КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Библиографический список. Алгоритм с использованием разделяемой памяти
|
|
|
|
Алгоритм с использованием разделяемой памяти
Молекулярная динамика на CUDA
Вызов процедуры перемножения матриц из программы на C
В принципе, использование CUDA позволяет писать процедуры для графического и центрального процессоров в одном и том же текстовом файле. В настоящем примере коды для GPU и для CPU разнесены в разные файлы, для того чтобы лучше структурировать проект. В Приложении 2 мы приводим код, исполняемый на СPU, с краткими комментариями. Подробности даны, например, в руководстве пользователя CUDA от NVIDIA [67].
В проект также должны входить заголовочный файл matrixMul.h и файл, содержащий непараллельную процедуру перемножения матриц на CPU matrixMul_gold.cpp. Тексты этих файлов [68] также приведены в Приложении 2.
Самые последние графические процессоры уже поддерживают вычисления с двойной точностью, что в принципе позволяет полностью реализовывать на GPU шаги молекулярной динамики, не обращаясь к центральному процессору. Всё же, здесь мы ограничимся только рассмотрением алгоритма расчёта межчастичных сил, который вполне демонстрирует новые возможности 4-й шейдерной модели и CUDA [69].
Этот алгоритм, приведённый на рис. 9.7, отличается от рассмотренных в главе 6 тем, что включает в себя «ручную» оптимизацию использования «быстрой» разделяемой параллельной памяти, которой не существовало у GPU шейдерной модели 3.0.
Кодирование алгоритма молекулярной динамики на CUDA не имеет принципиальных особенностей по сравнению с перемножением матриц, так что мы не будем приводить весь код. Остановимся только на одной из простых реализаций «треугольного» цикла расчёта сил, использующего 3-й закон Ньютона для двукратного уменьшения объёма вычислений.
9.5.2. Расчёт сил на GPU с использованием 3-го закона Ньютона
На рис. 9.8 a (без учёта распараллеливания) показан самый простой цикл расчёта действующих между частицами сил. На GPU SM3 можно (с распараллеливанием) реализовать только этот цикл, поскольку каждая сила F i рассчитывается независимо от сил F j, действующих на другие частицы. Распараллеливание этого же цикла на GPU SM4 показано на рис. 9.7.
Вместе с тем, согласно 3-му закону Ньютона, F ij = - F ji, то есть Ñ U ij(R ij) = - Ñ U ji(R ji). Таким образом, алгоритм расчёта сил можно модифицировать согласно рис. 9.8 б. В новом цикле суммирование по j начинается с j = i+ 1, а не с нуля, так что весь двойной цикл по i, j, становящийся «треугольным», содержит в 2 раза меньше операций вычисления сил. На рис. 9.9, иллюстрирующем «треугольный» цикл, тёмные прямоугольники соответствуют парам (i, j), для которых силы F ij реально считаются, а белые – обратным комбинациям (i, j), для которых F ji = - F ij.
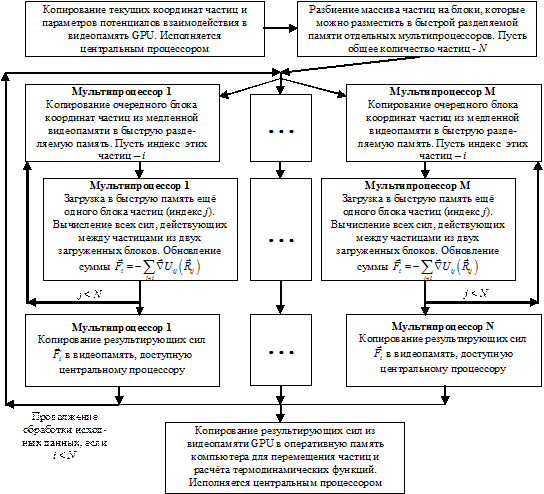
Рис. 9.7. Молекулярная динамика на графическом процессоре шейдерной модели 4.0
Ниже с комментариями приведена реализация «треугольного» цикла с 3-м законом Ньютона на CUDA. Для наглядности используется только один мультипроцессор. Каждый i -й поток суммирует парные взаимодействия i -й частицы и записывает их в разделяемую память, а в конце сохраняет одну из накопленных сумм в линейный массив force (каждой частице соответствует только один элемент), расположенный в глобальной памяти. Это позволяет минимизировать количество обращений к медленной общей памяти.
