КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Распределенная файловая система Google File System (GFS)
|
|
|
|
Google File System (GFS) – распределенная файловая система, используемая компанией Google в качестве основы проприентарной, то есть не распространяемой, СУБД BigTable (содержание данного пункта является полной копией работы http://bourabai.kz/dbt/google/GFS.htm). GFS — кластерная система, оптимизированная для центрального хранилища данных Google и нужд поискового механизма, обладающая повышенной защитой от сбоев.
Система предназначена для взаимодействия между вычислительными системами, а не между пользователем и вычислительной системой. Вся информация копируется и хранится в трёх (или более) местах одновременно, при этом система способна очень быстро находить реплицированные копии, если какая-то машина вышла из строя. Задачи автоматического восстановления после сбоя решаются с помощью программ, созданных по модели MapReduce. Является коммерческой тайной компании Google. Она несовместима с POSIX и создавалась Google для своих внутренних потребностей. В GFS файлы делятся на блоки данных по 64 МБ (англ. chunk — кусок). Предполагается, что файлы очень редко переписываются или уменьшаются в размере хранимых данных, а лишь читаются или увеличиваются в размере, посредством добавления в конец новых данных.
Идеология файловой системы GFS (Google File System)
В настоящее время, в условиях роста информации, возникают задачи хранения и обработки данных очень большого объема. Поэтому эти данные обрабатывается сразу на нескольких серверах одновременно, которые образуют кластеры. Для упрощения работы с данными на кластерах и разрабатывают распределенные файловые системы. Мы подробно рассмотрим пример распределенной файловой системы Google File System, используемую компанией Google.
GFS является наиболее, наверное, известной распределенной файловой системой. Надежное масштабируемое хранение данных крайне необходимо для любого приложения, работающего с таким большим массивом данных, как все документы в интернете. GFS является основной платформой хранения информации в Google. GFS - большая распределенная файловая система, способная хранить и обрабатывать огромные объемы информации.
GFS строилась исходя из следующим критериев:
1. Система строится из большого количества обыкновенного недорого оборудования, которое часто дает сбои. Должны существовать мониторинг сбоев, и возможность в случае отказа какого-либо оборудования восстановить функционирование системы.
2. Система должна хранить много больших файлов. Как правило, несколько миллионов файлов, каждый от 100 Мб и больше. Также часто приходится иметь дело с многогигабайтными файлами, которые также должны эффективно храниться. Маленькие файлы тоже должны храниться, но для них не оптимизируется работа системы.
3. Как правило, встречаются два вида чтения: чтение большого последовательного фрагмента данных и чтение маленького объема произвольных данных. При чтении большого потока данных обычным делом является запрос фрагмента размером в 1Мб и больше. Такие последовательные операции от одного клиента часто читают подряд идущие куски одного и того же файла. Чтение небольшого размера данных, как правило, имеет объем в несколько килобайт. Приложения, критические по времени исполнения, должны накопить определенное количество таких запросов и отсортировать их по смещению от начала файла. Это позволит избежать при чтении блужданий вида назад-вперед.
4. Часто встречаются операции записи большого последовательного куска данных, который необходимо дописать в файл. Обычно, объемы данных для записи такого же порядка, что и для чтения. Записи небольших объемов, но в произвольные места файла, как правило, выполняются неэффективно.
5. Система должна реализовывать строго очерченную семантику параллельной работы нескольких клиентов, в случае если они одновременно пытаются дописать данные в один и тот же файл. При этом может случиться так, что поступят одновременно сотни запросов на запись в один файл. Для того чтобы справится с этим, используется атомарность операций добавления данных в файл, с некоторой синхронизацией. То есть если поступит запрос на операцию чтения, то он будет выполняться, либо до очередной операции записи, либо после.
6. Высокая пропускная способность является более предпочтительной, чем маленькая задержка. Так, большинство приложений в Google отдают предпочтение работе с большими объемами данных, на высокой скорости, а выполнение отдельно взятой операции чтения и записи, вообще говоря, может быть растянуто.
