КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Условия отбора 2 страница
|
|
|
|
Модуль синтаксического разбора запросов отвечает за компиляцию поступающих от клиентов через интерфейсные процессы запросов во внутренний код, который будет исполняться сервером. При ошибках компиляции соответствующие сообщения передаются клиенту. Наиболее современные СУБД позволяют сохранять откомпилированный код запросов некоторое время. Это позволяет избежать стадии компиляции при повторном обращении клиента к запросу.
Модуль планирования выполнения запросов составляет наиболее оптимальный по скорости выполнения план запроса. Для этого анализируются условия выборок и соединений, устанавливается порядок их выполнения. План выполнения запроса включается в его откомпилированный код.
Модуль выполнения транзакций реализует оптимизированный код запроса, обновляет индексы, выполняет в случае необходимости триггеры и хранимые процедуры. Как правило, несколько запросов могут исполняться параллельно, при этом обеспечивается необходимый уровень их изоляции. Также ведется журнал транзакций, обеспечивается их завершение и корректный откат.
Модуль управления памятью отвечает за считывание данных с диска в оперативную память, синхронизацию обновлений с данными на диске и др. Он может использовать файловые функции операционной системы, но часто СУБД имеет свои собственные низкоуровневые средства доступа к дискам.
10..2. Системы совместного использования файлов
Технология «файл-сервер» предполагает, чтофайлы базы данных располагаются на удаленном сервере файлов. В соответствии с пользовательскими запросами файлы базы данных в полном объеме передаются на рабочие станции, где производится их обработка. Особенностью обработки является совмещение процедур представления данных (ввод и отображение данных) и выполнения прикладных программ пользователя. Протокол обмена при этом представляет собой набор низкоуровневых вызовов операций файловой системы.
Технология «файл-сервер» реализуется, как правило, с помощью персональной СУБД.
Принципиальная схема обработки данных в системе «файл-сервер» отображена на рис. 10.1.
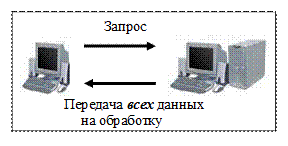
Рис. 10.1. Технология «файл-сервер»
К недостаткам такой схемы обработки относятся: высокий сетевой трафик (по сети передаются целые файлы базы данных), низкий уровень безопасности доступа к данным, отсутствие унифицированного доступа к ресурсам, а также снижение производительности при большой интенсивности доступа к одним и тем же данным. Повышение производительности достигается, например, для реляционных систем, совместным использованием только таблиц базы данных. Остальные объекты базы данных хранятся и обрабатываются на рабочих станциях.
10.3. Клиент-серверные системы
Основной принцип технологии "клиент-сервер" заключается в разделении функций приложения между следующими его компонентами:
– компонент представления данных обеспечивает ввод и отображение данных (взаимодействие с пользователем);
– прикладной компонент выполняет прикладные функции, характерные для данной предметной области;
– компонент управления ресурсом осуществляет функции управления ресурсами, такими как, файловая система, база данных и др.
Связь между компонентами осуществляется по определенным правилам, которые называют "протокол взаимодействия".
В технологии «клиент-сервер»ядро СУБД функционирует на сервере, который обеспечивает выполнение основного объема обработки данных. В соответствии с запросом на получение данных, посылаемым клиентом на сервер, осуществляется поиск и извлечение необходимых данных в базе данных. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Принципиальная схема обработки данных в архитектуре изображена на рис.10.2.
В системе «клиент-сервер» прикладная программа или конечный пользователь взаимодействуют с клиентской частью системы. Доступ к базе данных от прикладной программы или
пользователя производится путем обращения к клиентской
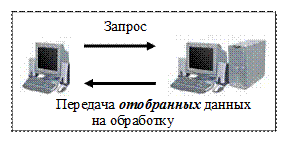
Рис. 10.2. Технология «клиент-сервер»
части системы, программное обеспечение которой не имеет непосредственного доступа к базам данных. В качестве основного интерфейса между клиентской и серверной частями выступает язык структурированных запросов SQL.
