КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Организация ввода-вывода информации
|
|
|
|
Подсистема ввода-вывода
Подсистема ввода-вывода служит для организации связи и взаимодействия ЭВМ с внешним миром. Производительность ЭВМ определяется не только процессором и оперативной памятью, но и составом устройств ввода-вывода информации и способом организации их совместной работы.
Связь устройств ЭВМ друг с другом осуществляется с помощью сопряжений (интерфейсов). Интерфейс - это совокупность средств, стандартов, сигналов, обеспечивающая обмен данными между устройствами ЭВМ.
Устройства ввода-вывода (УВВ) совместно с внешними запоминающими устройствами образуют периферийные устройства.
При разработке систем ввода-вывода должны быть решены следующие проблемы:
1. Обеспечена возможность реализации ЭВМ с переменным составом оборудования.
2. Обеспечена параллельная во времени работа процессора над программой и выполнение процедур ввода-вывода.
3. Обеспечена независимость программирования ввода-вывода от особенностей УВВ.
4. Обеспечена автоматическая реакция ЭВМ на готовность УВВ, отсутствие УВВ, нарушения нормальной работы.
Перечисленные проблемы решаются на основе модульности, т.е. выполнения отдельных узлов в виде конструктивно законченных модулей, унификации, т.е. использования не зависящих от типа УВВ форматов данных, унифицированных интерфейсов и набора команд.
Принципы и структуры систем ввода-вывода строятся на основе архитектуры ЭВМ.
Иерархическая архитектура.
В этом случае центральный процессор соединяется с внешними устройствами через вспомогательные процессоры, называемые каналами ввода-вывода. Каналы ввода-вывода нужны для того, чтобы обмен между ЭВМ и ПУ производился одновременно с выполнением основной программы. Управление обменом сводится к следующим действиям: 1) выработка сигнала начала обмена, 2) выработка управляющей информации, необходимой для подготовки к обмену, 3) последовательное формирование адресов ОЗУ, 4) выработка сигналов, управляющих чтением или записью, 5) выработка сигналов об окончании обмена.
Функция процессора в данной системе – инициирует операции ввода-вывода, задает номера каналов и ПУ, указывает адреса начала программы канала.
Функции каналов
- обеспечение прямого доступа в память
- задание размера массивов;
- формирование адресов ячеек основной памяти, используемых в передаче;
- определение момента завершения передачи массивов данных;
- формирование запросов прерываний.
Начало обмена определяется моментом, когда ПУ готово к приему или выдаче информации. Команды ЭВМ должны обеспечивать организацию обмена в момент, предусмотренный программой. Основная информация о задаваемом обмене записывается в командах канала, называемых управляющими словами обмена. Непосредственно в команду ЭВМ записывается номер ПУ, с которым назначен обмен, номер канала и адрес команды канала.
Типы каналов
Способ организации взаимодействия ПУ с каналом определяется соотношением быстродействия ПУ, которые делятся на быстродействующие (дисковая память ВЗУ) и медленнодействующие (печатающие устройства).
Для обслуживания быстрых устройств применяется селекторный канал, показанный на рис.2.3.1
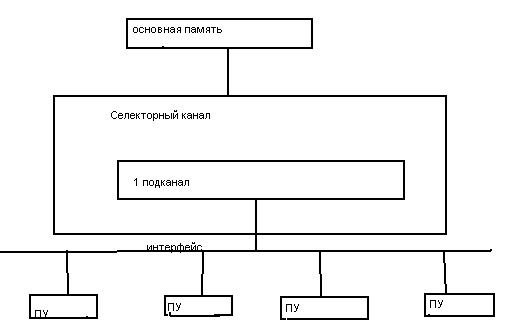
Рис.2.3.1 Селекторный канал
Селекторный канал обслуживает одно периферийное устройство и связан с ним до окончания операции обмена. В это время запросы от других ПУ не воспринимаются. Все функции, выполняемые каналом, определяются управляющим словом канала, которое выбирается один раз в начале операции обмена и содержится в памяти канала до окончания всех предписанных действий.
