КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методика разработки экспертной системы
|
|
|
|
После исследований, проведенных русским математиком Марковым А.А. в начале XX столетия, интерес к информационным изменениям текстов естественного языка возобновился только с установлением Шенноном следующей формулы для вычисления количественной меры информации:
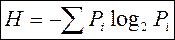 , (1)
, (1)
где Pi – вероятность или частота i-ого события.
В своей работе мы также используем данные показатели.
Pi – это показатель субъективной оценки поэтических текстов. С позиции исчисленской части языка любой текст – это множество слов. Слова образуют группы слов по какому-либо признаку. В качестве такого признака можно выбрать, например, начальную букву слова. Если число всех слов в тексте обозначить через Ni, а число слов на конкретную начальную букву – через ni, то можно определить величину Pi.
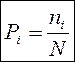 (2)
(2)
Для того, чтобы подсчитать ni, мы в ячейку F2 вставляем формулу «СЧЕТЕСЛИ» из категории «Статистические». Диапазон указывается «В:В» (английский регистр), условие «Е2», затем размножаем формулу до конца таблицы (см. рис.3.).

Рис.1.
Для подсчета Ni в ячейку E30 вводится «N =», а в ячейку F30 вставляется формула суммы всех букв. Для этого щелкаем на этой ячейке и затем по кнопке «Автосумма»  , и нажимаем клавишу «Enter» на клавиатуре. В итоге получается следующая таблица (см. рис.2):
, и нажимаем клавишу «Enter» на клавиатуре. В итоге получается следующая таблица (см. рис.2):

Рис.2.
Далее возвращаемся к нашей формуле (2) и считаем Pi. В ячейку G2 ввести «=F2/F$30», а затем размножить до конца таблицы. В результате в столбце G получим значение Pi (см. рис.3.).
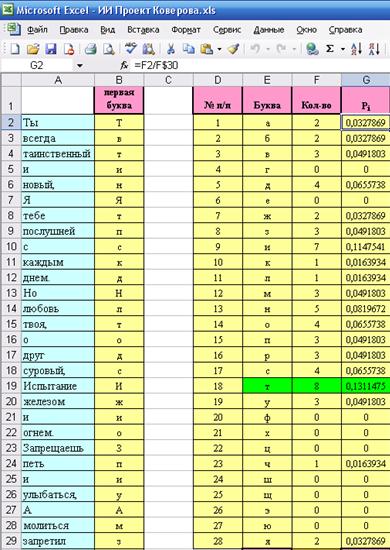
Рис.3.
Вернемся к формуле (1). Величина Hi измеряется в битах и ее часто называют энтропией информации. Формулу (1) стали применять при анализе кодов, используемых при передаче сообщений, составленных на каком-либо естественном языке.
Для подсчета H1 в ячейку H2 вводим
«=ЕСЛИ (G2=0;0;-G2*Log(G2;2))», что соответствует формуле (1), а затем размножаем до конца таблицы. В ячейку G30 вводим «Н =». В ячейку Н30 вставляем формулу автосуммы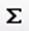 (см. рис.4.).
(см. рис.4.).
Рис. 4.
Анализ таблицы, приведенный ниже показывает, что количественная мера информации Н1 различна для каждого произведения, и ее числовые значения для стихов Ахматовой изменяются в пределах от 3, 669 до 4, 213 (см. рис.5.).

Рис.5.
Для проведения несубъективного анализа необходимо еще посчитать несколько показателей. Одним из них является N2.
N2 – показывает общее количество букв в тексте. Для нахождения этого показателя мы подсчитали количество всех букв, начиная с «а», в стихотворении и перенесли данные в таблицу.
Для этого нужно в меню « Правка » выбрать команду « Заменить ». В окне диалога « Заменить » после слова «Найти» пишем «а» и щелкаем по кнопке « Заменить все ». Программа сообщает нам, сколько произведено замен. Это число 20 и есть количество букв «а» в тексте (см. рис.6.).
Рис. 6.
Заносим количество букв «а» с клавиатуры в таблицу, в ячейку L2. Проделываем эту операцию с остальными буквами, после чего столбец L окажется полностью заполненным (см. рис.7.).

