КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Поддержка процесса проектирования и разработки
|
|
|
|
Activity Report
Организация репозитария
Основные функции: хранение, доступ, обновление, анализ и визуализация всей информации.
Содержимое репозитария включает в себя:
1) описание объекта;
2) отношение с другими объектами;
3) контроль информации;
4) правила обработки [4].
Каждый информационный объект в репозитарии описывается перечислением его свойств: идентификаторы, имена-синонимы, тип, текстовое описание, хранилище, компоненты, область значений. Кроме этого, хранятся все перекрестные ссылки, правила формирования и редактирования объектов, а также контроля информации о времени его последнего обновления, номер версии и т.д.
На основе репозитария осуществляется интеграция CASE-средств и разделение системной информации между разработчиками.
Уровни интеграции: общий пользовательский интерфейс, передача данных между средствами, единая система для интеграции этапов разработки, передача данных между аппаратными платформами.
Репозитарий является базой для стандартизации и автоматически строит следующие основные отчеты:
1) отчеты по содержимому;
2) отчеты по перекрестным ссылкам;
3) отчеты по результатам анализа;
4) отчеты по декомпозиции объектов [4].
Пример отчета по функциональным блокам SADT-модели управления банком, автоматически создаваемого пакетом Design/IDEF, приведен ниже.
[А0] Банк
Inputs: Платежные документы
Outputs: Деньги
Controls: Законы, Время, Баланс Mechanisms: Техника, Сотрудники
Sub-Activities: [А1] Операционные залы
[А2] Управление банком,
[A3] Центральный банк
[А1] Операционные залы
Inputs: Платежные документы
Outputs: Принятые платежные документы Controls: Законы, Продолжит. раб. дня,
Остатки счетов клиентов
Mechanisms: Сотрудники, Терминал БД
[А2] Управление банком
Inputs: Принятые платежные документы Outputs: (Unlabled), Деньги, (Unlabled)
Controls: Cneц. законы,Расчет баланса,Срок обработки
Mechanisms: Управленческий персонал, Компьютеры [A3] Центральный банк
Inputs: {Unlabled}
Outputs: Деньги, (Unlabled)
Controls: Срок отправки
Mechanisms: Экспедиторы, Автомашины [4]
Важные функции управления иконтроля проекта также реализуются на основе репозитария.В частности через репозитарийможет осуществляться контроль безопасности (ограничения доступа, привилегии доступа, контроль версий, контроль изменений и др).
Для поддержки процесса проектирования и разработки используются следующие возможности CASE-пакетов: покрытия жизненного цикла, поддержка прототипирования, поддержка структурных методологий, автоматическая кодогенерация. При покрытии жизненного цикла наибольшее внимание уделяется анализу требований и проектированию спецификаций, последние являются основой всего проекта. Важную роль на ранних этапах жизненного цикла играют возможности поддержки прототипирования. Такие средства, как генераторы меню, экранов и отчетов позволяют быстро построить прототипы пользовательских интерфейсов и снабдить модели функционирования системы с позиции конечного пользователя.
Поддержка структурных методологий осуществляется за счет их автоматизации на следующих двух уровнях:
1. Подготовка документации, графическая поддержка построения структурных диаграмм, продуцирование спецификаций для детализации функциональных блоков.
2. Корректное использование шагов обработки и методов [4].
Кодогенерация осуществляется на основе репозитария и позволяет автоматически построить 80-90% объектных кодов. Автоматическая кодогенерация производится в основном с помощью целевых языков (С, ADA) либо на основе модели, полученной из проектных спецификаций.
Тема 6. КЛАССИФИКАЦИЯ CASE-СРЕДСТВ
Лекция 10. Все CASE-средства делятся на типы, категории и уровни. Классификация по типам отражает функциональную ориентацию CASE-средств в технологическом процессе.
1. АНАЛИЗ И ПРОЕКТИРОВАНИЕ. Средства данной группы используются для создания спецификаций системы и ее проектирования; они поддерживают широко известные методологии проектирования. К таким средствам относятся: CASE Аналитик (Эйтэкс), The Developer (ASYST Technologies), POSE (Computer Systems Advisers), ProKit*Workbench (McDonnell Douglas), SELECT (Select Software Tools), System Architect (Popkin Software & Systems), CASE/4/0 (microTOOL GmbH) и др. Их целью является определение системных требований и свойств, которыми система должна обладать, а также созданиепроекта системы, удовлетворяющей этим требованиям и обладающей соответствующими свойствами. На выходе продуцируются спецификации компонент системы и интерфейсов, связывающих эти компоненты, а также архитектура системы и детальная схема проекта, включающая алгоритмыопределения структур данных.
2. ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ И ФАЙЛОВ. Средства
данной группы обеспечивают логическое моделирование данных, автома-
тическое преобразование моделей данных, автоматическую генерацию схем БД и описаний форматов файлов на уровне программного кода: ERWin (Logic Works), Chen Toolkit (Chen\&Asssociates), S-Designor (SDP), Designer2000 (Oracle), Silverrun (Computer Systems Advisers).
3. ПРОГРАММИРОВАНИЕ. Средства этой группы поддержива
ют этапы программирования и тестирования, а также автоматическую
кодогенерацию из спецификаций, получая полностью документирован
ную выполняемую программу: COBOL 2/Workbench (MikroFocus),
DECASE (DEC), NETRON/CAP (Netron), APS (Sage Software). Помимо диа-
граммеров различного назначения и средств поддержки работы с репози-
тарием, в эту группу средств включены и традиционные генераторы ко-
дов, анализаторы кодов (как в статике, так и в динамике), генераторы
наборов тестов, анализаторы покрытия тестами, отладчики.
4. СОПРОВОЖДЕНИЕ И РЕИНЖИНИРИНГ. К таким средст-
вам относятся документаторы, анализаторы программ, средства реструктурирования и реинжениринга: Adpac CASE Tools (Adpac), Scan/COBOL u SuperStructure (Computer Data Systems), Inspector/Recoder (Language Technology). Их целью является корректировка, изменение, анализ, преобразование и реинжиниринг существующей системы. Средства позволяют осуществлять поддержку всей системной документации, включая коды, спецификации, наборы тестов: контролировать покрытие тестами для оценки полноты тестируемости: управлять функционированием системы и т.п. Особый интерес представляют средства обеспечения мобильности (в CASE они получили название средств миграции) и реинжиниринга. К средствам миграции относятся трансляторы, конверторы, макрогенераторы и др., позволяющие обеспечить перенос существующей системы в новое операционное или аппаратурное окружение. Средства реинжиниринга включают:
• статические анализаторы для продуцирования схем системы ПО из ее кодов;
• динамические анализаторы (обычно компиляторы и интерпретаторы
с встроенными отладочными возможностями);
• документаторы, позволяющие автоматически получать обновленную
документацию при изменении кода;
• редакторы кодов, автоматически изменяющие при редактировании и
все предшествующие коду структуры (например, спецификации);
• средства доступа к спецификациям, их модификации и генерации нового (модифицированного) кода;
• средства реверсного инжиниринга, транслирующие коды в специфи-
кации [4].
