КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Динамический SQL
|
|
|
|
Возможности операторов встроенного SQL, описанные ранее, относятся к статическому SQL (содержание данного пункта скопировано из работы [19]). В статическом SQL вся информация об операторе SQL известна на момент компиляции. Однако очень часто в диалоговых программах требуется более гибкая форма выполнения операторов SQL. Фактически, сам текст оператора SQL формируется уже во время выполнения программы. Сформированный таким образом текст SQL-оператора поступает в СУБД, которая должна его скомпилировать и выполнить «на лету», в процессе работы приложения. Если мы снова вернемся к этапам выполнения SQL-операторов, то первые четыре действия, связанные с синтаксическим анализом, семантическим анализом, построением и оптимизацией плана выполнения запроса, выполняются на этапе компиляции. В момент исполнения этого оператора СУБД просто изымает хранимый план выполнения этого оператора и исполняет его.
В случае динамического SQL ситуация абсолютно иная. На момент компиляции мы не видим и не знаем текст оператора SQL и не можем выполнить ни одного из четырех обозначенных этапов. Все этапы СУБД должна будет выполнять с ходу, без предварительной подготовки в момент исполнения программы.
Конечно, динамический SQL гораздо менее эффективен в смысле производительности, по сравнению со статическим SQL. Поэтому во всех случаях, когда это возможно, необходимо избегать динамического SQL.
Но бывают случаи, когда отказ от динамического SQL серьезно усложняет приложение. Например, в случае с поиском по произвольному множеству параметров невозможно заранее предусмотреть все возможные комбинации запросов, даже если возможных параметров два десятка. А если их больше, то именно динамический SQL становится наиболее удобным методом решения необъятной проблемы.
Наиболее простой формой динамического SQL является оператор непосредственного выполнения EXECUTE IMMEDIATE. Этот оператор имеет следующий синтаксис:
EXECUTE IMMEDIATE <имя_базовой переменной>
Базовая переменная содержит текст SQL оператора.
Однако оператор непосредственного выполнения пригоден для выполнения операции, которые не возвращают результаты. Так же как в статическом SQL, для работы с множеством записей вводится понятие курсора и добавляются операторы по работе с курсором, и в динамическом SQL должны быть определены подобные структуры.
Прежде всего было предложено разделить выполнение SQL-оператора в динамическом SQL на два отдельных этапа. Первый этап называется подготовительным, он фактически включает 4 первых этапа выполнения SQL-операторов: синтаксический и семантический анализ, построение и оптимизация плана выполнения оператора.
Этот этан выполняется оператором PREPARE, синтаксис которого приведен ниже:
PREPARE <имя_оператора> FROM <имя_базовой переменной>
<имя_оператора> - это идентификатор базового языка.
Далее на втором этапе этот определенный на первом этапе оператор может быть выполнен операцией EXECUTE, которая имеет синтаксис:
EXECUTE <имя__оператора> USING {<список базовых переменных> |
DESCRIPTOR <имя_дескриптора>}
Здесь DESCRIPTOR — это некоторая структура, которая описывается на клиенте, но создается и управляется сервером. Дескриптор представляет совокупность элементов данных, принадлежащих СУБД. Программное обеспечение СУБД должно содержать и поддерживать набор операций над дескрипторами. Эта структура была введена в стандарт SQL2 для типизации динамического SQL.
В стандарт SQL2 введены следующие операции над дескрипторами:
- ALLOCATE DESCRIPTOR <имя_дескриптора> [WITH MAX <число_элементов>] — оператор связывает имя дескриптора с числом его базовых элементов и обеспечивает выделение памяти под данный дескриптор.
- DEALLOCATE DESCRIPTOR <имя_дескриптора> — оператор освобождает разделяемую память СУБД, занятую хранением описания данного дескриптора. После выполнения данного оператора невозможно обратиться к дескриптору ни с одной операцией.
- SET DESCRIPTOR {COUNT = <имя_базовой переменной> VALUE <номер элемента> {<имя_ элемента>= <имя_базовой перененной>[...]}} — оператор занесения в дескриптор описания передаваемых параметров. Описания перелаются СУБД, которая их обрабатывает, внося соответствующие изменения в область данных, отведенную под дескриптор.
