КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция 1. Базы данных – теоретический обзор
|
|
|
|
1.1 Иерархические, сетевые и реляционные модели данных.
Базы данных (БД) – это данные, организованные в виде набора записей определенной структуры и хранящиеся в файлах, где, помимо самих данных, содержится описание их структуры. Система управления базами данных (СУБД) – это система, обеспечивающая ввод данных в БД, их хранение и восстановление в случае сбоев, манипулирование данными, поиск и вывод данных по запросу пользователя.
По моделям представления данных базы данных делят на:
- иерархические
- сетевые
- реляционные
- объектно-реляционные
Иерархические базы данных – это самая первая модель представления данных, в которой все записи базы данных представлены в виде дерева, с отношениями предок-потомок (рис. 1.1). Физически данные отношения реализуются в виде указателей на предков и потомков, содержащихся в самой записи. Такая модель представления данных связана с тем, что на ранних этапах базы данных часто использовались для планирования производственного процесса: каждое выпускаемое изделие состоит из узлов, каждый узел из деталей и т.п. Для того, чтобы знать сколько деталей каждого вида надо заказать, строилось дерево (рис. 1.1). Поскольку список составных частей изделия представлял из себя дерево, то для его хранения в базе данных наилучшим образом подходила иерархическая модель организации данных.
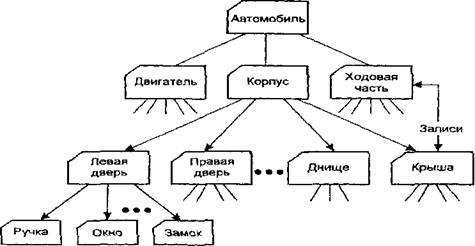
Рис. 1.1 Иерархическая база данных
Однако иерархическая модель не является оптимальной. Допустим, что один и тот же тип болтов используется в автомобиле 300 раз в различных узлах. При использовании иерархической модели, данный тип болтов будет фигурировать в базе данных не 1 раз, а 300 раз (в каждом узле – отдельно). Налицо дублирование.
Сетевая база данных - это база данных, в которой одна запись может участвовать в нескольких отношениях предок-потомок (рис. 1.2). Т.е. фактически, база данных представляет собой не дерево, а граф.
| Множество |
| Записи 1_>Л №112961 |
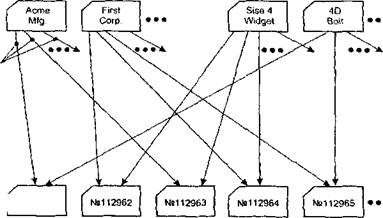 Заказы
Заказы
Рис. 1.2. Сетевая база данных.
Физически данная модель также реализуется за счет хранящихся внутри самой записи указателей на другие записи, только, в отличие от иерархической модели, число этих указателей может быть произвольным.
И иерархическая и сетевая модель достаточно просты, однако они имеют общий недостаток: для того, чтобы получить ответ даже на простой вопрос, программист был должен написать программу, которая просматривала базу данных, двигаясь по указателям от одной записи к другой. Написание программы занимало некоторое время, и часто к тому моменту, когда такая программа была написана, необходимость в получении данных уже отпадала. Поэтому в середине 80-х годов 20 века произошел практически повсеместный переход к реляционным базам данных.
В реляционной базе данных вся информация представляется в виде таблиц и любые операции над данными — это операции над таблицами. Таблицы состоят из строк и столбцов. Строки — это записи, а столбцы представляют структуру записи (каждый столбец имеет определенный тип данных и длину данных). Строки в таблице не упорядочены — не существует первой или десятой строки. Однако поскольку на строки надо как-то ссылаться, то вводится понятие "первичный ключ". Первичный ключ — это столбец, значения которого во всех строках разные. Используя первичный ключ можно однозначно сослаться на какую-либо строку таблицы. Первичный ключ может состоять и из нескольких столбцов (составной первичный ключ). Некоторые СУБД требуют в явном виде указать первичный ключ таблицы, а некоторые позволяют пользователю не задавать для таблицы первичный ключ — в таком случае СУБД сама добавляет в таблицу столбец — первичный ключ, не отображаемый на экране (так, например, в СУБД Oracle у любой таблицы существует псевдо-столбец ROWID, формируемый Oracle, который содержит уникальный адрес каждой строки). Отношения предок-потомок в реляционных БД реализуются при помощи внешних ключей. Внешний ключ — это столбец таблицы, значения которого совпадают со значениями первичного ключа некоторой другой таблицы. Так, например, на рис. 1.3 столбец "Ответственный" таблицы "Мероприятия" является внешним ключом для таблицы "Сотрудники" (первичный ключ — столбец "Фамилия").
Таблица "Сотрудники"__
Таблица "Мероприятия"

Рис. 1.3. Отношения предок-потомок в реляционных базах данных.
Важным моментом является также использование значения NULL в таблицах реляционной базы данных. NULL — это отсутствующее значение, отсутствие информации по данной позиции. Не допускается использовать 0 или "пробел" вместо NULL: понятно, что "нулевой" объем продаж — это не тоже самое, что "неизвестный" объем продаж. По этой же причине ни одно значение NULL не равно другому значению NULL. В реляционной базе данных, при запросах, группировке, сравнениях и т.д., значения NULL обрабатываются особым образом.
Объектно-реляционные базы данных появились в последнее время у значительного числа производителей СУБД (Oracle, Informix, PostgreSQL) и сочетают в себе реляционную модель данных с концепциями объектно-ориентированного программирования. Это такая методология реализации, при которой программа организуется, как совокупность сотрудничающих объектов, каждый из которых является экземпляром какого-либо класса, классы образуют иерархию наследования. При этом классы обычно статичны, а объекты очень динамичны. Объектно-ориентированный язык программирования характеризуется тремя основными свойствами (полиморфизм, инкапсуляция, наследование):
1. Инкапсуляция. Комбинирование записей с процедурами и функциями, манипулирующими полями этих записей, формирует новый тип данных - объект. Рассмотрим понятие инкапсуляция в 2-х аспектах:а) в языках ООП - возможность сокрытия некоторых аспектов представления класса; при этом доступ к объектам осуществляется только посредством экспортируемых операций;
- Наследование интерфейса. Объект-потомок наследует у родителя его интерфейс, возможно, пополняя его новыми методами. Однако потомок не использует никакой функциональности предка и вынужден самостоятельно реализовывать все методы. Такое наследование допускает возможность автоматического преобразования типа от потомка к предку и создание иерархии типов. Наличие подобной иерархии позволяет уменьшить количество интерфейсов в системе и упростить ее структуру.
- Наследование функциональности. Потомок наследует не только интерфейс, но и код методов. Такое наследование имеет принципиальное значение для повторного использования кода.
- Наследование состояния. Для того чтобы использовать функциональность методов предка для потомка, необходимо, чтобы структура данных потомка содержала все поля данных предка. Наследование функциональности обычно требует использования наследования состояния, поэтому эти два типа наследования можно объединить в один - наследование реализации. Такой механизм наследования используется для объектов в большинстве современных языков программирования, в том числе, в C++ и Java. Однако в распределенных системах наследование почти никогда не применяется.
Объектно-ориентированное программирование порой требует от вас оставить в стороне характерные представления о программировании, которые долгие годы рассматривались, как стандартные. Однако после того, как это сделано, объектно-ориентированное программирование становится простым, наглядным и превосходным средством разрешения многих проблем, которые доставляют неприятности традиционному программному обеспечению
|
|
|
|
Дата добавления: 2014-01-13; Просмотров: 569; Нарушение авторских прав?; Мы поможем в написании вашей работы!