КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Команда завантаження
|
|
|
|
Прикладом команди завантаження є команда LW R6,112(R3). Виконується наступна мікродія:
Regs[IR n 15 ] = LMD.
Наведена мікрокоманда надсилає до комірки R6 регістрового файла вміст комірки пам’яті даних за адресою 112 + (R3), яке на попередніх фазах вже було вибране з пам’яті і тимчасово зберігалося в службовому регістрі LMD. На цьому опис мікродій керування роботою комп’ютера DLX завершено. В табл. 4.1. наведено приклади алгоритмів виконання команд в комп’ютері DLX.
Таблиця 4.1
Приклади алгоритмів виконання команд в комп’ютері DLX

Пояснимо на прикладі синтаксис запису алгоритмів виконання окремих машинних команд комп’ютера DLX (див. таблицю 4.1). Розглянемо запис:
Regs[RI19]16….31=(DМ[Regs[R8]]0)8 ## DМ [ Regs[R8]].
Запис означає наступне. Оновлюють лише 16 молодших (правих) бітів регістра Е.19. До них пересилається двобайтовий бінарний код, в якому молодший правий байт береться з пам’яті даних DМ за адресою, що є збіжною з вмістом регістра R8. Старший лівий байт утворюється восьмиразовим повторюванням нульового (старшого) розряду щойно згаданого правого байта. Парою символів ## позначено операцію конкатенації (зчеплення) двох байтів до двобайтового півслова. Наведеного таблицею 4.1 достатньо, аби синтезувати неподані алгоритми виконання інших команд комп’ютера DLХ.
4.2.5. Конвеєрна структура процесора комп’ютера з простою системою команд
4.2.5.1. Конвеєрний процесор
Конвеєрну структуру процесора комп’ютера з простою системою команд розглянемо на прикладі вище описаного комп’ютера DLХ. Вище виконання типової команди в комп’ютері DlХ було розділено на наступні фази:
1. IF - вибірка команди (за адресою, заданою лічильником команд, із пам’яті зчитується команда).
1. ID - декодування команди/вибірка операндів з регістрів.
3. ЕХ - виконання операції та обчислення ефективної адреси пам’яті.
4. МЕМ - звернення до пам’яті.
5. WB - запам’ятовування результату.
На рис. 4.6 представлена схема процесора, що виконує вказані вище фази виконання команд без перекриття. Щоб конвеєризувати цю схему, можна просто розбити виконання команд на вказані вище фази, відвівши для виконання кожної фази один такт синхронізації, і починати в кожному такті виконання нової команди. Природно, для зберігання проміжних результатів кожної фази необхідно використовувати конвеєрні регістри. На рис. 4.9 показана схема процесора з конвеєрними регістрами, які забезпечують передачу даних і керуючих кодів з одного ярусу конвеєра на наступний. Хоча загальний час виконання однієї команди в такому конвеєрі складатиме п’ять тактів, у кожному такті апаратура виконуватиме в суміщеному режимі п’ять різних команд.
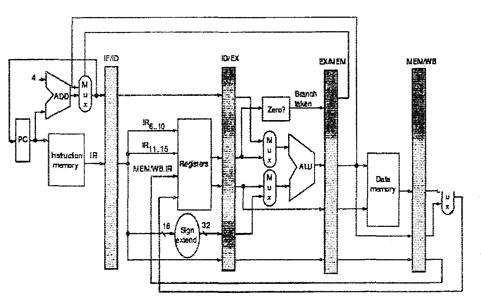
Рис. 4.9. Конвеєрна структура процесора комп’ютера DLX (з кеш пам’яттю даних та команд)
Конвеєрний процесор комп’ютера DLX структуровано наступними ярусами конвеєра: IF, ID, EX, MEM, WB. Апаратура кожного ярусу реалізує притаманні їй мікрооперації. Наприклад, на першому ярусі виконується вибирання команди з пам’яті команд ІМ за вмістом програмного лічильника PC, приріст (інкремент) на +4 (з врахуванням логічного байтового адресування пам’яті команд) поточної адреси за допомогою комбінаційного суматора ADD та занесення значення наступної адреси до поля NPC (Next PC), інтегрованого до конвеєрного регістра IF/ID. Мультиплексор Mux, що керується відповідним однобітним полем конвеєрного регістра ЕХ/МЕМ, визначає джерело запису до NPC - або наступна за чергою адреса, або цільова адреса умовного чи безумовного переходу. Важливо, що обов’язок змінювати природне адресування послідовності вибирання команд з пам’яті команд покладено на вміст команди, яка пройшла фазу конвеєра МЕМ.
Конвеєрні регістри виконують функцію збереження вмісту інтегрованих до них регістра команди IR, робочих регістрів А, В тощо. Конвеєрні регістри розташовано на межах ярусів. Вони мають назви, відповідні граничним ярусам, наприклад IF/ID. Тоді поле А конвеєрного регістра позначається як ЕХ/МЕМ.А.
До апаратури другого ярусу ID належать регістровий файл Regs, який містить множину програмно-доступних регістрів, та поширювач знаку Sign extend, що конвертує 16-бітові безпосередні знакові константи у 32-бітові стандартні операнда формату з фіксованою комою.
Апаратура третього ярусу містить комбінаційний ALU із мультиплексорами на кожному вході і схему (Zero?) визначення істинності чи хибності умови команди умовного переходу.