- GET DESCRIPTOR { <имя_базовой переменной> = COUNT | VALUE <номер элемента> {<имя_базовой переменной>=<имя_эленента>[...]} — оператор получения информации из дескрипторов после выполнения запроса.
- DESCRIBE [ INPUT | OUTPUT] <имя_оператора> USING SQL DESCRIPTOR <имя_дескрипто-pa> — оператор, позволяющий получить описания таблиц результатов запросов (DESCRIBE OUTPUT) или входных параметров (DESCRIBE INPUT).
- OPEN <имя_курсора> [USING <список базовых переменных> | USING SQL DESCRIPTOR <имя_дескриптора>] — динамический оператор открытия курсора.
- FETCH <имя_курсора> [USING <список базовых переменных> | USING SQL DESCRIPTOR <имя_дескриптора>] — динамический оператор перемещения но курсору.
- DEALLOCATE PREPARE <имя_оператора> — оператор уничтожает ранее подготовленный план выполнения оператора SQL и освобождает разделяемую память СУБД, связанную с храпением этого плана. Этот оператор имеет смысл применять, если вы не будете больше применять команду выполнения к подготовленному ранее оператору SQL.
1.11. Архитектура СУБД и оптимизация запросов
СУБД должна управлять внешней памятью, в которой расположены файлы с данными, файлы журналов и файлы системного каталога (рисунок 1.11.1). С другой стороны, СУБД управляет и оперативной памятью, в которой располагаются буфера с данными, буфера журналов, данные системного каталога, которые необходимы для поддержки целостности и проверки привилегии пользователей. Кроме того, и оперативной памяти во время работы СУБД располагается информация, которая соответствует текущему состоянию обработки запросов, там хранятся планы выполнения скомпилированных запросов и т. д.
Модуль управления внешней памятью обеспечивает создание необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например для ускорения доступа к данным в некоторых случаях (обычно для этого используются индексы). Как мы рассматривали ранее, в некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
Модуль управления буферами оперативной памяти предназначен для решения задач эффективной буферизации, которая используется практически для выполнения всех остальных функций СУБД.
Условно оперативную память, которой управляет СУБД, можно представить как совокупность буферов, хранящих страницы данных, буферов, хранящих страницы журналов транзакций и область совместно используемого пула (рисунок 11.1.2). Последняя область содержит фрагменты системного каталога, которые необходимо постоянно держать в оперативной памяти, чтобы ускорить обработку запросов пользователей, и область операторов SQL с курсорами. Фрагменты системного каталога в некоторых реализациях называются словарем данных. В стандарте SQL2 определены общие требования к системному каталогу.
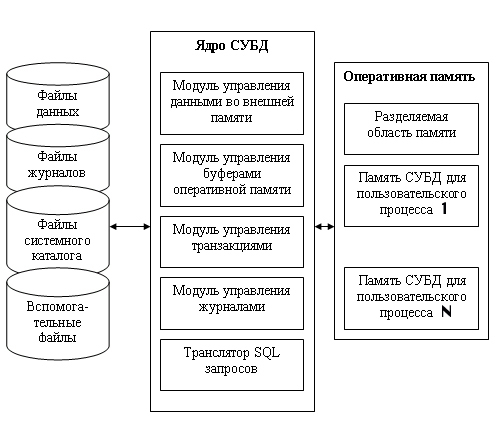
Рисунок1.11.1 - Обобщенная структура СУБД
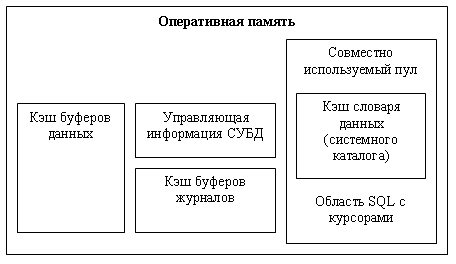
Рисунок11.1.2 – Оперативная память, управляемая СУБД
Системный каталог в реляционных СУБД представляет собой совокупность специальных таблиц, которыми владеет сама СУБД. Таблицы системного каталога создаются автоматически при установке программного обеспечения сервера БД. Все системные таблицы обычно объединяются некоторым специальным «системным идентификатором пользователя». При обработке SQL-запросов СУБД постоянно обращается к этим таблицам. В некоторых СУБД разрешен ограниченный доступ пользователей к ряду системных таблиц, однако только в режиме чтения.
