КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Отсюда ценность информации определяется как
|
|
|
|
Отсюда
f = k ln M /ln K = k 1loga M/ ln K = k 0 loga M,
где k 0 = k 1/ln K; k 1 =k ln a.
За единицу количества информации примем число сведений, которые передаются двумя равновероятными сообщениями. Назовем эту единицу двоичной единицей информации. Тогда для f= 1, М =2 получим J = k 0 loga2. Отсюда а = 2, k 0 = 1 и, следовательно, количество информации в сообщении составит I =log2 M.
Эта формула получила название формулы Хартли. Из нее следует, что для равновероятных дискретных сообщений количество информации зависит лишь от числа передаваемых сообщений.
Если сообщения отображаются неизбыточным кодом, то, подставляя М = Kn, получим I= п log2 К.
Видно, что число двоичных единиц информации, содержащихся в одном сообщении, прямо пропорционально длине кода п и возрастает с увеличением его основания. Если основание кода К= 2, то количество информации, содержащееся в любом сообщении, передаваемом неизбыточным кодом, составит I = п двоичных единиц или бит. Отсюда видно, что если длина сообщения равна п, то сообщение содержит п бит информации, т.е. один элемент кода несет одну двоичную единицу информации. Информация, содержащаяся в сообщении, складывается из информации, которую несет каждый элемент кода, поэтому мера информации является аддитивной.
Аддитивность статистической меры информации позволяет определить ее количество и в более общем случае, когда передаваемые дискретные сообщения являются неравновероятными. Можно предположить, что количество информации, содержащейся в конкретном дискретном сообщении, функционально зависит от вероятности выбора этого сообщения. Тогда для сообщения x 0 j возникающего с вероятностью P (x 0 j), количество информации может быть описано в виде 1= φ[ P (x 0 j)]Пусть вслед за сообщением x 0 j, из источника формируется сообщение x 0 k. Вероятность последовательного возникновения этих сообщений обозначим Р (x 0 j, xjk). Количество информации, которая будет содержаться в этих сообщениях, оценим как 1 = φ[ Р (x 0 j, x 0 k)]. Учитывая аддитивный характер принятой выше статистической меры информации, будем считать, что количество информации, заключенное в последовательности сообщений x 0 j, x 0 k,равно сумме количеств информации, содержащихся в каждом из выбранных сообщений. Тогда
φ[ Р (x 0 j, x 0 k)] = φ[ Р (x 0 j)] + φ[ Р (x 0 k / x 0 j)],
где Р (x 0 k / x 0 j) — вероятность возникновения сообщения x 0 k при условии появления перед ним сообщения x 0 j.
Соответственно вероятность возникновения последовательности сообщений x 0 j, x 0 k составит Р (x 0 j, x 0 k) = Р (x 0 j) [ Р (x 0 k / x 0 j)]. Отсюда
φ[ Р (x 0 j)] + φ[ Р (x 0 k / x 0 j)] = φ[ Р (x 0 j)] + φ[ Р (x 0 k / x 0 j)].
Дифференцируя по переменной Р (x 0 j), получим
Р (x 0 k / x 0 j) φ΄[ Р (x 0 j) Р (x 0 k / x 0 j)] = φ΄[ Р (x 0 j)]
Умножим левую и правую части уравнения на вероятность Р (x 0 j), тогда
Р (x 0 j) Р (x 0 k / x 0 j) φ΄[ Р (x 0 j) Р (x 0 k / x 0 j)] = Р (x 0 j) φ΄[ Р (x 0 j)]
Учитывая, что вероятность Р (x 0 j) находится в пределах от 0 до 1, видим, что части уравнения должны представлять собой постоянную величину, т.е. Р (x 0 j) φ΄[ Р (x 0 j)] = k, где k — постоянная величина. Отсюда φ΄[ Р (x 0 j)] = k/Р (x 0 j). Количество информации в j -м сообщении составит
φ[ Р (x 0 j)] = k ln Р (x 0 j) + с,
где с — постоянная интегрирования. Для определения с рассмотрим частный случай, когда имеет место передача лишь одного j -го сообщения, т.е. Р (x 0 j) = 1. Подставляя Р (x 0 j) = 1 в приведенное уравнение, находим, что с = 0, а отсюда
φ[ Р (x 0 j)] = k ln Р (x 0 j).
Для определения постоянной k выберем систему единиц. Естественным требованием является то, что количество информации должно быть положительной величиной, тогда, принимая k = 1, получаем
φ[ Р (x 0 j)] = –ln Р (x 0 j).
