КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Операции, определенные по умолчанию над структурированными объектами
|
|
|
|
Address set_current(address next)
{
address prev = current;
current = next;
return prev;
}
void main (){
address Nik={"Jim Dandy", 61, "South Street", "New Providence", {‘N’,‘J’}, 1974}, f2;
f2 = set_current(Nik);
}
Напомним, что при передачи по значению формальным параметрам присваивается значения фактических параметров в строгом соответствии с порядком в списке. В данном случае next является формальным параметром, Nik – фактическим. Следовательно все поля объекта next получат те же значения, что и поля объекта Nik. Поскольку функция set_current () возвращает структурированный объект address по значению, то в точке вызова функции будет создан неименованный объект типа address, поля которого будут инициализированы полями локального структурированного объекта prev. После чего локальный структурированный объект prev будет уничтожен, а объекту f2 будет присвоено значение неименованного объекта, т.е. поля объекта f2 получат те же самые значения, что и поля неименованного объекта. Таким образом будут переданы данные по значению из функции (локального параметра prev в f2).
Функция может также иметь формальные параметры в виде указателей или ссылок на структурированный объект и возвращать указатель или ссылку на структурированный объект. В общем, никаких особых отличий при использовании структурированных типов в функции от использования фундаментальных типов нет.
Над структурированными объектами по умолчанию определено всего несколько операций (&, *, sizeof(), =, операции выбора компонентов структурированного объекта (точка) и ->, операции с компонентами классов *, ->*,::). Программист может при желании расширить список операций над структурированными объектами определив их с помощью компонентных функций, но пока рассмотрим только операции определённые по умолчанию.
|
|
|
Унарная операция получения адреса структурированного объекта & возвращает адрес, начиная с которого в памяти расположены поля данных структурированного объекта. Поля в памяти размещены в той же последовательности, как и при их записи в определении структурированного объекта.
Унарная операция разыменования (доступа по адресу) * может быть применена к указателю на структурированный объект. С помощью неё можно получить доступ к объекту на который указывает указатель.
Операции выбора компонентов структурированного объекта (точка) и -> были рассмотрены выше. С помощью имени структурированного объекта или указателя на него мы можем обратиться к полю данных структурированного объекта.
Операция sizeof () может быть применена, как и в случае с фундаментальными типами данных, к имени типа или к имени объекта структурированного типа. Результатом выполнения операции является число, указывающее сколько байт в памяти занимает структурированный объект. Это число можно рассчитать самостоятельно, оно буде равно сумме количества байт отводимых под каждое поле данных + сумме количества байт отводимых под таблицу виртуальных функций (таблица существует, если в структурированном объекте определены или унаследованы виртуальные компонентные функции) + некоторое количество байт необходимое для того, чтобы выровнять общее количество байт до границы слова (т. е. сделать общее количество байт кратным 4). Например, sizeof (address) = 20 если считать, что int занимает 2 байта и sizeof (address) = 24, если sizeof (int) = 4 байта.
Операция присваивания = обычно переопределяется с помощью компонентных функций программистом, если же она программистом не переопределена, то выполняется операция присваивания реализованная в компиляторе по умолчанию, т.е. всем полям структурированного объекта, стоящего слева от знака присваивания, присваиваются значения полей данных структурированного объекта, стоящего справа от знака присваивания (см. примеры выше). В общем случае это не всегда правильно (именно поэтому обычно операцию присваивания по умолчанию переопределяют). При выполнении операции присваивания компилятор проверяет соответствие типов. В простейшем случае слева и справа от операции присваивания должны стоять структурированные объекты одного и того же типа, в противном случае компилятор выдаст сообщение об ошибке.
|
|
|
Операция (::) двойное двоеточие применяется при использовании полного имени при обращении к полю структурированного объекта.
Операция ->* используется в записи указатель_на_структурированный_объект->*указатель. Такая операция эквивалентна операции *(указатель_на_структурированный_объект->указатель), т.е. значение выражения в скобках - это указатель, к которому применяется операция (*) разыменования.