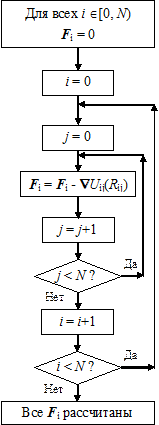
| 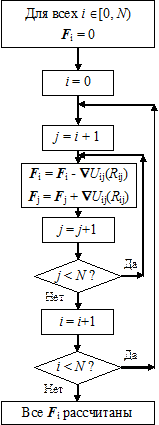
|
| a) | б) |
Рис. 9.8. Расчёт сил с учётом и без учёта 3-го закона Ньютона

Рис. 9.9. «Треугольный» цикл расчёта сил
Процедура вычисления сил в «треугольном» цикле на CUDA
/* Спецификатор __global__ означает, что вся процедура будет исполняться на GPU как вычислительное ядро */
__global__ void kernel_NxN(float4 force[], float4 pos[], int type[], float4 coefs[]) {
/* Переменные, описываемые без спецификаторов, будут хранится в том кэше GPU, который называют «памятью для констант». Они не будут меняться по ходу алгоритма: */
int j;
/* Вычислительные потоки в данном случае упорядочены в линейный массив. Каждый поток рассчитывает силу F i, действующую на одну из частиц: */
int i = threadIdx.x;
/* Тип частицы type[i] и 4-вектор с координатами частицы pos[i] копируются в кэш, для того чтобы потом не обращаться за ними внутри цикла по j к медленной видеопамяти: */
int type_i = type[i];
float4 pos_i = pos[i];
/* Создаётся переменная (4-вектор) force_i, в которой будет суммироваться результирующая сила, действующая на частицу i со стороны остальных частиц; в начале расчёта она зануляется */
float4 force_i = { 0, 0, 0, 0 };
/* В разделяемой памяти (на что указывает модификатор __shared__) создаются массивы, содержащие координаты и типы всех частиц, параметры всех потенциалов взаимодействия (coefs_ij[4], где coefs_ij – сам по себе 4-вектор), а также все результирующие силы (force_j[N]), действующие на каждую из частиц: */
__shared__ float4 pos_j[N];
__shared__ int type_j[N];
__shared__ float4 coefs_ij[4];
__shared__ float4 force_j[N];
/* Следующий блок операторов копирует данные из медленной «глобальной» памяти GPU, куда их перед обращением к GPU записывает центральный процессор, в быструю разделяемую память. Каждый из потоков копирует элементы массивов, относящиеся к «своей» частице i, а первые 4 потока – ещё и параметры потенциалов взаимодействия */
if (threadIdx.x < 4) coefs_ij[i] = coefs[i];
pos_j[i] = pos[i]; type_j[i] = type[i];
force_j[j] = make_float4(0, 0, 0, 0);
/* Синхронизация потоков. Выполнение программы за функцией __syncthreads() продолжится только после того, как все потоки завершат копирование данных в разделяемую память */
__syncthreads();
/* Цикл, в котором суммируется сила, действующая на i -ю частицу со стороны остальных. Индекс j изменяется до N + i для того, чтобы во всех потоках, независимо от значения i, в этом цикле было одинаковое количество итераций. Фактически, при j ³ N внутри цикла ничего не делается */
for (j = i+1; j < N + i; j++)
{
if (j < N)
{
/* Функция force_ij возвращает силу, действующую между частицами i и j. Аргументами функции являются координаты частиц и параметры потенциала взаимодействия */
float4 Fij = force_ij(pos_i, pos_j[j], coefs_ij[type_i + type_j[j]]);
/* Применение 3-го закона Ньютона
force_i += Fij; force_j[j] -= Fij;
}
/* Синхронизация потоков, необходимая для устранения возможных конфликтов доступа к элементам массива force_j[j]: */
__syncthreads();
}
/* Получение окончательных результирующих сил
force[i] = force_i + force_j[i];
}
/* Функция расчёта парной силы force_ij. Возвращает 4-вектор с компонентами силы (четвёртый элемент – пустой). Спецификатор __device__ означает, что функция и вызывается, и исполняется графическим процессором */
__device__ float4 force_ij(float4 pos_i, float4 pos_j, float4 c)
{
float4 R = pos_i - pos_j; R.w = rsqrt(max(R * R, 1e-4));
return R * (c.x * R.w * R.w * R.w + pow(c.y * R.w, c.z));
}
1. Структура и принципы функционирования ЭВМ // http://dvoika.net/education/informat/eu_intro/i4.htm. 2008. 7с.