Для обслуживания медленных устройств применяется мультиплексный канал, который обслуживает несколько параллельно работающих ПУ в режиме разделения времени. При этом, каждое ПУ связывается с каналом на короткие промежутки времени (сеансы) только после того, как ПУ подготовлено к работе. Во время сеанса передается 1 или несколько байт. Если несколько ПУ подготовились к работе, то канал выбирает одно из них, остальные ожидают своей очереди. Аппаратные средства условно разделяются на две части: подканалы (предназначенные для обслуживания отдельных ПУ) и общее оборудование, представленные на рис.2.3.2.
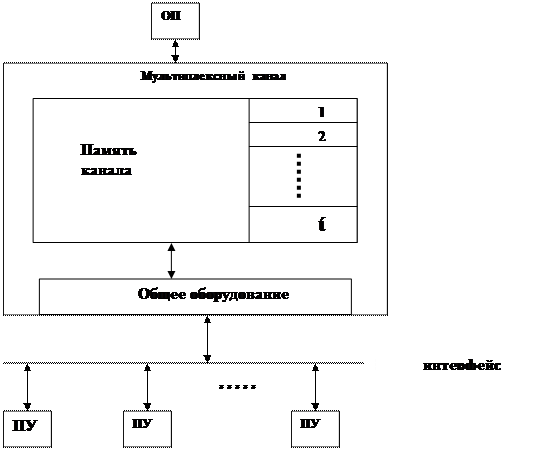
Рис.2.3.2. Мультиплексный канал
Физически подканал реализуется в виде участка памяти, в котором хранятся параметры операции ввода-вывода. Общее оборудование представляет набор триггерных регистров и схем, осуществляющих обмен с основной памятью и ПУ.
Магистральная архитектура.
Это структура с общей шиной, к которой присоединяются все модули ЭВМ. В каждый данный момент времени через общую шину может происходить обмен данными только между одной парой присоединенных к ней модулей. Таким образом, модули ЭВМ разделяют во времени один общий интерфейс, а процессор выступает как один из модулей. ПУ присоединяются к общей шине через контроллер, который согласовывает формат данных шины и ПУ.
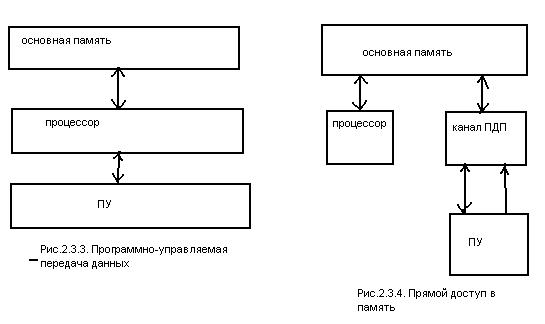
Если операции ввода-вывода производятся для отдельных байт или слов, то используется программно-управляемая передача данных, при которой обмен происходит под управлением процессора. (рис.2.3.3)
Если применяется поблочная передача данных, то используется прямой доступ в память, как более быстрый режим, при котором процессор отключается от шин адреса и данных и не принимает участия в процессе обмена.(Рис.2.3.4)
Интерфейсы
Интерфейс – это совокупность линий и шин, сигналов, электронных схем и алгоритмов, предназначенная для осуществления обмена информацией между устройствами. Это означает, что интерфейс – это не просто набор проводников для связи между устройствами, а целый комплекс технических средств.
По способу соединения компонентов интерфейсы делятся на магистральные, радиальные, цепочные и комбинированные.
По способу передачи информации интерфейсы подразделяются на параллельные, последовательные, параллельно-последовательные.
По принципу обмена информацией интерфейсы бывают синхронные и асинхронные.
По режиму передачи информации интерфейсы делятся на односторонние, двухсторонние, двухсторонние поочередные.
