КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Директиви препроцесора
|
|
|
|
Препроцесором в мові C ++ називається попередній етап компіляції, що формує остаточний варіант тексту програми. У мові С#, нащадку С++, препроцесор практично відсутній, але деякі директиви збереглися. Призначення директив - виключати з процесу компіляції фрагменти коду при виконанні певних умов, виводити повідомлення про помилки і попередження, а також структурувати код програми. Кожна директива розташовується на окремому рядку і не закінчується крапкою з комою, на відміну від операторів мови. У одному рядку з директивою може розташовуватися тільки коментар виду //. Перелік і короткий опис директив приведені в таблиці 12.4.
Розглянемо детальніше застосування директив умовної компіляції. Вони використовуються для того, щоб виключити компіляцію окремих частин програми. Це буває корисно при відладці або, наприклад, за підтримки декількох версій програми для різних платформ.
Таблиця 12.4
Директиви препроцесора
| Найменування | Опис |
| #define, #undef | Визначення (наприклад, #define DEBUG) і відміна визначення (#undef DEBUG) символьної константи, яка використовується директивами умовної компіляції. Директиви розміщуються до першої лексеми одиниці компіляції. Допускається повторне визначення однієї і тієї ж константи |
| #if,#elif, #else, #endif | Директиви умовної компіляції. Код, що знаходиться в області їх дії, компілюється або пропускається залежно від того, чи була раніше визначена символьна константа |
| #line | Завдання номера рядка і імені файлу, про який видаються повідомлення, що виникають при компіляції (наприклад, #line 200 "ku_ku.txt"). При цьому в діагностичних повідомленнях компілятора ім'я компільованого файлу замінюється вказаним, а рядки нумеруються, починаючи із заданого першим параметром номера |
| # error, #warning | Виведення при компіляції повідомлення, вказаного в рядку директиви. Після виконання директиви компіляція припиняється (наприклад, #error Далі компілювати не можна). Після виконання директиви #warning компіляція продовжується |
| #region, #endregion | Визначення фрагмента коду, який можна буде скрутити або розвернути засобами редактора коду. Фрагмент розташовується між цими директивами |
| #pragma | Дозволяє відключити (#pragma warning disable) або відновити (#pragma warning restore) видачу всіх або перерахованих в директиві попереджень компілятора |
Формат директив:
# константний_вираз
…
[ #elif константний_вираз
...]
[ #elif константний_вираз
...]
[ #else
... ]
#endif
Кількість директив #elif довільна. Блоки коду, що виключаються, можуть містити як описи, так і виконуваних операторів. Константний вираз може містити одну або декілька символьних констант, об'єднаних знаками операцій = =,!=,!, && і ||. Також допускаються круглі дужки. Константа вважається рівною true, якщо вона була раніше визначена за допомогою директиви # define. Приклад застосування директив приведений на лістингу 12.4.
Лістинг 12.4. Застосування директив умовної компіляції
// #define VAR1
// #define VAR2
using System;
namespace ConsoleApplication1
{
class Classl
{
#if VAR1
static void F(){ Console.WriteLine("Вариант 1"): }
#elif VAR2
static void F(){ Console.WriteLine("Вариант 2"); }
#else
static void F(){ Console.WriteLine("Основной вариант"); }
#endif
static void Main()
{
F();
}
}
}
Залежно від того, визначення якої символьної константи розкоментувати, в компіляції братиме участь один з трьох методів F.
Директива #define застосовується не тільки у поєднанні з директивами умовної компіляції. Можна застосовувати її разом із стандартним атрибутом Conditional для умовного управління виконанням методів. Метод виконуватиметься, якщо константа визначена. Приклад приведений в лістингу 12.5. Зверніть увагу на те, що для застосування атрибуту необхідно підключити простір імен System.Diagnostics.
Лістинг 12.5. Використання атрибуту Conditional
// #define VAR1
#define VAR2
using System;
using System.Diagnostics;
namespace ConsoleApplication1
{
class Classl
{
[Conditional ("VAR1")]
static void A(){ Console.WriteLine(" Виконується метод A"); }
[Conditional ("VAR2")]
static void B(){ Console.WriteLine(" Виконується метод В"); }
static void Main()
{
A(); B();
}
}
}
У методі Main записані виклики обох методів, проте в даному випадку буде виконаний тільки метод В, оскільки символьна константа Var1 не визначена.