2. Коньков К.А., Карпов В.Е. Основы операционных систем. Курс лекций / К.А. Коньков, В.Е. Карпов. Интернет-университет информационных технологий. http://www.intuit.ru/department/os/osintro/8/. 2008. 76с.
3. Дацюк В.Н., Букатов А.А., Жегуло А.И. Методическое пособие по курсу "Многопроцессорные системы и параллельное программирование" / В.Н. Дацюк, А.А. Букатов, А.И. Жегуло. Ростовский государственный университет. http://rsusu1.rnd.runnet.ru/tutor/method/m1/page09_3.html. 2008. 225с.
4. Ершова Н.Ю., Соловьев А.В. Организация вычислительных систем. Курс лекций / Н.Ю. Ершова, А.В. Соловьев. Интернет-университет информационных технологий. http://www.intuit.ru/department/hardware/csorg/10/. 2008. 102с.
5. Кузьминский М. Tera Computer // Computerworld. 1997. №37. C. 240. http://www.osp.ru/cw/1997/37/24023/
6. Воеводин В.В. Параллельная обработка данных. Курс лекций / В.В. Воеводин. Лаборатория Параллельных Информационных Технологий, НИВЦ МГУ. 2008. 78с. http://parallel.ru/vvv/lec4.html
7. Семенов Ю.А. Алгоритмы и протоколы каналов и сетей передачи данных. Курс лекций / Ю.А. Семенов. Интернет-университет информационных технологий. http://www.intuit.ru/department/network/algoprotnet/10/. 2007. 95с.
8. Богданов А.В., Станкова Е.Н., Мареев В.В., Корхов В.В. Архитектуры и топологии многопроцессорных вычислительных систем. Курс лекций / А.В. Богданов, Е.Н. Станкова, В.В. Мареев, В.В. Корхов. Интернет-университет информационных технологий. http://www.intuit.ru/department/hardware/atmcs/6/. 2008. 96с.
9. Богданов А., Мареев В., Станкова Е., Корхов В. Лекция 2. Архитектура вычислительных систем. // Архитектуры и топологии многопроцессорных вычислительных систем. Электронный учебник / А. Богданов, В. Мареев, Е. Станкова, В. Корхов. http://www.informika.ru/text/teach/topolog/2.htm. 2008. 96с.
10. Озеров С. Параллельное программирование // Компьютера Online. 2005. http://www2.computerra.ru/hitech/242551/ 8c.
11. Немнюгин С.А., Стесик О.Л. Параллельное программирование для многопроцессорных вычислительных систем / С.А. Немнюгин, О.Л. Стесик. СПб.: БХВ-Петербург, 2002. 400 с.
12. Воробьев А., Медведев A. Наступление ATI Technologies продолжается: RADEON X1900 XTX/XT (R580) // http://www.ixbt.com/video2/r580-part1.shtml. 2006. 6с.