Архитектура файловой системы GFS
Файлы в GFS организованы иерархически, при помощи каталогов, как и в любой другой файловой системе, и идентифицируются своим путем (рисунок 6.10.1). С файлами в GFS можно выполнять обычные операции: создание, удаление, открытие, закрытие, чтение и запись.
Более того, GFS поддерживает резервные копии, или снимки (snapshot). Можно создавать такие резервные копии для файлов или дерева директорий, причем с небольшими затратами.

Рисунок 6.10.1 – Архитектура файловой системы GFS
В системе существуют мастер-сервера и чанк-сервера, собственно, хранящие данные. Как правило, GFS кластер состоит из одной главной машины мастера (master) и множества машин, хранящих фрагменты файлов чанк-серверы (chunkservers). Клиенты имеют доступ ко всем этим машинам. Файлы в GFS разбиваются на куски - чанки (chunk, можно сказать фрагмент). Чанк имеет фиксированный размер, который может настраиваться. Каждый такой чанк имеет уникальный и глобальный 64 - битный ключ, который выдается мастером при создании чанка. Чанк-серверы хранят чанки, как обычные Linux файлы, на локальном жестком диске.
Для надежности каждый чанк может реплицироваться на другие чанк-серверы. Обычно используются три реплики.
Мастер отвечает за работу с метаданными всей файловой системы. Метаданные включают в себя пространства имен, информацию о контроле доступа к данным, отображение файлов в чанки, и текущее положение чанков. Также мастер контролирует всю глобальную деятельность системы такую, как управление свободными чанками, сборка мусора (сбор более ненужных чанков) и перемещение чанков между чанк-серверами. Мастер постоянно обменивается сообщениями (HeartBeat messages) с чанк-серверами, чтобы отдать инструкции, и определить их состояние (узнать, живы ли еще).
Клиент взаимодействует с мастером только для выполнения операций, связанных с метаданными. Все операции с самими данными производятся напрямую с чанк-серверами. GFS - система не поддерживает POSIX API, так что разработчикам не пришлось связываться с VNode уровнем Linux.
Разработчики не используют кеширование данных, правда, клиенты кешируют метаданные. На чанк-серверах операционная система Linux и так кеширует наиболее используемые блоки в памяти. Вообще, отказ от кеширования позволяет не думать о проблеме валидности кеша (cache coherence).
Мастер
Использование одного мастера существенно упрощает архитектуру системы. Позволяет производить сложные перемещения чанков, организовывать репликации, используя глобальные данные. Казалось бы, что наличие только одного мастера должно являться узким местом системы, но это не так. Клиенты никогда не читают и не пишут данные через мастера. Вместо этого они спрашивают у мастера, с каким чанк-сервером они должны контактировать, а далее они общаются с чанк-серверами напрямую.
Рассмотрим, как происходит чтение данных клиентом. Сначала, зная размер чанка, имя файла и смещение относительно начала файла, клиент определяет номер чанка внутри файла. Затем он шлет запрос мастеру, содержащий имя файла и номер чанка в этом файле. Мастер выдает чанк-серверы, по одному в каждой реплике, которые хранят нужный нам чанк. Также мастер выдает клиенту идентификатор чанка.
Затем клиент решает, какая из реплик ему нравится больше (как правило та, которая ближе), и шлет запрос, состоящий из чанка и смещения относительно начала чанка. Дальнейшее чтения данных, не требует вмешательства мастера. На практике, как правило, клиент в один запрос на чтение включает сразу несколько чанков, и мастер дает координаты каждого из чанков в одном ответе.