РОЗДІЛ 13. СТРУКТУРИ ДАНИХ, КОЛЕКЦІЇ І КЛАСИ-ПРОТОТИПИ
У даному розділі приводиться огляд основних структур даних і їх реалізація в бібліотеці .NET у вигляді колекцій. Крім того, описуються класи-прототипи (generics), часткові типи (partial types) і типи, що обнуляються (nullable types).
13.1. Абстрактні структури даних
Найчастіше в програмах використовуються наступні структури даних: масив, список, стек, черга, бінарне дерево, хеш-таблиця, граф і множина. Далі надані короткі характеристики кожній їз цих структур.
Масив - це кінцева сукупність однотипних величин. масив займає безперервну область пам'яті і надає доступ до своїх елементів по індексу. Пам'ять під масив виділяється до початку роботи з ним і згодом не змінюється.
У списку кожен елемент пов'язаний з наступним і, можливо, з попереднім. У першому випадку список називається однозвязковим, в другому - двозвязковим. Також застосовуються терміни однонапрямковим ідвонапрямковим. Якщо останній елемент зв'язати покажчиком з першим, виходить кільцевий список. Кількість елементів в списку може змінюватися в процесі роботи програми.
Кожен елемент списку містить ключ, що ідентифікує цей елемент. Ключ зазвичай буває або цілим числом, або рядком і є частиною даних, що зберігаються в кожному елементі списку. Як ключ в процесі роботи із списком можуть виступати різні частини даних. Наприклад, якщо створюється список із записів, що містять прізвище, рік народження, стаж роботи і стать, будь-яка частина запису може виступати як ключ: при впорядковуванні списку по зростанню ключа буде прізвище, а при пошуку, наприклад, ветеранів праці ключем можна зробити стаж. Ключі різних елементів списку можуть збігатися.
Над списками можна виконувати наступні операції:
· додавання елементу в кінець списку;
· читання елементу із заданим ключем;
· вставка елементу в задане місце списку;
· видалення елементу із заданим ключем;
· впорядковування списку по ключу.
Список не забезпечує довільний доступ до елементу, тому при виконанні операцій читання, вставки і видалення виконується послідовний перебір елементів, поки не буде знайдений елемент із заданим ключем. Для списків великого об'єму перебір елементів може займати значний час, оскільки середній час пошуку елементу пропорційний кількості елементів в списку.
Стек - це окремий випадок однонапрямкового списку, додавання елементів в який і вибірка з якого виконуються з одного кінця, званого вершиною стека. Інші операції із стеком не визначені. При вибірці елемент виключається із стека. Говорять, що стек реалізує принцип обслуговування LIFO (Last In - First Out, останнім прийшов - першим пішов). Стек найпростіше уявити собі як закриту з одного кінця вузьку трубу, в яку кидають м'ячики. Дістати перший кинутий м'ячик можна тільки після того, як вийняті всі останні. Стеки широко застосовуються в системному програмному забезпеченні, компіляторах, в різних рекурсивних алгоритмах.
Черга - це окремий випадок однонапрямкового списку, додавання елементів в який виконується в один кінець, а вибірка - з іншого кінця. Інші операції з чергою не визначені. При вибірці елемент виключається з черги. Говорять, що чергу реалізує принцип обслуговування FIFO (First In - First Out, першим прийшов - першим пішов). Чергу найпростіше уявити собі, постоявши в ній час-другий. У програмуванні черги застосовуються, наприклад, в моделюванні, диспетчеризації завдань операційною системою.
Бінарне дерево - це динамічна структура даних, що складається з вузлів, кожен з яких містить окрім даних не більше двох посилань на різні бінарні піддерева. На кожен вузол є рівно одне посилання. Початковий вузол називається коренем дерева.
Приклад бінарного дерева приведений на рис. 13.1 (корінь зазвичай зображається зверху). Вузол, що не має піддерев, називається листом. Витікаючи вузли називаються предками, що входять - нащадками. Висота дерева визначається кількістю рівнів, на яких розташовуються його вузли.
Якщо дерево організоване таким чином, що для кожного вузла всі ключі його лівого піддерева менші ключа цього вузла, а всі ключі його правого піддерева - більші, воно називається деревом пошуку. Однакові ключі не допускаються.