Рис.7.
Далее в MS Excel проводим подсчет всех букв в стихотворении. Для этого щелкаем по ячейке L35. В меню «Вставка» выбираем команду «СУММ» и щелкаем по кнопке «ОК», для перехода к шагу 2. В появившемся окне « Аргументы функции » напротив надписи « Число 1 » набираем с клавиатуры или выделяем мышкой диапазон ячеек L2:L34 и щелкаем по кнопке «ОК». В результате чего в ячейке L35 оказалось число 262, равное числу всех букв в тексте стихотворения. В ячейку K35 вводим с клавиатуры «N2 =», так как число букв нами обозначено через N2 (см. рис.8.)
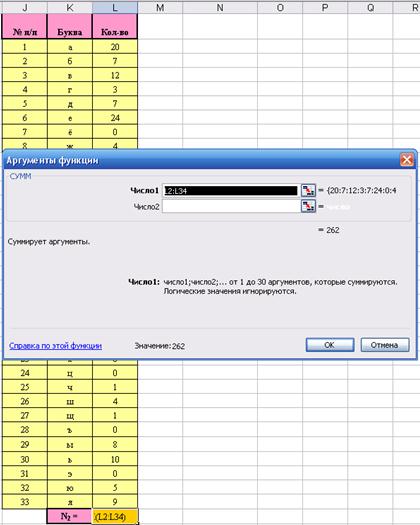
Рис. 8.
Также в анализе необходимо посчитать показатель Н2. Он вычисляется с помощью функции ЕСЛИ и формулы Шеннона:
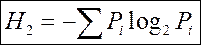
Для этого в ячейке N2 мы вводим следующую формулу: «=ЕСЛИ(M2=0;0;-M2*LOG(M2;2))» и растягиваем до ячейки N34. Затем в ячейку M35 вносим обозначение энтропии «Н2 =», а в ячейке N35 суммируем диапазон ячеек N2:N34 с помощью функции автосуммы  (=СУММ(N2:N34)). Получаем следующую таблицу (см. рис.9.):
(=СУММ(N2:N34)). Получаем следующую таблицу (см. рис.9.):
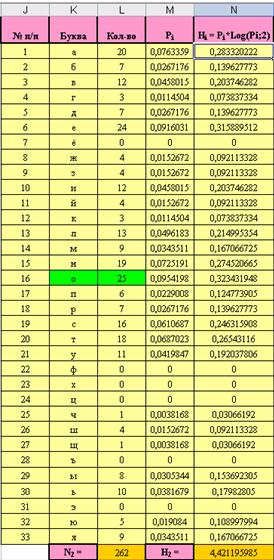
Рис. 9.
Так как в ходе проводимого нами анализа удалось выявить тексты, для которых H1 и H2 близки, мы вводим новый критерий ∆ = Н2-Н1. Эталонными считаются значения от 0,2 до 0,7 (см. рис.10.).
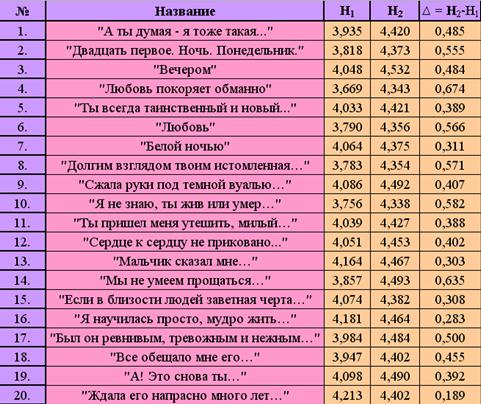
Рис. 10.
Далее определим среднее количество букв в слове, обозначим этот показатель как S.
S = N2/N1,
где N2 – общее количество букв в стихотворении;
N1 – общее количество слов в стихотворении.
Минимальное значение составляет 4,1 («Я не знаю, ты жив или умер…»), а максимальное 5,2 («Долгим взглядом твоим истомленная…», «Я научилась просто, мудро жить…»). Этот показатель оказывает непосредственное влияние на показатель уровня образования (λ1) (см. рис.11).
