КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Параллельное выполнение транзакций
|
|
|
|
Восстановление после жесткого сбоя
Восстановление начинается с обратного копирования базы данных из архивной копии (содержание данного пункта скопировано из работы [19]). Затем для всех закончившихся транзакций выполняется redo, то есть операции повторно выполняются в прямом порядке.
Более точно, происходит следующее:
по журналу в прямом направлении выполняются все операции;
для транзакций, которые не закончились к моменту сбоя, выполняется откат.
На самом деле, поскольку жесткий сбой не сопровождается утратой буферов оперативной памяти, можно восстановить базу данных до такого уровня, чтобы можно было продолжить даже выполнение незакончившихся транзакций. Но обычно это не делается, потому что восстановление после жесткого сбоя — это достаточно длительный процесс.
Хотя к ведению журнала предъявляются особые требования по части надежности, в принципе возможна и его утрата. Тогда единственным способом восстановления базы данных является возврат к архивной копии. Конечно, в этом случае не удастся получить последнее согласованное состояние базы данных, но это лучше, чем ничего.
Рассмотрим производство архивных копий базы данных. Самый простой способ – архивировать базу данных при переполнении журнала. В журнале вводится так называемая «желтая зона», при достижении которой образование новых транзакций временно блокируется. Когда все транзакции закончатся и, следовательно, база данных придет в согласованное состояние, можно производить ее архивацию, после чего начинать заполнять журнал заново.
Можно выполнять архивацию базы данных реже, чем переполняется журнал. При переполнении журнала и окончании всех начатых транзакций можно архивировать сам журнал. Поскольку такой архивированный журнал, по сути дела, требуется только для воссоздания архивной копии базы данных, журнальная информация при архивации может быть существенно сжата.
Если с БД работают одновременно несколько пользователей, то обработка транзакций должна рассматриваться с новой точки зрения (содержание данного пункта скопировано из работы [19]). В этом случае СУБД должна не только корректно выполнять индивидуальные транзакции и восстанавливать согласованное состояние БД после сбоев, но она призвана обеспечить корректную параллельную работу всех пользователей над одними и теми же данными. По теории каждый пользователь и каждая транзакция должны обладать свойством изолированности, то есть они должны выполняться так, как если бы только один пользователь работал с БД. И средства современных СУБД позволяют изолировать пользователей друг от друга именно таким образом. Однако в этом случае возникают проблемы замедления работы пользователей. Рассмотрим более подробно проблемы, которые возникают при параллельной обработке транзакций.
Основные проблемы, которые возникают при параллельном выполнении транзакций, делятся условно на 4 типа:
Пропавшие изменения. Эта ситуация может возникать, если две транзакции одновременно изменяют одну и ту же запись в БД. Например, работают два оператора на приеме заказов, первый оператор принял заказ на 30 мониторов. Когда он запрашивал склад, то там числилось 40 мониторов, и он, получив подтверждение от клиента, выставил счет и оформил продажу 30 мониторов из 40. Параллельно с ним работает второй оператор, который принимает заказ на 20 таких же мониторов (ну уж очень хорошая модель и дешево) и, в свою очередь запросив состояние склада и получив исходно ту же цифру 40, он успешно оформляет заказ для своего клиента. Заканчивая работу с данным заказом, он выполняет команду Обновить (UPDATE), которая заносит 20 как остаток любимых мониторов на складе. Но после этого, наконец, любезно попрощавшись со своим клиентом и заверив его в скорейшей доставке заказанных мониторов, заканчивает работу со своим заказом первый оператор и также выполняет команду Обновить и заносит 10 как остаток тех же мониторов на складе. Каждый из них доволен своей работой, но мы-то знаем, что произошло. Прежде всего, они продали 50 мониторов из наличествующих 40 штук, и далее на складе еще числится 10 подобных мониторов. БД теперь находится в несогласованном состоянии, а у фирмы возникли серьезные проблемы. Изменения, сделанные вторым оператором, были проигнорированы программой выполнения заказа, с которой работал первый оператор. Подобная ситуация представлена на рисунке 1.9.9.1.
