КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Информационно-поисковые системы World Wide Web
|
|
|
|
Fi SEARCH - Windows Internet Explorer
h«p:№ww*.benran.ru,'Zgw/Ep:gi e
Поиск в отмеченных источниках данных
Гчмш.: *»«■««■«Утаж.
сея}ха;

|
- //aVO-IUHWli
_ tun списки
Ф'грмст; ■.. номер колыч*стео.
r smtoetiMHX летев: *
запаси.
Результат поиска по запросу'
3S
p<ero i: wccc-, нацмен; 36:-a<\|f.
{i PRTSfNJ Windows internet Explorer
- £ httf j'^/j^w.benran.gi.f..
^PRESENT
j_ -lot-'K i ГЛСПЧ-
| serns. 5 |
www .benran. ru ^a-ii- contralTdev.-ifier (JJS RA.S! 'J451S1
placeOfFufclicsti.oi,- "JSA
d«teOfFuk-ii.c»Civ-a: 2005 2C04, iOOi ZO'J? 20C1 2000 1399 1996 1&Ч4 1993, 193: 199Q
i бозе^з'- ->a hoick
Рис. 7.15. Фрагмент диалога с WAlS-серверами с использованием шлюза
(окончание):
а — стартовый экран; б — запрос и результат поиска; в — просмотр атрибутов одной из найденных записей
Прежде чем описать проблемы построения информацион- но-поисковых систем Web и пути их решения, рассмотрим типовую структуру такой системы. В различных публикациях, посвященных конкретным системам, приводятся схемы, которые отличаются друг от друга только применением конкретных программных решений, но не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему (рис. 7.16) на примере, представленном в работе [28], где:
User Client — программа просмотра конкретного информационного ресурса. В настоящее время наиболее популярны мульти- протокольные программы типа Netscape Navigator, MS Internet Explorer. Такая программа обеспечивает просмотр документов World Wide Web, Gopher, WAIS, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска ИПС;
User Interface — интерфейс пользователя — в данном случае это способ общения пользователя с поисковым аппаратом системы, т. е. с системой формирования запросов и просмотра результатов поиска. Просмотр результатов поиска и информационных ресурсов сети — это совершенно разные вещи, на которых мы остановимся чуть позже;
Search Engine — поисковая машина — служит для трансляции запроса пользователя, который подготавливается на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы сети и выдачи результатов этого поиска пользователю;
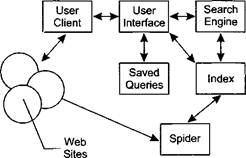 Рис. 7.16. Структура ИПС для Internet
Рис. 7.16. Структура ИПС для Internet
|
Index — индекс — служит для поиска адреса информационного ресурса. Структура индекса организована таким образом, чтобы поиск происходил максимально быстро и при этом можно было определить ценность каждого из найденных информационных ресурсов сети;
Queries — запросы пользователя — сохраняются в его личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно хранить запросы, поиск по которым привел к удовлетворительному результату;
Spider (Index Robot) — робот-индексировщик — служит для сканирования Internet и поддержки базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети;
Web Sites — это те информационные ресурсы, доступ к которым обеспечивает ИПС.
Рассмотрим теперь назначение и принцип построения каждой из этих компонент более подробно, чтобы определить, в чем отличие данной системы от традиционной информационно-поисковой системы локального типа.
Как видно из рис. 7.16, первичным документальным массивом ИПС Internet является все множество документов следующих основных типов: HTML-страницы, Gopher-файлы, документы WAIS, записи архивов FTP, новости Usenet, статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак не согласованных друг с другом форматов данных. Здесь есть текстовая, графическая, аудиоинформация и вообще все, что может быть в указанных выше типах хранилищ. Естественно, возникает вопрос, как информа- ционно-поисковая система должна со всем этим работать.
В традиционных системах есть понятие поискового образа документа. ПОД (поисковый образ документа) — это некая маска, заменяющая собой документ и использующаяся при поиске вместо реального документа. Поисковый образ являет собой результат применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель, в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл.
