнейшая декомпозиция схем.
Таблица находится в пятой нормальной форме (5НФ), если оно находится в 4НФ и удовлетворяет зависимости по соединению относительно своих проекций. 5НФ называют также нормальной формой с проецированием соединений. Она используется для разрешения трех и более таблиц, которые связаны более чем тремя ФЗ по типу «многие-ко-многим».
Рассмотрим таблицы с несколькими многозначными зависимостями, представленные на следующем рисунке.
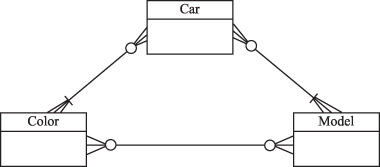
Рассмотрим сначала ее как три изолированных таблицы со степенью связи «многие-ко-многим»:

Каждый автомобиль имеет определенный цвет и модель. Некоторые цвета характерны только для определенных моделей. Такие таблицы разрешаются введением связывающих таблиц, в данном случае таких таблиц три:
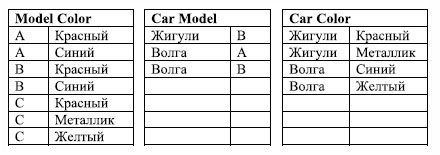
Предположим, что клиент желает приобрести автомобиль синего цвета модели С, при этом марка автомобиля роли не играет. Запрос к базе данных на поиск такого автомобиля будет содержать два соединения между тремя таблицами Car, Car Color и Car Model по атрибуту наименование машины и два предиката: цвет = синий и модель = С.
Результат выполнения запроса будет удивителен: есть и Волга, и Жигули. Однако из таблицы Model Color видно, что автомобиля синего цвета модели С не существует. Появляется несуществующий кортеж. Такое явление представляет собой аномалию проецирования соединений и пример нарушения 5НФ.
Приведение таблиц к 5НФ заключается во введении еще одной таблицы, связывающей три исходных, как показано на следующем рисунке.
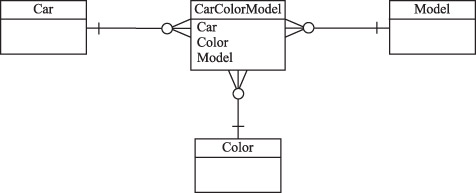
Таким образом, процедура приведения таблицы, содержащей многозначные ФЗ, к 5НФ состоит в построении связывающей таблицы, позволяющей исключить появление в соединениях ложных кортежей.
Следовательно, каждая нормальная форма ограничивает определенный тип ФЗ и устраняет аномалии обработки данных. Нормальные формы характеризуются следующими свойствами:
· 1НФ – все атрибуты простые;
· 2НФ – таблица находится в 1НФ и не содержит частичных ФЗ;
· 3НФ – таблица находится во 2НФ и не содержит транзитивных ФЗ от ключа;
· НФБК – таблица находится в 3НФ и не содержит ФЗ ключей от неключевых атрибутов;
· 4НФ, применяется при наличии более чем одной многозначной ФЗ. Таблица находится в НФБК или 3НФ и не содержит независимых многозначных ФЗ;
· 5НФ – таблица находится в 4НФ и не содержит ФЗ по соединению.
Создание базы данных SQL Server
Первым этапом реализации физической базы данных является создание объекта «база данных». Создают этот объект и определяют его характеристики на основе информации, полученной при определении требований к системе и деталей, определенных при проектировании базы данных. Характеристики объекта «база данных» можно изменить и после его создания.
Во время создания базы данных необходимо определить ее имя, размер, а также файлы и группы файлов, в которых она будет храниться. Прежде чем создавать базу данных, следует усвоить несколько правил:
• право на создание базы данных по умолчанию принадлежит членам стандартных ролей на сервере sysadmin и dbcreator. однако это право может быть предоставлено и другим пользователям;
• пользователь, создавший базу данных, становится ее владельцем;
• на сервере может быть создано до 32 767 баз данных;
• имя базы данных должно соответствовать правилам, определенным для идентификаторов.
Для хранения базы данных используются три типа файлов: основные, в которых находится информация для запуска; дополнительные, в которых хранятся все данные, не поместившиеся в основном файле; файлы журнала транзакций, содержащие данные журнала, необходимые для восстановления базы данных. Любая база данных состоит по крайней мере из двух файлов: основного и файла журнала транзакций.