Проблемы промежуточных данных. Рассмотрим ту же проблему одновременной работы двух операторов. Допустим, первый оператор, ведя переговоры со своим заказчиком, ввел заказанные 30 мониторов, но перед окончательным оформлением заказа клиент захотел выяснить еще некоторые характеристики товара. Приложение, с которым работает первый оператор, уже изменило остаток мониторов на складе, и там сейчас находится информация о 10 оставшихся мониторах. В это время второй оператор пытается принять заказ от своего клиента на 20 мониторов, но его приложение показывает, что на складе осталось всего 10 мониторов, и оператор вынужден отказать выгодному клиенту, который идет в другую фирму, весьма неудовлетворенный работой нашей компании. А в этот момент клиент оператора 1 заканчивает обсуждение дополнительных характеристик наших мониторов и принимает весьма невыгодное решение не покупать у нас мониторы, и приложение оператора 1 выполняет откат транзакции, и на складе снова оказывается 40 мониторов. Мы потеряли выгодного заказчика, но еще хуже было бы, если бы клиент второго оператора согласился на 10 оставшихся мониторов, и приложение, с которым работает оператор два, отработав свой алгоритм, занесло О (ноль) оставшихся мониторов на складе, а после этого приложение оператора один снова бы записало исходные 40 мониторов на складе, хотя 10 их них уже проданы. Такая ситуация оказалась возможной потому, что приложение второго оператора имело доступ к промежуточным данным, которые сформировало первое приложение.
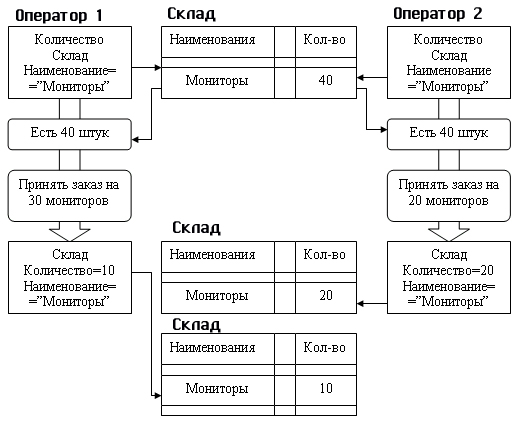
Рис. 1.9.9.1 – Проблема пропавших обновлений.
Проблемы несогласованных данных. Рассмотрим ту же самую ситуацию с заказом мониторов. Предположим, что ситуация несколько изменилась. И оба оператора начинают работать практически одновременно. Они оба получают начальное состояние склада 40 мониторов, а далее первый оператор успешно завершает переговоры со своим клиентом и продает ему 30 мониторов. Он завершает работу своего приложения, и оно выполняет команду фиксации транзакции COMMIT.
Состояние базы данных непротиворечивое. В этот момент, выяснив все тонкости и характеристики наших мониторов, клиент второго оператора также решает сделать заказ, и второй оператор, повторно получая состояние склада, видит, что оно изменилось. База данных находится в непротиворечивом состоянии, но второй оператор считает, что нарушена целостность его транзакции, в течение выполнения одной работы он получил два различных состояния склада. Эта ситуация возникла потому, что приложение первого оператора смогло изменить кортеж с данными, который уже прочитало приложение второго оператора.
Проблемы строк-призраков (строк-фантомов). Предположим, что администратор нашей фирмы поручил секретарю напечатать итоговый отчет по результатам работы за текущий месяц. И допустим, что приложение печатает отчет в двух видах: в подробном и в укрупненном. В момент, когда приложение печати начало формировать свой первый вид отчета, один из операторов принимает еще один заказ, поэтому к моменту формирования укрупненного отчета в БД появились новые сведения о продажах, которые и были внесены в укрупненный отчет. Мы получили два отчета в одном приложении, которые содержат разные цифры и не совпадают друг с другом. Такое стало возможно потому, что приложение печати выполнило два одинаковых запроса и получило два разных результата. БД находится в согласованном состоянии, но приложение печати работает некорректно.