Кроме определения структурированного типа в программе может использоваться и его описание, которое в общем случае имеет вид:
Одно из ключевых слов struct, union, class имя_структурированного_типа;
C помощью описания программист сообщает компилятору, что идентификатор имя_структурированного_типа – это имя типа данных, определённого программистом где-то ниже по тексту или в другом файле программы. Иногда без описание вообще невозможно обойтись, так, в приведённом ниже примере описание помогает нам обойти безвыходную ситуацию
struct A; // Описание, сообщающее, что А – это новое имя типа данных,определённого где-то ниже по тексту.
struct B { A* pa;}; //Определение структурированного типа В
struct A { B*pb;}; //Определение структурированного типа А
Эквивалентность типов
Два структурных типа считаются различными даже тогда, когда они имеют одни и те же члены. Например, ниже определены различные типы:
struct s1 { int a; };
struct s2 { int a; };
В результате имеем:
s1 x;
s2 y =x; // ошибка: несоответствие типов
Кроме того, структурные типы отличаются от основных типов, поэтому получим:
s1 x;
int i = x; // ошибка: несоответствие типов
Есть, однако, возможность, не определяя новый тип, задать новое имя для типа. В описании, начинающемся служебным словом typedef, описывается не переменная указанного типа, а вводится новое имя для типа.
|
|
|
Приведем пример:
typedef char* Pchar;
Pchar p1, p2;
char* p3 = p1; // ошибки нет типы соответствуют
Это просто удобное средство сокращения записи.
Реализация линейного списка на языке СИ++
Линейный список – это в общем случае абстрактное понятие, под которым подразумевается наличие некоторого отличного от нуля количества объектов (узлов), связанных друг с другом таким образом, что их можно представить в виде цепи или ожерелья (звенья цепи или бусинки ожерелья – это объекты), вытянутого в одну линию.
Над линейным списком обычно определены следующие операции
- получение доступа к k-му узлу списка для проверки и/или изменения содержимого его полей;
- вставка нового узла сразу после или до k-го узла;
- удаление k-го узла;
- объединение в одном списке двух (или более) линейных списков;
- разбиение линейного списка на два (или более) списка;
- создание копии линейного списка;
- определение количества узлов в списке;
- сортировка узлов в порядке возрастания значений в определённых полях этих узлов;
- поиск узла с заданным значением в некотором поле.
В одной программе редко используются сразу все девять типов операций в общей их формулировке. Поэтому линейные списки могут иметь самые разные представления в зависимости от класса операций, которые наиболее часто должны с ними выполняться. Достаточно трудно создать единое представление линейных списков, при котором эффективно выполнялись бы все эти операции. Поэтому нужно различать разные типы линейных списков в зависимости от выполняемых с ними основных операций.
Линейные списки, в которых операции вставки, удаления и доступа к значениям чаще всего выполняются в первом или последнем узле, получили следующие специальные названия.
Стек – это линейный список, в котором все операции вставки и удаления (и, как правило, операции доступа к данным) выполняются только на одном из концов списка.
Очередь или односторонняя очередь – это линейный список, в котором все операции вставки выполняются на одном из концов списка, а все операции удаления (и, как правило, операции доступа к данным) – на другом.
|
|
|
Дек или двухсторонняя очередь - это линейный список, в котором все операции вставки и удаления (и, как правило, операции доступа к данным) выполняются на обоих концах списка.
На рис. 1 представлен один из способов организации линейного списка на языке Си++ (так называемый двухсвязный список). Каждый элемент (звено) списка содержит три поля: P-указатель на предыдущее звено в списке; O – указатель на объект, включаемый в список; N – указатель на следующее звено в списке. Указатели begin и end – это указатели на первое и последнее звено в списке.
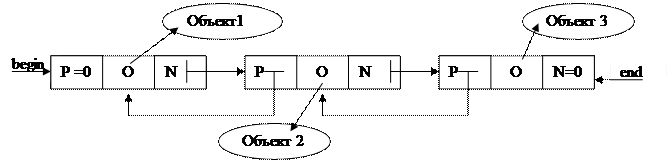
Рис. 1. Организация линейного двухсвязного списка
Из рисунка видно, что такая организация в принципе избыточна достаточно было бы односвязного списка, т.е. или поле Р, или поле N вообще можно опустить, но в этом случае возможно уменьшится скорость доступа к элементам списка. Так, если мы опускаем поле Р, то при вставке или удалении элемента из конца списка нам необходимо будет перебрать все элементы списка. Из рисунка видно, что в список в принципе могут быть включены любые объекты, т.е. указатель О может настраиваться на адреса любых объектов, которые программист хочет хранить в памяти в виде списка. Обычно предполагается, что все объекты будут одного и того же типа, но в принципе это не обязательно.