У дереві пошуку можна знайти елемент по ключу, рухаючись від кореня і переходячи на ліве або праве піддерево залежно від значення ключа в кожному вузлі. Такий пошук набагато ефективніший пошуку за списком, оскільки час пошуку визначається висотою дерева, а вона пропорційна двійковому логарифму кількості вузлів.
Втім, швидкість пошуку в значній мірі залежить від порядку формування дерева: якщо на вхід подається впорядкована або майже впорядкована послідовність ключів, дерево вироджується в список. Для прискорення пошуку застосовується процедура балансування дерева, що формує дерево, піддерева якого розрізняються не більше ніж на один елемент. Бінарні дерева застосовуються для ефективного пошуку і сортування даних.
Хеш-таблиця, асоціативний масив, або словник - це масив, доступ до елементів якого здійснюється не по номеру, а по деякому ключу. Можна сказати, що це таблиця, що складається з пар “ключ-значення” (таблиця 13.1). Хеш-таблиця ефективно реалізує операцію пошуку значення по ключу. При цьому ключ перетвориться в число (хеш - код), яке використовується для швидкого знаходження потрібного значення в хеш-таблиці.
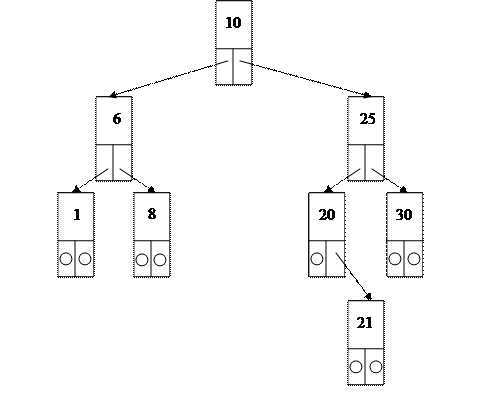
Рис. 13.1. Приклад бінарного дерева пошуку
Таблиця 13.1
Приклад хеш-таблиці
| Ключ | Значення |
| boy | хлопчик |
| girl | дівчинка |
| dog | собачка |
Перетворення виконується за допомогою хеш-функціі, або функції розстановки. Ця функція проводить які-небудь перетворення внутрішнього представлення ключа. Наприклад, обчислює середнє арифметичне кодів символів ключа. Якщо хеш-функція розподіляє сукупність можливих ключів рівномірно по множині індексів масиву, то доступ до елементу по ключу виконується майже так само швидко, як в масиві. Якщо хеш-функція генерує для різних ключів однакові хеш-коди, час пошуку зростає і стає порівнянним з часом пошуку в списку.
Сенс хеш-функціі полягає в тому, щоб відобразити широку множину ключів у вужчу множину індексів. При цьому неминуче виникають так звані колізії, коли хеш-функція формує для двох різних елементів одні і ті ж хеш-коди.
Граф - це сукупність вузлів і ребер, що сполучають різні вузли. Наприклад, можна уявити собі карту автомобільних доріг як граф з містами, як вузли і шосе між містами, як ребра. Множина реальних практичних завдань можна описати в термінах графів, що робить їх структурою даних, часто використовуваною при написанні програм.
Множина - це неврегульована сукупність елементів. Для множин визначені операції перевірки приналежності елементу множині, включення і виключення елементу, а також об'єднання, перетину і віднімання множин.
Описані структури даних називаються абстрактними, оскільки в них не задається реалізація допустимих операцій.
У бібліотеках більшості сучасних об'єктно-орієнтованих мов програмування представлені стандартні класи, що реалізовують основні абстрактні структури даних. Такі класи називаються колекціями, або контейнерами. Для кожного типу колекції визначені методи роботи з її елементами, не залежні від конкретного типу даних, які зберігаються в колекції, тому один і той же вид колекції можна використовувати для зберігання даних різних типів. Використання колекцій дозволяє скоротити терміни розробки програм і підвищити їх надійність.
Кожен вид колекції підтримує свій набір операцій над даними, і швидкодія цих операцій може бути різною. Вибір виду колекції залежить від того, що потрібно робити з даними в програмі і які вимоги пред'являються до її швидкодії. Наприклад, при необхідності частої вставки і видалення елементів з середини послідовності слід використовувати список, а не масив, а якщо включення елементів виконується головним чином в кінець або початок послідовності - чергу. Тому вивчення можливостей стандартних колекцій і їх грамотне застосування є необхідними умовами створення ефективних і професійних програм.