Призначення інших вузлів є зрозумілим з рисунка. Можна на додачу зауважити, що регістровий файл має два порти на читання і один на запис. Ця особливість є прямим наслідком запроваджених в комп’ютері DLX системи команд і конвеєрного принципу роботи. Регістровий файл Regs працює у кожній команді на двох ярусах конвеєра - ID (два читання) та WB (один запис). Означені фази двох різних команд можуть збігатися у часі. Аби запобігти колізії, потрібна реалізація одночасного читання та подвійного запису до цього файла. Крім того, необхідно запобігати запису даних до того ж самого регістра.
Роботу конвеєра можна умовно представити у вигляді часової діаграми суміщеного в часі виконання фаз команди, як це було показано раніше, або у вигляді зміщених в часі схем тракту даних комп’ютера DLX (рис. 4.10), де кожна схема зображає ту ж саму фазу команди. Тут ССі - тактові інтервали, IM - пам’ять команд, REG - регістровий файл, ALU - арифметико логічний пристрій, DM - пам’ять даних.
Час (в тактових інтервалах)
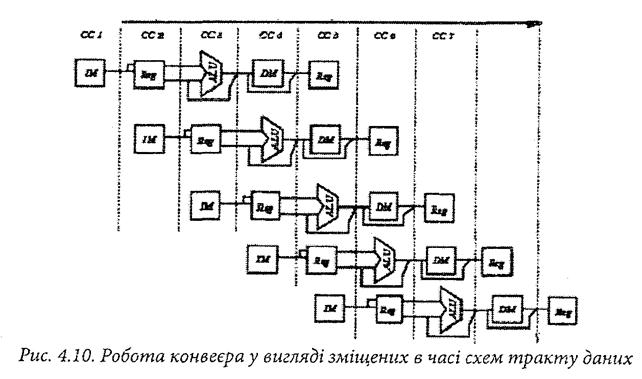
Цей рисунок добре відображає поєднання в часі виконання різних етапів команд. Тут перша опрацьована команда знаходиться вгорі, остання - знизу, СС - тактовий інтервал. Проте частіше для представлення роботи конвеєра використовуються часові діаграми (рис. 4.11), на яких зазвичай зображаються виконувані команди, номери тактів і етапи виконання команд.
| Номер Команди | Номер такту | ||||||||||||||
| І | IF | ID | EX | MEM | WB | ||||||||||
| і+1 | ІF | ID | ЕХ | МЕМ | WВ | ||||||||||
| і+2 | ІF | ID | ЕХ | МЕМ | WВ | ||||||||||
| і+3 | IF | ID | ЕХ | МЕМ | WВ | ||||||||||
| і+4 | ІF | ID | ЕХ | МЕМ | \¥В | ||||||||||
Рис. 4.11. Часова діаграма роботи конвеєра
З приведеної часової діаграми стає зрозуміло, для чого потрібні дві незалежні пам’яті - команд та даних. Це дозволить на тому ж самому тактовому інтервалі без колізії поєднувати виконання фаз ІF та МЕМ двох команд. При цьому, безперечно, зростають вимоги до швидкодії запам’ятовуючих пристроїв. Такі пристрої повинні відпрацьовувати звертання за один цикл (в нашому випадку за один тактовий імпульс), що обумовлює раціональність застосування відокремлених кеш пам’ятей команд та даних.
Конвеєризація збільшує пропускну спроможність процесора (кількість виконаних команд за одиницю часу), але вона не скорочує час виконання окремої команди. Насправді, вона навіть дещо збільшує час виконання кожної команди із-за затримок в конвеєрних регістрах. Проте збільшення пропускної спроможності означає, що програма виконуватиметься швидше порівняно зі скалярною (не конвеєрною) схемою.
Той факт, що час виконання кожної команди в конвеєрі не зменшується, накладає деякі обмеження на практичну довжину конвеєра. Окрім обмежень, пов’язаних із затримкою конвеєра, є також обмеження, що виникають в результаті незбалансованості затримки на кожному його ярусі та із-за накладних витрат на конвеєризацію. Частота синхронізації не може бути вищою, а, отже, такт синхронізації не може бути меншим, ніж час, необхідний для роботи найбільш повільного ярусу конвеєра. Накладні витрати на організацію конвеєра виникають через затримку сигналів у конвеєрних регістрах та із-за перекосів сигналів синхронізації. Конвеєрні регістри до тривалості такту додають час установки і затримку розповсюдження сигналів.
Як приклад розглянемо скалярний комп’ютер із п’ятьма етапами виконання операцій, які мають тривалість 50, 50, 60, 50 і 50 не відповідно (рис. 4.12).
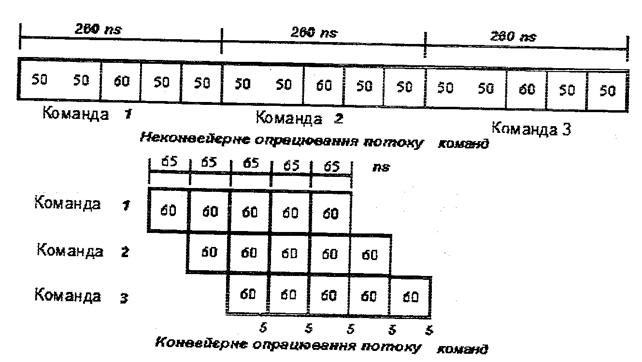
Рис. 4.12. Кoнвеєр потоку команд
Хай накладні витрати на організацію конвеєрної обробки складають 5 нc. Тоді середній час виконання команди в скалярному процесорі буде рівний 260 нc. Якщо ж використовується конвеєрна організація, тривалість такту буде рівна тривалості найповільнішої фази обробки плюс накладні витрати, тобто 65 нc. Цей час відповідає середньому часу виконання команди в конвеєрі. Таким чином, маємо чотирикратне прискорення, одержане в результаті конвеєризації.