Приведём пример программы на Си++, реализующей двухсвязный список.
#include "stdafx.h"
#include<string.h>
#include<iostream.h>
В качестве объекта вставляемого в список выберем структурированный объект card, определение которого приведено ниже.
struct card { //Определение структурного типа для книги
char *author; // Ф.И.О. автора
char *title; // Заголовок книги
char *city; // Место издания
char *firm; // Издательство
int year; // Год издания
int pages; // Количество страниц
};
//Функция печати сведений о книге:
void printbook(card& car)
{ static int count = 0;
cout<<"\n"<< ++count <<". "<<car.author;
cout<<" "<<car.title<<".- "<<car.city;
cout<<": "<<car.firm<<", ";
cout<<"\n"<<car.year<<".- "<<car.pages<<" c.";
}
Звенья цепи списка удобно представить в виде структурированного объекта, который мы назовём record. Поля prior и next играют роль указателей P и N приведённых на рис. 1. Указатель obj – это поле О, т.е. указатель на объект, который предполагается хранить в звене списке.
struct record { //Структурный тип для элемента списка (1)
void* obj;
record *prior;
record *next;
};
//Исходные данные о книгах:
card books[] = { //Инициализация массива структур: (2)
{ "Kruglinski David", "Visual C++ 6.0", "М", "Мир",2000, 819},
{ "Stroustrup B","Язык Си++", "Киев","ДиаСофт",1993, 560},
{ "Turbo C++.", "Руководство программиста", "М","ИНТКВ",1991,394},
{ "Lippman S.B.","C++ для начинающих", "М","ГЕЛИОН",1993,496}
};
void main()
{ record *begin = NULL, //Указатель начала списка (3)
*last = NULL, //Указатель на очередную запись
*list; //Указатель на элементы списка
// n-количество записей в списке:
int n = sizeof(books)/sizeof(books[0]);
// Цикл обработки исходных записей о книгах:
for (int i=0;i<n; i++)
{//Создать новую запись(элемент списка): (4)
last = new(record);
card * pcd = new (card);
//Занести сведения о книге в новую запись:
pcd->author = books[i].author;
pcd->title = books[i].title;
pcd->city = books[i].city;
pcd->firm = books[i].firm;
pcd->year = books[i].year;
pcd->pages = books[i].pages;
last->obj = pcd;
//Включить запись в список(установить связи):
if (begin == NULL) //Списка ещё нет (5)
{last->prior = NULL;
begin = last;
last->next = NULL;
}
else{
//Список уже существует
list = begin;
//Цикл просмотра цикла - поиск места для
//новой записи:
while (list){ //(6)
if (strcmp(((card*)(last->obj))->author, ((card*)(list->obj))->author) < 0){ //Вставить новую запись перед list:
if (begin == list){
//Начало списка: (7)
last->prior = NULL;
begin = last;
}
else{
//Вставить между записями: (8)
list->prior->next = last;
last->prior = list->prior;
}
list->prior = last;
last->next = list;
//Выйти из цикла просмотра списка:
break;
}
if (list->next == NULL){
//Включить запись в конец цикла: (9)
last->next = NULL;
last->prior = list;
list->next = last;
//Выйти из цикла просмотра списка:
break;
}
//Перейти к следующему элементу списка:
ist = list->next;
}//Конец цикла просмотра списка (конец while)
//(Поиск места для новой записи)
} //Включение записи выполнено (конец else)
} //Конец цикла (for) обработки исходных данных
//Печать в алфавитном порядке библиографического списка:
list = begin; // (10)
cout<<"\n";
while (list)
{ printbook(*(card*)(list->obj));
delete (card*)(list->obj);
record* tmp = list;
list = list->next;
delete tmp;
}
}
В общем случае назвать эту программу программой реализации двухсвязного списка нельзя, так как очень трудно отделить реализацию самого списка от примера. Вот если бы каждое из действий над списком (вставка, удаление, доступ к элементу списка и т.д.) было реализовано в виде отдельной функции, то таким списком можно было бы пользоваться в разных программах. В принципе такая реализация списка была бы похожа на ту, что реализована в STL (стандартной библиотеки шаблонов).
