КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Соединение и разбиение наборов данных
Вопросы для защиты
1. Назначение узла Групповая обработка.
2. Как добавить узел Групповая обработка?
3. Как определить группы обработки?
4. Для чего используется кэш?
Лабораторная работа №7
Цель работы: ознакомиться с инструментами Мастера обработки Deductor/
1. Парциальная предобработка
Парциальная предобработка служит для восстановления пропущенных данных, редактирования аномальных значений и спектральной обработки данных (например, сглаживания данных). Именно эти операции часто проводятся в первую очередь над данными.
Присутствие аномалий при построении моделей оказывает на них большое влияние, ухудшая качество результата.
В качестве примера возьмем данные из файла Trade.txt. В данном файле находятся данные о продажах за некоторый период.
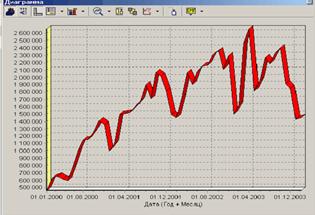
Как видно из диаграммы, выбросы ухудшают статистическую картину распределения данных. Воспользуемся Мастером обработки и выберем парциальную обработку.
В Мастере парциальной предобработки на втором шаге выбираем поле Количество и указываем ему тип обработки Редактирование аномальных значений, степень подавления Большая. Так как больше никаких действий над данными не планировалось, то переходим на шаг запуска процесса обработки.
После выполнения процесса обработки на диаграмме видно, что выбросы уменьшились стала проясняться реальная картина продаж.
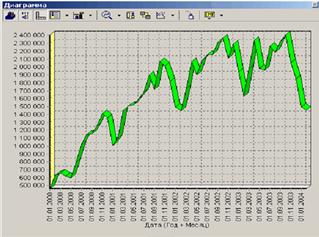
2. Спектральная обработка
Продемонстрируем такой метод спектральной обработки, как вычитание шума. Для этого продолжим работу с данными файла Trade.txt.
Сгладим данные при помощи парциальной обработки.
В Мастере парциальной предобработки на третьем шаге выбираем поле Количество и указываем ему тип обработки Вычитание шума, степень
подавления Большая.
После выполнения процесса обработки выберем в качестве визуализации диаграмму.
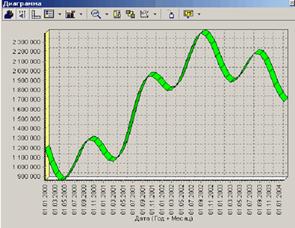
Как видно из примера данные стали более сглаженными и могут служить для дальнейшей обработки. Взглянув на данные легко понять общую тенденцию.
3. Факторный анализ
Факторный анализ служит для понижения размерности пространства входных факторов. Обработку можно выполнять как в автоматическом режиме (с указанием порога значимости), так и вручную (основываясь на значениях матрицы значимости).
Рассмотрим применение обработчика на примере данных из файла Anketa1.txt. Он содержит таблицу с информацией о кредитах граждан.
Попробуем выявить значение факторов, влияющих на возврат кредита.
В Мастере обработки выберем факторный анализ и зададим входные поля - Личный доход в месяц, Сумма кредита, Стаж работы, Рыночная стоимость автомобиля, Рыночная стоимость недвижимости.
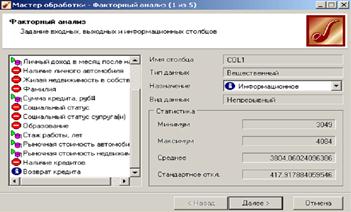
На следующем шаге предлагается запустить процесс понижения размерности пространства входных факторов. После завершения процесса можно выбрать, какие из полученных в результате обработки факторы оставить для дальнейшей работы. Это делается путем указания необходимого порога значимости.
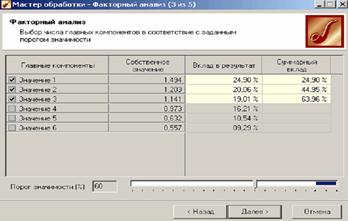
Теперь необходимо перейти на следующий шаг и выбрать способ визуализации; результаты просмотрим в таблице.
4. Корреляционный анализ
Корреляционный анализ применяется для оценки зависимости выходных полей данных от входных факторов и устранения незначащих факторов. Принцип корреляционного анализа состоит в поиске таких значений, которые в наименьшей степени коррелированны (взаимосвязаны) с выходным результатом. Такие факторы могут быть исключены из результирующего набора данных практически без потери полезной информации. Критерием принятия решения об исключении является порог значимости. Если корреляция (степень взаимозависимости) между входным и выходным факторами меньше порога значимости, то соответствующий фактор отбрасывается как незначащий.
Рассмотрим применение обработки на примере данных из файла region.txt. В данном примере определим степень влияния экономических показателей региона на среднедушевой доход жителей.