Конвеєризація ефективна тільки тоді, коли завантаження конвеєра близьке до повного, а швидкість подачі нових команд і операндів відповідає максимальній продуктивності конвеєра. Якщо відбудеться затримка, то паралельно виконуватиметься менше операцій, і сумарна продуктивність знизиться. Такі затримки можуть відбуватися в результаті виникнення конфліктних ситуацій. Далі будуть розглянуті різні типи конфліктів, що виникають при виконанні команд в конвеєрі, і способи їх вирішення. Але спочатку розглянемо мікродії ярусів вже для варіанта конвеєрного процесора.
4.2.5.2. Мікродії ярусів конвеєрного процесора
Відразу зазначимо, що всі мікродії одного ярусу конвеєра мають бути сумісними в часі та виконуються паралельно в рамках однієї фази (як правило, за один тактовий інтервал). Мікродії, що реалізуються в кожному ярусі конвеєра комп’ютера DLХ, зведено в табл. 4.2.
Таблиця 4.2

Мікродїї ярусу IF.
Перша мікродія вибирає нову команду з пам’яті команд за адресою, що зберігається в PC, і записує її до поля IR (Instruction Register) конвеєрного регістра IF/ID. В той самий час друга мікродія змінює вміст поля NPC конвеєрного регістра і програмний лічильник за алгоритмом: якщо бітове поле cond (condition - умова) попередньої команди, яка пройшла фазу ЕХ, є одиницею (true), тоді порушується природна черговість і вміст IF/ID.NPC та PC отримує значення поля EX/MEM.NPC конвеєрного регістра ЕХ/МЕМ; інакше записується наступна адреса (РС+4) з врахуванням байтової логічної структури адреси пам’яті.
Мікродії ярусу ID.
Усі чотири мікродії є сумісними і виконуються в часі паралельно. Перша мікродія вибирає перший операнд з програмно керованого регістра регістрового файла до службового регістра А, що є інтегрованим до конвеєрного регістра ID/ЕХ. При цьому адреса програмно керованого регістра визначається вмістом розрядів 8.. 10 поля IR конвеєрного регістра IF/ID. Тут вибирається операнд. Такі ж за призначенням дії виконує друга мікрооперація, але з іншим джерелом і приймачем. Третя і четверта мікродії зберігають контекст команди, що знаходиться на поточній сходинці. Це необхідно для її коректного просування конвеєром. Четверта мікродія вибирає (та знаково розширює з 16 до 32-х бітів) до службового регістра Imm (immediate - безпосередній) операнд, який містився у розрядах. 16...31 поля IR конвеєрного регістра. Поточну фазу ID можна розширити у назві додатковим означенням Operand Fetch (вибирання операндів).
Мікродії ярусу ЕХ (команди арифметико-погічного пристрою).
Важливо відзначити, що на фазі ЕХ вперше від початку виконання команди має бути визначеним її тип. Перша мікродія зберігає вміст регістра команди. Четверта мікродія забороняє командам ALU впливати на послідовність вибирання команд з пам’яті. Друга і третя мікродії утворюють альтернативу (або). Кожна з них визначає пару операндів для операції ор і при цьому записує результат ор до службового (програмно-некерованого) вихідного регістра ALU під назвою ALUoutput.
Мікродії ярусу ЕХ (команди load/store).
Перша мікродія зберігає контекст регістра команди, друга вираховує виконавчу (ефективну) адресу пам’яті даних на основі бази (Immediate - безпосередній операнд), третя зберігає вміст службового, програмно-некерованого регістра В, четверта забороняє поточній команді змінювати природний порядок адресування команд.
Мікродії ярусу ЕХ (команда branch).
Перша мікродія вираховує цільову адресу можливого переходу та зберігає її у робочому (некерованому програмістом) вихідному регістрі ALUoutput, а конкретно - у полі ALUoutput конвеєрного регістра ЕХ/МЕМ. Друга мікродія вираховує істинне або хибне значення логічної умови, що визначається порівнянням в деякому, тобто ор розумінні, службового регістра А, визначеного за вмістом на фазі ID, з нулем (дорівнює нулю, не дорівнює нулю, тощо). Логічне значення умови записується до поля cond конвеєрного регістра ЕХ/МЕМ з метою дозволу зміни природного порядку вибирання команд програми, коли cond=l. Контексти не зберігаються, що свідчить про неформальне завершення опрацювання цієї команди в конвеєрі.
Мікродії ярусу MEM (команди арифметико логічного пристрою).
Активних мікродій обробки інформації немає, що свідчить про транзитний характер опрацювання команди на цій сходинці. Обидві мікродії лише зберігають для подальшого користування вміст регістра команд і вихідного регістра ALU.
Мікродії ярусу МЕМ (команди load/store).