5. ОКРУЖЕНИЕ. Средства поддержки платформ для интеграции,
создания и придания товарного вида CASE-средствам: Multi/Cam (AGS
Management Systems), Design/OA (Meta Software).
6. УПРАВЛЕНИЕ ПРОЕКТОМ. Средства, поддерживающие планирование, контроль, руководство, взаимодействие, т.е. функции, необходимые в процессе разработки и сопровождения проектов: Project Workbench (Applied Business Technology).
Классификация по категориям определяет уровень интегрированности по выполняемым функциям и включает вспомогательные программы (tools), пакеты разработчика (toolkit) и инструментальные средства (workbench). Категория tools обозначает вспомогательный пакет, решающий небольшую автономную задачу, принадлежащую проблеме более широкого масштаба. Категория toolkit представляет совокупность интегрированных программных средств, обеспечивающих помощь для одного из классов программных задач; использует репозитарий для всей технической и управляющей информации о проекте, концентрируясь при этом на поддержке, как правило, одной фазы или одного этапа разработки ПО. Категория workbench представляет собой интеграцию программных средств, которые поддерживают системный анализ, проектирование и разработку ПО; используют репозитарий, содержащий всю техническую и управляющую информацию о проекте; обеспечивают автоматическую передачу системной информации между разработчиками и этапами разработки; организуют поддержку практически полного ЖЦ (от анализа требований и проектирования ПО до получения документированной выполняемой программы). Workbench, по сравнению с toolkit, обладает более высокой степенью интеграции выполняемых функций, большей самостоятельностью и автономностью использования, а также наличием тесной связи с системными и техническими средствами аппаратно-вычислителыюй среды, на которой workbench функционирует. По существу, workbench может рассматриваться как автоматизированная рабочая станция, используемая как инструментарий для автоматизации всех или отдельных совокупностей работ по созданию ПО [4].
Классификация по уровням связана с областью действия CASE в пределах жизненного цикла ПО. Данная классификация не имеет четких границ.
Верхние (Upper) CASE часто называют средствами компьютерного планирования. Они призваны повышать эффективность деятельности руководителей фирмы и проекта путем сокращения затрат на определение политики фирмы и на создание общего плана проекта. Этот план включает цели и стратегии их достижения, основные действия в свете целей и задач фирмы, установление стандартов на различные виды взаимосвязей и т.д. Использование верхних CASE позволяет построить модель предметной области, отражающую всю существующую специфику.
Средние (Middle) CASE считаются средствами поддержки этапов анализа требований и проектирования спецификаций и структуры ПО. Их использование существенно сокращает цикл разработки проекта; при этом важную роль играет возможность накопления и хранения знаний, обычно имеющихся только в голове разработчика-аналитика, что позволит использовать накопленные решения при создании других проектов. Основная выгода использования среднего CASE состоит в значительном облегчении проектирования систем, проектирование превращается в итеративный процесс, включающий следующие действия:
• пользователь обсуждает с аналитиком требования к проектируемой
системе;
• аналитик документирует эти требования, используя диаграммы и словари входных данных;
• пользователь проверяет эти диаграммы и словари, при необходимости
модифицируя их;
• аналитик отвечает на эти модификации, изменяя соответствующие
спецификации [4].
Кроме того, средние CASE обеспечивают возможности быстрого документирования требований и быстрого прототипирования.
Нижние (Lower) CASE являются средствами разработки ПО (при этом может использоваться до 30% спецификаций, созданных средствами среднего CASЕ). Они содержат системные словари и графические средства, исключающие необходимость разработки физических спецификаций. Имеются системные спецификации, которые непосредственно переводятся в программные коды разрабатываемой системы (при этом автоматически генерируется до 80-90% кодов). На эти средства возложены также функции тестирования, управления конфигурацией, формирования документации [4]. Главными преимуществами нижних CASE являются: значительное уменьшение времени на разработку, облегчение модификаций, поддержка возможностей прототипирования (совместно со средними CASE).
Тема 7. ОСНОВЫ ПРОЕКТИРОВАНИЯ ИНФОРМАЦИОННЫХ СИСТЕМ (ИС)
Лекция 11. Основы методологии и технологии
Основу проекта любой ИС составляют методологии, технологии и инструментальные средства проектирования (CASE-средства). Методология реализуется через конкретные технологии и поддерживающие их стандарты, методики и инструментальные средства, которые обеспечивают выполнение процессов ЖЦ.
Технология проектирования - совокупность трех составляющих:
· пошаговая процедура - последовательность технологических операций проектирования;
· критерии и правила, используемые для оценки результатов выполнения технологических операций;
· нотации (графических и текстовых средств), используемые для описания проектируемой системы.
Технологические инструкции, составляющие основное содержание технологии, состоят из описания последовательности технологических операций, условий, в зависимости от которых выполняется та или иная операция, и описаний самих операций.
Технология проектирования, разработки и сопровождения ИС должна:
· поддерживать ЖЦ ПО;
· обеспечивать достижение целей разработки ИС с требуемым качеством и в установленное время;
· давать возможность выполнения крупных проектов в виде подсистем, т.е. разбивать проект на составные части, разрабатываемые группами исполнителей с последующей интеграцией составных частей. Опыт разработки крупных ИС показывает, что для повышения эффективности работ необходимо разбить проект на отдельные слабо связанные по данным и функциям подсистемы. Реализация подсистем должна выполняться отдельными группами специалистов. При этом необходимо обеспечить координацию ведения общего проекта и исключить дублирование результатов работ каждой проектной группы, которое может возникнуть в силу наличия общих данных и функций;
· обеспечить возможность ведения работ по проектированию отдельных подсистем несколькими специалистами. Это обусловлено принципами управляемости коллектива и повышения производительности за счет минимизации числа внешних связей;
· обеспечивать минимальное время получения работоспособной ИС. Речь идет о сроках реализации отдельных подсистем. Реализация ИС в целом в короткие сроки может потребовать привлечения большого числа разработчиков, при этом эффект может оказаться ниже, чем при реализации в более короткие сроки отдельных подсистем меньшим числом разработчиков. Практика показывает, что даже при наличии полностью завершенного проекта внедрение идет последовательно по отдельным подсистемам;
· предусматривать возможность управления конфигурацией проекта, ведения версий проекта и его составляющих, возможность автоматического выпуска проектной документации и синхронизацию ее версий с версиями проекта;
· обеспечивать независимость выполняемых проектных решений от средств реализации ИС (систем управления базами данных (СУБД), операционных систем, языков и систем программирования);
· быть поддержана комплексом согласованных CASE-средств, обеспечивающих автоматизацию процессов, выполняемых на всех стадиях ЖЦ.