13. Kirk D, Hwu W. Programming Massively Parallel Processors / D. Kirk, W. Hwu. ECE 498AL1, University of Illinois, Urbana-Champaign, 2007.
14. Графический конвейер / http://ru.wikipedia.org/wiki/ - Википедия. 2008. 19с.
15. Лаборатория Параллельных информационных технологий НИВЦ МГУ. История развития / http://parallel.ru/ - Информационно-аналитический центр по параллельным вычислениям. 2008. 2с.
16. Медведев А. NVIDIA GeForce 7800 GTX 256MB PCI-E. Часть 1 - Теория и архитектура // http://www.ixbt.com/video2/g70-part1.shtml. 2005. 10с.
17. P. Gibbon, G. Sutmann, Long-Range Interactions in Many-Particle Simulation, Quantum Simulations of Complex Many-Body Systems: From Theory to Algorithms, Lecture Notes, J. Grotendorst, D. Marx, A. Muramatsu (Eds.), NIC Series, Vol. 10, 467–506, (2002).
18. Amara G. Amara's Recap of Particle Simulation Methods // http://www.amara.com/ftpstuff/nbody.txt. 2008. 23c.
19. P. P. Ewald, Die Berechnung optischer und elektrostatischer Gitterpotentiale, Ann. Phys. 64, 253 (1921).
20. J. W. Perram, H. G. Petersen, and S. W. D. Leeuw, An algorithm for the simulation of condensed matter which grows as the N3/2 power of the number of particles, Mol. Phys. 65, 875–893 (1988).
21. C. K. Birdsall and A. B. Langdon, Plasma Physics via Computer Simulation, (McGraw-Hill, New York, 1985).
22. Хокни Р., Иствуд Дж. Численное моделирование методом частиц. Пер. с англ. М.: Мир 1987. 640 с. / R.W. Hockney and J.W. Eastwood, Computer Simulation Using Particles, Institute of Physics Publishing. 1988. 650 с.
23. J. Barnes and P. Hut, A hierarchical O(NlogN) force-calculation algorithm, Nature 324, 446–449 (1986).
24. L. Hernquist, Hierarchical N-body methods, Comp. Phys. Commun. 48, 107–115 (1988).
25. L. Greengard and V. Rokhlin, A fast algorithm for particle simulations, J. Comp. Phys. 73, 325–348 (1987).
26. H. Cheng, L. Greengard, and V. Rohklin, A fast adaptive multipole algorithm in three dimensions, J. Comp. Phys. 155, 468–498 (1999).
27. K. E. Schmidt and M. A. Lee, Implementing the fast multipole method in three dimensions, J. Stat. Phys. 63, 1223–1235 (1991).
28. K. Esselink, A comparison of algorithms for long-range interactions, Comp. Phys. Commun. 87, 375–395 (1995).
29. R. K. Kalia, S. de Leeuw, A. Nakano and P. Vashishta, Molecular dynamics simulations of Coulombic systems on ditributed-memory MIMD machines, Comp. Phys. Commun. 74, 316–326 (1993).
30. J. V. L. Beckers, C. P. Lowe, and S. W. de Leeuw, An iterative PPPM method for simulating Coulombic systems on distributed memory parallel computers, Mol. Sim. 20, 369–383 (1998).
31. L. Greengard and W. D. Groop, A parallel version of the fast multipole method, Comp. Math. Applic. 20, 63–71 (1990).
32. Warren, M. S., J. K. Salmon, and D. J. Becker. 1997. Pentium Pro inside: I. A treecode at 430 Gigaflops on ASCI Red; II. Price/performance of $50/Mflop on Loki and Hyglac. Proc. Supercomputing '97, November, online at http://www.supercomp.org/sc97/proceedings
33. Walker J.R. and Catlow C.R. Structural and dynamic properties of UO2 at high temperatures, J. Phys. C. Solid State Phys., v.14, 979–983 (1981).
