КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Шкалирование
|
|
|
|
Исследования. Квантификация и
Информации, анализ результатов
Обработка первичной социологической
Обработка первичной социологической информации может проводиться вручную, с помощью средств малой механизации, с использованием компьютерной техники. Основные этапы обработки первичной информации следующие.
Первый этап. Разрабатываются логическая схема обработки и анализа получаемых данных. В ходе этого этапа устанавливаются формы документов для сбора информации, методы ее кодирования для ручной и машинной обработки, методы контроля данных и устранения ошибок. Определяются порядок и методы обработки данных, алгоритм расчетов, разрабатываются система анализа полученных в ходе обработки данных, основные направления анализа.
Второй этап. В случае обработки данных компьютерными методами осуществляется разработка математического обеспечения, выясняется, какие необходимы программы для обработки материалов исследования, иногда разрабатывается новое программное обеспечение.
Третий этап. Подготовка данных первичной социологической информации к обработке. Работа эта очень трудоемка. Так, при обработке данных анкетирования открытые вопросы анкет “закрывают” — классифицируют по определенным признакам, систематизируют и кодируют в соответствии с классификацией. Осуществляют проверку анкет на качество заполнения. Эта проверка включает три момента:
• на полноту заполнения (ответ может отсутствовать из-за нежелания респондента отвечать, непонимания им вопроса, небрежности в заполнении анкеты). При невозможности устранить ошибку отдельные вопросы или вся анкета изымается из обработки. Часто устанавливают “критерий полноты заполнения”, например, процент незаполненных вопросов анкеты, при превышении которого она будет изъята из обработки. В случае большого изъятия, ставящего под сомнение репрезентативность выборки, возможно возникновение необходимости дополнительного сбора исходных данных;
• на надежность (определяется отклонение от репрезентативной выборки, с помощью контрольных и фильтрующих вопросов проверяется качество информации, устраняются противоречивые ответы, умышленно недостоверные, отфильтровываются ответы или анкеты лиц, некомпетентных в исследуемых вопросах и т.д.);
• на технологичность (удобство обработки). Все ответы необходимо привести к виду, дающему возможность легко перенести информацию на машинный носитель для обработки. Из анкет убирают все пометки, которые можно неоднозначно трактовать, номера (шифры) выбранных ответов четко обводятся ручкой.
Далее подсчитывают все документы, входящие в обрабатываемый массив информации, каждому присваивается порядковый номер. Информация кодируется, т.е. категориям документа присваиваются условные обозначения (шифр, код). Если все вопросы анкеты закрытые, кодирование может осуществляться в ходе ее разработки. При наличии полузакрытых и открытых вопросов кодировать информацию возможно только после их “закрытия”. Закодированную информацию переносят на машинные носители, контролируют качество переноса и устраняют ошибки.
Четвертый этап. Обработка информации (расчет средних величин, установление корреляционных связей, составление группировок, таблиц, графиков и пр.)
Рассмотрим некоторые из перечисленных методов.
1. Простые вариацюнные рады. Пусть варьируемый признак (варианта) Xi — стаж. Объем анализируемой совокупности — 8 чел. Тогда частота проявления признака — пi, т.е. количество человек из данной совокупности с данным стажем. Вариационный ряд будет выглядеть так:
| Хi(стаж, лет) | ||||||
| ni (чел.) |
Помимо частоты распределения варьируемого признака, можно определить его частость (mi), т.е. долю частоты в общем объеме совокупности. Так, частость 6-й варианты (стаж 10 лет) составит:
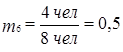 или 50%.
или 50%.
2. Интервальные вариационные ряды. Пример интервального вариационного ряда:
| Xi (стаж, лет) | до 1 года | Свыше 1 до 5 лет | Свыше 5 до 8 лет | Свыше 8 до 12 лет | и т. д. |
| mi (%) | 20,7 | 10,5 | 8,4 | 15,2 | и т.д. |
Здесь важно выбрать оптимальную величину интервала (более 20 группировочных интервалов делать не рекомендуется). Величина интервала определяется по формуле:
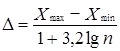 ,
,
где Xmax и Xmin — соответственно максимальное и минимальное значения варианты в исследуемой совокупности;
n — величина анализируемой совокупности;
lg—десятичный логарифм;
D — величина интервала.
Пример. Численность работников составляет 1000 чел., максимальный стаж работы на данном предприятии — 40 лет, минимальный — 1 год,
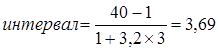 лет.
лет.
Тогда интервалы могут быть установлены следующим образом:
до 1 года;
1+3,69 = 4,69» 5 лет;
4,69 + 3,69 = 8,38» 8 лет;
8,38 + 3,69 = 12,07» 12 лет и т.д.
Могут применяться как равные, так и неравные интервалы.
3. Расчет средних величин. Средняя величина представляет собой абстрактную характеристику всей анализируемой совокупности.
а) Среднеарифметическая величина рассчитывается по формуле:
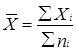 ,
,
где 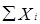 — сумма значений варьируемого признака;
— сумма значений варьируемого признака;
 — сумма всех членов совокупности.
— сумма всех членов совокупности.
Пример. Если взять за основу данные приведенного выше простого вариационного ряда, то среднеарифметический стаж составит:
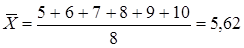 года.
года.
б) Среднеарифметическая взвешенная величина учитывает частоту лроявления признака, последняя выступает в качестве весов. Расчет яедется по формуле:
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 540; Нарушение авторских прав?; Мы поможем в написании вашей работы!