КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Понятие нормализации сущностей
|
|
|
|
Качественная разработка логической модели данных имеет большое значение для проектирования баз данных, так как она, с одной стороны, обеспечивает адекватность данных предметной области, а с другой стороны, определяет структуру физической базы данных и, следовательно, её эксплуатационные характеристики.
Одни и те же данные могут группироваться в сущности, различными способами, то есть, возможна организация различных наборов сущности взаимосвязанных информационных объектов предметной области. Группировка атрибутов в сущности должна быть рациональной, предельно сокращающей дублирование данных и упрощающей процедуры их обработки и обновления.
Определенный набор сущностей обладает лучшими свойствами при включении, модификации и удалении данных, если он отвечает определенным требованиям нормализации сущностей. Нормализация сущностей — это формальный аппарат ограничений на их формирование, который позволяет устранить дублирование данных, обеспечить их непротиворечивость и уменьшить затраты на поддержание базы данных.
На практике наиболее часто используются понятия первой, второй и третьей нормальных форм.
Сущность называется нормализованной или приведенной к первой нормальной форме (1НФ), если все ее атрибуты простые или атомарные - далее неделимые Сущность, находящаяся в первой нормальной форме, будет иметь следующие свойства:
· аатрибуты не упорядочены и различаются по наименованиям;
· ввсе значения атрибутов атомарные.
Первая нормальная форма допускает хранение в одной сущности разнородной информации, избыточности данных, приводящих к неадекватности логической модели данных предметной области. Таким образом, первой нормальной формы недостаточно для правильного моделирования данных.
Чтобы рассмотреть вопрос приведения сущностей ко второй нормальной форме, рассмотрим понятие функциональной зависимости.
Пусть имеется сущность R. Множество атрибутов Y функционально зависимо от множества атрибутов X, если для любого состояния сущности R для любых кортежей r1,r2 R из того, что r1X = r2X следует, что r1Y = r2Y, то есть во всех кортежах, имеющих одинаковые значения атрибутов X, значения атрибутов Y также совпадают в любом состоянии сущности R.
Множество атрибутов X называется детерминантом функциональной зависимости, а множество атрибутов Y называется зависимой частью.
Функциональные зависимости отражают взаимосвязи, обнаруженные между объектами предметной области и являются дополнительными ограничениями, определяемыми предметной областью. Функциональная зависимость это семантическое понятие. Она возникает, когда по значениям одних данных в предметной области можно определить значения других данных. Например, зная табельный номер сотрудника, можно определить его фамилию. Функциональная зависимость задает дополнительные ограничения на данные, которые могут храниться в сущностях. Для корректности базы данных необходимо при выполнении операций модификации базы данных проверять все ограничения, определенные функциональными зависимостями.
Функциональная зависимость атрибутов утверждает лишь то, что для каждого конкретного состояния предметной области по значению одного атрибута можно однозначно определить значение другого атрибута.
Сущность находится во второй нормальной форме (2НФ), если онам находится в первой нормальной форме (1НФ) и не имеет не ключевых атрибутов, зависящих от части составного ключа.
Из определения 2НФ следует, что если ключ сущности является простым, то сущность автоматически находится во второй нормальной форме.
Однако сущности, приведенные ко второй нормальной форме, все-таки содержат разнородную информацию и требуют написания большого количества дополнительного программного кода в виде триггеров для корректной работы базы данных. Следующим шагом по улучшению качества сущностей является приведение их к третьей нормальной форме.
Сущность находится в третьей нормальной форме (3НФ), если оно находится в 2НФ и все не ключевые атрибуты взаимно независимы.
Модель данных, состоящая из сущностей, приведенных к 3НФ, является адекватной модели предметной области и требует наличия только тех триггеров, которые поддерживают ссылочную целостность. Такие триггеры являются стандартными и их разработка не требует больших усилий.
Таким образом, разработку логической модели данных можно представить как определение сущностей, отображающих понятия предметной области, и приведение их к третьей нормальной форме.
Алгоритм нормализации сущностей можно представить следующим образом:
1 этап – приведение к 1НФ. Определить и задать сущности, отображающие понятия предметной области.
2 этап – приведение к 2НФ. Если в некоторых сущностях обнаружена зависимость атрибутов от части сложного ключа, то следует провести их декомпозицию следующим образом: атрибуты, которые зависят от части сложного ключа выносятся в отдельную сущность вместе с этой частью ключа, а в исходной сущности остаются все ключевые атрибуты.
Исходная сущностье – S (K1,K2,A1,A2,…,An,B1,B2,…,Bm).
Ключ { K1,K2 } – сложный ключ.
