КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Декодирующие устройства
|
|
|
|
Декодирование комбинаций циклического кода можно проводить различными методами. Существуют методы, основанные на использовании рекуррентных соотношений, на мажоритарном принципе, на вычислении остатка от деления принятой комбинации на образующий многочлен кода и др. Целесообразность применения каждого из них зависит от конкретных характеристик используемого кода.
Рассмотрим сначала устройства декодирования, в которых для обнаружения и исправления ошибок производится деление произвольного многочлена f(x), соответствующего принятой комбинации, на образующий многочлен кода g0(x). В этом случае при декодировании могут использоваться те же регистры сдвига, что и при кодировании.
Таблица 4.18.
| Номер такта | Состояние ячеек регистра | Выход | |||
| - - - | - - - | - - | - |
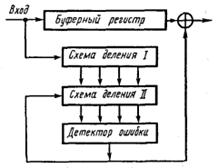
Рис. 4.17.
Декодирующие устройства для кодов, обнаруживающих ошибки, по существу ничем не отличаются от схем кодирующих устройств. В них добавляется лишь буферный регистр для хранения принятого сообщения на время проведения операции деления. Если остатка не обнаружено (случай отсутствия ошибки), то информация с буферного регистра считывается в дешифратор сообщения. Если остаток обнаружен (случай наличия ошибки), то информация в буферном регистре уничтожается и на передающую сторону посылается импульс запроса повторной передачи.
В случае исправления ошибок схема несколько усложняется. Информацию о разрядах, в которых произошла ошибка, несет, как и ранее, остаток. Схема декодирующего устройства представлена на рис. 4.17.
Символы подлежащей декодированию кодовой комбинации, возможно, содержащей ошибку, последовательно, начиная со старшего разряда, вводятся в n-разрядный буферный регистр сдвига и одновременно в схему деления, где за n тактов определяется остаток, который в случае непрерывной передачи сразу же переписывается в регистр второй аналогичной схемы деления.
Начиная с (n + 1)-го такта в буферный регистр и первую схему деления начинают поступать символы следующей кодовой комбинации. Одновременно на каждом такте буферный регистр покидает один символ, а в регистре второй схемы деления появляется новый остаток (синдром). Детектор ошибок, контролирующий состояния ячеек этого регистра, представляет собой комбинаторно-логическую схему, построенную с таким расчетом, чтобы она отмечала все те синдромы («выделенные синдромы»), которые появляются в схеме деления, когда каждый из ошибочных символов занимает крайнюю правую ячейку в буферном регистре. При последующем сдвиге детектор формирует сигнал «1», который, воздействуя на сумматор коррекции, исправляет искаженный символ.
Одновременно по цепи обратной связи с выхода детектора подается сигнал «1» на входной сумматор регистра второй схемы деления. Этот сигнал изменяет выделенный синдром так, чтобы он снова соответствовал более простому типу ошибки, которую еще подлежит исправить. Продолжая сдвиги, обнаружим и другие выделенные синдромы. После исправления последней ошибки все ячейки декодирующего регистра должны оказаться в нулевом состоянии. Если в результате автономных сдвигов состояние регистра не окажется нулевым, это означает, что произошла неисправимая ошибка.
Для декодирования кодовых комбинаций, разнесенных во времени, достаточно одной схемы деления, осуществляющей декодирование за 2n тактов.
Сложность детектора ошибок зависит от числа выделенных синдромом. Простейшие детекторы получаются при реализации кодов, рассчитанных на исправление единичных ошибок.
Выделенный синдром появляется в схеме деления раньше всего в случае, когда ошибка имеет место в старшем разряде кодовой комбинации, так как он первым достигает крайней правой ячейки буферного регистра. Поскольку неискаженная кодовая комбинация делится на g0(x) без остатка, то для определения выделенного синдрома достаточно разделить на g0(x) вектор ошибки с единицей в старшем разряде. Остаток, получающийся на n-м такте, и является искомым выделенным синдромом.
В зависимости от номера искаженного разряда после первых тактов будем получать различные остатки (опознаватели соответствующих векторов ошибок). Вследствие этого выделенный синдром будет появляться в регистре схемы деления через различное число последующих тактов, обеспечивая исправление искаженного символа.
В качестве схем деления в декодирующем устройстве могут быть использованы как схемы, определяющие остаток за n тактов (см. рис. 4.11), так и схемы, определяющие остаток за k тактов (рис. 4.13). При использовании схемы деления за k тактов векторам одиночных ошибок ξ(х) будут соответствовать другие остатки на n-м такте, являющиеся результатом деления на образующий многочлен кода векторов ξ(х)хт, а на ξ(x). Поэтому выделенные синдромы, а следовательно, и детекторы ошибок для указанных схем будут различны.
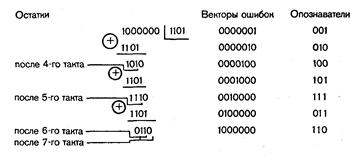
Пример 40. Рассмотрим процесс исправления единичной ошибки при использовании кода (7,4) с образующим многочленом g(x) = х3 + х2 + 1 и применении в декодирующем устройстве схем деления за n и k тактов.