Только системный администратор имеет некоторые права на модификацию данных в некоторых системных таблицах.
Каждая таблица системного каталога содержит информацию об отдельных структурных элементах БД. В стандарте SQL2 определены следующие системные таблицы:
Таблица 14.1. Содержание системного каталога по стандарту SQL2
| Системная таблица | Содержание |
| USERS - | Одна строка для каждого идентификатора пользователя с зашифрованным паролем |
| SCHEMA | Одна строка для каждой информационной схемы |
| DATA_TYPE_DESCRIPTION | Одна строка для каждого домена или столбца, имеющего определенный тип данных |
| DOMAINS | Одна строка для каждого домена |
| DOMAIN_CONSTRA1NS | Одна строка для каждого ограничивающего условия, наложенного на домен |
| TABLES | Одна строка для каждой таблицы с указанием имени, владельца, количества столбцов, размеров данных столбцов, и т. д. |
| VIEWS | Одна строка для каждого представления с указанием имени, имени владельца, запроса, который определяет представление и т. д. |
| COLUMNS | Одна строка для каждого столбца с указанием имени столбца, имени таблицы или представления, к которому он относится, типа данных столбца, его размера, допустимости или недопустимости неопределенных значений (NULL) и т. д. |
| VIEW_TABLE_USAGE | Одна строка для каждой таблицы, на которую имеется ссылка в каком-либо представлении (если представление многотабличное, то для каждой таблицы заносится одна строка) |
| VIEW_COLUMN_USAGE | Одна строка для каждого столбца, на который имеется ссылка в некотором представлении |
| TABLE_CONSTRAINS | Одна строка для каждого условия ограничения, заданного в каком-либо определении таблицы |
| KEY_COLUMN_USAGE | Одна строка для каждого столбца, на который наложено условие уникальности и который присутствует в определении первичного или внешнего ключа (если первичный или внешний ключ заданы несколькими столбцами, то для каждого из них задается отдельная строка) |
| REFERENTIAL_CONSTRAINTS | Одна строка для каждого внешнего ключа, присутствующего в определении таблицы |
| CHECK_ CONSTRAINTS | Одна строка для каждого условия проверки, заданного в определении таблицы |
| CHECK_TABLE_USAGE | Одна строка для каждой таблицы, на которую имеется ссылка в условиях проверки, ограничительном условии для домена или всей таблицы |
| CHECK_COLUMN_USAGE | Одна строка для каждого столбца, на который имеется ссылка в условии проверки, ограничительном условии для домена или ином ограничительном условии |
| ASSERTIONS | Одна строка для каждого декларативного утверждения целостности |
| TABLE_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какую-либо таблицу |
| COLUMN_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какой-либо столбец |
| USAGE_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какой-либо домен, набор символов и т. д. |
| CHARACTER_SETS | Одна строка для каждого заданного набора символов |
| COLLATIONS | Одна строка для заданной последовательности |
| TRANSLATIONS | Одна строка для каждого заданного преобразования |
| SQL_LAGUAGES | Одна строка для каждого заданного языка, поддерживаемого СУБД |
Стандарт SQL2 не требует, чтобы СУБД в точности поддерживала требуемый набор системных таблиц. Стандарт ограничивается требованием того, чтобы для рядовых пользователей были доступны некоторые специальные представления системного каталога. Поэтому системные таблицы организованы по-разному в разных СУБД и имеют различные имена, но большинство СУБД предо-ставля-ют ряд основных представлений рядовым пользователям.
Кроме того, системный каталог отражает некоторые дополнительные возможности, предоставляемые конкретными СУБД. Так, например, в системном каталоге Oracle присутствуют таблицы синонимов.
Область SQL содержит данные связывания, временные буферы, дерево разбора и план выполнения для каждого оператора SQL, переданного серверу БД. Область разделяемого пула ограничена в размере, поэтому, возможно, в ней не могут поместиться все операторы SQL, которые были выполнены с момента запуска сервера БД. Ядро СУБД удаляет старые, давно не используемые операторы, освобождая память под новые операторы SQL. Если пользователь выполняет запрос, план выполнения которого уже хранится в разделяемом пуле, то СУБД не производит его разбор и построение нового плана, она сразу запускает его на выполнение, возможно, с новыми параметрами.