Применение любой технологии проектирования, разработки и сопровождения ИС невозможно без выработки ряда стандартов, которые должны соблюдаться всеми участниками проекта. К таким стандартам относятся:
· стандарт проектирования;
· стандарт оформления проектной документации;
· стандарт пользовательского интерфейса [1,2].
Стандарт проектирования должен устанавливать:
· набор необходимых моделей (диаграмм) на каждой стадии проектирования и степень их детализации;
· правила фиксации проектных решений на диаграммах, в том числе: правила именования объектов, набор атрибутов для всех объектов и правила их заполнения на каждой стадии, правила оформления диаграмм и т. д.;
· требования к конфигурации рабочих мест разработчиков, включая настройки операционной системы, настройки CASE-средств, общие настройки проекта и т. д.;
· механизм обеспечения совместной работы над проектом, в том числе: правила интеграции подсистем проекта, правила поддержания проекта в одинаковом для всех разработчиков состоянии (регламент обмена проектной информацией, механизм фиксации общих объектов и т.д.), правила проверки проектных решений на непротиворечивость и т. д. [1].
Стандарт оформления проектной документации должен устанавливать:
· комплектность, состав и структуру документации на каждой стадии проектирования;
· требования к ее оформлению (включая требования к содержанию разделов, подразделов, пунктов, таблиц и т.д.),
· правила подготовки, рассмотрения, согласования и утверждения документации с указанием предельных сроков для каждой стадии;
· требования к настройке издательской системы, используемой в качестве встроенного средства подготовки документации;
· требования к настройке CASE-средств для обеспечения подготовки документации в соответствии с установленными требованиями.
Стандарт интерфейса пользователя должен устанавливать:
· правила оформления экранов (шрифты и цветовая палитра), состав и расположение окон и элементов управления;
· правила использования клавиатуры и мыши;
· правила оформления текстов помощи;
· перечень стандартных сообщений;
· правила обработки реакции пользователя [1,2,3].
RAD-методология разработки приложений
Одним из подходов к разработке ПО является получившая в последнее время широкое распространение методология быстрой разработки приложений RAD (Rapid Application Development). Под этим термином обычно понимается процесс разработки ПО, содержащий 3 компонента:
· небольшую команду программистов (от 2 до 10 человек);
· короткий, но тщательно проработанный производственный график (от 2 до 6 мес.);
· повторяющийся цикл, при котором разработчики запрашивают и реализуют в продукте требования, полученные через взаимодействие с заказчиком в процессе разработки [1].
Команда разработчиков должна представлять из себя группу профессионалов, имеющих опыт в проведении анализа, проектирования, генерации кода и тестирования ПО с использованием CASE-средств. Члены коллектива должны также уметь трансформировать в рабочие прототипы предложения конечных пользователей.
Жизненный цикл ПО по методологии RAD состоит из фаз:
· анализа и планирования требований;
· проектирования;
· построения;
· внедрения.
На фазе анализа и планирования требований пользователи системы определяют функции, которые она должна выполнять, выделяют наиболее приоритетные из них, требующие проработки в первую очередь, описывают информационные потребности. Определение требований выполняется в основном силами пользователей под руководством специалистов. Ограничивается масштаб проекта, определяются временные рамки для каждой из последующих фаз. Кроме того, определяется сама возможность реализации данного проекта в установленных рамках финансирования, на данных аппаратных средствах и т.п. Результатом данной фазы должны быть список и приоритетность функций будущей ИС, предварительные функциональные и информационные модели ИС.
На фазе проектирования часть пользователей принимает участие в техническом проектировании системы. CASE-средства используются для быстрого получения работающих прототипов приложений. Пользователи, непосредственно взаимодействуя с ними, уточняют и дополняют требования к системе, которые не были выявлены на предыдущей фазе. Более подробно рассматриваются процессы системы. Анализируется и корректируется функциональная модель. Каждый процесс рассматривается детально. Определяются требования разграничения доступа к данным. На этой же фазе происходит определение набора необходимой документации.
После детального определения состава процессов оценивается количество функциональных элементов разрабатываемой системы и принимается решение о разделении ИС на подсистемы, для реализации различными командами разработчиков за приемлемое для RAD-проектов время. С использованием CASE-средств проект распределяется между различными командами (делится функциональная модель). Результатом данной фазы должны быть:
· общая информационная модель системы;
· функциональные модели системы в целом и подсистем, реализуемых отдельными командами разработчиков;
· точно определенные с помощью CASE-средства интерфейсы между автономно разрабатываемыми подсистемами;
· построенные прототипы экранов, отчетов, диалогов [1].
Все модели и прототипы должны быть получены с применением тех CASE-средств, которые будут использоваться в дальнейшем при построении системы. Данное требование вызвано тем, что в традиционном подходе при передаче информации о проекте с этапа на этап может произойти неконтролируемое искажение данных.
В отличие от традиционного подхода, при котором использовались специфические средства прототипирования, не предназначенные для построения реальных приложений, а прототипы выбрасывались после того, как выполняли задачу устранения неясностей в проекте, в подходе RAD каждый прототип развивается в часть будущей системы. Таким образом, на следующую фазу передается более полная и полезная информация.
На фазе построения выполняется непосредственно сама быстрая разработка приложения. На данной фазе производят итеративное построение реальной системы на основе полученных в предыдущей фазе моделей, а также требований нефункционального характера. Программный код частично формируется при помощи автоматических генераторов, получающих информацию непосредственно из репозитария CASE-средств. Конечные пользователи на этой фазе оценивают получаемые результаты и вносят коррективы, если в процессе разработки система перестает удовлетворять определенным ранее требованиям. Тестирование системы осуществляется непосредственно в процессе разработки.
