КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Структура и режимы работы
|
|
|
|
Лекция 5. Центральный процессор современных PC.
В компьютере обязательно должен присутствовать центральный процессор (Central Processing Unit, CPU), который исполняет основную программу. В многопроцессорной системе функции центрального процессора распределяются между несколькими обычно идентичными процессорами для повышения общей производительности системы, а один из них назначается главным. В помощь центральному процессору в компьютер часто вводят сопроцессоры, ориентированные на эффективное исполнение каких-либо специфических функций. Широко распространены математические сопроцессоры, обрабатывающие числовые данные в формате с плавающей точкой; графические сопроцессоры, выполняющие геометрические построения и обрабатывающие графические изображения; сопроцессоры ввода-вывода, разгружающие центральный процессор от несложных, но многочисленных операций взаимодействия с устройствами. Бывают и другие сопроцессоры, однако все они несамостоятельны – исполнение основного вычислительного процесса осуществляется центральным процессором, который в соответствии с программой выдает «задания» сопроцессорам на исполнение их «партий».
Процессор фон-неймановской машины, фактически, может выполнять только один процесс, передавая управление от инструкции к инструкции согласно исполняемой программе. При этом могут исполняться переходы, ветвления и вызовы процедур, но вся эта цепочка запрограммирована разработчиком программы. Для реакции на события, асинхронные по отношению к исполняемому в данный момент процессу, используют аппаратные прерывания.
5.1. Архитектура и микроархитектура процессоров
Существует две основные архитектуры процессоров. Первая называется RISC (Reduced Instruction Set Computer) — компьютер с уменьшенным набором команд. Идея этой архитектуры основывается на том, что процессор большую часть времени тратит на выполнение ограниченного числа инструкций (например, переходов или команд присваивания), а остальные команды используются редко. Разработчики RISC-архитектуры создали «облегченный» процессор. Благодаря упрощенной внутренней логике (меньшему числу команд, менее сложным логическим контурам), значительно сократилось время выполнения отдельных команд и увеличилась общая производительность.
Вторая архитектура имеет сложную систему команд, она называется CISC (Complex Instruction Set Computer) — компьютер со сложной системой команд. Архитектура CISC подразумевает использование сложных инструкций, которые можно разделить на более простые. Все х86-совместимые процессоры принадлежат к архитектуре CISC.
Под архитектурой процессора понимается его программная модель, то есть программно-видимые свойства. Основные программно-видимые свойства процессора – это набор его регистров, система команд (определяющая также работу с памятью) и механизм обработки прерываний. Процессоры х86 являются явно выраженными представителями CISC-архитектуры: по сложности системы команд им нет равных, при этом базовых архитектурных регистров довольно мало. По мере развития семейства в процессоры вводят все более мощные команды, позволяющие сокращать число инструкций, требуемое для решения одних и тех же задач. Однако эти команды все сложнее исполнять. Количество архитектурных регистров увеличивается: появились блоки ММХ, ХММ, а в 64-битных расширениях еще и 8 дополнительных общих регистров.
Под микроархитектурой понимается внутренняя реализация программной модели. Для одной и той же архитектуры IA-32 разными фирмами и в разных поколениях применяются существенно различающиеся микроархитектурные реализации: при этом, естественно, стремятся к максимальному повышению производительности (скорости исполнения программ). Начиная с процессоров Р6 (и AMD К5), в микроархитектуре применяется RISC-ядро, исполняющее микрооперации (uOps), на которые раскладываются сложные инструкции х86. В результате производительность процессора (по скорости выполнения инструкций х86) зависит от способа разложения и скорости исполнения микроинструкций. При этом повышать производительность можно различными способами: ускорять выполнение микроопераций (за счет повышения тактовой частоты), по возможности распараллеливать выполнение микроопераций, сокращать число микроопераций, требуемых для исполнения одной инструкции х86. У лидеров «процессоростроения» – Intel и AMD – подходы к оптимизации различаются: при сопоставимой производительности процессоры AMD работают на более низких тактовых частотах. Однако заметим, что повышение производительности процессоров х86 обходится слишком дорого (по сравнению с «чистыми» RISC-архитектурами) – требует очень сложных управляющих устройств, на которые и уходит значительная часть транзисторов процессора и которые, к тому же, выделяют значительную мощность. Компьютеры на «чистых» RISC-процессорах (например, Power MAC) обеспечивают ту же прикладную производительность, что и IBM PC на Pentium 4, но при этом тактовая частота RISC-процессоров в несколько раз ниже частоты CISC-процессоров Pentium 4.
На рис.5.1 приведена общая структура современного процессора. Процессор содержит следующие блоки:
1) Декодер команд CISC - RISC – Instrution Decoder.
2) Блок предсказания переходов и таблица переходов – Prediction Table.
3) Блок распределения инструкций – Instrution Control (72–entry).
