КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Пример. Топологическая сортировка
|
|
|
|
Топологической называют сортировку на множестве элементов в случае, когда на множестве элементов задано отношение частичного порядка. Порядок является частичным, если отношение предшествования задано не для всех пар элементов. Множество целых чисел является полностью упорядоченным, так как для любой пары целых чисел a,b определено отношение ‘>’ (больше) или ‘<’ (меньше).
В качестве примера ситуации, когда порядок является частичным, рассмотрим производство следующих работ:
1. сделать болт
2. сделать гайку
3. навернуть гайку на болт
Ясно, что работы 1 и 2 должны предшествовать работе 3. Запишем этот факт как 1í2 (читается: 1 предшествует 2) и 2í3. Работы 1 и 2 не связаны между собой отношением предшествования.
Другим примером, в котором имеется частичный порядок, является учебный план подготовки специалистов в ВУЗе. Курс "Основы алгоритмизации и языки программирования" должен предшествовать курсу "Структуры и алгоритмы обработки данных", но ни тот, ни другой никак не связаны с курсом "История государственного управления в России".
Третий пример: пусть требуется написать библиотеку подпрограмм, в которой некоторые из подпрограмм вызывают другие подпрограммы из той же библиотеки. Очевидно, что приступать к отладке вызывающих подпрограмм следует после завершения отладки вызываемых.
Топологическая сортировка на основе имеющегося отношения частичного порядка строит линейную последовательность элементов сортируемого множества, в которой для любой пары Xi, Xj не может быть выполнено условие Xi í Xj при i>j. Иными словами, для пары a í b, a не может появиться в выходной последовательности позже b.
Исходными данными для работы алгоритма является массив пар элементов first, second, таких, что first í second.Одна такая пара представляется структурой:
struct PAIR{
char *first;
char *second;
};
Для реализации алгоритма используются списочная структура, содержащая узлы двух типов: узлы основного списка (MAINS) и узлы подсписков (POD). Основной список двусвязный, с головой, циклический. Подсписок – односвязный, без головы и нециклический.
struct MAINS{ // cтруктура узла основного списка
int count; // счетчик числа элементов, предшествующих
//данному
char name[40]; // имя элемента
MAINS *llink; // связи двусвязного списка
MAINS *rlink;
struct POD *pod; // указатель на подсписок
};
struct POD { // структура узла подсписка
POD *next;// следующий узел подсписка
MAINS *m; // указатель на узел основного списка
};
Алгоритм имеет три фазы:
Первая фаза – первоначальное построение списочной структуры. Проходим массив пар, и для каждого элемента множества, который ещё не включен в список, создаем узел и помещаем его в хвост основного списка. Для каждой пары first, second в подсписок узла first помещаем узел, в поле m которого помещаем ссылку на узел основного списка second. Счетчик count узла second увеличиваем на единицу. После завершения первой фазы узел каждого элемента содержит число элементов, предшествующих данному. На рис.19 изображено состояние основного списка после завершения первой фазы для массива пар
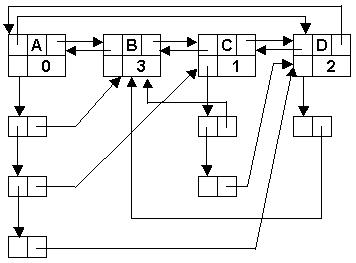 |
предшествования
Рис 19. Топологическая сортировка. 1 фаза.
Вторая фаза – создание списка ведущих элементов. Список ведущих имеет такую же структуру, что и основной список. Проходя основной список слева направо, узлы, имеющие поле счетчика, равное нулю, переносим в список ведущих элементов. Этим элементам ничто не предшествует, и они первыми будут выведены в выходную последовательность.
Третья фаза – построение выходной последовательности. Проходим список ведущих и его элементы помещаем в выходную последовательность и удаляем из списка ведущих. Проходя подсписок выводимого в результат элемента, уменьшаем на единицу поле счетчика того элемента основного списка, на который ссылается поле m подсписка. Действительно, после вывода элемента списка ведущих в результирующую последовательность, он уже не предшествует оставшимся в основном списке элементам. Если поле счетчика окажется равным нулю, переносим его в хвост списка ведущих.
