КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Поиск в лабиринте
|
|
|
|
Словарь в виде упорядоченного дерева
Nospy
Nodebug
Целевое утверждение nodebug вызывает устранение всех контрольных точек, установленных на текущий момент.
Подобно spy, nospy является префиксным оператором. Предикат nospy является более селективным, чем nodebug, так как вы можете точно указать, какие контрольные точки должны быть удалены. Это достигается путем указания аргумента, задаваемого в точности в такой же форме, как и для предиката spy. Так, целевое утверждение nospy[обр/2, присоединить/3] приведет к тому, что будут удалены все контрольные точки с предиката обр с двумя аргументами и с присоединить с тремя аргументами.
ГЛАВА 7. ЕЩЕ НЕСКОЛЬКО ПРИМЕРОВ ПРОГРАММ
В каждом разделе этой главы рассматривается некоторое конкретное применение Пролога. Мы советуем вам прочитать все разделы. Не огорчайтесь, если вы не поймете назначение какой-либо программы потому, что незнакомы с данной конкретной областью применения. Например, оценить значение символьного дифференцирования смогут лишь читатели, уже знакомые с дифференциальным исчислением. Тем не менее прочтите этот раздел, потому что программа нахождения символьных производных показывает, как установление соответствия между образцами используется при преобразовании структур одного вида (арифметическое выражение) в структуры другого вида. Самое главное – добиться понимания техники программирования на Прологе, находящейся в распоряжении программиста, независимо от конкретной прикладной задачи.
Мы надеемся, что набор задач достаточен, чтобы удовлетворить вкусам большинства читателей. Естественно, что все выбранные задачи относятся к таким областям, которые хорошо укладываются в те способы представления явлений реального мира, которые предлагает Пролог. Например, здесь отсутствует задача расчета потока тепла через трубу прямоугольного сечения. Правда, такие задачи тоже можно решать с помощью Пролога, однако выразительность и силу Пролога невыгодно демонстрировать на задачах, которые сводятся лишь к многократным повторениям вычислений над массивом чисел. Хотелось бы также рассмотреть и большие Пролог-программы, вроде тех, что используются в исследованиях по искусственному интеллекту для распознавания фраз естественного языка. К сожалению, цель такой книги как эта, не позволяет рассматривать программы, размеры которых превышают страницу текста и которые могут быть предложены лишь специально подготовленному читателю.
Предположим, что мы хотим установить отношения между элементами информации с тем, чтобы использовать их, когда потребуется. Например, толковый словарь ставит в соответствие слову его определение, а словарь иностранного языка ставит в соответствие слову на одном языке слово на другом языке. Мы уже познакомились с одним способом составления словаря: с помощью задания фактов. Если нам нужно составить таблицу выигрышей на скачках, проводившихся на Британских островах в течение 1938 г., то мы можем просто определить факты вида выигрыши(Х, Y), где X - кличка лошади, a Y – количество гиней (денежных единиц), выигранных этой лошадью. Следующая база данных может рассматриваться как часть этой таблицы:
Выигрыши(abaris,582).
Выигрыши(careful,17).
Выигрыши(jingling_silvee,300).
Bыигрыши(majola,356).
Если мы хотим узнать, какую сумму выиграла лошадь по кличке maloja, нам нужно просто правильно построить вопрос и Пролог даст нам ответ:
?- Bыигрыши(maloja, X).
X=356
Напомним, что Пролог просматривает базу данных сверху вниз. Это значит, что если база данных нашего словаря упорядочена в алфавитном порядке, как в приведенном выше примере, то на поиск суммы выигрыша для ablaze Пролог затратит меньше времени, чем на поиск суммы выигрыша для zoltan. Однако хотя Пролог способен просмотреть свою базу данных гораздо быстрее, чем вы сможете просмотреть напечатанную таблицу, неразумно просматривать таблицу с начала до конца, если известно, что данные искомой лошади расположены в самом конце. Точно так же, хотя в Прологе имеются специальные средства быстрого просмотра базы данных, он не всегда проходит так быстро, как хотелось бы. В зависимости от размеров таблицы и от того, сколько информации хранится о каждой лошади, Прологу может потребоваться на просмотр таблицы неприемлемо большое время.
По этим и другим причинам специалисты по информатике потратили немало сил на поиски хороших способов организации хранения таких данных, как таблицы и словари. Сам Пролог использует некоторые из этих методов внутри себя при организации хранения своих собственных фактов и правил, но иногда их полезно использовать и в наших программах. Мы рассмотрим один такой метод организации словаря, который называется методом упорядоченного дерева. Метод упорядоченного дерева является одновременно и эффективным способом использования словаря и средством демонстрации того, насколько полезны списки структур.