После окончания работ каждой отдельной команды разработчиков производится постепенная интеграция данной части системы с остальными, формируется полный программный код, выполняется тестирование совместной работы данной части приложения с остальными, а затем тестирование системы в целом. Завершается физическое проектирование системы:
· определяется необходимость распределения данных;
· производится анализ использования данных;
· производится физическое проектирование базы данных;
· определяются требования к аппаратным ресурсам;
· определяются способы увеличения производительности;
· завершается разработка документации проекта [1,14].
Результатом фазы является готовая система, удовлетворяющая всем согласованным требованиям.
На фазе внедрения производится обучение пользователей, организационные изменения и параллельно с внедрением новой системы осуществляется работа с существующей системой (до полного внедрения новой). Так как фаза построения достаточно непродолжительна, планирование и подготовка к внедрению должны начинаться заранее, как правило, на этапе проектирования системы. Приведенная схема разработки ИС не является абсолютной. Возможны различные варианты, зависящие, например, от начальных условий, в которых ведется разработка: разрабатывается совершенно новая система; уже было проведено обследование предприятия и существует модель его деятельности; на предприятии уже существует некоторая ИС, которая может быть использована в качестве начального прототипа или должна быть интегрирована с разрабатываемой.
Следует, однако, отметить, что методология RAD, как и любая другая, не может претендовать на универсальность, она хороша в первую очередь для относительно небольших проектов, разрабатываемых для конкретного заказчика.
Методология RAD неприменима для построения сложных расчетных программ, требующих написания большого объема уникального кода. Не подходят для разработки по методологии RAD приложения реального времени.
Оценка размера приложений проводится на основе так называемых функциональных элементов (экраны, сообщения, отчеты, файлы и т.п.) Подобная метрика не зависит от языка программирования, на котором ведется разработка. Размер приложения, которое может быть выполнено по методологии RAD, для хорошо отлаженной среды разработки ИС с максимальным повторным использованием программных компонентов, определяется при помощи табл. 2.
Таблица 2 [1]
| <1000 функциональных элементов | один человек |
| 1000-4000 функциональных элементов | одна команда разработчиков |
| >4000 функциональных элементов | 4000 функциональных элементов на одну команду разработчиков |
В качестве итога перечислим основные принципы методологии RAD:
· разработка приложений итерациями;
· необязательность полного завершения работ на каждом из этапов жизненного цикла;
· обязательное вовлечение пользователей в процесс разработки ИС;
· необходимое применение CASE-средств, обеспечивающих целостность проекта;
· применение средств управления конфигурацией, облегчающих внесение изменений в проект и сопровождение готовой системы;
· необходимое использование генераторов кода;
· использование прототипирования, позволяющее полнее выяснить и удовлетворить потребности конечного пользователя;
· тестирование и развитие проекта, осуществляемые одновременно с разработкой;
· ведение разработки немногочисленной хорошо управляемой командой профессионалов;
· грамотное руководство разработкой системы, четкое планирование и контроль выполнения работ [1].
Тема 8. СТРУКТУРНЫЙ ПОДХОД ПРОЕКТИРОВАНИЯ ИНФОРМАЦИОННЫХ СИСТЕМ (ИС)
Лекция 12. Основные принципы структурного подхода
При разработке с помощью структурного подхода ИС разбивается на автоматизируемые функции, т.е. на функциональные подсистемы, которые в свою очередь делятся на подфункции, подразделяемые на задачи и так далее. Процесс разбиения продолжается вплоть до конкретных процедур. При этом автоматизируемая система сохраняет целостное представление, в котором все составляющие компоненты взаимоувязаны. При разработке системы "снизу-вверх" от отдельных задач ко всей системе целостность теряется, возникают проблемы при информационной стыковке отдельных компонентов.
Распространенные методологии структурного подхода базируются на ряде общих принципов. В качестве двух базовых принципов используются:
· принцип "разделяй и властвуй" - принцип решения сложных проблем путем их разбиения на множество меньших независимых задач, легких для понимания и решения;
· принцип иерархического упорядочивания - принцип организации составных частей проблемы в иерархические древовидные структуры с добавлением новых деталей на каждом уровне.
Остальные принципы не являются второстепенными, поскольку игнорирование любого из них может привести к провалу всего проекта. Основными из этих принципов являются следующие:
· принцип абстрагирования - заключается в выделении существенных аспектов системы и отвлечении от несущественных;
· принцип формализации - заключается в необходимости строгого методического подхода к решению проблемы;
· принцип непротиворечивости - заключается в обоснованности и согласованности элементов;
· принцип структурирования данных - заключается в том, что данные должны быть структурированы и иерархически организованы [1,4,6,14].
В структурном анализе используются в основном две группы средств, иллюстрирующих функции, выполняемые системой, и отношения между данными. Каждой группе средств соответствуют определенные виды диаграмм, наиболее распространенными среди которых являются следующие:
· SADT (Structured Analysis and Design Technique) - модели и соответствующие функциональные диаграммы;
· DFD (Data Flow Diagrams) - диаграммы потоков данных;
· ERD (Entity-Relationship Diagrams) - диаграммы "сущность-связь".
На стадии проектирования ИС модели расширяются, уточняются и дополняются диаграммами, отражающими структуру программного обеспечения: архитектуру ПО, структурные схемы программ и диаграммы экранных форм [1,4,14].
Перечисленные модели в совокупности дают полное описание ИС независимо от того, является ли она существующей или вновь разрабатываемой. Состав диаграмм в каждом конкретном случае зависит от необходимой полноты описания системы.
Методология SADT
Методология SADT разработана Дугласом Россом. На ее основе разработана, в частности, известная методология IDEF0 (Icam DEFinition), которая является основной частью программы ICAM (Интеграция компьютерных и промышленных технологий), проводимой по инициативе ВВС США.
