КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Описательная модель предметной области
|
|
|
|
Процесс проектирования БД является весьма сложным. По сути, он заключается в определении перечня данных, хранимых на физических носителях (магнитных дисках и т.п.), которые достаточно полно отражают информационные потребности потенциальных пользователей в конкретной ПрОбл. Проектирование БД начинается с анализа предметной области и возможных запросов пользователей. В результате этого анализа определяется перечень данных и связей между ними, которые адекватно — с точки зрения будущих потребителей — отражают ПрОбл. Завершается проектирование БД определением форм и способов хранения необходимых данных на физическом уровне.
Весь процесс проектирования БД можно разбить на ряд взаимосвязанных этапов, каждый из которых обладает своими особенностями и методами проведения. На рис. 3 представлены типовые этапы.
На этапе инфологического (информационно-логического) проектирования осуществляется построение семантической модели, описывающей сведения из предметной области, которые могут заинтересовать пользователей БД. Семантическая модель (semantic model) — представление совокупности понятий о ПрОбл в виде графа, в вершинах которого расположены понятия, в терминальных вершинах — элементарные понятия, а дуги представляют отношения между понятиями.
Сначала из объективной реальности выделяется ПрОбл, т.е. очерчиваются ее границы. Логический анализ выделенной ПрОбл и потенциальных запросов пользователей завершается построением инфологической модели ПрОбл — перечня сведений об объектах ПрОбл, которые необходимо хранить в БД и связях между ними.
Анализ информационных потребностей потенциальных пользователей имеет два аспекта: 1) определение собственно сведений об объектах ПрОбл; 2) анализ возможных запросов к БД и требований по оперативности их выполнения.
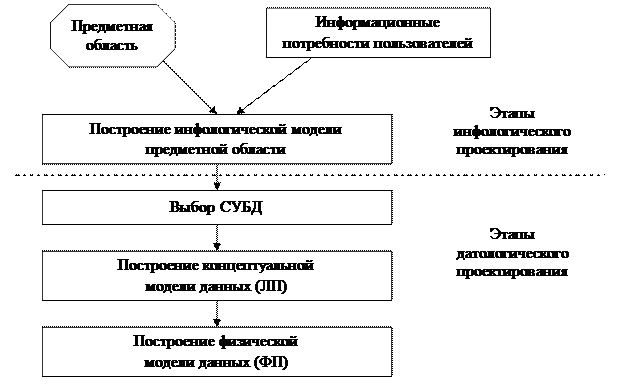
Рис. 3.Этапы проектирования БД.
Анализ возможных запросов к БД позволяет уточнить связи между сведениями, которые необходимо хранить. Пусть, например, в БД по учебному процессу института хранятся сведения об учебных группах, читаемых курсах и кафедрах, а также связи "учебные группы—читаемые курсы" и "читаемые курсы—кафедры". Тогда запрос о том, проводит ли некоторая кафедра занятия в конкретной учебной группе может быть выполнен только путем перебора всех читаемых в данной группе курсов.
Хранение большого числа связей усложняет БД и приводит к увеличению потребной памяти ЭВМ, но часто существенно ускоряет поиск нужной информации. Поэтому разработчику БД (АБД) приходится принимать компромиссное решение, причем процесс определения перечня хранимых связей, как правило, имеет итерационный характер.
Датологическое проектирование подразделяется на логическое (построение концептуальной модели данных) и физическое (построение физической модели) проектирование.
Главной задачей логического проектирования (ЛП) БД является представление выделенных на предыдущем этапе сведений в виде данных в форматах, поддерживаемых выбранной СУБД.
Задача физического проектирования (ФП) — выбор способа хранения данных на физических носителях и методов доступа к ним с использованием возможностей, предоставляемых СУБД.
Инфологическая модель "сущность—связь" (entity relationship model; ER-model) П. Чена (Р. Chen) представляет собой описательную (неформальную) модель ПрОбл, семантически определяющую в ней сущности и связи.
Относительная простота и наглядность описания ПрОбл позволяет использовать ее в процессе диалога с потенциальными пользователями с самого начала инфологического проектирования. Построение инфологической модели П. Чена, как и любой другой модели, является творческим процессом, по этому единой методики ее создания нет. Однако при любом подходе к построению модели используют три основных конструктивных элемента:
§ сущность;
§ атрибут;
§ связь.