34. Купряжкин А.Я. и др. Моделирование нестехиометрической двуокиси урана методом молекулярной динамики. Часть II. / А.Я. Купряжкин, К.А. Некорасов, А.Н. Жиганов. Отчет по НИР УрО АТН РФ, Екатеринбург, 2004. 63с.
35. Matzke H. Nonstoichiometric oxides, Ed. O. Toff Sorensen. New York, 155–232 (1981).
36. Купряжкин А.Я., Жиганов А.Н., Рисованый Д.В., Рисованый В.Д., Голованов В.Н. Диффузия кислорода в диоксиде урана в области фазовых переходов, ЖТФ, 2004, т. 74, вып. 2
37. Thermophysical Properties Database of Materials for Light Water Reactors and Heavy Water Reactors // IAEA-TECDOC-1496, 2006, ISBN 92-0-104706-1. http://www-pub.iaea.org/MTCD/publications/PDF/te_1496_web.pdf
38. Molecular dynamics // http:// en.wikipedia.org/wiki/Molecular_dynamics - Википедия. 2008. 13с.
39. Sindzingre P., Gillan M.J. A molecular dynamics study of solid and liquid UO2 // J. Phys. C: Solid State Phys. 1988. V. 21, P. 4017-4031.
40. Karakasidis T., Lindan P.J.D. A comment on a rigid-ion potential for UO2 // J. Phys.: Cond. Matter. 1994. V. 6, P. 2965-2969.
41. Walker J.R., Catlow C.R.A. Structural and dynamic properties of UO2 at high temperatures // J. Phys. C: Solid State Phys. 1981 V. 14, L. 979-983.
42. Busker G., Chroneos A., Grimes R.W. Solution mechanisms for dopant oxides in yttria // J. American Ceramics Soc. 1999. V. 82. P. 1553–1559.
43. Morelon N-D., Ghaleb D., et al. A new empirical potential for simulating the formation of defects and their mobility in uranium dioxide // Phil. Mag. 2003. V. 83. P. 1533–1550.
44. Gibbon P., Sutmann G.. Long-Range Interactions in Many-Particle Simulation, Quantum Simulations of Complex Many-Body Systems: From Theory to Algorithms, Lecture Notes, J. Grotendorst, D. Marx, A. Muramatsu (Eds.) // NIC Series. 2002. V. 10. P. 467–506.
45. Ryabov V.А. Constant pressure–temperature molecular dynamics on a torus // Physics Letters A. 2006. V. 359. P. 61–65.
46. Интегрирование Верлета // http://en.wikipedia.org/wiki/Verlet integration - Википедия. 2008. 6с.
47. Allen М.Р., Tildesley D.J. Computer simulations of liquids // M.P. Allen, D.J. Tildesley. New York: Oxford University Press Inc. 1987. 479c.
48. Brent R.P. An algorithm with guaranteed convergence for finding a zero of a function // Computer Journal. 1971. V 14. P. 422–425.
49. Nelder J.A., Mead R. A simplex method for function minimization // Computer Journal 1965. V. 7 P. 308–313.
50. Kurosaki K., Yamada K. et al. Molecular dynamics study of mixed oxide fuel // J. Nucl. Mater. 2001. V. 294 P. 160-167.
51. Basak C.B., Sengupta A.R., Kamath H.S. Classical molecular dynamics simulation of UO2 to predict thermophysical properties // J. of Alloys and Compounds. 2003. V. 360 P. 210–216.
52. Поташников C.И., Боярченков А.С. и др. Высокоскоростное моделирование диффузии ионов урана и кислорода в UO2 // Труды отраслевого семинара «Реакторное материаловедение», Димитровград. 2005.
53. Поташников C.И., Боярченков А.С. и др. Поточно-параллельное моделирование диффузии в нанокристаллах // Труды XII Национальной конференции по росту кристаллов «НКРК-2006», Институт кристаллографии РАН (2006).