Функциональные зависимости:
{K1,K2} 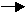 { A1,A2,…,An,B1,B2,…,Bm } – зависимость всех атрибутов от ключа отношения.
{ A1,A2,…,An,B1,B2,…,Bm } – зависимость всех атрибутов от ключа отношения.
{ K1 } { A1,A2,…,An } – зависимость некоторых атрибутов от части сложного ключа.
После декомпозиции отношения получаем:
R1 (K1,K2,B1,B2,…,Bm) – оставшаяся часть исходной сущности.
R2 (K1,A1,A2,…,An) – новая сущность.
3 этап – приведение к 3НФ. Если в некоторых сущностях обнаружена зависимость одних не ключевых атрибутов от других не ключевых атрибутов, то проводится декомпозиция этих отношений следующим образом: не ключевые атрибуты, которые зависят от других не ключевых атрибутов, образуют отдельную сущность. В новой сущности ключом становиться атрибуты от которых зависят другие не ключевые атрибуты
Например, исходное отношение – R (K,A1,A2,….,An,B1,B2,…,Bm).
K – ключ.
Функциональные зависимости:
K { A1,A2,…,An,B1,B2,…,Bm }.
{ A1,A2,…,An } { B1,B2,…,Bm }.
После декомпозиции отношения получаем:
R1 (K,A1,A2,…,An) – остаток от исходного отношения с ключом К.
R2 (A1,A2,…An,B1,B2,…,Bm) – новое отношение с детерминантом функциональной зависимости (A1,A2,…,An) в виде ключа.
На практике достаточно редко разработка логической модели данных производится по приведенному алгоритму. Чаще используются различные варианты ER-диаграмм, поддерживаемые соответствующими case-средствами. Основные понятия ER-диаграмм излагаются в стандартах IDEF1 и IDEF1X. Приведенный же алгоритм полезен как иллюстрация проблем, которые могут возникать при определении на первых этапах проектирования слабо нормализованных отношений. Понимание этих проблем особенно важно при проведении модификаций и доработок баз данных, когда вводятся новые сущности, появляются новые зависимости и тому подобное
Пример разработки простой модели данных.
(ER-диаграммы)
При разработке моделей сущность – связь мы должны получить следующую информацию о предметной области:
1. Список сущностей предметной области.
2. Список атрибутов сущностей.
3. Описание взаимосвязей между сущностями.
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным. Разработав первый приближенный вариант диаграмм, мы уточняем их, опрашивая экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Предположим, что перед нами стоит задача разработать информационную систему по заказу некоторой оптовой торговой фирмы. В первую очередь мы должны изучить предметную область и процессы, происходящие в ней. Для этого мы опрашиваем сотрудников фирмы, читаем документацию, изучаем формы заказов, накладных и т.п.
Например, в ходе беседы с менеджером по продажам, выяснилось, что он (менеджер) считает, что проектируемая система должна выполнять следующие действия:
- Хранить информацию о покупателях.
- Печатать накладные на отпущенные товары.
- Следить за наличием товаров на складе.
Выделим все существительные в этих предложениях - это будут потенциальные кандидаты на сущности и атрибуты, и проанализируем их (непонятные термины будем выделять знаком вопроса):
- Покупатель - явный кандидат на сущность.
- Накладная - явный кандидат на сущность.
- Товар - явный кандидат на сущность
- (?)Склад - а вообще, сколько складов имеет фирма? Если несколько, то это будет кандидатом на новую сущность.
- (?)Наличие товара – это, скорее всего, атрибут, но атрибут какой сущности?
Сразу возникает очевидная связь между сущностями - "покупатели могут покупать много товаров" и "товары могут продаваться многим покупателям". Первый вариант диаграммы выглядит так:
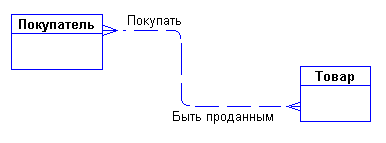
Рис. 49
Задав дополнительные вопросы менеджеру, мы выяснили, что фирма имеет несколько складов. Причем, каждый товар может храниться на нескольких складах и быть проданным с любого склада.