Перша мікродія виконує транзитне пересилання вмісту коду операції з відповідного поля вхідного конвеєрного регістра до відповідного поля вихідного конвеєрного регістра ярусу. Це свідчить про те, що виконання команди (лише - завантаження) має продовжуватися в наступному ярусі конвеєра. При завантаженні виконується друга мікродія, а при збереженні - третя. Виконавча (ефективна) адреса пам’яті даних визначається вмістом службового вихідного регістра ALU. При завантаженні вміст комірки пам’яті даних зберігається в проміжному регістрі LMD (Load Memory Data), а при збереженні вміст службового регістра В записується до комірки пам’яті даних
Важливо, що дана мікропрограма ігнорує існування відомого парадоксу пам’яті, що коректно тільки за умови використання кеш пам’яті даних та системи переривань у випадку «невлучення до кеш» («покарання» за невлучення - це певна кількістю додаткових тактових інтервалів, аби погодити швидкодію процесора і пам’яті даних за рахунок пригальмовування операцій в скалярному процесорі).
Мікродії ярусу WB (команди арифметико логічного пристрою).
Завжди виконується лише одна мікрооперація з двох зазначених. В кожному випадку результат обробки операндів в ALU з поля конвеєрного регістра MEM/WB.ALUoutput записується до регістра регістрового файла процесора. Використання двох мікрокоманд замість однієї пояснюється тим, що у форматі команд load DLX повного дотримання правила «фіксоване розташування полів» немає. За рахунок цього адреса призначення у форматі команди рухається: може визначатися розрядами 16...20 або розрядами 11...15 команди. Так чи інакше, але вказана «рухомість» адреси поля призначення ускладнює апаратний пристрій керування і може зменшити його швидкодію
Мікродії ярусу WB (команда load).
Зазначимо, що команда store (збереження) на цьому ярусі виконання не потребує мікродій. Тут завершується виконання лише команди завантаження операнда з комірки пам’яті даних до регістра регістрового файла процесора
Операнд зберігається у полі LMD вхідного конвеєрного регістра МЕМ/WB, а адреса комірки (регістра) регістрового файла міститься у полі MEM/WB.IR 11...15. Важливо, що регістровий файл повинен реалізувати два порти, а саме, два порти на читання та один порт на запис. При цьому, якщо дві адреси на читання постачає конвеєрний регістр (IF/ID), то адресу на запис і дані постачає щойно розглянутий конвеєрний регістр (MEM/WB).
4.3. Суперконвеєрні процесори
 Можлива така організація виконання деякої послідовності команд в процесорі, коли всі однойменні фази виконання цих команди послідовно, тобто спочатку проводиться вибірка всіх команд, далі їх декодування і т. д., як це показано на рис. 4.13. для послідовності із двох команд
Можлива така організація виконання деякої послідовності команд в процесорі, коли всі однойменні фази виконання цих команди послідовно, тобто спочатку проводиться вибірка всіх команд, далі їх декодування і т. д., як це показано на рис. 4.13. для послідовності із двох команд
| IF1 | IF2 | ID1 | ID2 | ЕХ1 | ЕХ2 | МЕ1 | МЕ2 | WB1 | WB2 | IF1 | IF2 | ID1 | ID2 | ЕХ1 | ЕХ2 | MЕ1 |MЕ2 | WB1 | WB2 |
Рис. 4.13. Послідовне виконання однойменних фаз двох команд
Такий підхід не прискорює роботу процесора, але при конвеєрному опрацюванні команд може виявитися доцільним, оскільки в ярусах конвеєра (рис. 4.14) знаходяться результати виконання декількох фаз різних команд, що при наявності конфліктів дозволяє ефективніше їх вирішувати, аніж у звичайному конвеєрі команд. Процесор з конвеєром команд, в якому послідовно виконуються декілька фаз над різними командами, називається суперконвеєрним.
| IF1 | !F2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||
| IF1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||
| IF1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||
| IF1 | IF2 | ID1 | Ю2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||
| IF1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 |
Рис. 4.14. Діаграма виконання команди в суперконвеєрному процесорі при послідовному виконанні фаз двох команд
Як видно з приведеної на рис. 4.14 діаграми, при послідовному виконанні фаз двох команд в одному такті роботи конвеєра кожна з фаз повинна виконуватись двічі. Коли послідовно виконується k фаз команд, то в кожному такті кожна з фаз має виконуватися k раз. Це говорить про те, що внутрішня частота роботи ярусів конвеєра суперконвеєрного процесора є в k разів вищою їх зовнішньої частоти, з якою відбувається обмін інформацією між ярусами.
Потрібно відзначити, що для організації суперконвеєрного опрацювання команд необхідне деяке додаткове обладнання порівняно з конвеєрним. Це, зокрема, регістри для зберігання проміжних результатів послідовно виконуваних фаз різних команд.
4.4. Суперскалярні процесори
Вище була розглянута конвеєрна структура процесора, коли засоби виконання ярусів потокового графа алгоритму розділяються конвеєрними регістрами. Щоб підвищити продуктивність конвеєрного процесора потрібно далі спрощувати операції його ярусів та поглиблювати глибину конвеєра. Це і робиться в сучасних процесорах, в яких глибина конвеєра досягає двадцяти і більше ярусів. Наприклад, процесор комп’ютера UltraSPARC III має 10 ярусів конвеєра, а процесор комп’ютера Pentium IV - 20 ярусів конвеєра. Однак процес спрощення операцій ярусів конвеєра має межу, коли операції не піддаються поділу. Наприклад, фаза вибірки команди з пам’яті не може бути поділеною на простіші фази. Тоді для підвищення продуктивності процесора необхідно використовувати паралельне включення декількох конвеєрів команд. Такі процесори з декількома конвеєрами команд дозволяють одночасно виконувати кілька скалярних команд, а тому дістали назву суперскалярних.