Методология SADT представляет собой совокупность методов, правил и процедур, предназначенных для построения функциональной модели объекта какой-либо предметной области. Функциональная модель SADT отображает функциональную структуру объекта, т.е. производимые им действия и связи между этими действиями. Основные элементы этой методологии основываются на следующих концепциях:
· графическое представление блочного моделирования. Графика блоков и дуг SADT-диаграммы отображает функцию в виде блока, а интерфейсы входа/выхода представляются дугами, соответственно входящими в блок и выходящими из него. Взаимодействие блоков друг с другом описывается посредством интерфейсных дуг, выражающих "ограничения", которые в свою очередь определяют, когда и каким образом функции выполняются и управляются;
· строгость и точность. Выполнение правил SADT требует достаточной строгости и точности, не накладывая в то же время чрезмерных ограничений на действия аналитика. Правила SADT включают: ограничение количества блоков на каждом уровне декомпозиции (правило 3-6 блоков); связность диаграмм (номера блоков); уникальность меток и наименований (отсутствие повторяющихся имен); синтаксические правила для графики (блоков и дуг); разделение входов и управлений (правило определения роли данных); отделение организации от функции, т.е. исключение влияния организационной структуры на функциональную модель [1].
Методология SADT может использоваться для моделирования широкого круга систем и определения требований и функций, а затем для разработки системы, которая удовлетворяет этим требованиям и реализует эти функции. Для уже существующих систем SADT может быть использована для анализа функций, выполняемых системой, а также для указания механизмов, посредством которых они осуществляются.
Иерархия диаграмм
Создание SADT-модели начинается с представления всей системы в виде простейшей (обобщенной) компоненты - одного блока и дуг, изображающих интерфейсы с функциями вне системы. Поскольку единственный блок представляет всю систему как единое целое, имя, указанное в блоке, является общим. Это верно и для интерфейсных дуг - они также представляют полный набор внешних интерфейсов системы в целом.
Затем блок, который представляет систему в качестве единого модуля, детализируется на другой диаграмме с помощью нескольких блоков, соединенных интерфейсными дугами. Эти блоки представляют основные подфункции исходной функции. Данная декомпозиция выявляет полный набор подфункций, каждая из которых представлена как блок, границы которого определены интерфейсными дугами. Каждая из этих подфункций может быть декомпозирована подобным образом для более детального представления.
Любая подфункция может содержать только те элементы, которые входят в исходную функцию. Кроме того, модель не может опустить какие-либо элементы, т.е., как уже отмечалось, родительский блок и его интерфейсы обеспечивают контекст. К нему нельзя ничего добавить, и из него не может быть ничего удалено.
Модель SADT - серия диаграмм с сопроводительной документацией, разбивающих сложный объект на составные части, которые представлены в виде блоков. Детали каждого из основных блоков показаны в виде блоков на других диаграммах. Каждая детальная диаграмма является декомпозицией блока из более общей диаграммы. На каждом шаге декомпозиции более общая диаграмма называется родительской для более детальной диаграммы [1].
Дуги, входящие в блок и выходящие из него на диаграмме верхнего уровня, являются теми же самыми, что и дуги, входящие в диаграмму нижнего уровня и выходящие из нее, потому что блок и диаграмма представляют одну и ту же часть системы (рис.16).
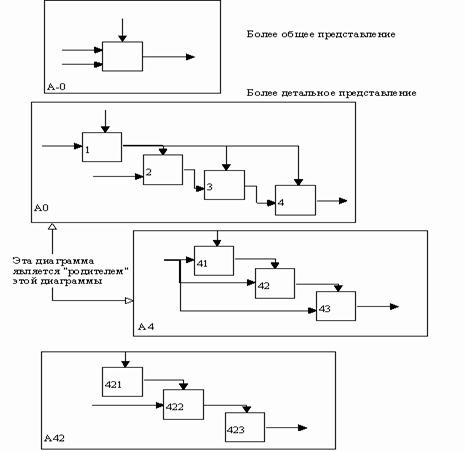 |
Рис. 16. Декомпозиция диаграмм [1]
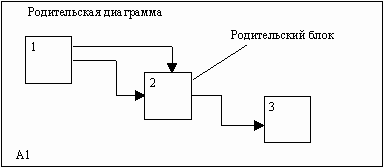
На рис. 17 представлены различные варианты выполнения функций соединения дуг с блоками.
Некоторые дуги присоединены к блокам диаграммы обоими концами, у других же один конец остается неприсоединенным. Неприсоединенные дуги соответствуют входам, управлениям и выходам родительского блока. Источник или получатель этих пограничных дуг может быть обнаружен только на родительской диаграмме.
Неприсоединенные концы должны соответствовать дугам на исходной диаграмме. Все граничные дуги должны продолжаться на родительской диаграмме, чтобы она была полной и непротиворечивой.
На SADT-диаграммах не указаны явно ни последовательность, ни время.
Обратные связи, итерации, продолжающиеся процессы и перекрывающиеся (по времени) функции могут быть изображены с помощью дуг.
 |
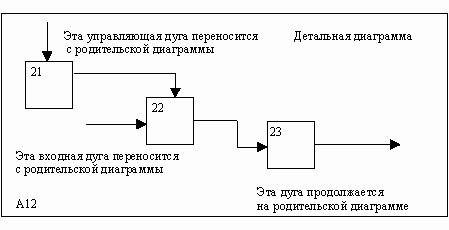 |
Рис. 17. Варианты выполнения функций соединения дуг с блоками [1]
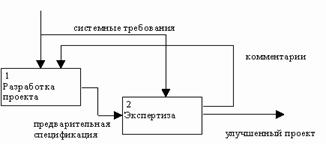 |
Связи могут выступать в виде комментариев, замечаний, исправлений и т.д. (рис. 18).
Рис. 18. Пример обратной связи [1]
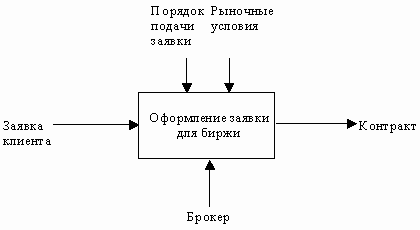 |
Как было отмечено, механизмы (дуги с нижней стороны) показывают средства, с помощью которых осуществляется выполнение функций. Механизм может быть человеком, компьютером или любым другим устройством, которое помогает выполнять данную функцию (рис. 19).
Рис. 19. Пример механизма [1]
Каждый блок на диаграмме имеет свой номер. Блок любой диаграммы может быть далее описан диаграммой нижнего уровня, которая, в свою очередь, может быть далее детализирована с помощью необходимого числа диаграмм. Таким образом, формируется иерархия диаграмм (рис. 20).