По функциональному назначению интерфейсы делятся на основные классы: 1) системные интерфейсы ЭВМ, 2) интерфейсы периферийного оборудования.
Мы уже говорили, что современные ПК построены по архитектуре магистральной, т.е. архитектуре с общей шиной, которая физически включает два типа шин: системную шину и шины ввода-вывода.
Системная шина соединяет процессор с ОЗУ и кэш-памятью 2 уровня. В процессорах Pentium MMX применена двойная независимая шина. При этой архитектуре системная шина физически разделена на две: первичная шина FSB, связывающая процессор с ОЗУ, и ОЗУ с периферийными устройствами, и вторичная шина BSB для связи с кэш-памятью. Использование двойной независимой шины повышает производительность за счет возможности процессору обращаться параллельно к различным уровням памяти.
Шины ввода-вывода соединяют процессор с различными ПУ. ПУ соединяются с системной шиной посредством моста, встроенного в набор микросхем (чипсет), который поддерживает функционирование процессора.
Внутренние интерфейсы.
Основные характеристики внутренних интерфейсов представлены в таблице 2.3.1
| стандарт | Типичное применение | Пропускная способность |
| ISA | Звуковые карты, модемы | 2 Мбит/с - 8,33 Мбит/с |
| PCI | Графические карты, адаптеры, звуковые карты новых поколений | 133Мбит/сек (32 битовая шина с частотой 33 МГц) |
| PCI-X | ------------«--------------- | 1 Гбит/сек (64 битовая шина с частотой 133 МГц) |
| PCI Express | --------------«--------------- | До 16 Гбит/сек |
| AGP | Графические карты | 528 Мбит/сек, 2хграфика |
| AGP PRO | 3D-графика | 800 Мбит/сек (4х графика) |
Шина ISA стандартная шина формата АТ имеет 16 бит данных и 24 бита адреса, 8 каналов прямого доступа в память (DMA), тактовую частоту 8/16 МГц, пропускную способность 8/16 Мбайт/сек. Максимальная скорость передачи данных составляет (8 МГц*16 бит=128 Мбит/сек/2, т.к. передача требует от 2 до 8 тактов=64 Мбит/сек=8 Мбайт/сек)
В таком виде шина ISA существует и поныне как самая распространенная шина для периферийных адаптеров (адаптер- -устройство сопряжения, иногда называется картой или контроллером). Эта шина используется в современных ПК в сочетании с шиной PCI.
Шина PCI (ее еще называют локальной шиной) – шина соединения периферийных компонентов. Она занимает особое место, являясь мостом между системной шиной процессора и шиной ввода-вывода. Шина PCI разрабатывалась для процессора Pentium, но сейчас она хорошо сочетается и с другими процессорами, поэтому ее приняли как стандартизованную высокопроизводительную шину расширения ввода-вывода. Частота шины 33 МГц, модификация PCI 2.1 допускает частоту 66 МГц. Теоретически максимальная скорость 264 Мбайт/сек при 33 МГц. Разъем (слот) достаточен для подключения адаптера, на системной плате он может существовать с любой из шин ввода-вывода.
Не считая AGP шина PCI является самой высокоскоростной шиной расширения (ввода-вывода) современных ПК. На одной шине может быть не более 4 устройств (слотов). Мост шины – это аппаратные средства подключения шины PCI к другим шинам. Главный мост используется для подключения PCI к шине процессора. Одноранговый мост используется для соединения двух шин PCI.
Известны более похдние разновидности PCI-X и PCI Express. Эти шины позволяют подключать расширители памяти, контроллеры дисков, сетевые адаптеры. У них увеличена скорость и количество подключаемых устройств. Шина PCI Express может заменить шину AGP и является последовательной шиной. Несмотря на разрядность и скорость шины PCI передача графической информации превышает ее возможности.
AGP – порт ускоренного графического ввода позволяет решить эту проблему. Схемы AGP взаимодействуют непосредственно с 4 источниками информации: процессор, оперативная память, графическая карта, шина PCI. Схема взаимодействия представлена на рис.2.3.5.