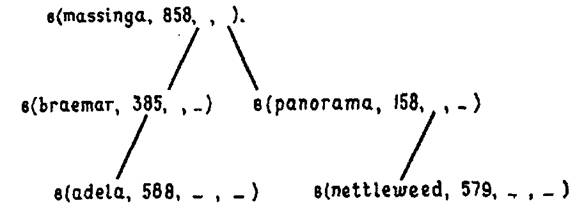
Рис. 7.1.
Упорядоченное дерево состоит из некоторого числа структур, называемых узлами, причем каждому входу словаря соответствует один узел. Каждый узел содержит четыре компоненты. Сюда входят два связанных с узлом элемента данных, как в предикате выигрыши в вышеприведенном примере. Один из этих элементов называется ключом, его имя определяет место в словаре (кличка лошади в нашем примере). Другой элемент используется для хранения какой-либо другой информации о данном объекте (сумма выигрыша в нашем примере). Кроме того, каждый узел содержит ссылку (наподобие ссылки на хвост списка) на узел со значением ключа, которое лексикографически (по алфавиту) меньше, чем имя, являющееся ключом данного узла, а также еще одну ссылку на узел со значением ключа лексикографически большим, чем имя, являющееся ключом данного узла. Будем использовать структуру, которую обозначим как в(Л,В,М, Б) (в - сокращение от «выигрыши»), где Л – кличка лошади (атом), используемая в качестве ключа, В – сумма выигрыша в гинеях (целое), М – структура, соответствующая лошади, кличка которой меньше, чем та, что хранится в Л, а Б – структура, соответствующая лошади, кличка которой больше, чем значение в Л. Когда для М и Б нет соответствующих структур, мы не будем их конкретизировать. Для небольшого множества лошадей указанная структура, будучи записанной в виде дерева, могла бы иметь вид, как представлено на рис. 7.1.
Если записать ее на Прологе в ступенчатом виде, учитывая ширину страницы, то она могла бы выглядеть так:
в(massinga,858,
в(braermar,385,
в(adela,588,_,_),
_),
в(panorama,158,
в(nettleweed,579,_,_),
_).
).
Теперь, располагая такой структурой, мы хотим «просмотреть» ее по кличкам лошадей, чтобы узнать их выигрыши в течение 1938 г. Как и раньше, структура должна иметь формат в(Л,В,М, Б). Условие окончания поиска состоит в том, что кличка искомой лошади должна совпасть с Л. В этом случае поиск удачен и не требуется пробовать другие варианты. В противном случае мы должны использовать предикат меньше, определенный в гл. 3, чтобы определить, какую из «ветвей» дерева, М или Б, нужно рекурсивно просмотреть. Мы используем эти принципы при определении предиката искать, причем искать(Л,Т, Г) означает, что лошадь Л, если она найдена в таблице Т (которая организована в виде структуры формата в), выиграла Г гиней:
искать (Л, в(Л,Г,_,),Г):-!.
искать Л, в(Л1,_,До,_),Г):-меньше(Л,Л1),искать(Л,До,Г).
искать(Л, в(Л1,_,_,После),Г):- not (меньше(Л,Л1)), искать(Л,После,Г).
Если при поиске по упорядоченному дереву использовать этот предикат, то в общем случае проверок будет меньше, чем если бы их данные были организованы в виде простого списка и просматривались бы с начала до конца.
Предикат искать обладает одним интересным и удивительным свойством: когда вводим вопрос о лошади, клички которой нет в структуре, то любая информация, содержащаяся в вопросе, остается зафиксированной в этой структуре после окончания поиска. Иными словами, вопрос
?- искать(ruby_vintage,S,X).
имеет следующую интерпретацию: построить структуру в, в которой кличке ruby_vintage поставлен в соответствие выигрыш X, и присвоить ее в качестве значения переменной S. Таким образом, искать осуществляет вставку новых компонент в частично заданную структуру. Поэтому многократно обратившись к искать, можно построить словарь. Например, вопрос
?- искать(abaris,X,582), искать(maloja,X,356).
привел бы к тому, что значение переменной X стало упорядоченным деревом из двух вхождений.
Понять то, каким образом искать одновременно выполняет и создание и выборку компонент, можно на основе тех знаний о Прологе, которыми вы уже располагаете; мы настоятельно рекомендуем разобраться в этом самостоятельно. Подсказка: если искать(Л,Т, Г) используется в конъюнкции целей, то «изменения» в структуре Т сохраняются только в области определения Т.