Тогда в качестве единицы информации можно принять натуральную единицу. Количество информации в одну натуральную единицу (1 нат) равно информации, которая передается в одном сообщении с вероятностью появления 1/е. Как указывалось выше, в статистической теории получила применение двоичная единица информации, что соответствует коэффициенту k = –1/ln 2. Тогда количество информации для неравновероятных сообщений составит
I = φ[ Р (x 0 j)] = –log2.
При необходимости количество информации в случайно выбранном сообщении нетрудно связать с информативностью символов кода сообщения. Если процесс образования символов описывается цепью Маркова и символы могут принимать К значений, то найти вероятность возникновения сообщения Р (x 0 j)можно как произведение вероятностей возникновения символов его кода. Если они выбираются независимо и символ типа j встречается nj раз, то вероятность возникновения сообщения x 0 j, составит
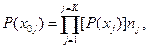
где P(xj) — вероятность возникновения символа типа j.
При большой длине кода п можно считать, что nj = nP(xj), а так как выше установлено, что количество сообщения x 0 j составляет I = –log2 Р (x 0 j), то, подставляя полученные выше значения вероятности Р (x 0 j) найдем количество информации I в виде
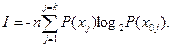
Видно, что количество информации прямо пропорционально длине кода п и информативности отдельно взятого символа. Отметим, что максимально возможное количество информации, т.е. максимум записанного выше выражения, получается, если символы равновероятны. Тогда для множества символов К оптимальное равномерное распределение соответствует Р(хj) = 1 /К. В этом случае получим, что I = n log2 К. Для двоичного кода К = 2, I = п, что соответствует количеству информации для неизбыточного кода при равновероятных сообщениях. Введенная количественная статистическая мера информации широко используется в теории информации для оценки количества собственной, условной, взаимной и других видов информации. Рассмотрим это на примере собственной информации.
Под этим будем понимать информацию, которая содержится в данном конкретном сообщении. В соответствии с этим определением количество собственной информации в сообщении х 0 j определяется как I (x 0 j) = –log2 Р (x 0 j). Количество собственной информации измеряется числом бит информации, содержащихся в сообщении х 0 j . Для нее могут быть сформулированы следующие свойства:
1. Собственная информация неотрицательна. Чем меньше вероятность возникновения сообщения, тем больше количество информации, содержащейся в нем. Если сообщение имеет вероятность возникновения, равную единице, то получаемая с ним информация равна нулю, так как заранее известно, что может прийти только это сообщение, и выявление данного сообщения не несет потребителю никакой информации.
2. Собственная информация обладает свойством аддитивности. Для доказательства этого рассмотрим ансамбль из множества сообщений {X, У}. Найдем количество собственной информации для пары сообщений х 0 j , у 0 i :
I (х 0 j , у 0 i ) = –log2 Р (x 0 j, у 0 i ).
Если сообщения х 0 j , у 0 i статистически независимы, то Р (x 0 j, у 0 i ) = Р (x 0 j) Р (у 0 i ). Количество информации в двух сообщениях составит
I (х 0 j , у 0 i ) = –log2 Р (x 0 j) – log2 Р (у 0 i ) = I (х 0 j ) + I (у 0 i )
Таким образом, количество собственной информации в двух независимых сообщениях равно сумме собственных сообщений. Отметим, что она характеризует сообщение, которое возникает случайным образом из источника, а поэтому является случайной величиной и зависит от номера выбранного сообщения.
Рассмотрим понятия и свойства энтропии дискретных систем. Математическое ожидание случайной величины собственной информации называется энтропией. Энтропия рассчитывается на множестве (ансамбле) сообщений X 0 либо на множестве символов X и физически определяет среднее количество собственной информации, которое содержится в элементах множества (либо сообщений, либо символов). Для источника сообщений случайная величина собственной информации принимает значения I (х 01), I (х 02), …, I (х 0 j), …, I (х 0 M) cвероятностями P (х 01), P (х 02), …, P (х 0 j), …, P (х 0 M) соответственно.
Среднее количество (математическое ожидание) собственной информации, содержащейся в ансамбле сообщений Х 0, т.е. энтропия этого ансамбля, составит
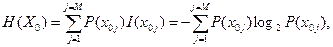
где М — множество сообщений в ансамбле X 0. Содержательно энтропия H (X 0) показывает количество двоичных единиц информации, которая содержится в любом сообщении из множества Х 0.