Першу суперскалярну архітектуру розробив Джон Коук (John Cocke, IBM, 1987 рік), що отримала назву America. Він і запропонував термін “суперскаляр”. Вже потім модифікований варіант архітектури America під назвою POWER-1 (Performance Optimization With Enhanced RISC) впровадили до серійних систем RISC System/6000 фірми IBM.
Нарешті, підмножину архітектури POWER-1 реалізовано в процесорах Power PC, які є основою комп’ютерів Apple Macintosh. Іншими прикладами суперскалярних процесорів є процесори систем UltraSparc фірми Sun та Alpha фірми DEC.
Структура суперскалярного процесора та його зв’язки з кеш пам’яттю даних і команд, показані на рис. 4.15.
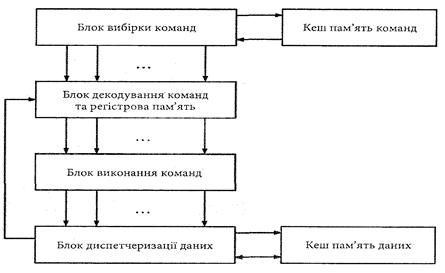
Рис. 4.15. Структура суперскалярного процесора
Тут одночасно вибирається та декодується декілька команд, а блок виконання команд включає кілька функціональних блоків. Для забезпечення одночасного читання та запису кількох операндів кеш пам’ять будується за модульним принципом.
Зрозуміло, що підвищення продуктивності такого процесора досягається шляхом його конвеєризації. Діаграма виконання команд в суперскалярному процесорі, який має два конвеєри команд, показана на рис. 4.16а.
| IF | ID | EX | ME | WB | 1F1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||||
| IF | ID | EX | ME | WB | IF1 | iF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||||
| IF | ID | EX | ME | WB | IF1 | IF? | in? | FX1 | FX? | MF1 | ME2 | WB1 | WB2 | ||||||
| IF | ID | EX | ME | WB | IF1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||||
| IF | ID | EX | ME | WB | IF1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||||
| IF | ID | EX | ME | WB | IF1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||||
| IF | ID | EX | ME | WB | IF1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB2 | |||||
| IF | ID | EX | ME | WB | IF1 | IF2 | ID1 | ID2 | EX1 | EX2 | ME1 | ME2 | WB1 | WB^ |
а) b)
Рис. 4.16. Діаграма виконання команд в суперскалярному процесорі з двома конвеєрами команд, коли в одному такті виконується одна (а) та дві (Ь) фази команди
Можливе суміщення суперскалярного та суперконвеєрного опрацювання команд, як це показано на рис. 4.16 b.
4.5. Процесор векторного комп’ютера
Вище були розглянуті скалярні та суперскалярні процесори, в яких операції виконуються над скалярними даними. Однак існує значна кількість завдань, коли опрацюванню за одними процедурами підлягають великі масиви (вектори) даних. У цьому випадку виглядає доцільним розгляд можливості модифікації комп’ютера під виконання цього класу завдань. До цих пір така модифікація здійснювалась в потужних комп’ютерах, але на даний час вона почала поширюватись на всі типи комп’ютерів. Відповідно комп’ютери, орієнтовані на опрацювання векторів даних, дістали назву векторних.
Різницю між виконанням скалярної та векторної операції наглядно відображає рис. 4.17, з якого видно, що скалярна операція передбачає виконання додавання над двома даними, тоді як векторна - над двома векторами даних.
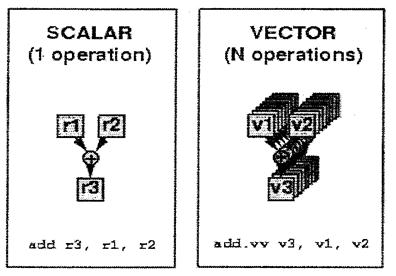
Рис. 4.17. Виконання скалярної та векторної операцій додавання
Аби зрозуміти стиль програмування векторних комп’ютерів, наведемо приклад програми із скалярними і векторними кодами. Запишемо програму обчислення виразу У= а * X + У, де У, X - вектори, а а - скаляр. Нехай вектори мають довжину по 64 елементи. Векторна програма має вигляд:
| LD | F0, a | ; load scalar a |
| LV | VI, Rx | ; load vector X |
| MULTS | V2, F0, VI | ; vector-scalar mult. |
| LV | V3, Ry | ; load vector Y |
| ADDV | V4, V2, V3 | ; add |
| SV | Ry, V4 | ; store vector |
Відповідна скалярна програма має вигляд:
| LD | F0,a | ||
| Loop: | ADDI load | R4,Rx,#512 | ; last address to |
| LD | F2,0(Rx) | ; load X(l) | |
| MULTD F2,F0,F2 | ; a*X(l) | ||
| LD | F4,0(Ry) | ; load Y(l) | |
| ADDD | F4,F2,F4 | ; a*X(l)+Y(l) | |
| SD | F4, 0(Ry) | ; store into Y (1) | |
| ADDI | Rx,Rx,#8 | ; increment index | |
| ADDI | Ry,Ry,#8 | ; increment index | |
| SUB | R20,R4,Rx | ; compute bound | |
| BNZ | R20, loop | ; check if done |
У скалярній програмі курсивом позначено залежності, яких немає у векторному варіанті програми. Обидва варіанти програми можна порівняти за наступними кількісними характеристиками:
1. За кількістю операцій: 578(2+9*64) проти 321(1+5*64); кількість операцій у векторній програмі зменшено в 1,8 разу.