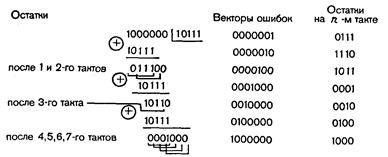
Определим опознаватели ошибок и выделенный синдром для случая использования схемы деления за n тактов:
Детектор ошибки, обеспечивающий формирование на выходе сигнала только в случае появления в схеме деления остатка 110, можно реализовать посредством двух логических элементов НЕ и одного логического элемента ИЛИ-НЕ.
На рис. 4.18 приведена схема соответствующего декодирующего устройства. В табл. 4.19 представлен процесс исправления ошибки для случая, когда кодовая комбинация 1001011 (см. табл. 4.18) поступила на вход декодирующего устройства с искаженным символом в 4-м разряде (1000011).
После n (в данном случае 7) тактов в схему деления II переписывается опознаватель ошибки 101.
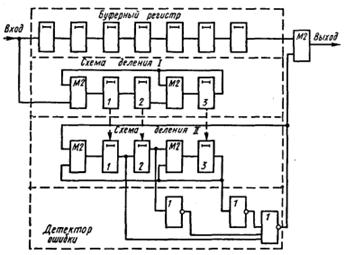
Рис. 4.18.
Таблица 4.19.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | ||
| Переписывается в схему деления II |
На каждом последующем такте на выходе буферного регистра появляется неискаженный символ корректируемой кодовой комбинации, а в схеме деления II новый остаток. Выделенный синдром появится в схеме деления на 10-м такте, когда искаженный символ займет крайнюю правую ячейку регистра. На следующем такте он попадет в корректирующий сумматор и будет там исправлен импульсом, поступающим с выхода детектора ошибки. Этот же импульс по цепи обратной связи приводит ячейки схемы деления II в нулевое состояние (корректирует выделенный синдром). При использовании схемы деления за k тактов соответствие между векторами ошибок и остатками на n-м такте иное.
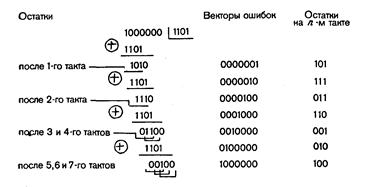
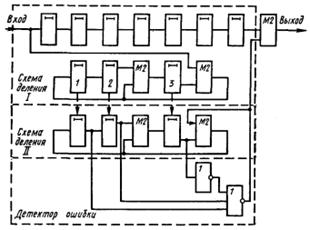
Рис. 4.19.
Таблица 4.20.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | ||
| Переписывается в схему деления II |
Детектор для выделенного синдрома 100 можно построить из одного логического элемента НЕ и одного элемента ИЛИ-НЕ.
На рис. 4.19 представлена схема декодирующего устройства для этого случая. Табл. 4.20 позволяет проследить по тактам процесс исправления ошибки в кодовой комбинации 1000011 (искажен символ в 4-м разряде).
Сравнение показывает, что использование в декодирующем устройстве схемы деления за k тактов предпочтительнее, так как выделенный синдром в этом случае при любом объеме кода содержит единицу в старшем и нули во всех остальных разрядах, что приводит к более простому детектору ошибки.
Пример 41. Рассмотрим более сложный случай исправления одиночных и двойных смежных ошибок. Для этой цели может использоваться циклический код (7,3) с образующим многочленом g(x) = (х + 1)(x3 + x2+1).
Ориентируясь на схему деления за k тактов, найдем выделенный синдром для двойных смежных ошибок:
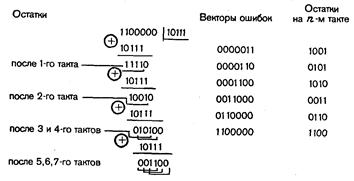
Для одиночных ошибок соответственно получим
Детектор ошибок в этом случае должен формировать сигнал коррекции при появлении каждого выделенного синдрома. Схема декодирующего устройства представлена на рис. 4.20.
Процесс исправления кодовой комбинации 1000010 с искаженными символами в 4-м и 5-м разрядах поясняется табл. 4.21.
На 9-м такте в схеме деления II появляется первый выделенный синдром 1100. На следующем такте на выходе аналогично обозначенного элемента ИЛИ-НЕ детектора ошибок формируется импульс коррекции, который исправляет 5-й разряд кодовой комбинации и одновременно по цепи обратной связи изменяет остаток в схеме деления II, приводя его в соответствие выделенному синдрому еще не исправленной одиночной ошибки в 4-м разряде (1000). На 11-м такте импульс коррекции формирует элемент ИЛИ-НЕ детектора ошибок, соответствующий указанному выделенному синдрому. Этим импульсом обеспечивается исправление 4-го разряда кодовой комбинации и получение нулевого остатка в схеме деления II.
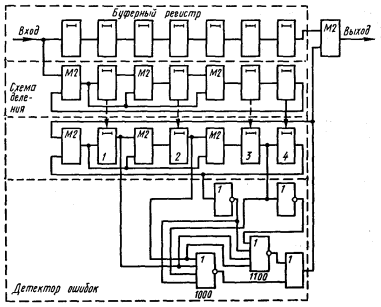
Рис. 4.20.
Таблица 4.21.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | |||
| Переписывается в схему деления II |
Список литературы
2. Дмитриев В.И. Прикладная теория информации. Учебник для студентов ВУЗов по специальности «Автоматизированные системы обработки информации и управления». – М.: Высшая школа, 1989 – 320 с.
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 676; Нарушение авторских прав?; Мы поможем в написании вашей работы!