Для того чтобы избежать подобных проблем, требуется выработать некоторую процедуру согласованного выполнения параллельных транзакций. Эта процедура должна удовлетворять следующим правилам:
В ходе выполнения транзакции пользователь видит только согласованные данные. Пользователь не должен видеть несогласованных промежуточных данных.
Когда в БД две транзакции выполняются параллельно, то СУБД гарантированно поддерживает принцип независимого выполнения транзакций, который гласит, что результаты выполнения транзакций будут такими же, как если бы вначале выполнялась транзакция 1, а потом транзакция 2, или наоборот, сначала транзакция 2, а потом транзакция 1.
Такая процедура называется сериализацией транзакций. Фактически она гарантирует, что каждый пользователь (программа), обращающаясь к базе данных, работает с ней так, как будто не существует других пользователей (программ), одновременно с ним обращающихся к тем же данным.
Для поддержки параллельной работы транзакций строится специальный план.
План (способ) выполнения набора транзакций называется сериальным, если результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций.
Самым простым было бы последовательное выполнение транзакций, но такой план не оптимален по времени, существуют более гибкие методы управления параллельным доступом к БД. Наиболее распространенным механизмом, который используется коммерческими СУБД для реализации на практике сериали-зации транзакций является механизм блокировок. Самый простой вариант — это блокировка объекта на все время действия транзакции. Подобный пример рассмотрен на рисунке 1.9.9.2.
Здесь две транзакции, названные условно А и В, работают с тремя таблицами: T1, T2 и Т3. В момент начала работы с любым объектом этот объект блокируется транзакцией, которая с ним начала работу, и он становится недоступным всем другим транзакциям до окончания транзакции, заблокировавшей («захватившей») данный объект. После окончания транзакции все заблокированные ею объекты разблокируются и становятся доступными другим транзакциям. Если транзакция обращается к заблокированному объекту, то она остается в состоянии ожидания до момента разблокировки этого объекта, после чего она может продолжать обработку данного объекта. Поэтому транзакция В ожидает разблокировки таблицы Т2 транзакцией А. Над прямоугольниками стоит условное время выполнения операций.
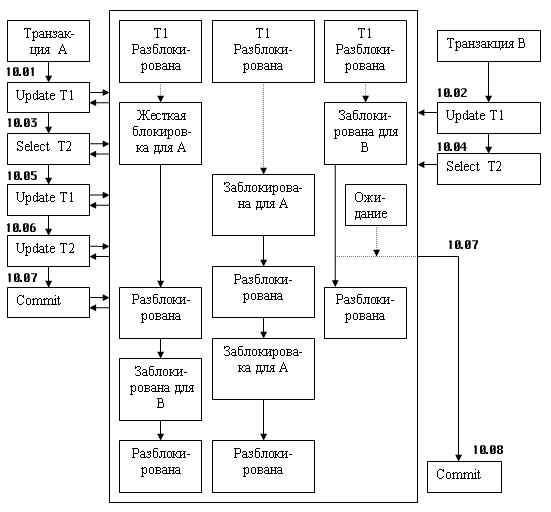
Рисунок 1.9.9.2 – Блокировки при одновременном выполнении двух транзакций
В общем случае на момент выполнения транзакция получает как бы монопольный доступ к объектам БД, с которыми она работает. В этом случае другие транзакции не получают доступа к объектам БД до момента окончания транзакции. Такой механизм действительно ликвидирует все перечисленные ранее проблемы: пропавшие изменения, неподтвержденные данные, несогласованные данные, строки-фантомы.
Однако такая блокировка создает новые проблемы — задержку выполнения транзакций из-за блокировок.