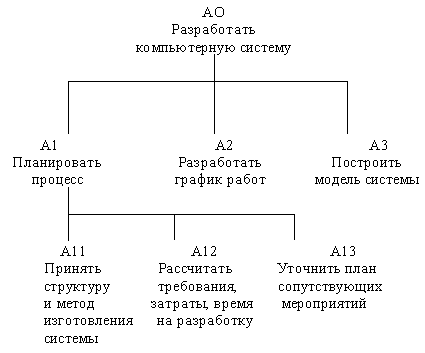
Рис. 20. Иерархия диаграмм [1]
Для того, чтобы указать положение любой диаграммы или блока в иерархии, используются номера диаграмм. Например, А21 является диаграммой, которая детализирует блок 1 на диаграмме А2. Аналогично, А2 детализирует блок 2 на диаграмме А0, которая является самой верхней диаграммой модели. На рис. 20 показано типичное дерево диаграмм.
Типы связей между функциями
Одним из важных моментов при проектировании ИС с помощью методологии SADT является точная согласованность типов связей между функциями. Различают, по крайней мере, семь типов связывания (табл. 3).
Таблица 3 [1]
| Тип связи | Относительная значимость |
| Случайная | |
| Логическая | |
| Временная | |
| Процедурная | |
| Коммуникационная | |
| Последовательная | |
| Функциональная |
Ниже каждый тип связи кратко определен и проиллюстрирован с помощью типичного примера из SADT.
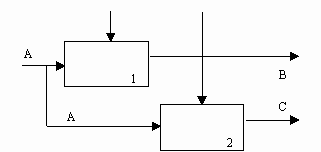
(0) Тип случайной связности: наименее желательный.
Случайная связность возникает, когда конкретная связь между функциями мала или полностью отсутствует. Это относится к ситуации, когда имена данных на SADT-дугах в одной диаграмме имеют малую связь друг с другом. Крайний вариант этого случая показан на рис. 21.
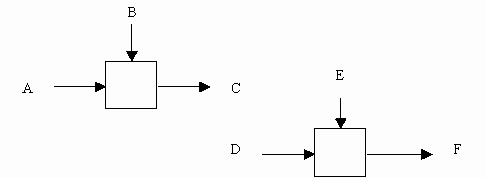 |
Рис. 21. Случайная связность [1]
(1) Тип логической связности. Логическое связывание происходит тогда, когда данные и функции собираются вместе вследствие того, что они попадают в общий класс или набор элементов, но необходимых функциональных отношений между ними не обнаруживается.
(2) Тип временной связности. Связанные по времени элементы возникают вследствие того, что они представляют функции, связанные во времени, когда данные используются одновременно или функции включаются параллельно, а не последовательно.
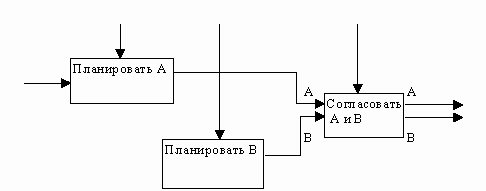
(3) Тип процедурной связности. Процедурно-связанные элементы появляются сгруппированными вместе вследствие того, что они выполняются в течение одной и той же части цикла или процесса. Пример процедурно-связанной диаграммы приведен на рис. 22.
Рис. 22. Процедурная связность [1]
(4) Тип коммуникационной связности. Диаграммы демонстрируют коммуникационные связи, когда блоки группируются вследствие того, что они используют одни и те же входные данные и/или производят одни и те же выходные данные (рис. 23).
(5) Тип последовательной связности. На диаграммах, имеющих последовательные связи, выход одной функции служит входными данными для следующей функции. Связь между элементами на диаграмме является более тесной, чем на рассмотренных выше уровнях связок, поскольку моделируются причинно-следственные зависимости (рис. 24).
 |
(6) Тип функциональной связности. Диаграмма отражает полную функциональную связность, при наличии полной зависимости одной функции от другой. Диаграмма, которая является чисто функциональной, не содержит чужеродных элементов, относящихся к последовательному или более слабому типу связности. Одним из способов определения функционально-связанных диаграмм является рассмотрение двух блоков, связанных через управляющие дуги, как показано на рис. 25.
Рис. 23. Коммуникационная связность [1]
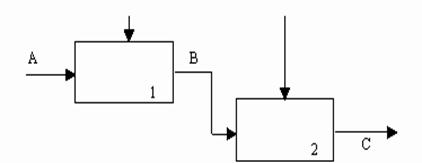 |
Рис. 24. Последовательная связность [1]
В математических терминах необходимое условие для простейшего типа функциональной связности, показанной на рисунке 25, имеет следующий вид:
C = g(B) = g(f(A)).
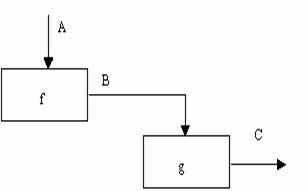 |
Ниже в табл. 4 представлены все типы связей, рассмотренные выше. Важно отметить, что уровни 4-6 устанавливают типы связностей, которые разработчики считают важнейшими для получения диаграмм хорошего качества.
Рис. 25. Функциональная связность [1]
Таблица 4 [1]
| Значи- мость | Тип связности | Для функций | Для данных |
| Случайная | Случайная | Случайная | |
| Логическая | Функции одного и того же множества или типа (например, "редактировать все входы") | Данные одного и того же множества или типа | |
| Временная | Функции одного и того же периода времени (например, "операции инициализации") | Данные, используемые в каком-либо временном интервале | |
| Процедурная | Функции, работающие в одной и той же фазе или итерации (например, "первый проход компилятора") | Данные, используемые во время одной и той же фазы или итерации | |
| Коммуникацион. | Функции, использующие одни и те же данные | Данные, на которые воздействует одна и та же деятельность | |
| Последовательн. | Функции, выполняющие последовательные преобразования одних и тех же данных | Данные, преобразуемые последовательными функциями | |
| Функциональная | Функции, объединяемые для выполнения одной функции | Данные, связанные с одной функцией |
Лекция 13. Построение модели анализируемой ИС
Модель системы определяется как иерархия диаграмм потоков данных (ДПД или DFD), описывающих асинхронный процесс преобразования информации от ее ввода в систему до выдачи пользователю. Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы ИС с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается, создавая многоуровневую иерархию диаграмм, до тех пор, пока процессы станут элементарными и детализировать их далее невозможно.
Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те в свою очередь преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям - потребителям информации. Таким образом, основными компонентами диаграмм потоков данных являются:
· внешние сущности;
· системы/подсистемы;
· процессы;
· накопители данных;
· потоки данных [1,14].