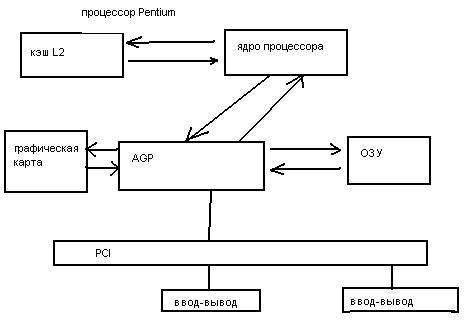
Рис.2.3.5. Схема взаимодействия с использованием AGP.
AGP функционирует на скорости процессорной шины, что позволяет достичь пиковой пропускной способности в 264 Мбит/сек. В графических картах передача происходит как по переднему, так и по заднему фронту тактовых импульсов процессора, что позволяет при частоте 133 МГц осуществлять передачу со скоростью до 528 Мбит/сек (2х графика). В дальнейшем была выпущена версия AGP 2.0, которая поддерживала 4х графику, т.е. четырехкратную передачу за один такт.
Интерфейсы периферийных устройств.
IDE – интерфейс устройств со встроенным контроллером. При его создании разработчики ориентировались на подключение дискового накопителя. Чтобы подключить дисковый накопитель, необходимо, чтобы компьютер взаимодействовал с контроллером, контроллер оперировал данными и контроллер взаимодействовал с дисковым накопителем. До недавнего времени большая часть этих проблем решалась контроллерами и компьютером, поэтому при замене накопителя приходилось обеспечить полную совместимость контроллера с новым жестким диском. Теперь в стандарте контроллеров IDE основные функции выполняют эти контроллеры на плате дисковода. Поэтому упростилась электроника внутри компьютера. IDE имеет скорость передачи данных до 3 Мбайт/сек. Наиболее распространенной модификацией IDE является интерфейс АТА – 40 проводный интерфейс. IDE адаптер часто встраивается в системную плату. К настоящему времени разработаны усовершенствованные адаптеры с улучшенными характеристиками. ATAPI, ATA –2 позволяют подключать до 4 устройств, включая CD-ROM и стример. FAST ATA и FAST-ATA-2 – скоростные интерфейсы, обеспечивающие доступ к 8-гигобайтному диску.
SCSI (скази) – интерфейс системного уровня, представляет собой шину: сигнальные выводы множества устройств соединяются друг с другом. Интерфейс позволяет подключить до 7 устройств (дисковые накопители, CD-ROM, стример, сканер, винчестер фото и видеокамеры и т.п.). Любое устройство может инициировать обмен с другим устройством. Режим обмена может быть асинхронным и синхронным. Основным назначением «скази» является обеспечение аппаратной независимости подключаемых к компьютеру устройств. В отличие от жестких шин расширения PCI «скази-шина» реализуется в виде отдельного кабельного шлейфа, который допускает соединение до 8 устройств внутреннего и внешнего исполнения. Одно из них – хост-адаптер, связывает шину «скази» с системной шиной компьютера, 7 других свободны для периферии. Основные модификации интерфейса представлены в таблице 2.3.2
| Версия | Максимальная Скорость Мбайт/с | Ширина шины бит | Длина, м | Максимальное количество устройств |
| SCSI 1 | ||||
| FAST SCSI | ||||
| Ultra SCSI | ||||
| WIDE Ultra | ||||
| Ultra 3 |
Таблица 2.3.2 Модификации интерфейсов «скази»
SCSI 1 строго определяет физические и электрические параметры интерфейса и команд, FAST SCSI позволяет удвоить скорость передачи, Ultra SCSI – сверхскоростной интерфейс, WIDE – 16 битное расширение.
Ультрапорт. Альтернативой шинным архитектурам является коммутационное устройство ультрапорт UPA. Ультрапорт используется для тех же целей, что и шина, но если через шину могут взаимодействовать только два объекта, то ультрапорт обеспечивает передачу данных между несколькими парами объектов. Архитектура ультрапорта представлена на рис. 2.3.6.