Рассмотрим существующие типы конфликтов между двумя параллельными транзакциями. Можно выделить следующие типы:
W-W — транзакция 2 пытается изменять объект, измененный незакончившейся транзакцией 1;
R-W — транзакция 2 пытается изменять объект, прочитанный незакончившейся транзакцией 1;
W-R — транзакция 2 пытается читать объект, измененный незакончившейся транзакцией 1.
Практические методы сериализации транзакций основываются на учете этих конфликтов.
Блокировки, называемые также синхронизационными захватами объектов, могут быть применены к разному типу объектов. Наибольшим объектом блокировки может быть вся БД, однако этот вид блокировки сделает БД недоступной для всех приложений, которые работают с данной БД.
Следующий тип объекта блокировки — это таблицы. Транзакция, которая работает с таблицей, блокирует ее на все время выполнения транзакции. Именно такой вид блокировки рассмотрен в примере рисунка 1.9.9.3.
Этот вид блокировки предпочтительнее предыдущего, потому что позволяет параллельно выполнять транзакции, которые работают с другими таблицами.
В ряде СУБД реализована блокировка на уровне страниц. В этом случае СУБД блокирует только отдельные страницы на диске, когда транзакция обращается к ним. Этот вид блокировки еще более мягок и позволяет разным транзакциям работать даже с одной и той же таблицей, если они обращаются к разным страницам данных.
В некоторых СУБД возможна блокировка на уровне строк, однако такой механизм блокировки требует дополнительных затрат на поддержку этого вида блокировки.
В настоящее время проблема блокировок является предметом большого числа исследований.
Для повышения параллельности выполнения транзакций используется комбинирование разных типов синхронизационных захватов.
Рассматривают два типа блокировок (синхронизационных захватов):
совместный режим блокировки — нежесткая, или разделяемая, блокировка, обозначаемая как S (Shared). Этот режим обозначает разделяемый захват объекта и требуется для выполнения операции чтения объекта. Объекты, заблокированные таким образом, не изменяются в ходе выполнения транзакции и доступны другим транзакциям также, но только в режиме чтения;
монопольный режим блокировки — жесткая, или эксклюзивная, блокировка, обозначаемая как X (eXclusive). Данный режим блокировки предполагает монопольный захват объекта и требуется для выполнения операций занесения, удаления и модификации. Объекты, заблокированные данным типом блокировки, фактически остаются в монопольном режиме обработки и недоступны для других транзакций до момента окончания работы данной транзакции.
Захваты объектов несколькими транзакциями по чтению совместимы, то есть нескольким транзакциям допускается читать один и тот же объект, захват объекта одной транзакцией по чтению не совместим с захватом другой транзакцией того же объекта по записи, и захваты одного объекта разными транзакциями по записи не совместимы. Правила совместимости захватов одного объекта разными транзакциями изображены на рисунке 1.9.9.3:
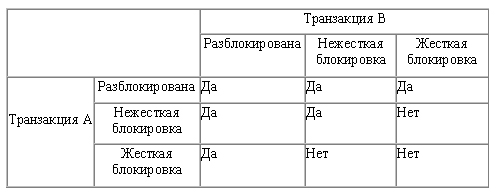
Рисунок 1.9.9.3. Правила применения жесткой и нежесткой блокировок транзакций
В примере, представленном на рис. 11.7 считается, что первой блокирует объект транзакция А, а потом пытается получить к нему доступ транзакция В.
На рисунке 1.9.9.4приведен ранее рассмотренный пример с выполнением транзакций 1 и 2, но с учетом разных типов блокировки. На рисунке видно, что, применив нежесткую блокировку к таблице 2 со стороны транзакции 1, мы обеспечили существенное уменьшение времени выполнения транзакции 2. Теперь транзакция 2 не ждет окончания транзакции 1, и поэтому завершает свою работу намного раньше.