Внешние сущности
Внешняя сущность - материальный предмет или физическое лицо, представляющее собой источник или приемник информации (заказчики, персонал, поставщики, клиенты, склад). Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что она находится за пределами границ анализируемой ИС. В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой ИС, если это необходимо, или, наоборот, часть процессов ИС может быть вынесена за пределы диаграммы и представлена как внешняя сущность.
Внешняя сущность обозначается квадратом (рис. 26), расположенным как бы "над" диаграммой и бросающим на нее тень, для того, чтобы можно было выделить этот символ среди других обозначений:
 |
Рис. 26. Внешняя сущность [1]
Системы и подсистемы
При построении модели сложной ИС она может быть представлена в самом общем виде на так называемой контекстной диаграмме в виде одной системы, как единого целого, либо может быть декомпозирована на ряд подсистем.
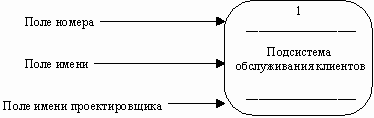 |
Подсистема (или система) на контекстной диаграмме изображается следующим образом (рис. 27).
Рис. 27. Подсистема [1]
Номер подсистемы необходим для ее идентификации. В поле имени вводится наименование подсистемы в виде предложения с подлежащим и соответствующими определениями и дополнениями.
Процессы
Процесс - преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Физически процесс может быть реализован различными способами: это может быть подразделение организации (отдел), выполняющее обработку входных документов и выпуск отчетов, программа, аппаратно реализованное логическое устройство и т.д.
Процесс на диаграмме потоков данных изображается, как показано на рис. 28.
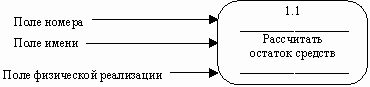
Рис. 28. Процесс [1]
Номер процесса необходим для его идентификации. В поле имени вводится наименование процесса в виде предложения с активным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже, например:
· "Ввести сведения о клиентах";
· "Выдать информацию о текущих расходах";
· "Проверить кредитоспособность клиента".
Использование таких глаголов, как "обработать", "модернизировать" или "отредактировать" означает, как правило, недостаточно глубокое понимание данного процесса и требует дальнейшего анализа [1,14].
Информация в поле физической реализации показывает, какое подразделение организации, программа или аппаратное устройство выполняет данный процесс.
Накопители данных
Накопитель данных - абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми.
 |
Накопитель данных может быть реализован физически в виде ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т.д. Накопитель данных на диаграмме потоков данных изображается, как показано на рис. 29.
Рис. 29. Накопитель данных [1]
Накопитель данных идентифицируется буквой "D" и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика.
Накопитель данных в общем случае является прообразом будущей базы данных и увязывается с информационной моделью.
Потоки данных
Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой по кабелю между двумя устройствами, пересылаемыми по почте письмами, магнитными лентами или дискетами, переносимыми с одного компьютера на другой и т.д.
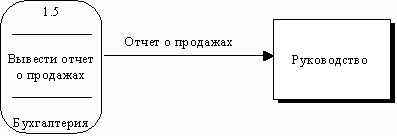 |
Поток данных на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока (рис. 30). Каждый поток данных имеет имя, отражающее его содержание.
Рис. 30. Поток данных [1]
Лекция 14. Иерархия диаграмм потоков данных
Построение контекстных диаграмм - первый шаг при построении иерархии ДПД. Обычно при проектировании относительно простых ИС строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится так называемый главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы.
Если сложная система описана единственной контекстной диаграммой, то она будет содержать слишком большое количество источников и приемников информации, которые трудно расположить на листе бумаги нормального формата, и кроме того, единственный главный процесс не раскрывает структуры распределенной системы. Признаками сложности могут быть:
· наличие большого количества внешних сущностей (десять и более);
· распределенная природа системы;
· многофункциональность системы с уже сложившейся или выявленной группировкой функций в отдельные подсистемы [1,6,14].
Для сложных ИС строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит не единственный главный процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем.
Иерархия контекстных диаграмм определяет взаимодействие основных функциональных подсистем проектируемой ИС как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует ИС.
Разработка контекстных диаграмм решает проблему строгого определения функциональной структуры ИС на самой ранней стадии ее проектирования, что особенно важно для сложных многофункциональных систем, в разработке которых участвуют разные организации и коллективы разработчиков.
После построения контекстных диаграмм полученную модель следует проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами).
Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи ДПД. Каждый процесс на ДПД, в свою очередь, может быть детализирован при помощи ДПД или миниспецификации. При детализации должны выполняться следующие правила:
· правило балансировки - означает, что при детализации подсистемы или процесса детализирующая диаграмма в качестве внешних источников/приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеет информационную связь детализируемая подсистема или процесс на родительской диаграмме;
· правило нумерации - означает, что при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т.д.
Миниспецификация (описание логики процесса) - формулирует его основные функции таким образом, чтобы в дальнейшем специалист, выполняющий реализацию проекта, смог выполнить их или разработать соответствующую программу.
Миниспецификация является конечной вершиной иерархии ДПД. Решение о завершении детализации процесса и использовании миниспецификации принимается аналитиком исходя из следующих критериев:
· наличия у процесса относительно небольшого количества входных и выходных потоков данных (2-3 потока);
· возможности описания преобразования данных процессом в виде последовательного алгоритма;
· выполнения процессом единственной логической функции преобразования входной информации в выходную;
· возможности описания логики процесса при помощи миниспецификации небольшого объема (не более 20-30 строк) [1,6].
При построении иерархии ДПД к детализации процессов переходят только после определения содержания всех потоков и накопителей данных, которое описывается при помощи структур данных. Структуры данных конструируются из элементов данных и могут содержать альтернативы, условные вхождения и итерации. Условное вхождение означает, что данный компонент может отсутствовать в структуре. Альтернатива означает, что в структуру может входить один из перечисленных элементов. Итерация означает вхождение любого числа элементов в указанном диапазоне. Для каждого элемента данных может указываться его тип (непрерывные или дискретные данные). Для непрерывных данных может указываться единица измерения, диапазон значений, точность представления и форма физического кодирования. Для дискретных данных может указываться таблица допустимых значений.
После построения законченной модели системы ее необходимо верифицировать (проверить на полноту и согласованность). В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные недетализированные объекты следует детализировать, вернувшись на предыдущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны.
Case-метод Баркера моделирования данных
Цель моделирования данных - обеспечение разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных.
Наиболее распространенным средством моделирования данных являются диаграммы "сущность-связь" (ERD). С их помощью определяются важные для предметной области объекты (сущности), их свойства (атрибуты) и отношения друг с другом (связи). ERD непосредственно используются для проектирования реляционных баз данных.