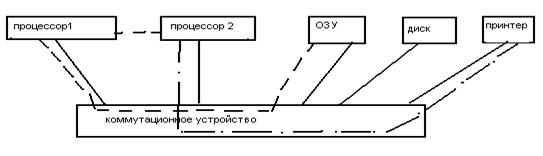
Рис.2.3.6. Архитектура ультрапорта
Внешние интерфейсы
Принтеры, модемы и другие Пу подключаются к компьютеру через стандартизованные интерфейсы, иногда называемые портами. В зависимости от способа передачи информации, последовательного или параллельного, различают параллельные и последовательные интерфейсы. Характеристики основных внешних интерфейсов представлены в таблице 2.3.3.
Таблица 2.3.3. Характеристики основных внешних интерфейсов.
| стандарт | Год выпуска | Скорость, Мбит/сек |
| Последовательный порт (RS 232) | 0,02 | |
| Параллельный порт LPT | 1,1 | |
| USB | ||
| Fire Wire | ||
| USB 2.0 | ||
| Fire Wire 800 |
Последовательный порт стандарта RS является стандартом для соединения ЭВМ с различными последовательными внешними устройствами (принтерами). IBM PC компьютеры поддерживают этот интерфейс не в полном объеме, поэтому в операционных системах этих компьютеров этому порту присваивается логическое имя COM. Основу последовательного порта составляет микросхема, содержащая регистры приемника и передатчика данных. При передаче байта информации он вначале записывается в буферный регистр передатчика, затем в сдвиговый регистр, откуда выдвигается по битам для последовательной передачи по линии связи.
Параллельный порт LPT используется для передачи одновременно 8 бит информации. В компьютерах он используется в основном для подключения принтера, хотя можно подключать и графопостроитель. Конструктивно он оформлен в виде 25-контактного разъема.Имеется 8 линий данных,8 линий заземления, кроме того ряд управляющих сигналов (запрос готовности, подтверждение готовности, занятость, выбор, перевод строки).
Хотя чаще всего параллельный порт применяется для передачи данных из компьютера в принтер, его можно использовать и для приема данных от внешнего устройства. Параллельное соединение применяется на расстояниях не более 5 метров, при увеличении длины возрастает межпроводная емкость и помехи.
USB – популярная последовательная шина, позволяющая подсоединять до 127 разнотипных устройств последовательно или использовать концентратор, к которому подсоединяются 7 устройств. Сейчас через этот порт подсоединяют клавиатуру, мышь, колонки, модемы, мобильные телефоны, оптические и магнитные накопителя, словом все, что подключается к компьютеру. Пропускная способность порта 480 Мбит/сек. Добавление устройств не требует установки дополнительных адаптеров.
Fire Wire – универсальный внешний интерфейс ввода-вывода, пригодный как для работы с мультимедиа, так и с накопителями. Этот стандарт использует в своих компьютерах фирма Apple. Этот стандарт используют для подключения цифровых камер. Это последовательный интерфейс. Его особенности:
- последовательная шина позволила использовать кабели малого размера и небольшие разъемы;
- поддержка «горячего подключения» и отключения;
- питание внешних устройств через шину;
- высокая скорость;
- возможность строить сети;
- простота конфигурации;
- поддержка асинхронной и синхронной работы.
Быстродействие интерфейса до 1,6 Гбит/сек.
2.4. Технология повышения производительности ЭВМ.
Пути повышения производительности ЭВМ
Современные ЭВМ развиваются в нескольких направлениях. Повышение производительности ЭВМ заключается в первую очередь в повышении скорости выполнения операций.
Первоначально повышение скорости шло по пути повышения частоты тактового генератора, т.е. повышения скорости процессора. Сейчас частота процессора достигла 4 ГГц, и ее можно было бы повышать, но ограничивающим фактором является частота шины, которая растет значительно медленнее. Для повышения частоты шины используются двукратная и четырехкратная синхронизация по тактовым импульсам, но очевидно этот путь имеет свои пределы.