Развитием технологии «клиент-сервер» является концепция активного сервера, который использует механизм хранимых процедур. При активном сервере часть прикладного компонента переносится на сервер (модель распределенного приложения). Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, что и SQL-сервер. Преимуществами такой технологии являются возможность централизованного администрирования прикладных функций и значительное снижение сетевого трафика, так как передаются не SQL-запросы, а вызовы хранимых процедур. Недостаток - ограниченность средств разработки хранимых процедур по сравнению с языками общего назначения (C и Pascal).
При смешанном типе технологии «клиент-сервер» простейшие прикладные функции выполняются хранимыми процедурами на сервере, а более сложные реализуются на клиенте непосредственно в прикладной программе.
10.4. Системы обработки распределенных баз данных
Существуют два подхода к организации обработки распределенных данных.
Технология распределенной базы данных. Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (РаСУБД). Примером распределенной базы данных является база в автоматизированной банковской системе, содержащая сведения о состоянии депозитных счетов физических лиц в масштабах города. Результаты финансовых операций видны одновременно во всех отделениях банка.
С точки зрения пользователей распределенная база выглядит так, как будто все данные хранятся в одном месте. Такая технология предъявляет жесткие требования к производительности и надежности каналов связи.
Технология тиражирования. Как синоним понятию "тиражирование" используется термин "репликация". Тиражирование представляет собой технологию поддержки копий всей базы данных или ее фрагментов в нескольких узлах сети.
Другими словами, в каждом узле сети дублируются данные всех компьютеров сети.
По сети передаются только операции изменения данных, а не сами данные. Данные располагаются в месте обработки, а передача изменений может происходить не одновременно для разных узлов сети. Положительные стороны тиражирования – это снижение требований к пропускной способности каналов связи и повышение надежности системы, благодаря тому, что при выходе из строя линии связи какого-либо компьютера, пользователи других узлов могут продолжать работу. Основным недостатком является возможность конфликтов между копиями одной и той же записи, так как технология допускает неодинаковое состояние базы данных для различных пользователей в один и тот же момент времени.
Рассмотрим основные принципы обработки данных в распределенных системах.
Независимость от оборудования. В качестве узла распределенной системы могут выступать компьютеры любых моделей и производителей – от мэйнфреймов до персональных компьютеров и ноутбуков.
Локальная автономия означает, что управление каждым узлом распределенной системы выполняется локально и независимо от других узлов системы.
Независимая фрагментация – это возможность распределенного размещения данных, логически представляющих собой единое целое. При горизонтальной фрагментации строки одной таблицы хранятся на различных узлах. Вертикальная фрагментация разрешает распределение столбцов логической таблицы по нескольким узлам.
Независимое тиражирование заключается в переносе изменений объектов исходной базы данных в базы, расположенные на других узлах распределенной системы, внутрисистемными средствами.
Прозрачность сети – в распределенной системе возможны любые сетевые протоколы.
В экономике и социальной сферах распространение получили многопользовательские распределенные OLTP-системы (On-Line Transaction Processing – оперативная обработка транзакций). Основной функцией OLTP-систем является выполнение большого количества коротких транзакций.
К особенностям транзакций в OLTP-приложениях относятся:
– несложность транзакций – это могут быть простые операции, например, заказ билетов в кассах авиакомпании, снятие денежных средств с одного счета и зачисление этих средств на другой;
– массовость транзакций;
– одновременное выполнение большого числа транзакций, если к системе подключены несколько тысяч работающих в режиме on-line пользователей;
– быстрый откат всей транзакции при возникновении ошибки и возврат системы к состоянию, которое было до начала транзакции.
Практически все запросы к базе данных в OLTP-приложениях состоят из команд вставки, обновления, удаления. Запросы на выборку в основном предназначены для предоставления пользователям возможности выбора из различных справочников. Важными характеристиками таких систем являются скорость и надежность выполнения коротких операций обновления данных.
10.5. Технологии обработки хранилищ данных
Перспективным направлением развития многопользовательских распределенных систем является создание систем на основе хранилищ данных.
Хранилище данных – это предметно-ориентированный, интегрированный, неизменяемый и поддерживающий хронологию набор данных. В определении понятия «хранилище данных» отражены его характерные черты.