Если быть более точным, то документу приписывается вектор, размерность которого равна числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия или отсутствия термина в ПОДе документа. В более сложных моделях термины взвешиваются, т. е. элемент вектора равен не 1 или 0, а некоторому числу, которое отражает соответствие данного термина документу. Именно последняя модель наиболее популярна в информационно-поисковых системах Internet. Существуют и другие модели описания документов — вероятностная модель информационных потоков и поиска, модель поиска в нечетких множествах. Анализ преимуществ и недостатков применения этих моделей при реализации информационно-поисковых систем в Internet — это тема специального исследования. Здесь имеет смысл обратить внимание читателя лишь на то, что пока именно линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText, AliWeb и ряде других. Исследования по применению других моделей также ведутся, например в рамках проекта AltaVista.
Таким образом, первая задача, которую должна решить ин- формационно-поисковая система, — это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием.
Индексирование. Часто индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов, в которых он встречается. Такая процедура является только частным случаем, точнее, техническим аспектом создания поискового аппарата информационно-поисковой системы.
Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы. Таким образом, все новые документы могли быть проиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени, и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе трудности такой процедуры в динамичной среде Internet, где ресурсы постоянно появляются и исчезают. При создании программы Veronica для поиска в GopherSpace предполагалось, что все серверы должны быть зарегистрированы, и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных поисковых образов документов Gopher.
В World Wide Web ничего подобного нет. Для решения этой задачи используются программы сканирования сети или робо- ты-индексировщики. Разработка роботов — довольно нетривиальная задача, поскольку существует опасность зацикливания робота или попадания на виртуальные страницы. Все системы имеют своего робота, который просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главная проблема заключается в том, чтобы определить, какие термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. В настоящее время различные роботы используют для индексирования следующие источники для пополнения своих виртуальных словарей:
• гипертекстовые ссылки;
• заголовки (title);
• заглавия (HI, Н2 и т. п.);
• аннотации;
• списки ключевых слов;
• полные тексты документов;
• сообщения администраторов о своих Web-страницах.
Для индексирования Telnet, Gopher, FTP, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков — поля Subject и Keywords. Наибольший простор для построения ПОДов дают HTML-документы.
Однако не следует думать, что все термины из перечисленных выше элементов документов попадают в их поисковые образы. Очень активно применяются списки запрещенных слов (stop-words) и общих слов (предлоги, союзы и т. п.), которые не могут быть использованы для индексирования, кроме того, часто производится нормализация лексики. Таким образом, даже то, что в OpenText, например, называется полнотекстовым индексированием, реально является выбором слов из текста документа и результатом сравнения с целым набором различных словарей, после чего термин попадает в поисковый образ документа, а потом и в индекс системы. Для того чтобы не раздувать словарей и индексов (а индекс Lycos, например, равен 4 Тбайт), применяется такое понятие, как «вес» термина. Документ обычно индексируется списком от 40 до 100 наиболее значимых терминов.
Поисковый аппарат. После того как ресурсы заиндексирова- ны, т. е. система составила массив поисковых образов, начинается построение поискового аппарата системы. Совершенно очевидно, что лобовой просмотр файла или файлов ПОДов займет много времени, что абсолютно неприемлемо для интерактивной системы, которой является Web. Для того чтобы можно было быстро находить информацию, в базе данных ПОДов строится индекс. Индекс в большинстве систем — система связанных между собой файлов, которая нацелена на быстрый поиск данных по запросу пользователя. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов. К этим факторам можно отнести и размер массива поисковых образов, и информационно-поисковый язык системы, и размещение различных компонентов системы, и т. п. Рассмотрим структуру индекса, приведенную в [28]. Этот проект выбран потому, что он позволяет не только выполнять булевский поиск, контекстный поиск и взвешенный поиск, но и реализовывать ряд других возможностей, которые отсутствуют во многих поисковых системах.
Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (Page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного списка (IL) и прямого списка (FL).
Page-id отображает идентификаторы страниц в URL этих страниц, Keyword-ID — каждое ключевое слово в уникальный идентификатор этого слова, таблица заголовков — идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок — идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову список пар (номер документа, идентификатор страницы, позиция слова в странице). Прямой список — это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них, безусловно, является файл инвертированного списка. Результат поиска в этом файле — это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками, возвращается пользователю в его программу просмотра Web.
Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например файл буквенных пар с указанием записей инвертированного списка, с этих пар начинающихся, а также применяется механизм прямого доступа к данным — хеширование.
Для обновления индекса используется подход, который можно назвать коррекцией индекса «на ходу». Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и применяется при поиске. Когда число таких ссылок становится таким, что это ощущается при поиске, происходит полное обновление индекса, т. е. его перезагрузка.