У бібліотеці.NET визначена множина стандартних класів, що реалізовують більшість перерахованих раніше абстрактних структур даних.
Основні простори імен, в яких описані ці класи:
· System.Collections;
· System.Col1ections.Specialized;
· System.Col1ections.Generiс.
У наступних розділах коротко описані основні елементи цих просторів імен.
13.2. Простір імен System.Collections
У просторі імен System.Collections визначені набори стандартних колекцій і інтерфейсів, які реалізовані в цих колекціях. У таблиці 13.2 приведені найбільш важливі інтерфейси.
Таблиця 13.2
Інтерфейси простору імен System.Collections
| Інтерфейс | Призначення |
| ICollection | Визначає загальні характеристики (наприклад, розмір) для набору елементів |
| IComparer | Дозволяє порівнювати два об'єкти |
| IDictionary | Дозволяє представляти вміст об'єкту у вигляді пар “ім'я-значення” |
| IDictionaryEnumerator | Використовується для нумерації вмісту об'єкту, що підтримує інтерфейс IDictionary |
Продовження таблиці 13.2
| Інтерфейс | Призначення |
| IEnumerable | Повертає інтерфейс IEnumerator для вказаного об'єкту |
| IEnumerator | Зазвичай використовується для підтримки оператора foreach відносно об'єктів |
| IHashCodeProvider | Повертає хеш-код для реалізації типу із застосуванням вибраного користувачем алгоритму хешування |
| IList | Підтримує методи додавання, видалення і індексування елементів в списку об'єктів |
У таблиці 13.3 перераховані основні колекції, визначені в просторі System. Collections.
Таблиця 13.3
Колекції простору імен System.Collections
| Клас | Призначення | Найважливіші з реалізованих інтерфейсів |
| ArrayList | Масив, що динамічно змінює свій розмір | IList, ICollection, IEnumerable, ICloneabl |
| BitArray | Компактний масив для зберігання бітових значень | ICollection, IEnumerable, ICloneable |
| Hashtable | Хеш-таблиця | IDictionary, ICollection, IEnumerable, ICloneable |
| Queue | Черга | ICollection, ICloneable, IEnumerable |
| SortedList | Колекція, відсортована по ключах. Доступ до елементів - по ключу або по індексу | IDictionary, ICollection, IEnumerable, ICloneable |
| Stack | Стек | ICollection, IEnumerable |
Простір імен System.Collections.Specialized включає спеціалізовані колекції, наприклад колекцію рядків StringCollection і хеш- таблицю із рядковими ключами StringDictionary.
Як приклад стандартної колекції розглянемо клас ArrayList.
13.3. Клас ArrayList
Основним недоліком звичайних масивів є те, що об'єм пам'яті, який потрібен для зберігання їх елементів, має бути виділений до початку роботи з масивом. Клас ArrayList дозволяє програмістові не піклуватися про виділення пам'яті і зберігати в одному і тому ж масиві елементи різних типів.
За умовчанням при створенні об'єкту типу ArrayList будується масив з 16 елементів типу object. Можна задати бажану кількість елементів в масиві, передавши його в конструктор або встановивши як значення властивості Capacity, наприклад:
ArrayList arrl = new ArrayList(); // створюється масив з 16 елементів
ArrayList arr2 = new ArrayList(1000); // створюється масив з 1000 елементів
ArrayList аrrЗ = new ArrayList();
arr3.Capacity = 1000; // кількість елементів задається
Основні методи і властивості класу Arraylist перераховані в таблиці 13.4.