Модуль управления транзакциями поддерживает механизмы фиксации и отката транзакций, он связан с модулем управления буферами оперативной памяти и обеспечивает сохранение всей информации, которая требуется после мягких или жестких сбоев в системе. Кроме того, модуль управления транзакциями содержит специальный механизм поиска тупиковых ситуаций или взаимоблокировок и реализует одну из принятых стратегий принудительного завершения транзакций для развязывания тупиковых ситуаций.
Особое внимание надо обратить на модуль поддержки SQL. Это практически транслятор с языка SQL и блок оптимизации запросов.
В общем, оптимизация запросов может быть разделена на синтаксическую и семантическую.
Методы синтаксической оптимизации запросов связаны с построением некоторой эквивалентной формы, называемой иногда канонической формой, которая требует меньших затрат на выполнение запроса, но дает результат, полностью эквивалентный исходному запросу.
К методам, используемым при синтаксической оптимизации запросов, относятся следующие.
Логические преобразования запросов. Прежде всего это относится к преобразованию предикатов, входящих в условие выборки. Предикаты, содержащие операции сравнения простых значений. Такой предикат имеет вид арифметическое выражение ОС арифметическое выражение, где ОС — операция сравнения, а арифметические выражения левой и правой частей в общем случае содержат имена полей отношений и константы (в языке SQL среди констант могут встречаться и имена переменных объемлющей программы, значения которых становятся известными только'при реальном выполнении запроса).
Канонические представления могут быть различными для предикатов разных типов. Если предикат включает только одно имя поля, то его каноническое представление может, например, иметь вид имя поля ОС константное арифметическое выражение (эта форма предиката — простой предикат селекции — очень полезна при выполнении следующего этапа оптимизации). Если начальное представление предиката имеет вид (n+12)*R.B OC 100 здесь n — переменная языка, R.B — имя столбца В отношения R, ОС - допустимая операция сравнения.
Каноническим представлением такого предиката может быть
R.В ОС 100/(n+12)
В этом случае мы один раз для заданного значения переменной п вычисляем выражение в скобках и правую часть операции сравнения 100/(n +12), а потом каждую строку можем сравнивать с полученным значением.
Если предикат включает в точности два имени поля разных отношений (или двух разных вхождений одного отношения), то его каноническое представление может иметь вид имя поля ОС арифметическое выражение, где арифметическое выражение в правой части включает только константы и второе имя ноля (это тоже форма, полезная дпя выполнения следующего шага оптимизации,
предикат соединения; особенно важен случай эквисоединения, когда ОС — это равенство).
Если в начальном представлении предикат имеет вид:
12*(Rl.A)-n*(R2.B) ОС m,
то его каноническое представление:
R1.A ОС (m+n*(R2.B)/12
В общем случае желательно приведение предиката к каноническому представлению вида арифметическое выражение ОС константное арифметическое выражение, где выражения правой и левой частей также приведены к каноническому представлению. В дальнейшем можно произвести поиск общих арифметических выражений в разных предикатах запроса. Это оправдано, поскольку при выполнении запроса вычисление арифметических выражений будет производиться при выборке каждого очередного кортежа, то есть потенциально большое число раз.
При приведении предикатов к каноническому представлению можно вычислять константные выражения и избавляться от логических отрицаний.Еще один класс логических преобразований связан с приведением к каноническому виду логического выражения, задающего условие выборки запроса. Как правило, используются либо дизъюнктивная, либо конъюнктивная нормальные формы. Выбор канонической формы зависит от общей организации оптимизатора.
При приведении логического условия к каноническому представлению можно производить поиск общих предикатов (они могут существовать изначально, могут появиться после приведения предикатов к каноническому виду или в процессе нормализации логического условия) и упрощать логическое выражение за счет, например, выявления конъюнкции взаимно противоречащих предикатов.
Преобразования запросов с изменением порядка реляционных операций. В традиционных оптимизаторах распространены логические преобразования, связанные с изменением порядка выполнения реляционных операций.
Например, имеем следующий запрос:
R1 NATURAL JOIN R2
WHERE R1.A ОС a AND R2.B С b
Здесь а и b некоторые константы, которые ограничивают значение атрибутов отношений R1 и R2.
Если мы его рассмотрим в терминах реляционной алгебры, то это естественное соединение отношений R1 и R2, в которых заданы внутренние ограничения на кортежи каждого отношения.