Информационно-поисковый язык системы. Однако индекс — это только часть поискового аппарата, причем скрытая от пользователя. Второй частью этого аппарата является информационно-поисковый язык. ИПЯ позволяет сформулировать запрос к системе в довольно простой и доходчивой форме. Уже давно осталась позади романтика создания ИПЯ как естественного языка. Именно этот подход использовался в системе WAIS на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это не значит, что система будет осуществлять семантический разбор запроса пользователя. Обычно фраза разбивается на слова, из этого списка удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим and, либо or. Таким образом, запрос типа
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: «Найти все документы, в которых слова Unix, Platform и Software встречаются одновременно».
Возможны и варианты. Так, в большинстве систем фраза «Unix Platform» будет опознана как ключевая и не будет разделяться на отдельные слова. Другой подход заключается в вычислении меры близости между запросом и документом. Именно этот подход используется, например, в Lycos. В этом случае мера близости вычисляется в соответствии с векторной моделью представления документов и запросов. К настоящему времени известно около дюжины различных мер близости. Наиболее часто применяется косинус угла между поисковым образом документа и запросом пользователя. Именно эта мера соответствия документа запросу и выдается в качестве справочной информации при списке найденных документов.
Одним из наиболее развитых языков запросов современных информационно-поисковых систем Internet обладает AltaVista. Кроме обычного набора and, or, not, эта система позволяет использовать near. Последний оператор дает возможность организовать контекстный поиск. Все документы в системе разбиты на поля, поэтому в запросе можно указать, в какой части документа пользователь хочет увидеть ключевое слово (в ссылке, заголовке и т. п.). Можно также задать поле ранжирования выдачи и критерий близости документов запросу.
Краткие характеристики АИПС для WWW-пространства
Lycos ( http://mnr.lycos.com ). Как и большинство систем, Lycos дает возможность использовать для работы с простым запросом достаточно изощренный метод поиска. В простом запросе в качестве поискового критерия вводится предложение на естественном языке. Lycos производит нормализацию запроса, удаляя из него так называемые stop-слова, и только после этого приступает к его выполнению. Почти сразу выдается информация о числе документов на каждое слово, а уже позже и список ссылок на формально релевантные документы. Релевантность — это мера соответствия найденного системой документа потребности пользователя. В списке напротив каждого документа указываются его мера близости запросу, число слов из запроса, которые попали в документ, и оценочная мера близости, которая может быть больше или меньше формально вычисленной. Нельзя вводить операторы в строке вместе с терминами, но использовать логику через систему меню Lycos позволяет. Это относится к расширенной форме запроса, предназначенной для использования искушенными пользователями системы, которые уже научились пользоваться этим механизмом.
Таким образом, мы видим, что Lycos относится к системе с языком запросов типа «Like this», но предполагается его расширение и на другие способы организации поисковых предписаний.
AltaVista ( http://www.altavista.digital.com ). С точки зрения информационно-поискового языка наиболее интересным в AltaVista является возможность расширенного поиска. Здесь стоит сразу выделить, что в отличие от многих систем AltaVista поддерживает одноместный оператор not. Кроме того, есть еще и оператор near, который реализует возможность контекстного поиска, когда термины должны располагаться рядом в тексте документа. AltaVista разрешает поиск по ключевым фразам, при этом она имеет довольно большой словарь этих фраз. Помимо всего прочего при поиске в AltaVista можно задать имя поля, где должно встретиться слово. Это может быть гипертекстовая ссылка, апплет, название образа, заголовок и ряд других полей. Реально эту систему можно отнести к системе с расширенным булевым поиском.
Yahoo. Данная система появилась в сети одной из первых. В настоящее время Yahoo сотрудничает со многими производителями средств информационного поиска, и на различных ее серверах используется различное программное обеспечение. На взгляд авторов, это самая незатейливая информационная служба, которая сосредоточилась на информации о Web как таковой. ИПЯ Yahoo достаточно прост: все слова следует вводить через пробел, и они соединяются либо and, либо or. В результат поиска не включаются степени соответствия документа запросу, а только подчеркиваются слова из запроса, которые встретились в документе. При этом не производится нормализация лексики и не проводится анализ на «общие» слова. Хорошие результаты поиска получаются только тогда, когда пользователь знает, что информация в базе данных Yahoo точно имеется. Ранжирование производится по числу терминов запроса в документе. Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска.