Упражнение 7.1. Поэкспериментируйте с предикатом искать, чтобы установить, какие различия будут в словаре, если элементы в него вставлять каждый раз в разном порядке. Например, как будет выглядеть дерево словаря, если вставлять его элементы в таком порядке: massinga, braemar nettleweed, panorama? А если в таком порядке: adela, braemar, nettleweed, massinga?
Стоит темная грозовая ночь. Когда вы ехали по пустынной сельской дороге, ваша машина сломалась и вы оказались перед входом сказочного дворца. Вы подошли к двери, обнаружили, что она открыта, и стали искать телефон. Как нужно осматривать дворец, чтобы не заблудиться и быть уверенным, что вы осмотрели каждую комнату? И каков кратчайший путь к телефону? Именно для таких крайних обстоятельств и разработаны методы поиска в лабиринте.
Во многих программах для ЭВМ, подобных программам поиска в лабиринте, полезно вести информационные списки и просматривать нужный список, когда впоследствии понадобится некоторая информация. Например, если мы решили найти во дворце телефон, нам может понадобиться список уже осмотренных комнат. Чтобы не плутать, снова и снова заходя в те же самые комнаты, нам нужно просто записывать на листке бумаги номера комнат, где мы уже побывали. Перед тем, как войти в комнату, мы проверяем, нет ли ее номера на нашем листке. Если он есть, мы пропускаем эту комнату, потому что уже должны были побывать там раньше. Если номера этой комнаты нет на листке, то мы записываем ее номер и входим в комнату, и так до тех пор, пока не найдем телефон.
Этот метод нуждается в некоторых уточнениях, но мы сделаем их позднее, при обсуждении проблем поиска на графе. А сначала давайте запишем по порядку наши шаги, чтобы знать, какие задачи предстоит решать:
1. Подойти к двери какой-либо комнаты. Если номер комнаты есть в нашем списке, то перейти к шагу 1.
2. Если в поле зрения нет ни одной комнаты, то «вернуться назад» через ту комнату, через которую мы прошли сюда, и посмотреть, нет ли возле нее каких-либо других комнат.
3. Иначе дописать номер комнаты к нашему списку.
4. Поискать телефон в этой комнате.
5. Если телефона нет, то перейти к шагу 1. Иначе мы останавливаемся, и наш список содержит путь, который мы прошли, чтобы попасть в нужную комнату.
Будем считать, что номера комнат являются константами (безразлично целыми числами или атомами). Сначала мы можем решить, как просматривать номера комнат, записанные на листке бумаги. Для этого можно использовать предикат принадлежит, определенный в разд. 3.3, полагая, что содержимое листка бумаги представлено в виде списка. Теперь мы можем продвинуться в решении задачи поиска в лабиринте. Рассмотрим небольшой пример, где задан план дома, комнаты которого помечены буквами (см. рис. 7.2). Заметим, что просветы в стенах обозначают двери и что комната а – это просто представление пространства вне дома. Имеются двери, ведущие из а в b, из с в d, из f в е, и так далее. Сведения о том, где имеются двери, могут быть представлены в виде фактов Пролога:
д(а,b).
д(b,е).
д(b,с).
д(d,c).
д(c,d).
д(e,f).
д(g,e).
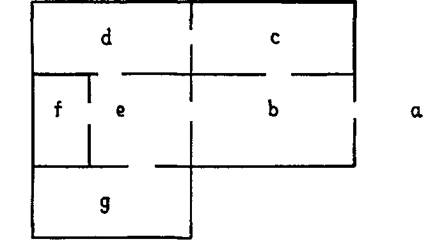
Рис. 7.2.
Заметим, что информация о наличии дверей не избыточна. Например, мы сказали, что имеется дверь, ведущая из комнаты g в комнату е, но не сказали, что имеется дверь, ведущая из комнаты е в комнату g, т. е. мы не зафиксировали утверждение д(e,g). Чтобы обойти эту проблему представления двухсторонних дверей, мы могли бы повторно записать д-факт для каждой двери с перестановкой аргументов. Или мы могли бы устроить программу таким образом, чтобы она понимала, что каждая дверь фактически может рассматриваться как двухсторонняя. Этот вариант мы и выбрали в нижеследующей программе.
Чтобы перейти из одной комнаты в другую, мы должны распознать один из следующих случаев:
• мы находимся в той комнате, которая нам нужна, или
• мы должны войти в дверь и распознать эти случаи снова (рекурсивно).