Для уменьшения числа соединяемых кортежей резоннее сначала произвести операции выборки на каждом отношении и только после этого перейти в операции естественного соединения. Предикат соединения; особенно важен случай зквисоединения, когда ОС – это равенство). Если в начальном представлении предикат имеет вид:
12*(Rl.A)-n*(R2.B) ОС m,
то его каноническое представление:
R1.A ОС (m+n*(R2.B)/12
В общем случае желательно приведение предиката к каноническому представлению вида арифметическое выражение ОС константное арифметическое выражение, где выражения правой и левой частей также приведены к каноническому представлению. В дальнейшем можно произвести поиск общих арифметических выражений в разных предикатах запроса. Это оправдано, поскольку при выполнении запроса вычисление арифметических выражений будет производиться при выборке каждого очередного кортежа, то есть потенциально большое число раз.
При приведении предикатов к каноническому представлению можно вычислять константные выражения и избавляться от логических отрицаний.
Еще один класс логических преобразовании связан с приведением к каноническому виду логического выражения, задающего условие выборки запроса. Как правило, используются либо дизъюнктивная, либо конъюнктивная нормальные формы. Выбор канонической формы зависит от общей организации оптимизатора.
При приведении логического условия к каноническому представлению можно производить поиск общих предикатов (они могут существовать изначально, могут появиться после приведения предикатов к каноническому виду или в процессе нормализации логического условия) и упрощать логическое выражение за счет, например, выявления конъюнкции взаимно противоречащих предикатов.
Преобразования запросов с изменением порядка реляционных операций. В традиционных оптимизаторах распространены логические преобразования, связанные с изменением порядка выполнения реляционных операций.
Например, имеем следующий запрос:
Rl NATURAL JOIN R2 WHERE R1.A ОС a AND R2.B С b
Здесь а и b некоторые константы, которые ограничивают значение атрибутов отношений R1 и R2.
Если мы его рассмотрим в терминах реляционной алгебры, то это стественное соединение отношений R1 и R2, в которых заданы внутренние ограничения на кортежи каждого отношения.
Для уменьшения числа соединяемых кортежей резоннее сначала произвести операции выборки на каждом отношении и только после этого перейти в операции естественного соединения.
Поэтому данный запрос будет эквивалентен следующей последовательности операций реляционной алгебры:
R3 =.R1[R1.A ОС а] R4 = R2[R2.B С b] R5 = R3*[ ]*R4
Хотя немногие реляционные системы имеют языки запросов, основанные в чистом виде на реляционной алгебре, правила преобразований алгебраических выражений могут быть полезны и в других случаях. Довольно часто реляционная алгебра используется в качестве основы внутреннего представления запроса. Естественно, что после этого можно выполнять и алгебраические преобразования.
В частности, существуют подходы, связанные с преобразованием запросов на языке SQL к алгебраической форме. Особенно важно то, что реляционная алгебра более проста, чем язык SQL. Преобразование запроса к алгебраической форме упрощает дальнейшие действия оптимизатора по выборке оптимальных планов. Вообще говоря, развитый оптимизатор запросов системы, ориентированной на SQL, должен выявить все возможные планы выполнения любого запроса, но «пространство поиска» этих планов в общем случае очень велико; в каждом конкретном оптимизаторе используются свои эвристики для сокращения пространства поиска. Некоторые, возможно, наиболее оптимальные планы никогда не будут рассматриваться. Разумное преобразование запроса на SQL к алгебраическому представлению сокращает пространство поиска планов выполнения запроса с гарантией того, что оптимальные планы потеряны не будут.
Приведение запросов с вложенными подзапросами к запросам с соединениями. Основным отличием языка SQL от языка реляционной алгебры является возможность использовать в логическом условии выборки предикаты, содержащие вложенные подзапросы. Глубина вложенности не ограничивается языком, то есть, вообще говоря, может быть произвольной. Предикаты с вложенными подзапросами при наличии общего синтаксиса могут обладать весьма различной семантикой. Единственным общим для всех возможных семантик вложенных подзапросов алгоритмом выполнения запроса является вычисление вложенного подзапроса всякий раз при вычислении значения предиката. Поэтому естественно стремиться к такому преобразованию запроса, содержащего предикаты со вложенными подзапросами, которое сделает семантику подзапроса более явной, предоставив тем самым в дальнейшем оптимизатору возможность выбрать способ выполнения запроса, наиболее точно соответствующий семантике подзапроса.