Размер чанка является важной характеристикой системы. Как правило, он устанавливается равным 64 мегабайт, что гораздо больше, чем размер блока в обычной файловой системе. Понятно, что если необходимо хранить много файлов, размеры которых меньше размера чанка, то будем расходоваться много лишней памяти. Но выбор такого большого размера чанка обусловлен задачами, которые приходится компании Google решать на своих кластерах. Как правило, что-то считать приходится для всех документов в интернете, и поэтому файлы в этих задачах очень большого размера.
Метаданные
Мастер хранит три важных вида метаданных: пространства имен файлов и чанков, отображение файла в чанки и положение реплик чанков. Все метаданные хранятся в памяти мастера. Так как метаданные хранятся в памяти, операции мастера выполняются быстро. Состояние дел в системе мастер узнает просто и эффективно. Он выполняется сканирование чанк-серверов в фоновом режиме. Эти периодические сканирования используются для сборки мусора, дополнительных репликаций, в случае обнаружения недоступного чанк-сервера и перемещение чанков, для балансировки нагрузки и свободного места на жестких дисках чанк-серверов.
Мастер отслеживает положение чанков. При старте чанк-сервера мастер запоминает его чанки. В процессе работы мастер контролирует все перемещения чанков и состояния чанк-серверов. Таким образом, он обладает всей информацией о положении каждого чанка.
Важная часть метаданных - это лог операций. Мастер хранит последовательность операций критических изменений метаданных. По этим отметкам в логе операций, определяется логическое время системы.
Именно это логическое время определяет версии файлов и чанков.
Так как лог операций важная часть, то он должен надежно храниться, и все изменения в нем должны становиться видимыми для клиентов, только когда изменятся метаданные. Лог операций реплицируется на несколько удаленных машин, и система реагирует на клиентскую операцию, только после сохранения этого лога на диск мастера и диски удаленных машин.
Мастер восстанавливает состояние системы, исполняя лог операций. Лог операций сохраняет относительно небольшой размер, сохраняя только последние операции. В процессе работы мастер создает контрольные точки, когда размер лога превосходит некоторой величины, и восстановить систему можно только до ближайшей контрольной точки. Далее по логу можно заново воспроизвести некоторые операции, таким образом, система может откатываться до точки, которая находится между последней контрольной точкой и текущем временем.
Взаимодействия внутри системы
Выше была описана архитектура системы, которая минимизирует вмешательства мастера в выполнение операций. Теперь же рассмотрим, как взаимодействуют клиент, мастер и чанк-серверы для перемещения данных, выполнения атомарных операций записи, и создания резервной копии (snapshot).
Каждое изменение чанка должно дублироваться на всех репликах и изменять метаданные. В GFS мастер дает чанк во владение (lease) одному из серверов, хранящих этот чанк. Такой сервер называется первичной (primary) репликой. Остальные реплики объявляются вторичными (secondary). Первичная реплика собирает последовательные изменения чанка, и все реплики следуют этой последовательности, когда эти изменения происходят.
Механизм владения чанком устроен таким образом, чтобы минимизировать нагрузку на мастера. При выделении памяти сначала выжидается 60 секунд. А затем, если потребуется первичная реплика может запросить мастера на расширение этого интервала и, как правило, получает положительный ответ. В течение этого выжидаемого периода мастер может отменить изменения.
Рассмотрим подробно процесс записи данных. Он изображен по шагам на рисунке 6.10.2, при этом тонким линиям соответствуют потоки управления, а жирным потоки данных.
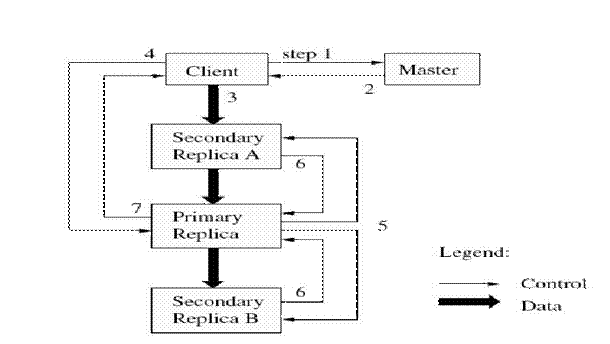
Рисунок 6.10.2 –Процесс записи данных
1. Клиент спрашивает мастера, какой из чанк-серверов владеет чанком, и где находится этот чанк в других репликах. Если необходимо, то мастер отдает чанк кому-то во владение.