Рассмотрим целевое утверждение переход(X,Y,T), которое доказуемо (согласуется с базой данных), если можно перейти из комнаты X в комнату Y. Третий аргумент Т – это наш листок бумаги, который мы носим с собой и на котором записан перечень номеров комнат, в которых мы побывали до сего момента.
Граничное условие перехода из комнаты X в комнату Y состоит в том, что, возможно, мы уже находимся в комнате Y (т. е., возможно, X есть Y). Это условие представлено в виде утверждения:
переход(Х,Х,Т).
В противном случае мы выбираем некоторую смежную комнату, назовем ее Z, и смотрим, были ли мы в ней раньше. Если нет, то «переходим» из Z в Y, дописывая Z в наш список. Все это выражается в виде следующего утверждения:
переход(Х, Y,T,):- Д(Х,Z),not(принадлежит(Z,Т)), переход(Z,Y,[Z|T]).
Словами это может быть выражено так: для того чтобы «перейти» из X в Y, не проходя через комнаты из списка Т, надо найти дверь из X куда-либо (т. е. в Z), убедиться, что Z еще не занесена в список Т, и «перейти» из Z в Y, используя список Т с дописанной в него Z.
При использовании этого правила существуют три возможности возникновения ошибки: во-первых, если в X вообще нет двери. Во-вторых, если дверь, которую мы выбрали, уже есть в списке. В-третьих, если «переход» в комнату Z приведет в тупик на следующих уровнях. Если первое целевое утверждение д(X, Z) не согласуется с базой данных, то и данное целевое утверждение переход также недоказуемо. На «самом верхнем» уровне (не рекурсивный вызов) это означает, что из X в Y нет пути; на более глубоких уровнях это означает, что мы должны сделать «шаг назад» и поискать другую дверь.
Наша программа рассматривает каждую дверь как одностороннюю. Если мы считаем, что наличие двери из комнаты а в комнату b – это то же самое, что наличие двери из комнаты b в комнату а, то, как отмечалось выше, мы должны указать это явно. Кроме повторного задания д -фактов с перестановкой аргументов, имеются два способа задать эту информацию в самой программе. Самый очевидный способ – это добавить еще одно правило, получая в итоге:
переход(Х,X,T).
переход(X,Y,T):- д(X,Z), not(принадлежит(Z,Т)),переход(Z,Y[Z|T]). переход(Х,Y,T):- д(Z,Х), not(принадлежит(Z,Т)),пeреход(Z,Y,[Z|T]).
Или, используя предикат ';' (обозначающий дизъюнкцию), можно записать:
переход(Х,Х,Т).
переход(Х,Y,T):- (д(Х,Z); д(Z,Х)), not(принадлежит (Z,T)),пepexод(Z,Y,[Z|T]).
Теперь о том, как найти телефон. Рассмотрим целевое утверждение есть_телефон(X), которое согласуется с базой данных, если в комнате X есть телефон. Если мы хотим сказать, что в комнате g есть телефон, то мы просто записываем в нашу базу данных факт есть_телефон(g). Предположим, мы начали поиск с комнаты а. Один из способов узнать дорогу к телефону – это задать вопрос:
?- переход(а,Х,[]), есть_телефон(X).
Это – вопрос типа «создать и проверить», который находит достижимые комнаты и затем проверяет наличие в них телефона. Другой способ – это найти сопоставление сначала для предиката есть_телефон(Х), а затем попробовать перейти из комнаты а в X:
?- есть_телефон(Х), переход(а,Х,[]).
Последний метод более эффективен, однако он подразумевает что мы «знаем», где телефон, еще до того, как начали поиск.
Начальная установка третьего аргумента пустым списком означает, что мы начинаем поиск, имея чистый лист бумаги. Изменяя эту начальную установку, можно получить разные варианты поиска. Вопрос «найти телефону не заходя в комнаты d и f» можно выразить на Прологе так:
?- есть_телефон(X), переход (a,X,[d,f]).
В разд. 7.9 мы рассмотрим некоторые общие процедуры поиска по графу, в том числе программу, находящую кратчайший путь.
Упражнение 7.2. Допишите вышеприведенную программу так, чтобы она печатала такие сообщения, как «входим в комнату X» и «телефон найден в комнате Y», подставляя в них соответствующие номера комнат.
Упражнение 7.3. Может ли эта программа находить альтернативные пути? Если да, то где нужно «отсечь», чтобы избежать нахождения более чем одного пути?
Упражнение 7.4. Чем определяется порядок, в котором просматриваются комнаты?
|
|
|
|
|
Дата добавления: 2014-12-08; Просмотров: 408; Нарушение авторских прав?; Мы поможем в написании вашей работы!