Следующий путь – повышение разрядности процессора, но здесь тоже достигнут уровень 64 разрядов, и пока остановка. В больших ЭВМ процессоры применяют 128 и 256 разрядные, видимо по этому пути пойдут и ПК.
Большой сдвиг в повышении скорости дало кэширование, в современных ПК кэш размещается прямо на кристалле процессора. Но наибольший выигрыш в производительности дают архитектурные изменения в ЭВМ.
Конвейерная обработка команд.
Если вспомнить, как ЭВМ выполняет команду, то обработка каманды или цикл процессора, может быть разделен на несколько основных этапов, которых известно 5 основных типов: выборка команды; расшифровка кода операции; генерация адреса и выборка данных из памяти; выполнение операции; запись результата в память. Все этапы выполнения команды задействуются один раз и всегда в одном и том же порядке, одна за другой. Конвейеризация осуществляет многопоточную параллельную обработку команд, так что в каждый момент времени, одна из команд считывается, другая декодируется, третья выполняется и всего в обработке одновременно находятся несколько команд. Таким образом на выходе конвейера в каждом такте процессора появляется результат обработки одной команды. Для устройства конвейера необходимо разбиение процессора на части (ступени). Общее количество ступеней называется длиной конвейера. С ростом числа линий конвейера и увеличением числа ступеней увеличивается пропускная способность процессора при неизменной тактовой частоте. Процессоры с несколькими линиями конвейера получили название суперскалярных. Pentium – первый суперскалярный процессор фирмы Интел.Здесь имеются две линии, что позволяет при одинаковых частотах быть вдвое производительнее, выполняя две инструкции за такт.
Рассмотрим компьютер Pentium 4.
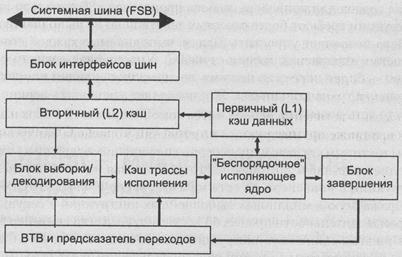
Рис.2.4.1.Структурная схема процессора Pentium -4
Конвейер процессора Pentium 4 состоит из трех частей (рис.2.4.1): 1) устройства предварительной обработки команд в порядке их следования в программе; 2) исполнительного ядра, исполняющего микрооперации в удобном для него порядке; 3) блока упорядоченного завершения, отражающего результаты выполнения микроопераций в правильный порядок. В свою очередь каждая часть конвейера делится на 20 ступеней. Это позволяет выпускать с конвейера за один такт до з инструкций.
Динамическое исполнение. Помимо конвейера операций в процессоре Pentium 4 применяется динамическое исполнение. Это новая технология обработки данных, которая представляет комбинацию трех методов обработки:
- множественное предсказание ветвлений;
- анализ потока данных;
- спекулятивное (по предположению) исполнение.
Множественное предсказание ветвлений. Предсказывается прохождение программы по нескольким ветвям, процессор использует предсказание, в какой области памяти можно найти следующие команды. Это становится возможным, так как процессор просматривает программу на несколько шагов вперед и этот метод позволяет повысить загруженность процессора.
Хотя буфер предсказания переходов и не может правильно предсказать абсолютно все переходы, но большинство предсказаний оказывется точными, что обеспечивает значительное повышение производительности. Такой буфер мы видим в процессоре Pentium 4.
Анализ потока данных. Процессор анализирует и составляет график исполнения команд в оптимальной последовательности, независимо от их порядка следования в программе. Используя анализ потока данных, процессор просматривает декодированные команды и определяет, готовы ли они к непосредственному исполнению или зависят от результатов выполнения других команд. Далее процессор определяет оптимальную последовательность выполнения и исполняет команды наиболее эффективным способом. Такое беспорядочно исполняющее ядро является одной из частей конвейера.