Куда поместить сущности "Накладная" и "Склад" и с чем их связать? Спросим себя, как связаны эти сущности между собой и с сущностями "Покупатель" и "Товар"? Покупатели покупают товары, получая при этом накладные, в которые внесены данные о количестве и цене купленного товара. Каждый покупатель может получить несколько накладных. Каждая накладная обязана выписываться на одного покупателя. Каждая накладная обязана содержать несколько товаров (не бывает пустых накладных). Каждый товар, в свою очередь, может быть продан нескольким покупателям через несколько накладных. Кроме того, каждая накладная должна быть выписана с определенного склада, и с любого склада может быть выписано много накладных. Таким образом, после уточнения, диаграмма будет выглядеть следующим образом:
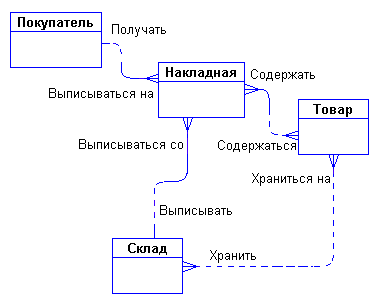
Рис. 50
Пора подумать об атрибутах сущностей. Беседуя с сотрудниками фирмы, мы выяснили следующее:
- Каждый покупатель является юридическим лицом и имеет наименование, адрес, банковские реквизиты.
- Каждый товар имеет наименование, цену, а также характеризуется единицами измерения.
- Каждая накладная имеет уникальный номер, дату выписки, список товаров с количествами и ценами, а также общую сумму накладной. Накладная выписывается с определенного склада и на определенного покупателя.
- Каждый склад имеет свое наименование.
- Снова выпишем все существительные, которые будут потенциальными атрибутами, и проанализируем их:
- Юридическое лицо - термин риторический, мы не работаем с физическими лицами. Не обращаем внимания.
- Наименование покупателя - явная характеристика покупателя.
- Адрес - явная характеристика покупателя.
- Банковские реквизиты - явная характеристика покупателя.
- Наименование товара - явная характеристика товара.
- (?)Цена товара - похоже, что это характеристика товара. Отличается ли эта характеристика от цены в накладной?
- Единица измерения - явная характеристика товара.
- Номер накладной - явная уникальная характеристика накладной.
- Дата накладной - явная характеристика накладной.
- (?)Список товаров в накладной - список не может быть атрибутом. Вероятно, нужно выделить этот список в отдельную сущность.
- (?)Количество товара в накладной - это явная характеристика, но характеристика чего? Это характеристика не просто "товара", а "товара в накладной".
- (?)Цена товара в накладной - опять же это должна быть не просто характеристика товара, а характеристика товара в накладной. Но цена товара уже встречалась выше - это одно и то же?
- Сумма накладной - явная характеристика накладной. Эта характеристика не является независимой. Сумма накладной равна сумме стоимостей всех товаров, входящих в накладную.
- Наименование склада - явная характеристика склада.
В ходе дополнительной беседы с менеджером удалось прояснить различные понятия цен. Оказалось, что каждый товар имеет некоторую текущую цену. Эта цена, по которой товар продается в данный момент. Естественно, что эта цена может меняться со временем. Цена одного и того же товара в разных накладных, выписанных в разное время, может быть различной. Таким образом, имеется две цены - цена товара в накладной и текущая цена товара.
С возникающим понятием "Список товаров в накладной" все довольно ясно. Сущности "Накладная" и "Товар" связаны друг с другом отношением типа много-ко-многим. Такая связь, как мы отмечали ранее, должна быть расщеплена на две связи типа один-ко-многим. Для этого требуется дополнительная сущность. Этой сущностью и будет сущность "Список товаров в накладной". Связь ее с сущностями "Накладная" и "Товар" характеризуется следующими фразами - "каждая накладная обязана иметь несколько записей из списка товаров в накладной", "каждая запись из списка товаров в накладной обязана включаться ровно в одну накладную", "каждый товар может включаться в несколько записей из списка товаров в накладной", " каждая запись из списка товаров в накладной обязана быть связана ровно с одним товаром". Атрибуты "Количество товара в накладной" и "Цена товара в накладной" являются атрибутами сущности " Список товаров в накладной".
Точно также поступим со связью, соединяющей сущности "Склад" и "Товар". Введем дополнительную сущность "Товар на складе". Атрибутом этой сущности будет "Количество товара на складе". Таким образом, товар будет числиться на любом складе и количество его на каждом складе будет свое.
Теперь можно внести все это в диаграмму:
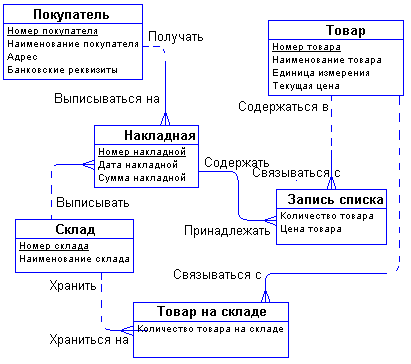
Рис. 51
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 1312; Нарушение авторских прав?; Мы поможем в написании вашей работы!