2. За кількістю команд: 578(2+9*64) проти 6-ти команд у векторній програмі; перевага в 96 разів.
В таблиці 4.3 наведені характеристики кількох промислових векторних комп’ютерів, з якої видно доцільність їх створення з огляду на досягнуту продуктивність.
Таблиця 4.3
| Тип машини | Рік випуску | Частота, MHz | Кількість регістрів | Кількість елементів | Кількість пристроїв float point | Кількість пристроїв load/store | Продуктив ність (MFLOPS) |
| Cray-1 | |||||||
| Cray XMP | 2L, IS | ||||||
| Cray YMP | 2L, IS | ||||||
| Cray C-90 | 15238(16) | ||||||
| Cray T-90 | 57600(32) | ||||||
| Conv. C-l | 20(1) | ||||||
| Conv. C-4 | 3240(4) | ||||||
| Fuj. VP200 | 8-256 | 32-1024 | 533(1) | ||||
| Fuj. VP300 | 8-256 | 32-1024 | N/A | ||||
| NEC SX/2 | 8 + 8К | 256 + var | 1300(1) | ||||
| NEC SX/3 | 8 + 8К | 256 + var | 25600(4) |
Таким чином, процесори векторних комп’ютерів виконують команди над векторами даних. Структура цих процесорів за складом та зв’язками повторює вже розглянуті вище структури процесорів, тобто це можуть бути процесори векторних комп’ютерів із складною та простою системою команд, конвеєрні та суперконвеєрні, а також процесори супервекторних комп’ютерів, коли в процесорі є декілька конвеєрів команд. Основна їх відмінність - забезпечення одночасного виконання однієї команди над вектором даних. Це, зокрема, дозволяє будувати їх блоки виконання команд за конвеєрним принципом і при цьому позбутися конфліктів, які суттєво гальмують роботу конвеєра чи ускладнюють його структуру.
Для вияснення базових принципів побудови процесорів векторних комп’ютерів розглянемо структуру та систему команд процесора векторного варіанта комп’ютера DLХ, а саме комп’ютера DlХV. До складу процесора, структура якого приведена на рис. 4.18, входять пристрій векторного читання запису, регістрові файли з векторними та скалярними регістрами, а також операційний пристрій з набором конвеєрних операційних пристроїв додавання, множення та ділення з рухомою комою та виконання арифметичних і логічних операцій над цілими числами.
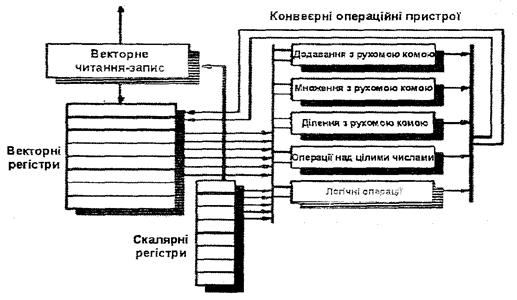
Рис. 4.18. Структура процесора комп’ютера DlХV
Цей комп’ютер має векторні команди, які наведено в табл. 4.4.
| Команда | Операнди | Операція | Коментар |
| ADDV | VI, V2.V3 | V1=V2+V3 | VECTOR+VECTOR |
| ADDSV | VI, F0.V2 | V1=F0+V2 | SCALAR+VECTOR |
| MULTV | VI, V2,V3 | Vl=V2xV3 | VECTORxVECTOR |
| MULSV | VI, F0.V2 | V1=F0XV2 | SCALAR x VECTOR |
| LV | VI, R1 | Vl=M[Rl..Rl+63] | LOAD, STRIDE=1 |
| LVWS | VI, R1,R2 | V1=[R1..R1+63*R2] | LOAD, STRIDE=R2 |
| LVI | VI, R1,V2 | V1=[R1+V2i,i=0..63 | indirect (“gather”) |
| CeqV | VM,V1,V2 | VMASKi=(Vl I=V2I) | comp. Set mask |
| MOV | VLR,R1 | Vec. Len. Reg = R1 | set vector length |
| MOV | VM, R1 | Vec. Mask=Rl | set vector mask |
Приведений процесор є процесором комп’ютера з простою системою команд. До цього типу належать усі векторні суперкомп’ютери: Cray, Convex, Fujitsu, Hitachi, NEC.
Хоча потрібно зауважити, що існують і векторні комп’ютери з архітектурою «пам’ять- пам’ять», коли всі векторні операції є операціями типу пам’ять-пам’ять наприклад, СDС-6600.