Ориентация на предметную область. Хранилище разрабатывается с учетом специфики предметной области, а не приложений, оперирующих данными. Структура хранилища отражает представления пользователей об информации, с которой им приходится работать.
Интегрированность. Данные в хранилище загружаются из приложений, созданных разными разработчиками, и объединяются путем приведения их к единому синтаксическому и семантическому виду.
Неизменяемость данных. Д анные после загрузки в хранилища остаются неизменными. Внесение каких-либо изменений, кроме добавления записей, не предполагается.
Поддержка хронологии. Для выполнения большинства запросов необходим анализ тенденций развития явлений или характера изменения значений переменных во времени.
Хранилища данных могут быть разбиты на два типа: корпоративные хранилища данных (enterprise data warehouses) и киоски данных (data marts).
Корпоративные хранилища данных содержат информацию всей корпорации, собранную из множества оперативных источников для консолидированной обработки.
Киоски данных содержат подмножества корпоративных
данных и строятся для отделов или подразделений внутри организации. Киоск данных может получать данные из корпоративного хранилища (зависимый киоск) или данные могут поступать непосредственно из оперативных источников (независимый киоск).
Системы, основанные на концепции хранилищ данных, принято называть OLAP-системами (OnLine Analysis Proccessing – системы оперативной аналитической обработки).
OLAP-системы, как правило, строятся на основе архитектуры клиент-сервер. Хранилище данных размещается на специальном сервере (сервере хранилища данных). Для его реализации используются мощные многопроцессорные вычислительные системы. В качестве СУБД применяется одна из СУБД, поддерживающих параллельную обработку запросов: DB/2, Oracle, Informix и др. Киоски данных реализуются с использованием серверов многомерных БД: Essbase, Oracle Express, Gentium и др.
Данные должны поступать в хранилище в нужном формате и с требуемой регулярностью. Как правило, составляется расписание пополнения хранилища, в соответствии с которым специальные программы организуют передачу данных в хранилище и их первичную обработку. Передача данных может также осуществляться при возникновении заранее определенных внешних событий.
Процесс загрузки данных включает процедуры:
– приведение данных к единому формату (унификация типов данных и их представления, исключение управляющих кодов);
– предобработка данных (исключение дубликатов, устранение ошибочных значений, восстановление пропущенных значений);
– агрегирование данных (вычисление обобщенных статистических показателей).
Основой логической организации хранилищ данных являются многомерные и реляционные модели.
Для описания структур данных в базах данных хранилища используются метаданные. Метаданные – это высокоуровневые средства отражения информационной модели. Для обеспечения удобства доступа пользователей к информации хранилища метаданные должны содержать: описание структур данных хранилища, структур данных, импортируемых из разных источников, сведения о периодичности импортирования, методах загрузки и обобщения данных, средствах доступа и правилах представления информации, оценки приблизительных затрат времени на получение ответа на запрос.
Метаданные помещаются в так называемый «репозитарий метаданных» системы. Этот компонент поддерживается большинством современных СУБД, средств разработки приложений и администрирования. Существует стандарт обмена метаданными, обеспечивающий возможность интеграции средств разных производителей друг с другом.
Многомерная модель хранилища данных
Единой общепризнанной многомерной модели хранения данных не существует. В такой модели отсутствует стандартизованный метод доступа к данным, и они могут быть ориентированы на специфику обрабатываемой информации.
В многомерных базах данных информация хранится не в виде индексированных записей в таблицах, а в форме логически упорядоченных многомерных массивов – гиперкубов. Такой подход требует большего объема памяти для хранения данных, при его использовании сложно модифицировать структуру данных. Например, добавление еще одного измерения приводит к необходимости полной перестройки гиперкуба. Однако многомерные СУБД обеспечивают более быстрый по сравнению с реляционными системами поиск и чтение данных, избавляют от необходимости многократно соединять таблицы. Среднее время ответа на сложный аналитический запрос при использовании многомерных СУБД обычно в 10 – 100 раз меньше, чем в случае реляционной СУБД с нормализованной структурой.