Если отношение предшествования было задано корректно, то все элементы будут выведены и основной список опустеет. Если же основной список по завершении третьей фазы не пуст, то это говорит о противоречивом задании частичного порядка. Например, частичный порядок
a í b; b í c; c í a
противоречив.
Ниже приведен текст функции, реализующей топологическую сортировку:
void TopSort(PAIR *p, int n_pair, FILE *result){
// p - массив пар указателей на имена элементов
// Наличие пары s1,s2 означает,
// что s1ís2
// n_pair - число таких пар
// result - файл, в который помещаются результаты
MAINS *mhead; // голова основного списка
MAINS *vhead; // голова списка ведущих элементов
MAINS *u1,*u2,*v,*w;
int i;
POD *x,*y;
// создание основного списка
mhead=new MAINS;
mhead->llink=mhead;
mhead->rlink=mhead;
// проход по всем парам
for(i=0; i<n_pair; i++){
// найдем или создадим элемент по имени p[i].first
u1=FindU(mhead,p[i].first);
// найдем или создадим элемент по имени p[i].second
u2=FindU(mhead,p[i].second);
// u1 предшествует u2, поэтому к счетчику u2 прибавим 1
u2->count++;
// в подсписок u1 добавим узел, указывающий на u2
x=new POD;
x->next=u1->pod;
u1->pod=x;
x->m=u2;
}
// создание списка ведущих
vhead=new MAINS; // голова
vhead->llink=vhead->rlink=vhead;
// проходим по основному списку и узлы с полем счетчика ==0
// переносим в список ведущих
for(v=mhead->rlink; v!=mhead; v=w){
w=v->rlink;
if(v->count==0){
// переносим в хвост списка ведущих
AddToTail(vhead,v);
}
}
// проход по списку ведущих
for(v=vhead->rlink; v!=vhead; v=v->rlink){
// имя элемента печатаем в файл результата
fprintf(result," \"%s\",\n",v->name);
// проходим по подсписку и уменьшаем на 1 поле счетчика
// в узлах основного списка, на которые ссылаются узлы
// подсписка
for(x=v->pod,y=x->next; x!=NULL; x=y){
y=x->next;
x->m->count--;
if(x->m->count==0){
// если счетчик==0, то переносим узел из основного
// списка в конец списка ведущих
AddToTail(vhead,x->m);
}
// узлы подсписка больше не понадобятся
delete x;
}
// узлы списка ведущих тоже больше не нужны
delete v;
}
delete vhead;
// осталось ли что-нибудь в основном списке?
// если осталось, то это говорит о противоречивом
// задании предшествования и список содержит кольца
// элементов множества
// в любом случае надо все освободить
if(mhead->rlink!=mhead){
fprintf(result,"Список функций, образующих рекурсивные цепи\n");
for(v=mhead->rlink; v!=mhead; v=v->rlink){
fprintf(result,"%3d %s\n",v->count, v->name);
for(x=v->pod,y=x->next; x!=NULL; x=y){
y=x->next;
delete x;
}
delete v;
}
}
delete mhead;
}
Рассмотренный алгоритм использует две вспомогательные функции:
MAINS *FindU(MAINS *head, char *WhatToFind){
MAINS *v;
// Функция либо находит в основном списке с головой head
// узел с элементом по имени WhatToFind, либо создает его
// В любом случае возвращается указатель на узел с
// элементом по имени WhatToFind
// ищем, и если найдем, вернем указатель
for(v=head->rlink; v!=head; v=v->rlink){
if(strcmp(WhatToFind,v->name)==0){
return v;
}
}
// не нашли - создаем
v=new MAINS;
strcpy(v->name,WhatToFind);
v->count=0;
v->pod=NULL;
v->rlink=head;
v->llink=head->llink;
head->llink->rlink=v;
head->llink=v;
return v;
}
//-------------------------------------
void AddToTail(MAINS *head, MAINS *v){
// изъять узел v из основного списка и вставить
// в хвост списка ведущих с головой head
// удаляем из того списка, в котором он сейчас находится
v->llink->rlink=v->rlink;
v->rlink->llink=v->llink;
// помещаем слева от head
v->rlink=head;
v->llink=head->llink;
head->llink->rlink=v;
head->llink=v;
}
|
|
|
|
|
Дата добавления: 2014-12-08; Просмотров: 719; Нарушение авторских прав?; Мы поможем в написании вашей работы!