Во время создания базы данных составляющие ее файлы заполняются нулевыми значениями, чтобы уничтожить все данные, которые могли остаться на диске после удаленных ранее файлов. Хотя из-за этого файлы создаются дольше, во время обычной работы базы данных ОС освобождается от заполнения файлов нулевыми значениями при первой записи в них. Эта функция повышает производительность каждодневных операций.
При создании базы данных следует задать ее максимальный размер. Это позволяет предотвратить рост файла при добавлении данных вплоть до исчерпания свободного места на диске.
SQL Server создает новую базу данных в два этапа:
1. используя копию базы Model, SQL Server инициализирует новую базу данных и ее метаданные;
2. после этого SQL Server заполняет оставшуюся часть базы данных (кроме страниц с внутренними данными, отражающими использование дискового пространства, занятого базой данных) пустыми страницами.
Любые пользовательские объекты из базы Model копируются во все новые базы данных. К базе данных Model можно добавлять любые объекты: таблицы, представления, хранимые процедуры, типы данных и т. д., которые следует включить в новые базы данных. Каждая новая база данных наследует все настроечные параметры базы Model.
Компоненты базы данных SQL Server
База данных SQL Server состоит из набора таблиц с данными и других объектов; представлений, индексов, хранимых процедур и триггеров, обеспечивающих обработку данных. В базах данных обычно хранится информация, связанная с некоторым субъектом или процессом, например сведения о покупателях, используемые розничными торговцами, или данные производителя о продажах товаре.
Методы создания баз данных SQL Server
SQL Server предоставляет несколько методов для создания базы данных, в том числе оператор Trarsact-SQL CREATE DATABASE и мастер Create Database, который можно вызвать в SQL Server Management Studio.
Средств оператора CREATE DATABASE обычно достаточно, чтобы создать базу данных со всеми ее файлами. Оператор CREATE DATABASE позволяет задать несколько параметров, определяющих характеристики базы данных, например максимальный размер или инкремент роста файла. При исполнении простого оператора CREATE DATABASE <имя_БД> без параметров создается база данных того же размера, что и Model. Подробное описание параметров оператора CREATE DATABASE можно найти в справочнике по языку Transact-SQL в SQL Server Books Online.
Оператор CREATE DATABASE можно исполнить в SQL Query Analyzer. Следующая программа-пример создает базу данных под названием Products и задает для нее один основной файл. Также автоматически создается файл журнала транзакций размером 1 Мб. Поскольку в параметре SIZE для основного файла не заданы ни мегабайты, ни килобайты, размер основного файла измеряется в мегабайтах. Поскольку не заданы параметры файла журнала транзакций, в том числе параметр MAXSIZE, этот файл может увеличиваться, пока не заполнит все место на диске.
USE master
GO
CREATE DATABASE Products
ON
(
NAME = prods_dat,
FILENAME = 'c:\temp\prods.mdf',
SIZE = 4,
MAXSIZE = 10,
FILEGROWTH = 1
)
GO
Аналогичного результата можно достичь с использованием «мастера» CreateDatabase в составе SQL Server Management Studio или консоли выполнения запросов sqlcmd.exe из состава инструментария, поставляемого с SQL Server.
Управление базой данных SQL Server
С новой базой данных SQL Server можно выполнять различные действия: просматривать сведения о ней, модифицировать ее характеристики или удалить ее.
Если необходимо устранить неполадки и принять решения о внесении изменений в базу данных, то стоит просмотреть определение базы данных и параметры ее конфигурации.
SQL Server предоставляет несколько методов просмотра сведений о базе данных: системную хранимую процедуру sp_helpdb, оператор DATABASEPROPERTYEX и SQL Server Management Studio.
Системная хранимая процедура sp_helpdb выдает информацию обо всех базах данных или только о заданной. Оператор DATABASEPROPERTYEX возвращает текущее значение настроечного параметра или свойства только для заданной базы данных. За один раз этот оператор возвращает значение лишь одного свойства. Для просмотра настроечных параметров базы данных можно также использовать SQL Server Management Studio. Для этого в консоли достаточно открыть диалоговое окно Properties для нужной базы данных. В диалоговом окне Properties имеется несколько вкладок со сведениями о конфигурации базы данных. Использование данных консоли, процедуры и оператора очевидны и примеры их работы мы по понятным причинам приводить не будем.