Основные понятия многомерной модели – измерение и значение (ячейка). Измерение – это множество, образующее одну из трех граней гиперкуба (аналог домена в реляционной модели). Измерения играют роль индексов, используемых для идентификации конкретных значений в ячейках гиперкуба. Значения – это подвергаемые анализу количественные или качественные данные, которые находятся в ячейках гиперкуба.
В многомерной модели вводятся следующие основные операции манипулирования измерениями: 1) сечение; 2) вращение; 3) детализация; 4) свертка.
При выполнении операции сечения формируется подмножество гиперкуба, в котором значение одного или более измерений фиксировано. Например, если зафиксировать значение измерения «Время» равным «январь 1999 года», то мы получим двумерную таблицу с информацией о значениях всех параметров для всех субъектов хозяйствования в январе 1999 года.
Операция вращения изменяет порядок представления измерений. Она обычно применяется к двумерным таблицам, обеспечивая представление их в более удобной для восприятия форме. Если в исходной таблице по горизонтали были расположены хозяйственные субъекты, а по вертикали параметры социально-экономической сферы, то после операции вращения параметры будут размещены по горизонтали, а названия субъектов – по вертикали.
Для выполнения операций свертки и детализации должна существовать иерархия значений измерения, то есть некоторая подчиненность одних значений другим. Например, 12 месяцев образуют год. При выполнении операции свертки одно из значений измерения заменяется значением более высокого уровня иерархии. Операция детализация – это операция, обратная свертке. Она обеспечивает переход от обобщенных данных к детализированным данным.
Основное назначение СУБД, поддерживающих многомерную модель, – это выполнение сложных нерегламентированных запросов.
Однако у многомерных баз данных есть недостатки, сдерживающие их применение:
– многомерные СУБД по сравнению с реляционными СУБД неэффективно используют память;
– в многомерной СУБД заранее резервируется место для всех значений, даже если часть из них заведомо будет отсутствовать;
– выбор высокого уровня детализации при реализации гиперкуба может очень сильно увеличить размер многомерной БД.
Реляционная модель хранилища данных
Основой при построении хранилищ данных может служить и традиционная модель данных. В этом случае гиперкуб эмулируется на логическом уровне. В отличие от многомерных СУБД реляционные СУБД способны хранить огромные объемы данных, однако они проигрывают по скорости выполнения аналитических запросов.
При использовании РаСУБД для организации хранилища данные организуются специальным образом. Чаще всего используется так называемая радиальная схема. Другое ее название – «звезда». В этой схеме используются два вида таблиц: таблица фактов (фактологическая таблица) и несколько справочных таблиц (таблицы измерений).
В таблице фактов обычно содержатся данные, наиболее интенсивно используемые для анализа. Если проводить аналогию с многомерной моделью, то запись фактологической таблицы соответствует ячейке гиперкуба. В справочной таблице перечислены возможные значения одного из измерений гиперкуба. Каждое измерение описывается своей собственной справочной таблицей. Фактологическая таблица индексируется по сложному ключу, скомпонованному из индивидуальных ключей справочных таблиц. Это обеспечивает связь справочных таблиц с фактологической по ключевым атрибутам.
В реальных системах количество строк в фактологической таблице может составлять десятки и сотни миллионов. Число справочных таблиц обычно не превышает двух десятков. Для увеличения производительности обработки данных в фактологической таблице могут храниться не только детализированные, но и предварительно вычисленные агрегированные данные.
Тема 11. Администрирование баз данных
11.1. Понятие и функции администратора базы данных
Коллективное использование базы данных требует административного контроля. Эту обязанность поручают одному или нескольким сотрудникам, которые исполняют роль администраторов базы данных.
Администратор базы данных – это коллектив людей, несущих ответственность за поддержку нормальной работы приложения (программного ресурса) и сохранность корректной базы данных в течение периода времени их использования.
Среди основных задач администрирования выделяются следующие:
– создание резервных копий баз данных;
– периодическое сжатие файлов баз данных;
– защита файлов средствами шифрования;
– изменение пароля для открытия файла;
– управление учетными записями и правами доступа для приложений, защищенных на уровне пользователей;
– установка клиентского приложения на новую рабочую станцию и корректное ее подключение к базе данных, установленной на сервере.