2. Мастер в ответ выдает первичную реплику, и остальные (вторичные) реплики. Клиент хранит эти данные для дальнейших действий. Теперь, общение с мастером клиенту может понадобиться только, если первичная реплика станет недоступной.
3. Далее клиент отсылает данные во все реплики. Он может это делать в произвольном порядке. Каждый чанк-сервер будет их хранить в специальном буфере, пока они не понадобятся или не устареют.
4. Когда все реплики примут эти данные, клиент посылает запрос на запись первичной реплике. В этом запросе содержатся идентификация данных, которые были посланы в шаге 3. Теперь первичная реплика устанавливает порядок, в котором должны выполняться все изменения, которые она получила, возможно от нескольких клиентов параллельно. И затем, выполняет эти изменения локально в этом определенном порядке.
5. Первичная реплика пересылает запрос на запись всем вторичным репликам. Каждая вторичная реплика выполняет эти изменения в порядке, определенном первичной репликой.
6. Вторичные реплики рапортуют об успешном выполнении этих операций.
7. Первичная реплика шлет ответ клиенту. Любые ошибки, возникшие в какой-либо реплике, также отсылаются клиенту. Если ошибка возникла при записи в первичной реплике, то и запись во вторичные реплики не происходит, иначе запись произошла в первичной реплике, и подмножестве вторичных. В этом случае клиент обрабатывает ошибку и решает, что ему дальше с ней делать.
Из примера выше видно, что создатели разделили поток данных и поток управления. Если поток управления идет только в первичную реплику, то поток данных идет во все реплики. Это сделано, чтобы избежать создания узких мест в сети, а взамен широко использовать пропускную способность каждой машины. Так же, чтобы избежать узких мест и перегруженных связей, используется схема передачи ближайшему соседу по сетевой топологии. Допустим, что клиент передает данные чанк-серверам S1,..., S4. Клиент шлет ближайшему серверу данные, пусть S1. Он далее пересылает ближайшему серверу, пусть будет S2.
Далее S2 пересылает их ближайшему S3 или S4, и так далее.
Также задержка минимизируется за счет использования конвейеризации пакетов передаваемых данных по TCP. То есть, как только чанк-сервер получил какую-то часть данных, он немедленно начинает их пересылать. Без сетевых заторов, идеальное время рассылки данных объемом B байт на R реплик будет B/T + RL, где T сетевая пропускная способность, а L - задержка при пересылке одного байта между двумя машинами.
GFS поддерживает такую операцию, как атомарное добавление данных в файл.
Обычно, при записи каких-то данных в файл, мы указываем эти данные и смещение. Если несколько клиентов производят подобную операцию, то эти операции нельзя переставлять местами (это может привести к некорректной работе). Если же мы просто хотим дописать данные в файл, то в этом случае мы указываем только сами данные. GFS добавит их атомарной операцией. Вообще говоря, если операция не выполнилась на одной из вторичных реплик, то GFS, вернет ошибку, а данные будут на разных репликах различны.
Еще одна интересная вещь в GFS - это резервные копии (еще можно сказать мгновенный снимок) файла или дерева директорий, которые создаются почти мгновенно, при этом, почти не прерывая выполняющиеся операции в системе. Это получается за счет технологии похожей на сopy on write. Пользователи используют эту возможность для создания веток данных или как промежуточную точку, для начала каких-то экспериментов.
|
|
|
|
|
Дата добавления: 2014-12-10; Просмотров: 698; Нарушение авторских прав?; Мы поможем в написании вашей работы!