Сущность — это собирательное понятие некоторого повторяющегося объекта, процесса или явления окружающего мира, о котором необходимо хранить информацию в системе. Сущность может определять как материальные (например, "студент", "грузовой автомобиль" и т.п.), так и нематериальные объекты (например, "экзамен", "проверка" и т.п.). Главной особенностью сущности является то, что вокруг нее сосредоточен сбор информации в конкретной ПрОбл. Тип сущности определяет набор однородных объектов, а экземпляр сущности — конкретный объект в наборе. Каждая сущность в модели Чена именуется. Для идентификации конкретного экземпляра сущности и его описания используется один или несколько атрибутов.
Атрибут — это поименованная характеристика сущности, которая принимает значения из некоторого множества значений. Например, у сущности "студент" могут быть атрибуты "фамилия", "имя", "отчество", "дата рождения", "средний балл за время обучения" и т.п.
Связи в инфологической модели выступают в качестве средства, с помощью которого представляются отношения между сущностями, имеющими место в ПрОбл. При анализе связей между сущностями могут встречаться бинарные (между двумя сущностями) и, в общем случае, n -арные (между п сущностями) связи. Например, сущности "отец", "мать" и "ребенок" могут находиться в триарном отношении "семья" ("является членом семьи").
Связи должны быть поименованы; между двумя типами сущностей могут существовать несколько связей.
Наиболее распространены бинарные связи. Любую n -арную связь можно представить в виде нескольких бинарных.
Различают четыре типа связей:
§ связь один к одному (1:1);
§ связь один ко многим (1:М);
§ связь многие к одному (М:1);
§ связь многие ко многим (M:N).
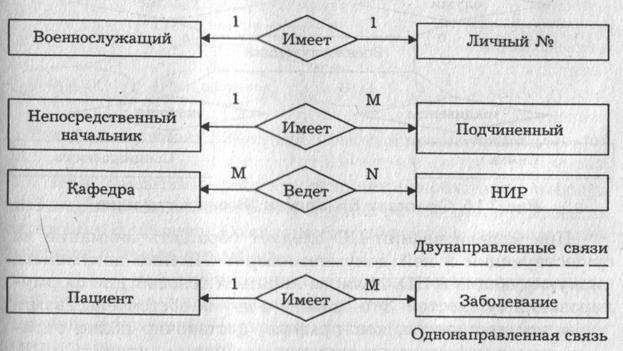
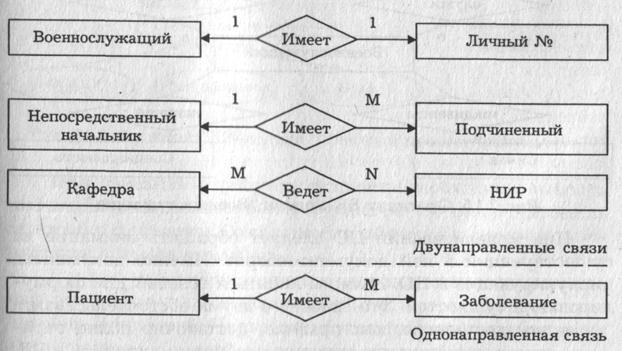
Связь один к одному определяет такой тип связи между типами сущностей А и В, при которой каждому экземпляру сущности А соответствует один и только один экземпляр сущности В, и наоборот. Таким образом, имея некоторый экземпляр сущности А, можно однозначно идентифицировать соответствующий ему экземпляр сущности В, а по экземпляру сущности В — экземпляр сущности А. Например, связь типа 1:1 ("имеет") может быть определена между сущностями "автомобиль" и "двигатель", так как на конкретном автомобиле может быть установлен только один двигатель, и этот двигатель, естественно, нельзя установить сразу на несколько автомобилей.