Администратор базы данных может также участвовать в разработке базы данных. С учетом запросов пользователей к базе данных определять ее информационное содержание и модель данных, принимать решения по физической организации данных: определять структуру памяти и стратегии доступа к данным
В корпоративных информационных системах администратору предоставляются возможности выполнения функций, связанных с распределенной обработкой данных:
– обеспечение режима оперативного совместного использования части информационной базы данных несколькими предприятиями-пользователями в рамках корпоративной структуры организации;
– проведение корпоративного межофисного обмена между базами данных, расположенными в территориально удаленных локальных вычислительных сетях;
– осуществление электронного обмена документами с организациями и банками; адаптация приложения к языковым и отраслевым особенностям пользователей.
Для выполнения своих функций администратор базы данных использует набор вспомогательных программ, таких как, системный журнал, контролирующий все обращения к базе данных, программы восстановления базы данных, программы анализа статистики использования данных.
11.2. Архивирование, сжатие и восстановление
баз данных
Под архивированием базы данных понимается создание ее резервной копии с целью страховки от потери данных. В случае повреждения файла исходной базы данных его можно заменить резервной копией.
К способам создания резервной копии базы данных относятся:
– обычное копирование файла;
– создание сжатой копии файла базы данных.
Обычное копирование используется при наличии достаточного объема свободного места на диске. При использовании СУБД Access создать копию можно с помощью стандартного приложения Проводник операционной системы Windows, с помощью команды операционной системы copy или инструкции FileCopy в процедуре VBA.
Создание сжатой копии выполняется при необходимости сэкономить место на диске с помощью программы архивирования, например, посредством стандартных средств архивирования, входящих в состав операционной системы Windows, или с помощью утилит сторонних производителей, таких как. WinZip или WinRar.
Сжатие базы данных – это процедура, приводящая к физическому уменьшению объема дискового пространства, занимаемого базой данной.
Файл базы данных при удалении данных или объектов становится фрагментированным, что приводит к неэффективному использованию дискового пространства. Сжатие файла приводит к экономии места на диске и, следовательно, повышает производительность базы данных.
Восстановление базы данных осуществляется в случаях, если она повреждена. Факт повреждения обнаруживает СУБД при попытке открытия, шифрования или дешифрования базы данных. Восстановление базы данных осуществляют процедурой сжатия. Если повреждение не обнаружено, но база данных ведет себя непредсказуемо, также выполняется ее сжатие.
При восстановлении базы данных используются результаты административной функции журнализации.
Журнализация представляет собой ведение системного журнала регистрации действий пользователей по изменению базы данных. В журнале автоматически регистрируются дата и время внесения изменений, системное имя пользователя, совершившего данные действия, а также состояние модифицированной записи таблицы баз данных до и после внесения изменений. Благодаря журналу регистраций действий пользователей в архиве возможна операция восстановления архивного варианта данных.
Процедура восстановления связана с репликацией данных, что позволяет восстанавливать данные в узлах сети. При этом восстановление базы данных выполняется путем откатки изменений базы данных (транзакций) в одном узле сети и пересылки этих изменений в другие узлы.
11.3. Защита баз данных
Понятие информационной безопасности баз данных
Базы данных представляют собой стратегический информационный ресурс, который должен удовлетворять требованиям информационной безопасности.
Основными компонентамиинформационной безопасности технологий систем с базами данных являются: компьютерная безопасность, безопасность данных, безопасность коммуникаций и безопасность программного обеспечения.
Компьютерная безопасность – это совокупность технологических и административных мер, которая обеспечивает доступность, целостность и конфиденциальность ресурсов компьютера.
Безопасность данных – это защита данных от несанкционированной модификации, разрушения или их вскрытия.
Безопасность коммуникаций – это меры по предотвращению выдачи информации по каналам связи неавторизованным лицам.
Безопасность программного обеспечения – это меры, направленные на безопасную обработку данных и безопасное использование программных ресурсов.