OpenText ( http://index.opentext.net ). Информационная система OpenText представляет собой самый коммерциализированный информационный продукт в сети. Все описания больше напоминают рекламу, чем реальное руководство по работе. Система позволяет провести поиск с использованием логических коннекторов, размер запроса ограничен тремя терминами или фразами. В данном случае речь идет о расширенном поиске. При выдаче результатов поиска сообщается степень соответствия документа запросу и размер документа. Система позволяет также улучшить результаты поиска в стиле традиционного буле- вого поиска.
OpenText можно было бы отнести к разряду традиционных информационно-поисковых систем, если бы не механизм ранжирования.
InfoSeek ( http://infoseek.com ). Система InfoSeek обладает довольно развитым информационно-поисковым языком, который позволяет не просто указывать, какие термины должны встречаться в документах, но и своеобразно взвешивать их. Достигается это с помощью специальных знаков: «+» — термин обязан быть в документе, «—о — термин обязан отсутствовать в документе. Помимо этого InfoSeek позволяет проводить то, что называется контекстным поиском. Это значит, что, используя специальную форму запроса, можно потребовать последовательной совместной встречаемости слов. Кроме того, можно указать, что некоторые слова должны совместно встречаться не только в одном документе, но и в отдельном параграфе или заголовке. Есть возможность и указания ключевых фраз. Ключевая фраза от последовательной встречаемости отличается тем, что фраза всегда ищется как единое целое, а при последовательной встречаемости слова могут стоять рядом, но в произвольном порядке. Ранжирование при выдаче осуществляется по числу терминов запроса в документе, по числу фраз запроса в документе, за вычетом общих слов. Все эти факторы используются как вложенные процедуры.
Подводя краткое резюме, можно сказать, что InfoSeek относится к традиционным системам с элементом взвешивания терминов при поиске.
Интерфейс системы. Важным фактором качества И ПС является вид представления информации в программе-интерфейсе. При этом различают два типа страниц: страницы запросов и страницы результатов поиска.
При составлении запроса используют либо меню-ориентированный подход, либо командную строку. Меню-ориентированный подход позволяет ввести список терминов, обычно через пробел, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины.
На схеме, представленной на рис. 7.13, есть так называемые сохраненные запросы пользователя. В большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один тип использования сохраненных запросов. В традиционных системах это называется расширением или уточнением запроса в зависимости от того, что получаем в результате преобразования запроса: увеличение размера выборки или ее сокращение. При этом традиционная система хранит не запрос как таковой, а результат поиска, т. е. список идентификаторов документов, который объединяется/пересекается со списком, полученным при поиске документов по новым терминам. К сожалению, возможность сохранения списка идентификаторов найденных документов в World Wide Web практически отсутствует, что связано с особенностью протоколов взаимодействия программы-клиента и сервера системы, которые не поддерживают сеансовый режим работы.
Как понятно из вышеизложенного, результат поиска в базе данных ИПС — это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых системах выдается только список ссылок, а в таких системах, как Lycos, AltaVista, Yahoo, кроме ссылок, дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме того, система сообщает степень близости документа запросу. В Yahoo, например, сообщается, сколько терминов запроса содержится в поисковом образе документа, и в соответствии с этим ранжируется результат поиска. В Lycos выдается мера соответствия документа запросу и ранжирование производится по этому параметру. Обычно пользователь имеет возможность уточнить запрос.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности. Различают формальную и истинную релевантность. Формальная вычисляется системой, и на этом основании ранжируется выборка найденных документов. Истинная соответствует оценке пользователем выдачи на запрос. Некоторые системы имеют для этого специальное поле, в котором пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа, и выдача снова ранжируется. Так происходит до тех пор, пока результат не стабилизируется, что означает достижение оптимального поискового результата.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http:// host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают, и система не индексирует. Если с HTTP-ссылками все более или менее понятно, то ссылки WAIS — это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы. Это значит, что одна ИПС, например Lycos, строит поисковый аппарат над поисковым аппаратом другой системы — WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, т. е. разбить их на поля, и хранить документы как один файл. Индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения. В этом случае программа просмотра ресурсов Internet должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.
Перечисленные возможности и поисковые технологии в достаточной степени иллюстрируются далее на примере поисковых машин Yandex и Rambler.
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 1159; Нарушение авторских прав?; Мы поможем в написании вашей работы!