Подібно до приведеного на рис. 4.18, процесори векторних комп’ютерів містять наступні основні компоненти
1. Векторні регістри; це регістрий файл фіксованої ємності що вміщує вектор даних. Цей файл має як мінімум 2 порти на читання і один порт на запис та зазвичай включає 8-32 векторних регістри, кожний з яких є 64-128-розрядним
3. Конвеєрні операційні пристрої. Зазвичай застосовують 4-8 операційних пристроїв, а саме: додавання, множення і ділення з фіксованою та рухомою комою, зсуву тощо
3. Векторний вузол читання-запису, також конвеєрний, який опрацьовує вектори даних. Водночас застосовують декілька таких вузлів
4. Скалярні регістри, які містять один скаляр з рухомою комою або адресу
5. Багатошинні магістралі або комутаційні мережі, які з’єднують між собою всі зазначені компоненти, аби прискорити роботу процесора в цілому
Перші векторні комп’ютери БТАІІ-ІОО фірми СDС та АSС фірми ТІ були створені в 1972 році. Це були векторні комп’ютери з архітектурою типу пам’ять-пам’ять
Значний внесок в теорію побудови векторних комп’ютерів зробив видатний американський конструктор векторних суперкомп’ютерів Сеймур Крей. На рис. 4.19 зображено його перший векторний суперкомп’ютер Сгау-1 та векторні суперкомп’ютери Сгау-2 і Сгау-УМР.

Рис. 4.19. Векторні суперкомп'ютери Сrау-1, Сrау-2 і Cray-YMP
Комп’ютер CRAY-1 був створений в 1976 році і мав архітектуру типу «регістр-регістр», тому він був найшвидшим серед векторних та скалярних комп’ютерів свого часу. В 1981 році на ринку з’явився значно потужніший векторний комп’ютер CYBER-205 фірми CDC з тією ж базовою архітектурою, що і STAR-100, але більшою кількістю векторних функціональних блоків. Це були векторні комп’ютери з архітектурою типу “пам’ять- пам’ять”. В 1983 році фірма Cray Research поставила на ринок векторний суперкомп’ютер CRAY X-MR а через кілька років - CRAY-2, який мав вищу тактову частоту та іще більший рівень конвеєризації. В 1988 році фірма Cray Research створила значно швидший, ніж Х-МР суперкомп’ютер CRAY Y-MP, котрий мав 8 конвеєрних процесорів, кожний з яких працював з тактом 6 нc.
Одночасно потужні векторні суперкомп’ютери почали створюватись і в інших державах. Зокрема, в середині 80-х років в Японії були створені суперкомп’ютери Fujitsu VP100 і VP200, за ними Hitachi S810 і NEC SX/2, які за технічними характеристиками не поступалися комп’ютерам фірми Cray Research
Протягом наступних 20 років векторні комп’ютери мали швидкий розвиток і з екзотичних перетворились в широковживаний клас потужних комп’ютерів.
4.6. Класифікація архітектури комп'ютера за рівнем суміщення опрацювання команд та даних
Виходячи з вищенаведеного розгляду різних принципів побудови процесорів, можна зробити наступну класифікацію архітектури комп’ютера за рівнем суміщення в них опрацювання команд та даних
1. за відсутністю та наявністю конвеєра команд: комп’ютери без конвеєра команд та комп’ютери з конвеєром команд
2. за відсутністю та наявністю конвеєра даних: комп’ютери без конвеєра даних та комп’ютери з конвеєром даних
3. за кількістю послідовно виконуваних фаз команд в конвеєрі: конвеєрні та супер- конвеєрні
4. за кількістю одночасно опрацьовуваних даних за однією командою: скалярні та векторні
5. за кількістю одночасно опрацьовуваних скалярних команд: скалярні та супер- скалярні
6. за кількістю одночасно опрацьовуваних векторних команд: векторні та супер- векторні
Проведений вище аналіз названих архітектур дозволяє зробити висновок про те, що для побудови високопродуктивних комп’ютерів потрібно, щоб вони мали суперконве- єрну суперскалярну та супервекторну архітектуру.
4.7. Короткий зміст розділу
Розглянуто місце процесора в комп’ютері, його функції та склад. Приведена одно- шинна структура процесора комп’ютера із складною системою команд та розглянуто виконання на ній основних операцій процесора: вибірки слова із пам’яті, запам’ятовування слова в пам’яті, обміну між регістрами, виконання арифметичних і логічних операцій. Проведено порівняння одношинної з багатошинною структурою процесора
Виділено особливості побудови процесора комп’ютера із складною системою команд та сформовано вимоги до процесора комп’ютера з простою системою команд. Описані базові принципи побудови процесора комп’ютера з простою системою команд, а також взаємодія процесора з основною пам’яттю в комп’ютері з простою системою команд
Розглянуто фази виконання команд в процесорі комп’ютера з простою системою команд: вибирання та декодування команди, виконання та формування ефективної адреси, звернення до пам’яті/завершення умовного переходу, зворотного запису. Описана конвеєрна структура процесора з простою системою команд на прикладі процесора комп’ютера DLX. Розглянуто принципи побудови суперконвеєрним та суперскалярних процесорів, а також процесорів векторних комп’ютерів. Виходячи з вищенаведеного розгляду різних принципів побудови процесорів, зроблено класифікацію архітектури комп’ютера за рівнем суміщення в ньому опрацювання команд та даних.
4.2. Література для подальшого читання
Питання побудови процесорів комп’ютерів з складною системою команд детально розглянуті в багатьох підручниках та наукових працях, зокрема [1-4, 7, 8]. Вимоги до процесора комп’ютера з простою системою команд та базові принципи його побудови детально описані в роботах [5, 6]. Там же, а також в роботах [7-8] запропоновано принципи побудови процесора комп’ютера DLX і процесора векторних комп’ютерів, а в роботах [9-10] розглянуті принципи побудови суперконвеєрним та суперскалярних процесорів.
4.3. Література до розділу 4
1. Каган Б.М. Электронные вычислительные машины и системы. - М.: Энергия, 1979. - 528 с.