Каноническим представлением запроса на п отношениях называется запрос, содержащий n-1 предикат соединения и не содержащий предикатов с вложенными подзапросами. Фактически каноническая форма — это алгебраическое представление запроса.
Например, запрос с вложенным подзапросом:
(SELECT Rl.A FROM Rl
WHERE Rl.B IN
(SELECT R2.B FROM R2 WHERE Rl.C = R2.D))
эквивалентен
SELECT Rl.A FROM Rl. R2
WHERE Rl.A = R2.B AND Rl.C = R2.D
Второй запрос:
(SELECT Rl.A FROM Rl WHERE Rl.K =
(SELECT AVG (R2.B) FROM R2 WHERE Rl.C = R2.D)
или
(SELECT Rl.A FROM Rl. R3
WHERE Rl.C = R3.D AND Rl.K = R3.L)
R3 = SELECT R2.D, L AVG (R2.B)
FROM R2
GROUP BY R2.D
При использовании подобного подхода в оптимизаторе запросов не обязательно производить формальные преобразования запросов. Оптимизатор должен в большей степени использовать семантику обрабатываемого запроса, а каким образом она будет распознаваться — это вопрос техники.
Семантические методы оптимизации основаны как раз на учете семантики конкретной БД. Таких методов в различных реализациях может быть множество, мы с вами коснемся лишь некоторых из них.
Преобразование запросов с учетом семантической информации. Это прежде всего относится к запросам, которые выполняются над представлениями. Само представление представляет собой запрос. В БД представление хранится в виде скомпилированного плана выполнения запроса, то есть в нем в некоторой канонической форме представлены уже все предикаты и сам план выполнения запроса. При преобразовании внешнего запроса производится объединение внешнего запроса с внутренней формой запроса, составляющего основу представления, и строится обобщенная каноническая форма, объединяющая оба запроса. Для этой попой формы проводится анализ и преобразование предикатов. Поэтому при выполнении запроса над представлением будет выполнено не два, а только один запрос, оптимизированный по обобщенным параметрам запроса.
Использование ограничений целостности при анализе запросов. Ограничения целостности связаны с условиями, которые накладываются на значения столбцов таблицы. При выполнении запросов над таблицами условия запросов объединяются специальным образом с условиями ограничений таблицы и полученные обобщенные предикаты уже анализируются. Допустим, что мы ищем в нашей библиотеке читателей с возрастом более 100 лет, но если у нас есть ограничение, заданное для таблицы READERS, которое ограничивает дату рождения наших читателей, так чтобы читатель имел дату рождения в пределах от 17 до 100 лет включительно. Поэтому оптимизатор запроса, сопоставив два эти предиката, может сразу определить, что результатом запроса будет пустое множество.
После оптимизации запрос имеет непроцедурный вид, то есть в нем не определен жесткий порядок выполнения элементарных операций над исходными объектами. На следующем этане строятся все возможные планы выполнения запросов и для каждого из них производятся стоимостные оценки. Оценка планов выполнения запроса основана на анализе текущих объемов данных, хранящихся в отношениях БД, и на статистическом анализе хранимой информации. В большинстве СУБД ведется учет диапазона значений отдельного столбца с указанием процентного содержания для каждого диапазона. Поэтому при построении плана запроса СУБД может оценить объем промежуточных отношений и построить план таким образом, чтобы на наиболее ранних этапах выполнения запроса минимизировать количество строк, включаемых в промежуточные отношения.
Кроме ядра СУБД каждый поставщик обеспечивает специальные инструментальные средства, облегчающие администрирование БД и разработку новых проектов БД и пользовательских приложений для данного сервера. В последнее время практически все утилиты и инструментальные средства имеют развитый графический интерфейс.
1.12. Перспективы развития СУБД
Взаимодействия Web-технологии и баз данных (содержание данного пункта скопировано из работы [19]). Дизайнеры крупнейших Web-серверов постепенно перекладывают задачи управления страницами с файловых систем на системы баз данных. Системы баз данных используются в качестве серверов электронной коммерции, помогая отслеживать профили, транзакции, счета и инвентарные листы. Web-издатели примериваются к использованию систем баз данных для хранения информационного наполнения, имеющего сложную природу. Однако в подавляющей части Web-узлов, особенно в тех, которые принадлежат провайдерам и держателям поисковых машин, технология баз данных не применяется. В небольших Web-узлах, как правило, используются статические HTML-страницы, хранящиеся в обычных файловых системах.