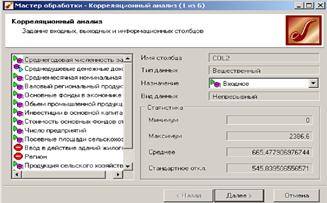
На следующем шаге необходимо выбрать метод, на основе которого будет происходить расчет коэффициентов корреляции, выберем метод коэффициент корреляции Пирсона.
После выполнения предварительных настроек запускаем процесс корреляционного анализа, по результатам которого предлагается выбрать, какие факторы оставить для дальнейшей работы. Это делается либо вручную, основываясь на значениях матрицы ковариации, либо путем указания порога значимости (по умолчанию порог значимости равен 0.05).
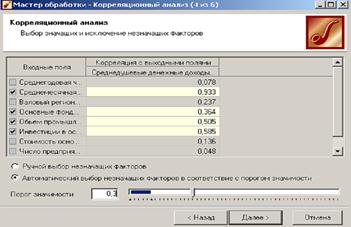
По полученной матрице корреляции видно, какие факторы влияют сильнее, чем другие, и какие можно не учитывать при построении всевозможных моделей.
5. Дубликаты и противоречия
Одна из серьезных проблем, часто встречающаяся на практике, - наличие в данных дубликатов и противоречий.
Противоречивыми являются группы записей, в которых содержатся строки с одинаковыми входными факторами, но разными выходными. В такой ситуации непонятно, какое результирующее значение верное. Если противоречивые данные использовать для построения модели, то она окажется неадекватной. Поэтому противоречивые данные чаще всего лучше вообще исключить из исходной выборки.
Также в данных могут встречаться записи с одинаковыми входными факторами и одинаковыми выходными, т.е. дубликаты. Таким образом, данные несут избыточность. Присутствие дубликатов в анализируемых данных можно рассматривать как способ повышения "значимости" дублирующейся информации. Иногда они даже необходимы, например, если при построении модели нужно особо выделить некоторые наборы значений.
Но все равно включение в выборку дублирующей информации должно происходить осознанно: в большинстве случаев дубликаты в данных являются следствием ошибок при подготовке данных.
Так или иначе возникает задача выявления дубликатов и противоречий.
В Deductor Studio для автоматизации этого процесса есть соответствующий инструмент – обработка Дубликаты и противоречия.
Суть обработки состоит в том, что определяются входные (факторы) и выходные (результаты) поля. Алгоритм ищет во всем наборе записи, для которых одинаковым входным полям соответствуют одинаковые (дубликаты) или разные (противоречия) выходные поля. На основании этой информации создаются два дополнительных логических поля – Дубликат и Противоречие, принимающие значения "правда" или "ложь". В дополнительные числовые поля Группа дубликатов и Группа противоречий записываются номер группы дубликатов и группы противоречий, в которые попадает данная запись. Если запись не является дубликатом или противоречием, то соответствующее поле будет пустым.
Рассмотрим механизм выявления дубликатов на примере данных файла Anketa.txt. В этом файле находится информация об анкетных данных граждан, участвующих в кредитовании. Попробуем вычислить присутствие дубликатов.
Импортируем данные из текстового файла и посмотрим их в виде таблицы.
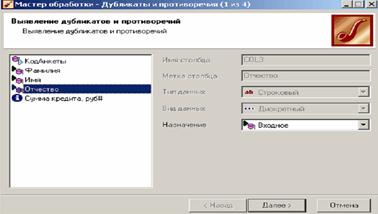
Для выявления дубликатов запустим Мастер обработки. В нем выберем тип обработки Дубликаты и противоречия.
На втором шаге Мастера необходимо настроить назначение полей.
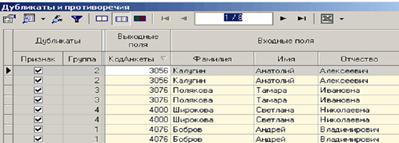
После завершения выявления дубликатов просмотрим результат в виде таблицы дубликатов и противоречий.
В первом случае видно, что существуют одинаковые строки, являющиеся дубликатами. Данный обработчик показывает дубликаты и их принадлежность к группам дубликатов.
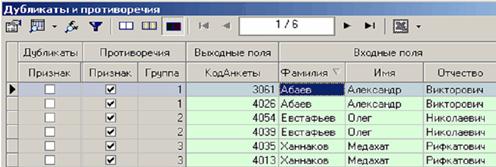
Во втором случае видно, что при одинаковых Фамилия, Имя, Отчество оказываются различные Коды Анкет. В данном обработчике видно, у каких строк существуют противоречия и к какой группе они относятся.
Задание для практической работы
1. Выполните Парциальную предобработку данных из файла Trade.txt
2. Выполните Спектральную обработку с данными файла Trade.txt
3. Выполните Корреляционный анализ данных из файла region.txt
4. Выполните Выявления дубликатов на примере данных файла
Anketa.txt.
|
|
Дата добавления: 2014-10-31; Просмотров: 1014; Нарушение авторских прав?; Мы поможем в написании вашей работы!