Связь один ко многим определяет такой тип связи между типами сущностей А и В, для которой одному экземпляру сущности А может соответствовать 0, 1 или несколько экземпляров сущности В, но каждому экземпляру сущности В соответствует один экземпляр сущности А. При этом однозначно идентифицировать можно только экземпляр сущности А по экземпляру сущности В. Примером связи типа 1:М является связь "учится" между сущностями "учебная группа" и "студент". Для такой связи, зная конкретного студента, можно однозначно идентифицировать учебную группу, в которой он учится, или, зная учебную группу, можно определить всех обучающихся в ней студентов.
Связь многие к одному по сути эквивалентна связи один ко многим. Различие заключается лишь в том, с точки зрения какой сущности (А или В) данная связь рассматривается.
Связь многие ко многим определяет такой тип связи между типами сущностей А и В, при котором каждому экземпляру сущности А может соответствовать 0, 1 или несколько экземпляров сущности В, и наоборот. При такой связи, зная экземпляр одной сущности, можно указать все экземпляры другой сущности, относящиеся к исходному, т.е. идентификация сущностей не уникальна в обоих направлениях. В качестве примера такой связи можно рассмотреть связь "изучает" между сущностями "учебная дисциплина" и "учебная группа".
Реально все связи являются двунаправленными, т.е., зная экземпляр одной из сущностей, можно идентифицировать (однозначно или многозначно) экземпляр (экземпляры) другой сущности. В некоторых случаях целесообразно рассматривать лишь однонаправленные связи между сущностями в целях экономии ресурсов ЭВМ. Возможность введения таких связей полностью определяется информационными потребностями пользователей. Различают простую и многозначную однонаправленные связи, которые являются аналогами связей типа 1:1 и 1:М с учетом направления идентификации. Так, для простой однонаправленной связи "староста" ("является старостой") между сущностями "учебная группа" и "студент" можно, зная учебную группу, однозначно определить ее старосту, но, зная конкретного студента, нельзя сказать, является ли он старостой учебной группы. Примером многозначной однонаправленной связи служит связь между сущностями "пациент" и "болезнь", для которой можно для каждого пациента указать его болезни, но нельзя выявить всех обладателей конкретного заболевания.
Графически типы сущностей, атрибуты и связи принято изображать прямоугольниками, овалами и ромбами соответственно. На рис. 4 представлены примеры связей различных типов; на рис. 5 и 6 – фрагменты инфологических моделей "военнослужащий" (без указания атрибутов) и "учебный процесс факультета".
Несмотря на то, что построение инфологической модели есть процесс творческий, можно указать два основополагающих правила, которыми следует пользоваться всем проектировщикам БД:
§ при построении модели должны использоваться только три типа конструктивных элементов: сущность, атрибут, связь;
§ каждый компонент информации должен моделироваться только одним из приведенных выше конструктивных элементов для исключения избыточности и противоречивости описания.
Моделирование ПрОбл начинают с выбора сущностей, необходимых для ее описания. Каждая сущность должна соответствовать некоторому объекту (или группе объектов) ПрОбл, о котором в системе будет накапливаться информация. Существует проблема выбора конструктивного элемента для моделирования той или иной "порции" информации, что существенно затрудняет процесс построения модели.
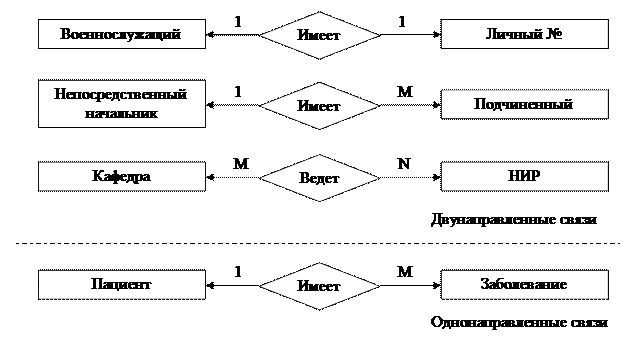
Рис. 4. Примеры связей между сущностями.