Спекулятивное выполнение повышает скорость выполнения, просматривая программу вперед и исполняя те команды, которые необходимы.Процессор выполняет их одновременно по мере их поступления в оптимизированной последовательности (спекулятивно). На конечном этапе порядок инструкций восстанавливается и переводится в обычное машинное состояние.
Первое отличие процессора Pentium 4 от первых МП – отсутствие первичного КЭШа команд, в котором у МП хранились копии фрагментов ОЗУ, и вторичного КЭШа, содержащего ранее исполненные команды и следующие за ним строки. Остались КЭШ данных L1 и вторичный КЭШ данных L2, которые размещены непосредственно в микросхеме.
Появился КЭШ трасс исполнение, в которых хранятся трассы (последовательности микроопераций, в которых были декодированные команды)
КЭШ трасс совместно с блоками выборки и декодирования образуют устройство предварительной обработки, которая выполняет следующие функции:
- предварительную выборку команд, которые предполагается исполнить;
- декодирование команд в микрооперации;
- генерацию микрокодов для сложных команд;
- доставку декодированных команд из КЭШа трасс;
- предсказание переходов.
КЭШ трасс способен хранить до 12 Кбайт микроопераций и за каждый такт доставляет ядру до 3 микроопераций.
Исполнительное ядро имеет максимальную пропускную способность, которая превышает возможности блока предварительной обработки и блока завершения. Оно способно запустить в исполнительные блоки до 6 микроопераций.
Блок завершения упорядочивает микрооперации произведенные ядром и позволяет выпускать за каждый такт до 3 микроопераций.
Еще более полно динамическое исполнение представлено в 64-разрядных процессорах. Эти процессоры имеют мощные вычислительные ресурсы, включая 128 регистров целых чисел, 128 регистров действительных чисел, 64 предикационных регистра и ряд специальных регистров.
Предикация – одновременное исполнение двух ветвей программы, вместо предсказания переходов (выполнения наиболее вероятного).
Опережающее чтение данных, т.е. загрузка данных в регистры с опережением, до того, как определилось реальное ветвление программы.
Эти возможности осуществляются комбинированно – при компиляции и выполнении программы.
Компилятор транслирует операторы исходного кода, содержащие ветвление (условный переход), в совокупность блоков машинных команд, идущих друг за другом. Процессор пытается прогнозировать исход операции и заранее выполняет один из блоков, теряя время при ошибке прогнозирования. Когда компилятор обнаруживает оператор перехода, он анализирует все возможные ветви и помечает их метками или предикатами.После этого, он определяет, какие из них могут быть выполнены параллельно.
Затем компилятор группирует машинные коды в 128 битовые связки по 3 команды в каждой. Это трассы исполнения.
В процессе выполнения программы процессор просматривает описания связок, выбирает команды, которые взаимно независимы и распределяет их на параллельную обработку. Если процессор обнаруживает ветвление, он не пытается предсказать переход, а начинает выполнять все возможные ветви программы.
Опережающее чтение разделяет загрузку данных в регистры и их реальное использование, избегая ожиданий. Прежде всего, компилятор анализирует программу, определяя команды, которые требуют приема данных из оперативной памяти. Там, где это возможно, он вставляет команды опережающего чтения, и переставляет команды так, чтобы процессор мог их обрабоатывать параллельно. В процессе работы процессор, встречая команду опережающего чтения, пытается выбрать данные из памяти. Если данные не все готовы, обработка продолжается до тех пор пока все данные не считаны. Если к моменту прихода в точку «команда проверки опережающего чтения» не все данные готовы, вырабатывается сигнал прерывания.
Все перечисленные методы повышения производительности относятся к однопроцессорным системам, т.е. ЭВМ.
|
|
|
|
|
Дата добавления: 2014-12-16; Просмотров: 3367; Нарушение авторских прав?; Мы поможем в написании вашей работы!