Следует отметить, что понятие энтропии исторически использовалось для оценки меры неопределенности состояния любой системы. Чем больше энтропия системы, тем больше неопределенность ее состояния и тем большую информацию получаем, когда эта неопределенность снимается. Энтропия как количественная мера информации обладает следующими свойствами [48J:
1. Функция энтропии является непрерывной относительно вероятности возникновения событий и для дискретных событий имеет наибольшее значение при равной вероятности их появления. Если возможно появление лишь одного события, то априорной неопределенности нет, поэтому количество информации и энтропия равны нулю;
2. При равновероятных событиях функция энтропии возрастает с увеличением числа событий в ансамбле, а поэтому для повышения информативности символов необходимо увеличивать основание системы счисления используемого кода;
3. Функция энтропии не зависит от пути выбора событий. Это свойство вытекает из аддитивности статической меры информации и, как следствие, аддитивности функции энтропии;
Теперь перейдем к понятиям «энтропия источника» и «энтропия сообщения». При кодировании важно обеспечить выбор кода, который оптимально согласуется с источником. Это согласование возможно по критерию энтропии источника. Под энтропией источника обычно понимают количество информации, которая в среднем содержится в одном символе кода. Если код имеет основание системы счисления К, то энтропия источника, т.е. среднее количество информации, содержащейся в символе кода, составит
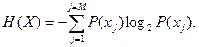
Содержательно энтропия источника показывает, сколько двоичных единиц информации переносится в среднем в одном символе кода. Для повышения информативности источника необходимо стремиться к равновероятности символов. В этом случае для неизбыточного кода в одном символе передается двоичная единица информации. С введением избыточности информативность символа уменьшается, но появляются возможности, связанные с обнаружением и исправлением ошибок, что обеспечивает требуемую помехоустойчивость передачи сообщений. Среднее количество информации, содержащееся в сообщении, называется энтропией сообщения и определяется в виде
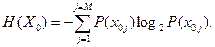
Видно, что энтропия сообщения представляет собой математическое ожидание собственной информации, содержащейся в ансамбле сообщений Х 0. Таким образом, энтропия является универсальной статистической характеристикой, позволяющей оценить количество информации, которая содержится в любом ансамбле дискретных событий.
Понятие энтропии применимо и к непрерывным событиям. В системах обработки информации и управления значительная доля информации имеет непрерывный характер и выражается в виде непрерывной функции от времени. В этом случае возникает задача передачи непрерывной информации в виде непрерывных сообщений по каналам связи. Непосредственная передача непрерывных сообщений без преобразования возможна лишь на незначительные расстояния. С увеличением расстояний осуществляют операцию дискретизации информации. Для этого вводят квантование по времени и по уровню. Непрерывная функция передается в виде совокупности мгновенных либо квантовых отсчетов, выбранных с различными интервалами по времени. Оценим количество информации, которая содержится в одном отсчете непрерывной функции, и найдем общее выражение для энтропии непрерывных событий.
Пусть имеет место непрерывная информация, представленная в виде непрерывной функции x(t) сизвестной плотностью распределения вероятностей амплитудных значений W(х). Разобьем область значений функции на K уровней с интервалом квантования 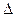 x, тогда получим уровни x 1, x 2,..., xj,..., хк. При достижении функцией x(t) некоторого уровня xj и передаче этого уровня по каналу связи количество передаваемой информации может быть определено с помощью функции энтропии H (xj), если известна вероятность возникновения отсчета P(xj). Для нахождения вероятности P(xj) построим плотность распределения P(xj) и отметим отсчеты функций x 1, x 2,..., xj, (рис. 1.3). Вероятность
x, тогда получим уровни x 1, x 2,..., xj,..., хк. При достижении функцией x(t) некоторого уровня xj и передаче этого уровня по каналу связи количество передаваемой информации может быть определено с помощью функции энтропии H (xj), если известна вероятность возникновения отсчета P(xj). Для нахождения вероятности P(xj) построим плотность распределения P(xj) и отметим отсчеты функций x 1, x 2,..., xj, (рис. 1.3). Вероятность 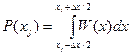 отображена заштрихованной на рис. 1.3 площадью под кривой W(х). Для упрощения расчетов заменим эту площадь другой площадью эквивалентного прямоугольника с основанием x и высотой W(хj), тогда вероятность P(xj) = W(хj) x. Отсюда количество собственной информации, содержащейся в отсчете xj, составит
отображена заштрихованной на рис. 1.3 площадью под кривой W(х). Для упрощения расчетов заменим эту площадь другой площадью эквивалентного прямоугольника с основанием x и высотой W(хj), тогда вероятность P(xj) = W(хj) x. Отсюда количество собственной информации, содержащейся в отсчете xj, составит
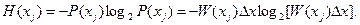
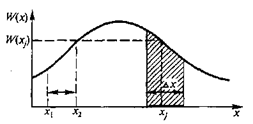
Рис. 1.3. Зависимость плотности распределения вероятностей W(х) от уровня амплитуды x
Энтропия отсчета определяет количество информации, которая передается отсчетом функции xj. С уменьшением шага дискретизации x, т.е. при x → 0, можно найти lim H(xj), т.е. предварительное значение
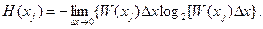
Учитывая, что исходная функция x(t) непрерывна и может изменяться в неограниченных пределах, найдем энтропию непрерывного сообщения как сумму энтропии отсчетов в виде
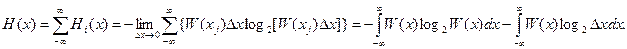
Второе слагаемое содержит член log2 x, который не рассчитывается, так как с уменьшением x он может стать бесконечно большой величиной. Обычно определяют так называемую дифференциальную или приведенную энтропию в виде
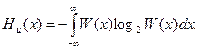
Таким образом, понятие энтропии применимо и для оценки среднего количества информации, которая содержится в непрерывном сообщении. Однако пользоваться выражением энтропии для непрерывных сообщений следует крайне осторожно, учитывая неопределенность второго слагаемого выражения, особенно при малых значениях шага квантования x.