54. Поташников C.И., Боярченков А.С. и др. Моделирование массопереноса в диоксиде урана методом молекулярной динамики с использованием графических процессоров // Международный научный журнал «Альтернативная энергетика и экология». 2007. Т. 5 С. 86–93. http://isjaee.hydrogen.ru/pdf/AEE0507/ISJAEE05-07_Potashnikov.pdf
55. Potashnikov S.I., Boyarchenkov A.S. et al. Molecular dynamic modeling of mass transport and empirical fitting of pair potentials in nuclear oxide fuel using graphics processing units // Proceedings of the 8th Russian Conference on “Reactor Materials”, Dimitrovgrad. 2007.
56. Majumdar S. N., Sengupta A.M. Thermo Physical and Thermo Mechanical Properties of Nuclear fuel for Thermal and Fast Reactor // IANCAS Bulletin on Nuclear Materials. 2005. V. 4. P. 226–236.
57. Fritz I.J. Elastic properties of UO2 at high pressure // J. of Applied Physics. 1976. V 47. P. 4353–4358.
58. Freeman G.C., Benson P.I., Dempsey E.L. Calculation of cohesive and surface energies of thorium and uranium oxides // J. of the American Ceramics Society. 1963. V. 46. P. 43-47.
59. Browning P., Hyland G.J., Ralph J. The origin of the specific heat anomaly in solid urania // High Temperatures-High Pressures. 1983. V. 15. P. 169-178.
60. Matzke Hj. Atomic transport properties in UO2 and mixed oxides (U,Pu)O2 // J. Chem. Soc. Faraday Trans. 1987. V. 83. P. 1121–1142.
61. Potashnikov S.I., Nekrassov K.A. et al. Investigation of mechanisms of structural disordering of uranium dioxide with methods of molecular dynamics, lattice statics // Proceedings of the 8th Russian Conference on “Reactor Materials”, Dimitrovgrad (2007).
62. Ralph J. Specific Heat of UO2, ThO2, PuO2 and the Mixed Oxides by Enthalpy Data Analysis // J. Chem. Soc. Faraday Trans. 1987. V. 83. P. 1253–1262.
63. Ronchi C., Hyland G.J. Analysis of recent measurements of the heat capacity of uranium dioxide // J. of Alloys and Compounds 1994. V. 213/214. P. 159–168.
64. Hutchings M.T. High-temperature studies of UO2 and ThO2 using neutron scattering techniques // J. Chem. Soc. Faraday Trans. 1987. V. 83. P. 1083–1103.
65. Hiernaut J.P., Hyland G.J. Premelting transition in uranium dioxide // Int. J. Thermophys. 1993. V. 14. P. 259–283.
66. Поташников С.И., Боярченков А.С. и др. Молекулярно-динамическое восстановление межчастичных потенциалов в диоксиде урана по тепловому расширению // Международный научный журнал «Альтернативная энергетика и экология» 2007. Т. 8. С. 43–52.
67. NVIDIA Corp. CUDA Technical Training / NVIDIA Corp. 2701 San Tomas Expressway, Santa Clara, CA 95050: NVIDIA Corp. www.nvidia.com. 2008. 146 c.
68. NVIDIA Corp. NVIDIA CUDA Compute Unified Device Architecture. Programming Guide Version 2.0 / NVIDIA Corp. 2701 San Tomas Expressway, Santa Clara, CA 95050: NVIDIA Corp. www.nvidia.com. 2008. 107 c.
69. Боярченков А.С., Поташников С.И. Использование графических процессоров и технологии CUDA для задач молекулярной динамики // Вычислительные методы и программирование. Новые вычислительные технологии. http://num-meth.srcc.msu.su. 2008.
Приложение 1
Операторы и функции языка HLSL, использованные в курсе лекций
|
|
|
|
|
Дата добавления: 2014-12-07; Просмотров: 866; Нарушение авторских прав?; Мы поможем в написании вашей работы!