Нотация ERD была впервые введена П. Ченом (Chen) и получила дальнейшее развитие в работах Баркера. Метод Баркера изложим на примере моделирования деятельности компании по торговле недвижимостью.
Главный менеджер: одна из основных обязанностей - содержание недвижимого имущества. Он должен знать, сколько заплачено за объект и каковы накладные расходы. Обладая этой информацией, он может установить нижнюю цену, за которую мог бы продать данный экземпляр. Кроме того, он несет ответственность за продавцов и ему нужно знать, кто что продает и сколько объектов продал каждый из них.
Продавец: ему нужно знать, какую цену запрашивать и какова нижняя цена, за которую можно совершить сделку. Кроме того, ему нужна основная информация об имеющихся строениях: год постройки, тип строения, общая площадь и т.п.
Администратор: его задача сводится к составлению контрактов, для чего нужна информация о покупателе, объекте и продавце, поскольку именно контракты приносят продавцам вознаграждения за продажи.
Первый шаг моделирования - извлечение информации и выделение сущностей.
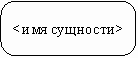 |
Сущность (Entity) - реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению (рис. 31).
Рис. 31. Графическое изображение сущности [1]
Каждая сущность обладает уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Каждая сущность должна обладать некоторыми свойствами:
· каждая сущность должна иметь уникальное имя, и к одному и тому же имени должна всегда применяться одна и та же интерпретация. Одна и та же интерпретация не может применяться к различным именам, если только они не являются псевдонимами;
· сущность обладает одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь;
· сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности;
· каждая сущность может обладать любым количеством связей с другими сущностями модели.
Обращаясь к приведенным выше выдержкам, видно, что сущности, которые могут быть идентифицированы с главным менеджером - это объекты и продавцы. Продавцу важны объекты и связанные с их продажей данные. Для администратора важны покупатели, объекты, продавцы и контракты. Исходя из этого, выделяются 4 сущности (объект, продавец, покупатель, контракт), которые изображаются на диаграмме следующим образом (рис. 32).
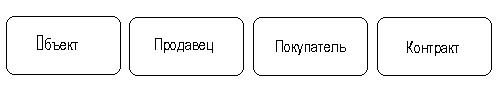
Рис. 32. Изображение сущностей
Следующим шагом моделирования является идентификация связей.
Связь (Relationship) - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - это ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности-родителя.
Связи может даваться имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка.
Например, связь продавца с контрактом может быть выражена следующим образом:
· продавец может получить вознаграждение за 1 или более контрактов;
· контракт должен быть инициирован ровно одним продавцом.
Степень связи и обязательность графически изображаются следующим образом (рис. 33).
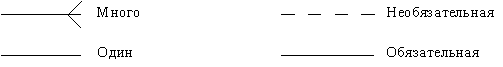 |
Рис. 33. Степень связи [1]
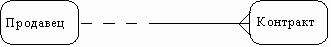 |
Таким образом, 2 предложения, описывающие связь продавца с контрактом, графически будут выражены следующим образом (рис. 34).
Рис. 34. Пример графического отображения связи [1]
Описав также связи остальных сущностей, получим следующую схему (рис. 35).
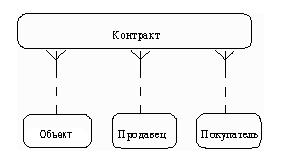
Рис. 35. Пример отображения связей в схеме
Последним шагом моделирования является идентификация атрибутов. Атрибут - любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик или свойств, ассоциированных с множеством реальных или абстрактных объектов. Экземпляр атрибута - это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута.
Атрибут может быть либо обязательным, либо необязательным (рис. 36). Обязательность означает, что атрибут не может принимать неопределенных значений (null, values). Атрибут может быть либо описательным, либо входить в состав уникального идентификатора.
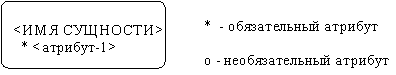 |
Уникальный идентификатор - это атрибут или совокупность атрибутов и/или связей, предназначенная для уникальной идентификации каждого экземпляра данного типа сущности. В случае полной идентификации каждый экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в его идентификации участвуют также атрибуты другой сущности-родителя (рис. 37).
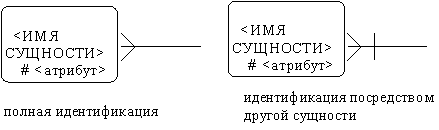 |
Рис. 36. Виды атрибутов [1]
Рис. 37. Разновидности идентификации [1]
Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком "#".
Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности - это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные - как альтернативные ключи.
С учетом имеющейся информации дополним построенную ранее диаграмму (рис. 38). Помимо перечисленных основных конструкций модель данных может содержать ряд дополнительных.
Подтипы и супертипы: одна сущность является обобщающим понятием для группы подобных сущностей (рис. 39).
Взаимно исключающие связи: каждый экземпляр сущности участвует только в одной связи из группы взаимно исключающих связей (рис. 40).
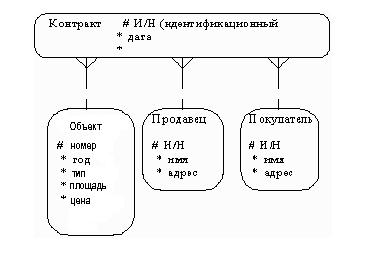
Рис. 38. Дополненная диаграмма
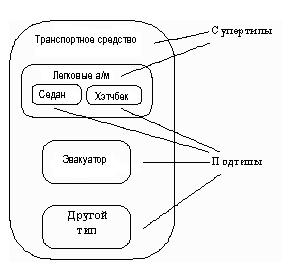
Рис. 39. Подтипы и супертипы
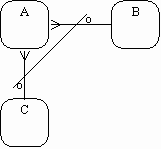 |
Рис. 40. Взаимно исключающие связи [1]
Рекурсивная связь: сущность может быть связана сама с собой (рис. 41).
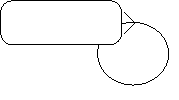 |
Неперемещаемые (non-transferrable) связи: экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рис. 42).
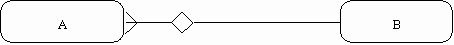
Рис. 41. Рекурсивная связь [1]
Рис. 42. Неперемещаемая связь [1]
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 896; Нарушение авторских прав?; Мы поможем в написании вашей работы!