В целом в отношении энтропии непрерывного сообщения можно сделать следующие выводы:
1. Дифференциальная энтропия определяется статистикой отсчетов непрерывной функции. Можно показать, что при постоянной дисперсии отсчетов наибольшее количество информации соответствует непрерывным сообщениям, отсчеты которых распределяются по нормальному закону;
2. Энтропия зависит от амплитуды исходной непрерывной функции х и шага ее квантования x. На практике реализуют системы с равномерным и неравномерным шагом квантования, с передачей отклонения функции от математического ожидания и др. Это позволяет в конкретных условиях повысить скорость передачи информации в непрерывном канале.
Таким образом, статистическая теория позволяет дать плодотворные оценки количества информации для такого важного этапа информационного процесса в системе, как передача. Заложенные еще К. Шенноном принципы количественной оценки на основе функции энтропии сохраняют свою значимость до настоящего времени и являются полезными при определении информативности символов и сообщений и при оценке оптимальности построения кода на основе критериев избыточности.
В современных системах обработки информации и управления существенное место занимает подготовка информации для принятия решения и сам процесс принятия решения в системе. Здесь существенную помощь может оказать семантическая теория, позволяющая понять смысл и содержание информации, выражаемой на естественном языке. С увеличением объема и сложности производства количество информации, необходимое для принятия безошибочного решения, непрерывно возрастает. В этих условиях необходимо осуществлять отбор информации по некоторым критериям, т.е. предоставлять руководителю либо лицу, принимающему решение, своевременную и полезную информацию. С учетом ошибок, которые могут возникать в информации в связи с действиями оператора, отказами технических средств в др., избыточность допускается лишь как средство борьбы с ошибками. В этом смысле можно считать, что избыточность способствует сохранению ценности информации, обеспечивая требуемую верность. В рамках семантического подхода ценность информации можно задать через функцию потерь. Если в процессе подготовки информации исходная величина х отображается через величину у, то минимум потерь можно установить как
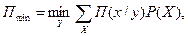
где Р(х) — распределение входной величины х; П (х/у) — потери при преобразовании входной величины х в величину у.
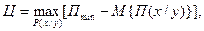
где М{П(х/у)} — математическое ожидание потерь при отклонении от входной величины х к величине у.
Следует отметить, что данная интерпретация ценности имеет сугубо технический характер. Конструктивным выходом из нее является такое разбиение входной величины х, при котором удается максимизировать ценность. В общем случае ценность информации, поступающей от материального объекта, является функцией времени. Анализ информации, используемой для принятия решения в реальных системах, позволил найти функции ценности. Эти функции задают предельные временные интервалы, в течение которых имеет смысл использовать данную информацию. При принятии решения обычно используется информация не только о материальном объекте, но и об условных распределениях критериальных оценок последствий различных альтернативных решений. В этом случае резко уменьшается число предпочтительных альтернатив и удается принять решение, базируясь на качественно неполной информации. В ряде практических случаев решение принимается с использованием субъективных критериев, при этом приходится применять большой объем информации, ужесточать требования к согласованности и непротиворечивости исходной информации. Принцип принятия решений по своей методологии требует сохранения содержания качественных понятий на всех этапах использования информации при общей оценке альтернативных решений. Кроме того, исключается сложная информация, при работе с которой лицо, принимающее решение, должно иметь дело с громоздкими задачами. Используют замкнутые процедуры выявления предпочтений, т.е. процедуры, в которых имеется возможность проверить предпочтение на непротиворечивость и транзитивность. Можно отметить, что семантическая теория требует дальнейшей серьезной проработки, однако уже сейчас при принятии решений существует ряд методов, позволяющих оценивать смысловое содержание информации.
|
|
|
|
|
Дата добавления: 2014-10-31; Просмотров: 729; Нарушение авторских прав?; Мы поможем в написании вашей работы!