4) Регистры хранения декодированных команд TLB (Translation Lookside Buffer, буфер быстрого преобразования адреса).
5) Конвейеры с плавающей точкой FPU (MMX, SSE, 3Dnow!)
6) Регистры и блок их быстрого переименования – Stack Rename.
7) Конвейер целочисленных вычислений – Integer.
8) Блок выгрузки-загрузки данных – Load/Store.
9) L1 Tag – кэш 1-го уровня для хранения инструкций.
10) L1 Data – кэш 1-го уровня для хранения данных.
11) L2 – кэш 2-го уровня.
12) Интерфейс 64 бита - Interface.
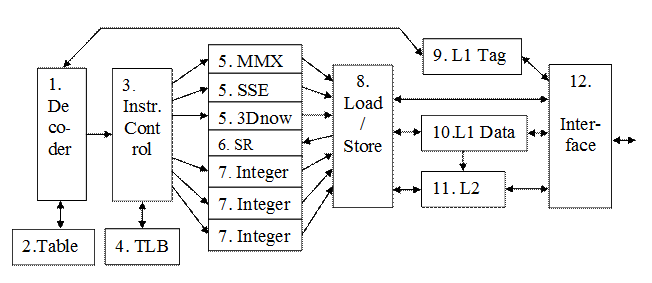
Рис. 5.1. Структура современного процессора
Конвейеризация (pipelining) предполагает, что каждая инструкция обрабатывается за несколько этапов, причем каждый этап выполняется на своей ступени конвейера процессора. При выполнении инструкция продвигается по конвейеру по мере освобождения последующих ступеней. Таким образом, на конвейере одновременно может обрабатываться несколько последовательных инструкций.
Скалярным называют процессор с единственным конвейером, к этому типу относятся все процессоры Intel до класса 486 включительно. Суперскалярный (superscalar) процессор имеет более одного конвейера (Pentium – два); эти конвейеры способны обрабатывать инструкции параллельно.
Инструкции переходов и особенно ветвлений нарушают непрерывность работы начальных ступеней конвейера, поскольку они должны начинать выборку и декодирование инструкций с нового, заранее неизвестного адреса. Предсказание переходов (branch prediction) позволяет продолжать выборку и декодирование потока инструкций после выборки инструкции ветвления (условного перехода), не дожидаясь проверки самого условия. В процессорах прежних поколений инструкция перехода приостанавливала конвейер (выборку инструкций) до исполнения собственно перехода, на чем, естественно, терялась производительность. Предсказание переходов направляет поток выборки и декодирования по одной из ветвей, при этом используется ряд методов предсказания:
· При статическом предсказании (схема заложена в процессор) переходы по одним условиям, вероятнее всего, произойдут, а по другим – нет. Переходы назад скорее произойдут (это типичный цикл), вперед – нет (типично для обработки ошибок).
· Динамическое предсказание опирается на предысторию вычислительного процесса – для каждой конкретной команды перехода (ее адреса в памяти) накапливается статистика поведения, на основе которой предсказывается переход. Для динамического предсказания в процессор вводят таблицу ВТВ (Branch Table Buffer – буфер таблицы переходов), напоминающую кэш с ассоциативным поиском.
· Программные «намеки» (hints) – новые префиксы инструкций (появились в Р4), перекрывающие статическое предсказание. Намеки закладываются в программный код на этапе компиляции.
Для того, чтобы процессор мог параллельно обрабатывать несколько инструкций, программный код должен быть написан (скомпилирован) так, чтобы в «поле зрения» процессора (то есть на его конвейере) оказывалось побольше фактически независимых друг от друга инструкций. В процессорах RISC-архитектур, как правило, много универсальных регистров, что располагает к написанию кода, удобного для параллельного исполнения. Малое число и неравноправность основных регистров х86 не располагают к программированию с учетом параллельности исполнения. Однако если несколько инструкций, обращающихся к одному и тому же регистру, не имеют фактических зависимостей по данным (не используют результаты друг друга), их можно исполнять одновременно в разных физических регистрах процессора (архитектурно невидимых), которых может быть много. Это делается путем переименования регистров (register renaming) – временного сопоставления физических регистров логическим с отслеживанием правильной последовательности смены состояний архитектурных (логических) регистров.
Продвижение данных (data forwarding) подразумевает начало исполнения инструкции до готовности всех операндов. При этом выполняются все возможные действия, и декодированная инструкция с одним операндом помещается в исполнительное устройство, где дожидается готовности второго операнда, выходящего с другого исполнительного устройства.
При исполнении по предположению, называемом также спекулятивным (speculative execution), используется результат предсказаний переходов: инструкции по предсказанной ветви перехода не только декодируются, но и по возможности исполняются до проверки условия перехода. Если предсказание сбывается, то труд оказывается не напрасным; если не сбывается, приходится выполнять откат – в этом случае конвейер оказывается недогруженным и простаивает несколько тактов (как минимум столько, сколько ступеней у конвейера).
