КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Комбинированные системы
|
|
|
|
MIMD архитектура с разделяемой и распределенной памятью
SIMD архитектура (с разделяемой и распределенной памятью)
Чаще всего, при упоминании архитектуры SIMD, понимают матричные процессоры. Эти процессоры имеют общее управляющее устройство, которое генерирует поток команд. Также в составе есть несколько процессорных элементов, которые работают параллельно и каждый обрабатывает свой поток данных. По сути, общая производительность системы должна равняться сумме производительностей, входящих в нее элементов. Но чтобы приблизится к этой величине необходимо применять ряд технических решений. В частности, необходима организация связи между процессорными элементами для полной их загрузки. Пример такой связи приведен на рис. 3.1.
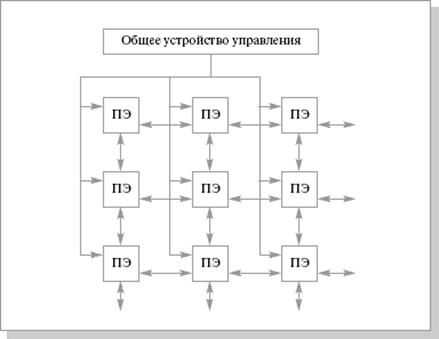
Рис. 3.1. Структура матричной вычислительной системы SOLOMON (60-е годы) [8]
В этом процессоре была реализована многомодальность. В каждом процессорном элементе существовал специальный регистр (регистр моды), которой имел четыре состояния. Мода попадала в этот регистр от устройства управления. В ходе выполнения команд моды передаются в коде операции и сравниваются со значением регистра. Если значения совпадают, то операция выполняется. В других случаях операция не выполняется, но процессорный элемент может передать свои операнды соседнему элементу. Такое решение позволяет выделять строки или столбцы процессорных элементов. Это очень удобно при работе с матрицами.
Вторым по быстродействию устройством в компьютерах (после процессора) является оперативная память. Это связано с несколькими факторами. Во-первых, само время цикла работы с памятью tmem больше времени цикла работы центрального процессора tcp. Во вторых, при обращении к памяти она будет занята в течение времени tcp+tmem. Для уменьшения подобных задержек существует два возможных варианта. Организовать работу на основе разделяемой памяти, когда есть одна большая память и все процессоры имеют одинаковый доступ к ней. Или работать с распределенной памятью, выделив каждому процессору свою оперативную память (локальную) и запретить доступ к ней со стороны других процессоров. Разрабатывать программу, не зная какой тип памяти будет использоваться на данном параллельном компьютере, - бесполезное занятие. Так например, что делать при перемножении двух матриц? Если вы работаете по первому варианту, то можно один раз задать структуру данных и разместить ее в памяти. А если реализована разделяемая память, то необходимо создать копии матриц на каждом процессоре, т.е. послать всем процессорам сообщение с данными о матрицах.
Наиболее просто реализовать разделяемую память следующим образом – соединить одной шиной все процессоры, в конце поставив оперативную память. Конечно, такой вариант не идеален из-за постоянных конфликтов между процессорами. Если одни из процессоров начнет принимать или передавать данные, то доступ к оперативной памяти для остальных процессоров будет закрыт. Этот конфликт приводит к тому, что появляется предел производительности. Увеличение числа процессоров не будет приводить к увеличению производительности – шина станет узким местом. Однако, и это научились обходить. Достаточно ввести систему кэш-памяти для хранения команд. К каждому процессору добавляют локальную кэш-память. Причем, каждая следующая необходимая процессору команда будет с большой вероятностью находится там. Соответственно, уменьшается число обращений к шине уменьшится, а это позволит добавить в систему еще несколько процессоров. Проблема кэш-памяти – это ее локальность. Если двум процессорам понадобилось из общей памяти значение С1, то это значение скопируется в обе кэш-памяти. Один из процессоров меняет значение переменной и отправляет обратно в общую память. В это время второй процессор работает, совершенно ничего не подозревая, со старым значением С 1. Такое несоответствие влечет необходимость постоянного обновления данных в кэш-памяти всех процессоров. Можно реализовать разделяемую память на нескольких физических модулях. Для процессоров эти устройства будут представлены как единое (подробнее в п.3.3). Но для правильной работы необходимы переключатели. Если обращений к одному и тому же дискретному модулю от разных процессоров не много, то быстродействие возрастет.
Для организации распределенной памяти, как было сказано выше, необходимо подключить собственную оперативную память каждому процессору. При такой архитектуре нет необходимости использовать общую шину и переключатели, т.е. исчезают конфликты, связанные с этими устройствами. Но взамен тех проблем появляются новые. Они связаны с корректной организацией обмена информацией между процессорами. Проще организовать такой обмен при помощи сообщений, в которых будут содержаться данные. На формирование, обработку, получение и отправление таких пакетов уходит время, что, естественно, сказывается на производительности.
Оба варианта организации работ с памятью с успехом применяются, что и нашло отражение в SMP и MPP системах.
SMP (symmetric multiprocessing) – симметричная мультипроцессорная архитектура. Архитектура с общей разделяемой памятью. При такой организации все процессоры имеют одинаковые права на доступ к памяти и одинаковую адресацию для всех ячеек памяти (отсюда и название – симметричная). Такой способ очень удобен при обмене данными между процессорами. Основой в SMP-системе является высокоскоростная шина, к слотам которой можно подключить процессорные элементы (ПЭ), подсистему ввода/вывода (I/O). Работа контролируется операционной системой (ОС). Наиболее часто применяется такая система в серверах.