Таблиця 13.4
Основні елементи класу Arraylist
| Елемент | Вигляд | Опис |
| Capacity | Властивість | Ємність масиву (кількість елементів, які можуть зберігатися в масиві) |
| Count | Властивість | Фактична кількість елементів масиву |
| Item | Властивість | Отримати або встановити значення елементу по заданому індексу |
| Add | Метод | Додавання елементу в кінець масиву |
| AddRange | Метод | Додавання серії елементів в кінець масиву |
| BinarySearch | Метод | Двійковий пошук у відсортованому масиві або його частині |
| Clear | Метод | Видалення всіх елементів з масиву |
| Clone | Метод | Поверхневе копіювання елементів одного масиву в інший масив |
| CopyTo | Метод | Копіювання всіх або частини елементів масиву в одновимірний масив |
| GetRange | Метод | Набуття значень підмножини елементів масиву у вигляді об'єкту типу Arraylist |
| IndexOf | Метод | Пошук входження елементу (повертає індекс елементу або -1, якщо елемент не знайдений) |
| Insert | Метод | Вставка елементу в задану позицію (по заданому індексу) |
| InsertRange | Метод | Вставка групи елементів, починаючи із заданої позиції |
| LastIndexOf | Метод | Пошук останнього входження елементу в одновимірний масив |
| Remove | Метод | Видалення першого входження заданого елементу |
| RemoveAt | Метод | Видалення елементу з масиву по індексу |
Продовження таблиці 13.4
| Елемент | Вигляд | Опис |
| RemoveRange | Метод | Видалення групи елементів з масиву |
| Reverse | Метод | Зміна порядку проходження елементів на зворотний |
| SetRange | Метод | Установка значень елементів масиву в заданому діапазоні |
| Sort | Метод | Впорядковування елементів масиву або його частини |
| TrimToSize | Метод | Установка ємності масиву рівною фактичній кількості елементів |
Клас ArrayList реалізований через клас Array, тобто містить закрите поле цього класу. Оскільки всі типи в С# є нащадками класу object, масив може містити елементи довільного типу. Навіть якщо в масиві зберігаються звичайні цілі числа, тобто елементи значущого типу, внутрішній клас є масивом посилань на екземпляри типу object, які є упакованим типом-значенням. Відповідно, при занесенні в масив виконується упаковка, а при витяганні - розпаковування елементу. Це не може не позначитися на швидкодії алгоритмів, які використовують ArrayList.
Якщо при додаванні елементу в масив виявляється, що фактичну кількість елементів масиву перевищує його ємність, вона автоматично подвоюється, тобто відбувається повторне виділення пам'яті і переписування туди всіх існуючих елементів.
Приклад занесення елементів в екземпляр класу ArrayList:
arrl.Add(123);
arrl.Add(-2);
arrl.Add("Вася");
Доступ до елементу виконується по індексу, проте при цьому необхідно явним чином привести отримане посилання до цільового типу, наприклад:
int а = (int) arrl [0];
int b = (int) arrl [l];
string s = (string) arrl [2];
Спроба приведення до невідповідного типу зберігається в елементі, викликає генерацію виключення InvalidCastException.
Для підвищення надійності програм застосовується наступний прийом: екземпляр класу ArrayList оголошується закритим полем класу, в якому необхідно зберігати колекцію значень певного типу, а потім описуються методи роботи з цією колекцією, які делегують свої функції методам ArrayList. Цей спосіб ілюструється в лістингу 13.1, де створюється клас для зберігання об'єктів типу Monster і похідних від нього.
Лістинг 13.1. Колекція об'єктів
using System;
using System.Collections;
namespace ConsoleApplicationl
{
class Monster { ... }
class Daemon: Monster { ... }
class Stado: IEnumerable
{
private ArrayList list;
public Stado() { list = new ArrayList(); }
public void Add(Monster m) { list.Add(m); }
public void RemoveAt(int i) {list.RemoveAt(i); }
public void Clear() { list.Clear(); }
public IEnumerator GetEnumerator()
{ return list.GetEnumerator(); }
}
class Classl
{
static void Main()
{
Stado stado = new Stado();
stado.Add(new Monster("Monia"));
stado.Add(new Monster("Monk"));
stado.Add(new Daemon ("Dimon", 3));
stado.RemoveAt(1);
foreach (Monster x in stado) x. Passport();
}
}
}
Результат роботи програми:
Monster Monia health = 100 ammo = 100
Daemon Dimon health = 100 ammo = 100 brain = 3
Недоліком цього рішення є те, що для кожного методу стандартної колекції доводиться описувати метод-оболонку, що викликає стандартний метод. У С# з'явилися класи-прототипи (generics), що дозволяють вирішити цю проблему. Ми розглянемо їх в наступному розділі.
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 765; Нарушение авторских прав?; Мы поможем в написании вашей работы!