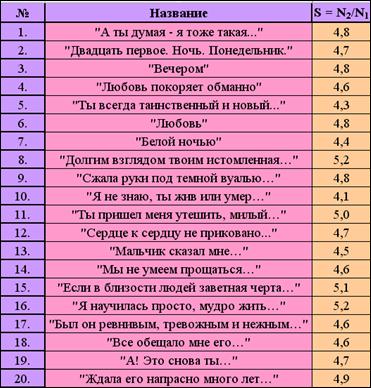
Рис. 11.
Учебный текст должен быть удобочитаем и понимаем. В настоящее время имеется ряд исследований, в которых предложены математические модели анализа сложности текстов вообще и учебных текстов с учетов возрастных особенностей учащихся, в частности. Однако, с одной стороны, эти модели получены, преимущественно для английских текстов, а с другой, не подкреплены соответствующими системами автоматизированного анализа с практичным и удобным интерфейсом. Между тем, потребность в такого рода системах и соответствующих методиках анализа текстов существует не только у экспертов-методистов федерального или регионального уровней, но и у создателей учебников и методик, у учителей, разрабатывающих различные дидактические материалы.
Подпрограмма «Статистика удобочитаемости» показывает общие средние количества символов, слов и предложений, а также позволяет оценить показатели легкости чтения текста. Эти показатели характеризуют текст с точки зрения того, насколько должен быть подготовлен читатель для его восприятия (см. рис.12).
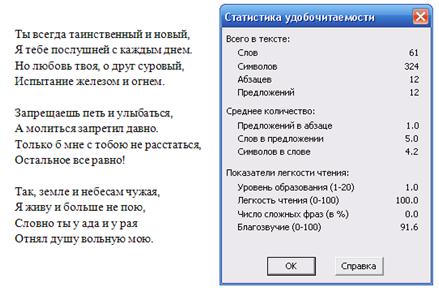
Рис. 12.
λ1 – уровень образования, основан на образовательном индексе Флеша-Кинсайда и показывает, каким уровнем образования должен обладать читатель исследуемого текста. Подсчет делается на основе вычисления среднего числа слогов в слове и слов в предложении.
Значения показателя от 0 до 20:
· от о до 10 – число классов школы, оконченных читателем;
· от 11 до 15 – курсы высшего учебного заведения;
· от 16 до 20 – относятся к сложным научным текстам.
Эталонным считаются от 1 до 3,7.
Рассчитывается по формуле:
λ1 = (0,39 * СДП) + (11,8 * СЧС) – 15,59,
где СДП – средняя длина предложения (= число слов в документе/число предложений);
СЧС – среднее число слогов в документе (= число слогов в документе/число слов).
λ2 – легкость чтения, подсчитывается по среднему числу слогов в слове и слов в предложении. Чем выше значение, тем легче прочесть текст и тем большему числу читателей он будет понятен.
Варьируется от 0 до100. Рекомендуемый интервал значений - от 60 до 70.
Рассчитывается по формуле:
λ2 = 206,835 – (1,015 * СДП) – (84,6 * СЧС)
λ3 – благозвучие, указывает на удобочитаемость текста с фонетической точки зрения. Подсчет основан на вычислении среднего количества шипящих и свистящих согласных.
Интервал изменения показателя – от 0 до 100. Рекомендуемый диапазон значений – от 80 до 100.
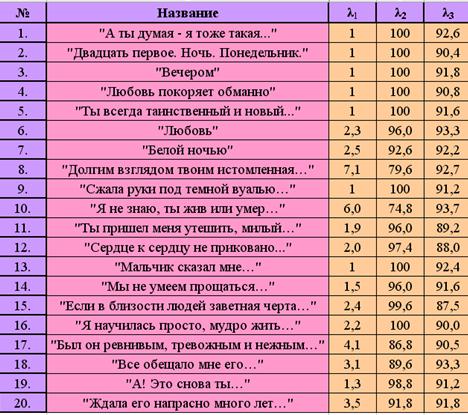
Рис. 13.
|
|
|
|
|
Дата добавления: 2014-10-31; Просмотров: 353; Нарушение авторских прав?; Мы поможем в написании вашей работы!