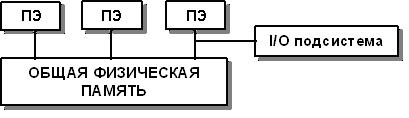
Рис. 3.2. Схематичный вид SMP-архитектуры [9]
За счет SMP-архитектуры можно получить простую и универсальную систему для программирования. В этой системе нет ограничений на модель программирования (можно организовать модель параллельных ветвей с независимыми процессорами или модель с межпроцессорным обменом). Кроме того можно получить доступ сразу ко всему объему памяти, возможность использовать средства автоматического распараллеливания (зачастую они оказываются достаточно эффективными), облегчить эксплуатацию системы, понизив ее цену.
Но поскольку система использует общую память, то ее недостатки напрямую связаны с недостатками систем с распределенной памятью, включающими плохую масштабируемость, частые конфликты между процессорными элементами, ограниченную пропускную способность системной шины. Так возможно использовать не более 32 процессоров (как следствие предыдущих трех недостатков).
Альтернативой SMP стала MPP-архитектура.
MPP(massive parallel processing) – массивно-параллельная архитектура. Как не сложно догадаться, эта архитектура основана на физически разделенной памяти. Такую систему можно строить на основе отдельных модулей, состоящих из процессорного элемента (ПЭ), локальной операционной памяти (ОП), двух коммуникационных процессоров (роутеры) или сетевого адаптера. Возможно подключение периферийных устройств. Наличие сразу двух сетевых адаптеров связано с тем, что один из них работает на передачу команд, другой – на передачу данных. В принципе, каждый модуль может выступать как самостоятельная, независимая ЭВМ. Доступ к ОП имеет только ПЭ из того же модуля. Между собой модули соединены коммуникационными каналами, по которым и происходит обмен информацией. Организовать работу MPP-систему можно двумя способами:
С управляющей машиной. В этом случае один из модулей работает в качестве основного, контролирующего все остальные. Именно на главном модуле будет стоять полновесная операционная система и программное обеспечение. На остальных модулях можно использовать урезанные варианты ОС и ПО, которые позволят модулю выполнять работу только его ветви распараллеленного приложения.
Равноправные модули. Каждый модуль имеет полноценные ОС и ПО.

Рис. 3.3. Схематичный вид MPP-архитектуры [9]
В отличие от SMP-систем, MPP легко масштабируется. Именно это является главным преимуществом. Число процессоров в таких системах может достигать нескольких тысяч.
Но MPP не лишена недостатков:
Меньшая, по сравнению с SMP, скорость межпроцессорного обмена. Это связано с тем, что необходима специальная техника программирования для корректного обмена информацией между процессорами.
Ограниченность объема памяти каждого из процессоров.
Может возникнуть ситуация, и это не редкость, когда часть оборудования не будет загружена полностью.
В качестве примеров MPP-систем можно привести такие суперкомпьютеры как Hitachi SR8000, CRAY T3E (эту систему можно масштабировать до 2048 процессоров).
Самым логичным решением после изучение SMP и MPP-систем было бы создать систему, объединяющую все достоинства и той и другой архитектуры. Так появилась гибридная система NUMA (Nonuniform memory access) – система с неоднородным доступом к памяти.
Память организована следующим образом – она физически является распределенной по различным частям системы, но процессоры видят ее как единую, с единым адресным пространством. NUMA-системы состоят из однородных базовых модулей, которые объединены при помощи высокоскоростного коммутатора. Сохраняется единое адресное пространство, доступ к памяти других процессоров (из других модулей) поддерживается на аппаратном уровне. Для доступа к локальной памяти требуется значительно меньшее время чем при доступе к удаленной (принадлежащей другому модулю).
NUMA-архитектура представляет собой MPP-архитектуру, где в качестве отдельных элементов использованы SMP узлы. Чтобы легче было понять, что же имелось ввиду в последнем предложении, приведем схему компьютера с комбинированной организацией памяти.
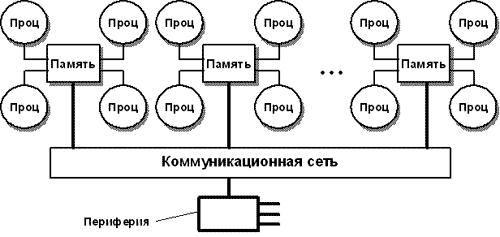
Рис. 3.4. Структурная схема вычислительной системы с комбинированной организацией памяти [9]
При подобной организации доступа к памяти очень важно, чтобы все процессоры получали одинаковые значение одних и тех же переменных в любой момент времени. Эта проблема называется когерентность кэш-памяти. Она появляется как следствие использования разделяемой памяти. Т.к. кэш-память принадлежит конкретному процессору, то она недоступна для остальных процессоров (даже для тех, которые находятся в его модуле). Именно поэтому необходимо проводить синхронизацию памяти. Применение нашли два варианта.
Отслеживать шинные запросы (Snoopy Bus Protocol). Кэши отслеживают переменные, которые передаются к любому из процессоров и, при необходимости, делают себе копии этих переменных;
Или выделить специальную область в памяти, в которой будет проверятся достоверность всех копий используемых переменных.
|
|
|
|
|
Дата добавления: 2014-12-07; Просмотров: 619; Нарушение авторских прав?; Мы поможем в написании вашей работы!