Исполнение с изменением последовательности инструкций (out-of-order execution), свойственное RISC-архитектуре, теперь реализуется и для процессоров х86. При этом изменяется порядок внутренних манипуляций данными, а внешние (шинные) операции ввода-вывода и записи в память выполняются, конечно же, в порядке, предписанном программным кодом. Однако эта способность процессора в наибольшей степени может блокироваться несовершенством программного кода (особенно 16-битных приложений), если он генерируется без учета возможности изменения порядка исполнения инструкций.
5.2. Режимы работы процессоров
32-битные процессоры могут работать в одном из следующих режимов:
· Режим реальной адресации (real address mode), или просто реальный режим (real mode), полностью совместим с 8086. В этом режиме возможна адресация до 1 Мбайт физической памяти (на самом деле, как и у 80286, почти на 64 Кбайт больше).
· Защищенный режим виртуальной адресации (protected virtual address mode), или просто защищенный режим (protected mode). В этом режиме у процессора включаются механизмы сегментации и страничной трансляции. Механизм сегментации позволяет поддерживать виртуальную память объемом до 64 Тбайт. На практике используется только страничная трансляция, благодаря которой каждой задаче предоставляется до 4 Гбайт виртуального адресного пространства. По умолчанию и адреса, и операнды имеют разрядность 32 бита. В защищенном режиме процессор может выполнять дополнительные инструкции, недоступные в реальном режиме; ряд инструкций, связанных с передачей управления, обработкой прерываний, и некоторые другие выполняются иначе, чем в реальном режиме.
· Режим виртуального процессора 8086 (Virtual 8086 Mode, V86) является особым состоянием задачи защищенного режима, в котором процессор функционирует как 8086 (16-битные адрес и данные). На одном процессоре в таком режиме могут параллельно исполняться несколько задач с изолированными друг от друга ресурсами. При этом использование физического адресного пространства памяти управляется механизмами сегментации и трансляции страниц. Попытки выполнения недопустимых команд, выхода за рамки отведенного пространства памяти и разрешенной области ввода-вывода контролируются системой защиты. Более эффективен расширенный режим виртуального процессора 8086 (Enhanced Virtual 8086 Mode, EV86), в котором оптимизирована виртуализация прерываний.
· «Нереальный» режим (unreal mode, он же big real mode ) – это «неофициальный» режим, который поддерживают все 32-битные процессоры. Он позволяет адресоваться к 4-гигабайтному пространству памяти. В этом режиме инструкции исполняются так же, как и в реальном режиме, но с помощью дополнительных сегментных регистров FS и GS программы получают непосредственный доступ к данным во всей физической памяти.
· В режиме системного управления (System Management Mode, SMM) процессор выходит в иное, изолированное от остальных режимов пространство памяти. Этот режим используется в служебных и отладочных целях. С его помощью, например, скрытно выполняются функции управления энергопотреблением, эмулируются обращения к несуществующим аппаратным средствам (эмуляция клавиатуры и мыши PS/2 для USB).
5.3. Программная модель процессоров x86
Cогласно концепции фон Неймана процессор должен состоять из следующих модулей: арифметико-логическое устройство (АЛУ), контроллер (блок управления) и регистры.
Контроллер управляет получением инструкций из памяти и их декодированием. Контроллер не обрабатывает инструкцию: после декодирования он просто передает ее по внутренней шине управления к другим модулям, которые выполняют необходимое действие.
Арифметико-логическое устройство (АЛУ) выполняет арифметические и логические действия над данными. Логическая часть АЛУ выполняет основные логические действия над данными, например, логическое сложение и умножение (ИЛИ, И), а также исключающее ИЛИ. Еще одна функция АЛУ, которую выполняет устройство циклического сдвига (barrel-shifter), заключается в сдвигах битов влево и вправо.
Для выполнения процессором инструкции необходимо намного меньше времени, чем для чтения этой инструкции из памяти. Чтобы сократить время ожидания памяти, процессор снабжен временным хранилищем инструкций и данных – регистрами. Размер регистра – несколько байтов, но зато доступ к регистрам осуществляется почти мгновенно.
Среди регистров обязательно должны присутствовать следующие группы:
– регистры общего назначения;
– регистры состояния;
– счетчики.
Регистры общего назначения содержат рабочие данные, полученные из памяти. Регистры состояния содержат текущее состояние процессора (или состояние АЛУ). Последняя группа – это счетчики. Согласно теории фон Неймана, должен быть хотя бы один регистр из этой группы – счетчик команд, содержащий адрес следующей инструкции.
Чтобы программировать на языке ассемблера, необходимо знать имена регистров и общий принцип работы команд.
|
|
|
|
|
Дата добавления: 2014-12-07; Просмотров: 512; Нарушение авторских прав?; Мы поможем в написании вашей работы!