Поэтому в качестве примера реализуем функцию вставки в начало списка (предполагается, что все остальные функции студенты реализуют в лабораторной работе). Для начала отметим, что фрагмент приведённого выше кода примера начиная с метки 5 и по 10 реализует вставку в начало, в конец и в середину списка элементов типа record. Поэтому внимательно проанализировав алгоритм и вычленив из него необходимые части, можно без труда реализовать функции вставки. Ниже приведёна реализация функции вставки в начало списка InsertBg и её тестирование.
#include "stdafx.h"
#include<string.h>
#include<iostream.h>
void printSpisok(double * p)
{ static int count = 0;
cout<<"\n"<< ++count <<"\t"<<*p;
}
struct record {
void* obj;
record *prior;
record *next;
static record *begin; //Статический компонент
};
//---------------------------------------------------------------------------
void InsertBg(void* lt){
if(record::begin ==NULL) {//Вставка первого элемента в список
record::begin = new (record);
record::begin->next = NULL;
record::begin->prior = NULL;
record::begin->obj = lt;
return;
}
record* tmp = new (record); //Вставка последующих элементов
record::begin->prior = tmp;
tmp->prior = NULL;
tmp->next = record::begin;
tmp->obj = lt;
record::begin = tmp;
return;
}
//-------------------------------------------------------------------
void ClearList(){
record * list = record::begin;
record* tmp = list;
while (list){
delete (double*)(list->obj);
tmp = list;
list = list->next;
delete tmp;
}
}
//------------------------------------------------------------------------------------------------
record* record::begin=NULL; //Инициализация статического компонента
//--------------------------------------------------------------------------------------------------
void main()
{
record *list;
double *pi = new (double); *pi = 3.14;
double *ex = new (double); *ex = 2.79;
double *z = new (double); *z = 1.1;
InsertBg(pi);
InsertBg(ex);
InsertBg(z);
list = record::begin;
while (list){
printSpisok((double*)list->obj);
cout<<"\t";
list = list->next;
}
ClearList();
}
В результату работы программы на экран выводятся числа 1.1, 2.79, 3.14.
В этом примере в определении структурированного типа record указатель begin определён со спецификатором static. Это делает указатель begin статическим компонентом. Главным отличием статического компонента от обычных компонентных данных заключается в том, что статический компонент в отличии от обычных компонентных данных существует в одном экземпляре для всех объектов этого типа данных, а поля обычных компонентных данных при создании нового объекта создаются вместе с ним, другими словами статическое поле одно на все объекты данного типа сколько бы их не было, а обычные компонентные данные тиражируются при создании объекта и у каждого объекта этого типа они свои. Мало того, если мы определили новый тип данных, но не создали ни одного объекта этого типа, то следовательно не существует и обычных компонентных данных, к которым мы могли бы обратиться с помощью имени объекта (ни одного объекта ещё нет). Тем не менее в этой ситуации статический компонент уже существует и к нему можно обратиться и даже инициализировать его с помощью имени типа и операции (::), например, record* record::begin=NULL; К статическому компоненту можно обратиться и обычным способом, как к обычным компонентным данным, с помощью имени объекта и операции точка (.) или указателя на объект и операции стрелочка (->).
В приведённом выше примере, мы воспользовались свойствами статических компонентов и сделали в определении типа record указатель на начало списка begin статическим компонентом. Это соответствует смыслу, которое мы вкладываем в указатель, он должен быть единственным для всех элементов типа record.
В примере также реализованы две функции работы со списком: вставка объекта в начало списка InsertBg() и очистки списка ClearList().
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 463; Нарушение авторских прав?; Мы поможем в написании вашей работы!