В будущем статические HTML-страницы все чаще станут заменять системами управления динамически формируемым содержимым. Уже сейчас, например, торговцы по каталогам не просто преобразуют бумажные каталоги в наборы статических HTML-страниц. Фактически они представляют электронный каталог, позволяющий заказчикам оперативно узнать то, что их интересует, не пролистывая ненужную информацию.
HTML расширяется до XML, языка расширяемой разметки, который лучше описывает структурированные данные. XML стимулирует использование кэшей (наборов) данных на стороне клиента с поддержкой обновлений, что заставляет разработчиков погружаться в трясину проблем распределенных транзакций.
Авторы Web-публикаций нуждаются в инструментах для быстрого и экономичного построения хранилищ данных, рассчитанных на сложные приложения. Это, в свою очередь, формирует требования к технологии баз данных для создания, управления, поиска и обеспечения безопасности содержимого Web-узлов.
Универсальность Web-клиента становится весьма привлекательной для разработчиков несложных приложений, которые смогут работать с базами данных. В этом случае не требуется установка каждого клиента, достаточно выслать код доступа и клиент автоматически может уже работать с базой данных, при этом вам все равно, где находится клиент, он может работать как в локальной, так и, в глобальной сети, если технология это позволяет.
Подобные системы называются системами, разработанными по интранет-технологии, то есть технологии, использующей принципы технологий Интернета, но реализованные во внутренней локальной сети.
Для разработки Интернет-приложений, которые связаны с базами данных, широко используются новые средства программирования: это язык PERL язык PHP (Personal Home Page Tools), язык JavaScript и ряд других.
Темпоральные базы данных чувствительные ко времени. Фактически БД моделирует состояние объектов предметной области в некоторый текущий момент времени. Однако в ряде прикладных областей необходимо исследовать именно изменение состояний объектов во времени. Если использовать чисто реляционную модель, то требуется строить и хранить дополнительно множество отношений, имеющих одинаковые схемы, отличающиеся временем существования или снятия данных. Гораздо перспективнее и удобнее для этого использовать специальные механизмы снятия срезов по времени для определенных объектов БД. Основной тезис темпоральных систем состоит в том, что для любого объекта данных, созданного в момент времени t1 и уничтоженного в момент времени t2, в БД сохраняются (и доступны пользователям) все его состояния во временном интервале (t1,t2). При обозначении интервала квадратные скобки означают, что граница интервала включена в него, а круглые скобки означают, что точка на временной оси, соответствующая границе интервала, не включается в интервал. И действительно, если объект уничтожен в момент времени t2, то в этой точке временной оси он уже не существует, поэтому мы оставляем правую границу временного интервала открытой.
Новые модели представления данных: СУБД, поддерживающие несколько моделей с разнообразными данными (двоичная, текстовая, графическая, аудио‑ и видеоинформация, гиперссылки) и видами обработки (обучение, телеконференции и др.).
Новые архитектуры: организация нового уровня носителей ‑ “третичной памяти” в виде стека сменяемых МД или МЛ: буферная система VSM (Virtual Storage Manager ‑ менеджер виртуальной памяти) корпорации Storage Tek и система CD Storage System корпорации Compaq Computer на компакт‑дисках, управляемых как одним логическим диском.
Новые области применения: обработка сверхбольших объемов информации (база данных системы наблюдения земли EOS (Earth Observing System), распределенная обработка информации в разнородных сетях (поиск и отбор данных в Internet и др.).
Качество сервиса: управление метаданными (объектно‑ориентированные репозитарии с готовыми компонентами общего пользования), длительная безостановочная работа, обслуживание (копирование, реорганизация, модернизация программ, ОС, компьютера) в “горячем” режиме с совмещением работы с пользователем, ведение БД на портативном компьютере с синхронизацией данных с БД на сервере (Access, Oracle Lite).
 Вопросы для самопроверки и контроля
Вопросы для самопроверки и контроля
|
|
|
|
|
Дата добавления: 2014-12-10; Просмотров: 668; Нарушение авторских прав?; Мы поможем в написании вашей работы!