2. Каган Б. М., Каневский М. М. Цифровые вычислительные машины и системы. - М.: Энергия, 1974. - 680 с.
3. Tanenbaum, A. Structured Computer Organization, 4,n ed. Upper Saddle River, NJ: Prentice Hall, 1999.
4. Stallings, W. Computer Organization ami Architecture, 5th ed., New York, NY: Macmillan Publishing Company, 2000.
5. D. Patterson, J. Hennessy. Computer Architecture. A Quantitative Approach. Morgan Kaufmann Publishers, Inc. 1996.
6. Patterson, D. A., & Hennessy, J. L. Computer Organization and Design, The Hardware/Software Interface, 2nd ed., San Mateo, CA: Morgan Kaufmann, 1997.
7. AGERWALA, T. AND J. COCKE [1987]. “High performance reduced instruction set processors”, IBM Tech. Rep. (March).
8. Bakoglu, H. B., G. E Grohoski, L. E. Thatcher, J. A. Kahie, С R. Moore, D. P. Tuttle, W. E. Maule, W. R. Hardell, D. A. Hicks, M. Nguyen phu, R. K. Montoye, W. T. Glover, and S. Dhawan [1989]. «IBM second-generation RISC processor organization,» Proc. Int’l Conf. on Computer Design, IEEE (October), Rye, N.Y., 138-142.
9. Johnson, M. [1990]. Superscalar Microprocessor Design, Prentice Hall, Englewood Cliffs, N.J.
10. JOUPPI, N. P. AND D. W. WALL [1989]. “Available instruction-level parallelism for superscalar and superpipelined processors”, Proc. Third Conf. on Architectural Support for Programming Languages and Operating Systems, IEEE/ACM (April), Boston, 272-282.
4.10. Питання до розділу 4
1. Місце процесора в комп’ютері та його функції.
2. Що таке командний цикл?
3. Дві основні фази командного циклу.
4. Основні вузли процесора.
5. Одношинна структура процесора комп’ютера із складною системою команд і його зв’язки з іншими пристроями комп’ютера.
6. Виконання процесором операції “Вибірка слова з пам’яті”.
7. Виконання процесором операції “Запам’ятовування слова в пам’яті”.
8. Виконання процесором операції обміну між регістрами.
9. Виконання процесором арифметичних і логічних операцій.
10. Порівняння одношинної та багатошинної структур процесора комп’ютера із складною системою команд.
11. Чому в процесорі комп’ютера із складною системою команд команда виконується за багато тактів?
11. Чому в процесорі комп’ютера із складною системою команд потрібна складна система розпізнавання команди?
13. Чому в процесорі комп’ютера із складною системою команд організація конвеєризації виконання команд складніша, ніж у процесорі комп’ютера з простою системою команд?
14. Основні вимоги до процесора комп’ютера з простою системою команд.
15. Сформуйте правила вибору системи команд комп’ютера з простою системою команд.
16. Чому в системі команд комп’ютера з простою системою команд відносно небагато операцій та способів адресації?
17. Чому в комп’ютері з простою системою команд команди обробки даних мають реалізуватися лише у формі “регістр-регістр”?
18. Чому в комп’ютері з простою системою команд обміни з основною пам’яттю виконуються лише за допомогою команд завантаження/запису?
19. Чому в процесорі комп’ютера з простою системою команд дешифрування команд із спрощеними форматами має виконуватися лише апаратно?
20. Що є основою проектування структури процесора комп’ютера з простою системою команд?
21. Як будується процесор для того, щоб команда виконувалася за один такт?
22. Поясніть принципи роботи процесора комп’ютера DLX.
23. Опишіть фази виконання команди в процесорі комп’ютера DLX.
24. Поясніть роботу конвеєрного процесора комп’ютера DLX.
25. Проаналізуйте та поясніть мікродії, що виконуються на сходинці IF конвеєра комп’ютера DLX.
26. Проаналізуйте та поясніть мікродії, що виконуються на сходинці ID конвеєра комп’ютера DLX.
27. Проаналізуйте та поясніть мікродії, що виконуються на сходинці ЕХ конвеєра комп’ютера DLX при виконанні команди АЛП.
28. Проаналізуйте та поясніть мікродії, що виконуються на сходинці ЕХ конвеєра комп’ютера DLX при виконанні команд завантаження і збереження (load/store).
29. Проаналізуйте та поясніть мікродії, що виконуються на сходинці ЕХ конвеєра комп’ютера DLX при виконанні команди умовного переходу (branch).
30. Проаналізуйте та поясніть мікродії, що виконуються на сходинці МЕМ конвеєра комп’ютера DLX при виконанні команд АЛП.
31. Проаналізуйте тапоясніть мікродії, що виконуються на сходинці МЕМ конвеєра комп’ютера DLX при виконанні команд завантаження або збереження.
32. Проаналізуйте та поясніть мікродії, що виконуються на сходинці WB конвеєра комп’ютера DLX при виконанні команд АЛП.
33. Проаналізуйте та поясніть мікродії, що виконуються на сходинці WB конвеєра комп’ютера DLX при виконанні команди load.
34. Основна ідея суперконвеєрних процесорів.
35. Суперскалярні процесори - структура та принцип роботи.
36. Процесори векторних комп’ютерів - структура та принцип роботи.
37. Наведіть класифікацію архітектури комп’ютера за рівнем суміщення в ньому опрацювання команд та даних.
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 2536; Нарушение авторских прав?; Мы поможем в написании вашей работы!