Разрешается модифицировать исходное определение базы данных после ее создания. Однако иногда перед внесением изменений требуется вывести базу данных из обычного режима работы. В следующей таблице перечислены типы изменений свойств базы данных с указанием способа их внесения. Подробно решение каждой из задач описано в SQL Server Books Online.
| Тип изменения | Методы внесения изменения |
| Увеличение размера базы данных | Оператор ALTER DATABASE, свойства базы данных в SQL Server Management Studio |
| Изменение физического местоположения базы данных | Оператор ALTER DATABASE |
| Уменьшение размера базы данных | Оператор DBCC SHRINKDATABASE, задача Shrink -> Database в SQL Server Management Studio, доступная через узел базы данных |
| Задание автоматического уменьшения размера базы данных | Системная хранимая процедура sp_dboption, свойства базы данных в SQL Server Management Studio |
| Уменьшение размера файла базы данных | Оператор DBCC SHRINKFILE |
| Добавление файла данных или файла журнала | Оператор ALTER DATABASE, свойства базы данных в SQL Server Management Studio |
| Удаление файла данных или файла журнала | Оператор ALTER DATABASE, свойства базы данных в SQL Server Management Studio |
| Добавление группы файлов | Оператор ALTER DATABASE, свойства базы данных в SQL Server Management Studio |
| Изменение группы файлов по умолчанию | Оператор ALTER DATABASE |
| Изменение параметров базы данных | Оператор ALTER DATABASE, системная хранимая процедура sp_dboption, свойства базы данных в SQL Server Management Studio |
| Переименование | Системная хранимая процедура базы данных sp_renamedb |
| Изменение владельца базы данных | Системная хранимая процедура sp_changedbowner |
Можно задать несколько параметров уровня базы данных, определяющих ее характеристики. Эти параметры доступны для изменения только системному администратору, владельцу базы данных, а также членам стандартных ролей на сервере sysadmin и dbcreator и фиксированной роли в базе данных db_owner. Для каждой базы данных эти параметры уникальны и не влияют на другие базы данных. Задать параметры базы данных можно в конструкции SET оператора ALTER DATABASE, системной хранимой процедуре sp _dboption, а также — в SQL Server Management Studio.
Параметры, общие для сервера, задаются с помощью системной хранимой процедуры sp_configure или SQL Server Management Studio. Параметры уровня соединения определяют посредством оператора SET.
После настройки параметра базы данных автоматически генерируется контрольная точка, благодаря чему изменения вступают в силу немедленно.
В SQL Server существуют пять категорий параметров базы данных, которые перечислены в следующей таблице.
| Тип параметра | Описание |
| Auto | Управляет некоторыми автоматическими режимами и функциями |
| Cursor | Управляет поведением и сферой действия курсора |
| Recovery | Управляет моделью восстановления базы данных |
| SQL | Управляет параметрами совместимости со стандартом ANSI SQL |
| State | Управляет состоянием базы данных (подключена она или отключена). Определяют, кто может подключиться к базе данных, а также находится ли она в режиме «только для чтения» (для контроля за завершением соединений при переходе базы данных из одного состояния в другое могут использоваться специальные конструкции) |
Если несистемная база больше не нужна (или она перемещена в другую базу данных или на другой сервер), ее можно удалить. При удалении базы файлы и их данные удаляются с диска на сервере. База данных удаляется навсегда и не может быть восстановлена иначе как со сделанной ранее резервной копии. Удалить системные базы данных (Msdb, Master, Model и Tempdb) невозможно.
После удаления базы данных необходимо сделать резервную копию базы Master, поскольку при удалении в ней обновляются системные таблицы. При восстановлении базы данных Master у любой базы, удаленной после создания последней резервной копии, останутся ссылки в системных таблицах, что может привести к появлению сообщений об ошибках.
Базу данных удаляют с помощью оператора DROP DATABASE или из консоли в SQL Server Management Studio.
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 954; Нарушение авторских прав?; Мы поможем в написании вашей работы!