Необходимость защиты баз данных диктуется наличием и постоянным развитием угроз информационной безопасности.
Под угрозой безопасности понимается любое обстоятельство или событие, которое может явиться причиной нанесения ущерба системе в форме разрушения, раскрытия, модификации данных или отказа в обслуживании.
В табл.11.1. представлены разновидности и возможное содержание причин нанесения ущерба объектам информационной безопасности.
Таблица 11.1. Характеристика возможных угроз информационной безопасности
| Виды угроз | Субъект нанесения ущерба | Содержание нанесенного ущерба |
| Аппаратные | Аппаратура | Внедрение электронных устройств перехвата информации в технических средствах Дешифрование и навязывание ложной информации в сетях передачи данных и линиях связи Вредное воздействие на парольноключевые системы Радиоэлектронное подавление линий связи и систем управления |
| Программные | Программы | Внедрение программ-вирусов Незаконное копирование данных Расшифровка данных |
| Физические | Человек - злоумышленник | Уничтожение или разрушение баз данных и каналов передачи данных; Уничтожение или хищение носителей информации Хищение программных и аппаратных ключей и средств криптографической защиты информации Воздействие на персонал Установка «зараженных» компонентов в систему обработки данных |
| Технологические | Пользователи базы данных | Нарушение технологии обработки данных: Изменение метаданных в тот момент, когда к базе данных подключены другие пользователи Подключение пользователей к базе данных во время её восстановления Копирование базы данных средствами ОС при работающем сервере Большое количество генераторов в базе данных Превышение максимально допустимого размера файла Слишком большое количество транзакций Аварийное завершение сервера |
| Организационные | Системный администратор, пользователи базы данных | Несанкционированный доступ к базе данных Несанкционированное манипулирование данными (ввод, изменение и стирание данных) Бесконтрольный ввод данных в систему |
Предупреждение угроз безопасности возможно при разработке эффективной политики информационной безопасности, позволяющей создать безопасную и надежную систему с базой данных.
Система называется безопасной, если она, используя соответствующие аппаратные и программные средства, управляет доступом к информации так, что только должным образом авторизованные лица или же действующие от их имени процессы получают право читать, писать, создавать и удалять информацию.
Система считается надежной, если она с использованием достаточных аппаратных и программных средств обеспечивает одновременную обработку информации разной степени секретности группой пользователей без нарушения прав доступа.
Методы и средства защиты баз данных
Защите подлежат все объекты базы данных: таблицы, представления (формы, запросы, отчеты, модули и др.), хранимые процедуры и триггеры.
Основной проблемой информационной безопасности баз данных является ее защита от несанкционированного доступа.
К механизмам защиты баз данных от несанкционированного доступа относятся:
• физическая защита персональных компьютеров и носителей информации;
• механизм подотчетности пользователей (идентификация и аутентификация);
• разграничение доступа к элементам защищаемой информации;
• криптографическое закрытие защищаемой информации, хранимой на носителях (архивация данных);
• криптографическое закрытие защищаемой информации в процессе непосредственной ее обработки;
• использование сканеров безопасности.
Физическая защита персональных компьютеров и носителей информации предусматривает использование дверных замков, сейфов, металлических решеток. Подавляющая часть компьютеров располагается непосредственно на рабочих местах специалистов, что создает благоприятные условия для доступа к ним посторонних лиц. Многие компьютеры служат коллективным средством обработки информации, что обезличивает ответственность за сохранность и целостность данных. Современные компьютеры оснащены несъемными жесткими дисками большой емкости, информация на которых сохраняется длительное время в обесточенном состоянии.
Механизм подотчетности пользователя содержит две составляющие: идентификацию и аутентификацию.
Каждому пользователю в БД присваивается уникальный идентификатор. Для дополнительной защиты каждый пользователь кроме уникального идентификатора снабжается уникальным паролем. Идентификаторы пользователей доступны системному администратору. Пароли известны только самим пользователям и хранятся в системе чаще всего в специальном кодированном виде.
|
|
|
|
|
Дата добавления: 2014-11-06; Просмотров: 402; Нарушение авторских прав?; Мы поможем в написании вашей работы!