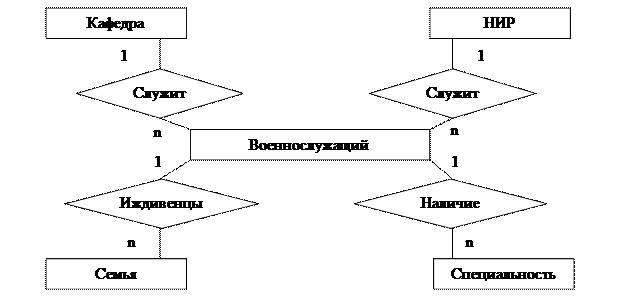
Рис. 5.Фрагмент ER-модели "Военнослужащий".
Так, информация о том, что некоторый студент входит в состав учебной группы (УГ) можно в модели представить:
§ как связь "входит в состав" для сущностей "студент" и "УГ";
§ как атрибут "имеет в составе "студента" сущности "УГ";
§ как сущность "состав УГ".
В этих случаях приходится рассматривать несколько вариантов и с учетом информационных потребностей пользователей разбивать ПрОбл на такие фрагменты, которые с их точки зрения представляют самостоятельный интерес.
|
|
Рис. 6. Фрагмент ER-модели "Учебный процесс факультета".
При описании атрибутов сущности необходимо выбрать ряд атрибутов, позволяющих однозначно идентифицировать экземпляр сущности. Совокупность идентифицирующих атрибутов называют ключом.
Помимо идентифицирующих используются и описательные атрибуты, предназначенные для более полного определения сущностей. Число атрибутов (их тип) определяется единственным образом — на основе анализа возможных запросов пользователей. Существует ряд рекомендаций по "работе с атрибутами", например, по исключению повторяющихся групп атрибутов (см. рис. 7).
При определении связей между сущностями следует избегать связей типа M:N, так как они приводят к существенным затратам ресурсов ЭВМ. Устранение таких связей предусматривает введение других (дополнительных) элементов — сущностей и связей. На рис. 8 приведен пример исключения связи многие ко многим.
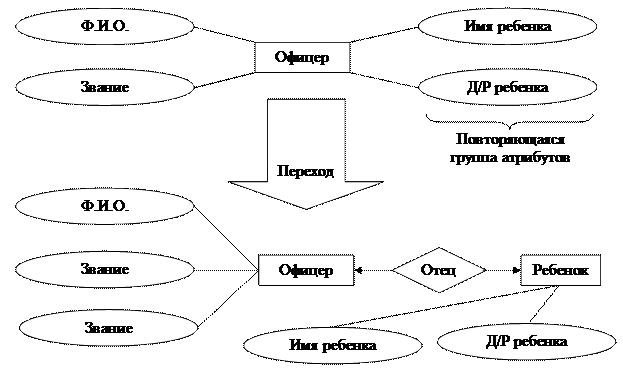
Рис.7. Пример исключения повторяющейся группы атрибутов.
Приведем типовую последовательность работ (действий) по построению инфологической модели:
§ выделение в ПрОбл сущностей;
§ введение множества атрибутов для каждой сущности и выделение из них ключевых;
§ исключение множества повторяющихся атрибутов (при необходимости);
§ формирование связей между сущностями;
§ исключение связей типа M:N (при необходимости);
§ преобразование связей в однонаправленные (по возможности).
Помимо модели Чена существуют и другие инфологические модели. Все они представляют собой описательные (неформальные) модели, использующие различные конструктивные элементы и соглашения по их использованию для представления в БД информации о ПрОбл. Иными словами, первый этап построения БД всегда связан с моделированием предметной области.
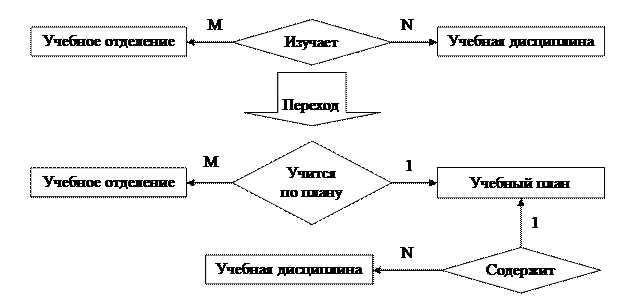
Рис. 8. Пример исключения связи типа M:N.
|
|
|
|
Дата добавления: 2014-01-13; Просмотров: 536; Нарушение авторских прав?; Мы поможем в написании вашей работы!