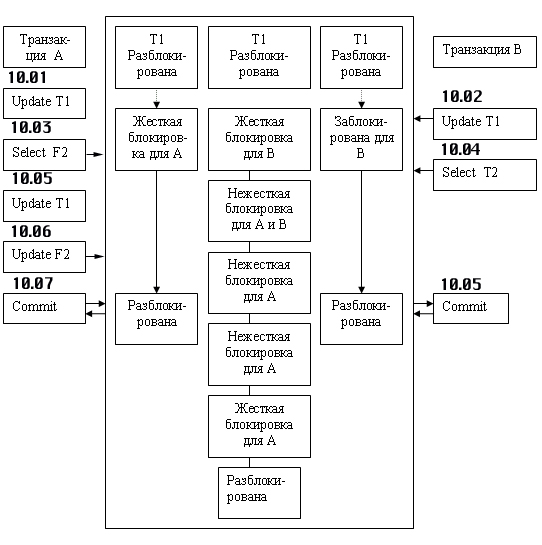
Рисунок 1.9.9.4. Использование жесткой и нежесткой блокировки
К сожалению, применения разных типов блокировок приводит к проблеме тупиков. Эта проблема не нова. Проблема тупиков возникла при рассмотрении выполнения параллельных процессов в операционных средах и также была связана с управлением разделяемыми (совместно используемыми) ресурсами.
Действительно, рассмотрим пример. Пусть транзакция А сначала жестко блокирует таблицу 1, а потом жестко блокирует таблицу 2. Транзакция В, наоборот, сначала жестко блокирует таблицу 2, а потом жестко блокирует таблицу 1. Если обе эти транзакции начали работу одновременно, то после выполнения операций модификации первыми объектами каждой транзакции они обе окажутся в бесконечном ожидании: транзакция А будет ждать завершения работы транзакции В и разблокировки таблицы 2, а транзакция В также безрезультатно будет ждать окончания работы транзакции А и разблокировки таблицы 1 (см. рисунок 1.9.9.5).
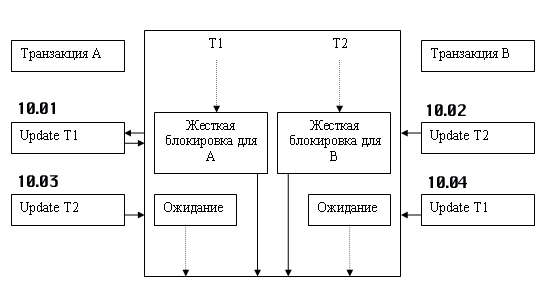
Рисунок 1.9.9.5 – Взаимная блокировка транзакций
Ситуации могут быть гораздо более сложными. Количество взаимно заблокированных транзакций может оказаться гораздо больше. Эту ситуацию каждая из транзакций обнаружить самостоятельно не может. Ее должна разрешить СУБД. И действительно, в большинстве коммерческих СУБД существует механизм обнаружения таких тупиковых ситуаций.
Для обеспечения сериализации транзакций синхронизационные захваты объектов, произведенные по инициативе транзакции, можно снимать только при ее завершении. Это требование порождает двухфазный протокол синхронизационных захватов — 2PL(two phase lock) или 2РС (two phase commit). В соответствии с этим протоколом выполнение транзакции разбивается на две фазы:
первая фаза транзакции – накопление захватов;
вторая фаза (фиксация или откат) – освобождение захватов.
В языке SQL введен оператор явной блокировки таблицы, который позволяет точно задать тип блокировки для всей таблицы.
Синтаксис операции блокировки имеет вид:
LOCK TABLE имя_таблицы IN {SHARED | EXCLUSIVE} MODE
Имеет смысл блокировать таблицу полностью, когда выполняется операция множественной модификации одной таблицы, то есть когда в ней изменяется большое количество строк. Эта операция иногда называется пакетным обновлением.
Конечно, у блокировки таблицы есть тот недостаток, что все остальные транзакции должны ждать окончания обновления таблицы. Но режим пакетного обновления одной таблицы работает достаточно быстро, и общая производительность выполнения множества транзакций может даже повыситься в этом случае.
|
|
|
|
|
Дата добавления: 2014-12-10; Просмотров: 689; Нарушение авторских прав?; Мы поможем в написании вашей работы!