КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Использование встроенного отладчика. 3 страница
|
|
|
|
int ch;
static char name [20]; /* память для имени выходного файла */
int count = 0;
if (argc < 2) /* проверяет, есть ли входной файл */
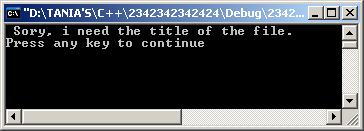
printf("Sory, i need the title of the file.\n");
else
{
if ((in = fopen(argv[1], "r"))!= NULL)
{
strcpy(name, argv[1]); /* копирует имя файла в массив */
strcat(name, ".red"); /* добавляет.red к имени */
out = fopen(name, " w"); /* открывает файл для записи */
while ((ch = getc(in))! = EOF)
if (count++ %3 ==0)
putc(ch, out); /* печатает каждый третий символ */
fclose(in);
fclose(out);
}
else
printf(" Я не смогла открыть файл\" %s\" \n", argv[1]);
}
}
Мы поместили программу в файл, названный reduce и применили эту программу к файлу, названному eddy, который содержал одну единственную строку
Даже Эдди нас опередил с детским хором.
Была выполнена команда
reduce eddy
и на выходе получен файл, названный eddy.red, который содержит
Дед спел тихо
Какая удача! Наш случайно выбранный файл сделал осмысленное сокращение.
Вот некоторые замечания по программе.
Вспомните, что argc содержит определенное количество аргументов, в число которых входит имя программного файла. Вспомните также, что с согласия операционной системы argv[0] представляет имя программы, т. е. в нашем случае reduce. Вспомните еще, что argv[1] представляет первый аргумент, в нашем случае eddy. Так как сам argv[1] является указателем на строку, он не должен заключаться в двойные кавычки в операторе вызова функции.
Мы используем argc, чтобы посмотреть, есть ли аргумент. Любые избыточные аргументы игнорируются. Помещая в программу еще один цикл, вы могли бы использовать дополнительные аргументы — имена файлов и пропускать в цикле каждый из этих файлов по очереди.
С целью создания нового имени выходного файла мы используем функцию strcpy() для копирования имени eddy в массив name. Затем применяем функцию strcat() для объединения этого имени с.red.
Программа требует, чтобы два файла были открыты одновременно, поэтому мы описали два указателя типа ' FILE'. Заметим, что каждый файл должен открываться и закрываться независимо от другого. Существует ограничение на количество файлов, которые вы можете держать открытыми одновременно. Оно зависит от типа системы, но чаще всего находится в пределах от 10 до 20. Можно использовать один и тот же указатель для различных файлов при условии, что они не открываются в одно и то же время. Мы не ограничиваемся использованием только функций getc() и putc() для файлов ввода-вывода. Далее мы рассмотрим некоторые другие возможности.
7.23.2. Использование функций getchar(), putchar(),fgetchar() и fputchar().
На самом деле два макроса getchar() и putchar() являются особыми реализациями макросов getc() и putc(), соответственно. Они всегда связаны со стандартными устройствами ввода (stdin) и вывода (stdout). Единственный способ их использования с другими файловыми потоками — переназначить стандартный ввод или стандартный вывод вне программы.
Два приведенных выше примера можно записать иначе, используя две рассматриваемые функции:
int ic;
ic = getchar();
и
putchar(ic);
Так же, как и getc() и putc(), getchar() и putсhar() реализованы как макросы. В случае ошибки функция putchar() возвращает значение EOF. Следующий фрагмент можно использовать для проверки ошибки вывода. Использование EOF для вывода может показаться немного сомнительным, однако это — технически корректно.
if(putchar(ic) =- EOF)
printf("An error has occurred writing to stdout"); /* При выводе на stdout произошла ошибка */
Макросам getchar() и putchar() эквивалентны функции fgetchar() и fputchar().
7.23.3. Использование функций getch() и putch().
Функции getch() и putch() являются полноценными низкоуровневыми функциями, тесно связанными с аппаратным обеспечением, — поэтому они не подпадают под стандарт ANSI С. В персональных компьютерах (ПК) эти функции не буферизируются; это означает, что они сразу же вводят символ, нажатый на клавиатуре. Однако, их можно переназначать, и поэтому они связаны не только с клавиатурой.
Функции getch() и putch() используются так же, как и getchar() и putchar(). Обычно программы, работающие на ПК, используют getch() для перехвата клавиш, которые игнорирует функция getcharO, например, PGUP, PGDN, HOME и END. Функция getch() видит символ, введенный с клавиатуры, сразу же после нажатия клавиши; символ возврата каретки для передачи введенного символа в программу не требуется. Эта возможность позволяет использовать getch() для обработки однократных нажатий клавиш, что невозможно с функциями getc() или getchar().
На ПК функция getch() работает совершенно по-другому, чем getc() и getchar(). Частично это объясняется тем, что в ПК легко можно распознать нажатие отдельной клавиши на клавиатуре. В других системах, подобных DEC и VAX С, аппаратура не может отслеживать отдельные нажатия клавиш. Обычно в этих системах выполняется эхо-отображение введенного символа и требуется нажатие клавиши возврата каретки, причем программа не видит нажатия этой клавиши до тех пор, пока не будут введены другие символы, и тогда при ее нажатии возвращается null-символ или десятичный ноль. Кроме того, функциональные клавиши не доступны, и при их нажатии результаты не достоверны.
7.24. Определение строк в программе.
Символьные строки представляют один из наиболее полезных и важных типов данных языка Си. Хотя до сих пор все время применялись символьные строки, мы еще не все знаем о них. Конечно, нам уже известно самое главное: символьная строка является массивом типа char, который заканчивается нуль-символом ('\0'). Здесь мы больше узнаем о структуре строк, о том, как описывать и инициализировать строки, как их вводить или выводить из программы, как работать со строками.
Ниже представлена работающая программа, которая иллюстрирует несколько способов создания строк, их чтения и вывода на печать. Мы.используем две новые функции: gets (), которая получает строку, и puts (), которая выводит строку. (Вы, вероятно, заметили сходство их имен с функциями getchar () и putchar ().) В остальном программа выглядит достаточно привычно.
/* работа со строками */
#include <stdio.h>
#define MSG " У вас, наверное, много талантов. Расскажите о некоторых."
/* константа символьной строки */
#define NULL 0
#define LIM 5
#define LINLEN 81 /* максимальная длина строки + 1 */
char m1[] = "Только ограничьтесь одной строкой.";
/* инициализация внешнего символьного массива */
char *m2 = " Если вы не можете вспомнить что-нибудь, придумайте.";
/* инициализация указателя внешнего символьного массива */
void main ()
{
char name[LINLEN];
static char talents [LINLEN];
int i;
int count = 0;
char *m3 = " \n Достаточно обо мне-- Как вас зовут?";
/* инициализация указателя */
static char *mytal[LIM] = {"Быстро складываю числа", "Точно умножаю", "Записываю данные", "Правильно выполняю команды", "Понимаю язык Си"};
/* инициализация массива строк */
printf(" Привет! Я Клайд, компьютер. У меня много талантов\n");
printf(" %s\n", " Позвольте рассказать о некоторых из них.");
puts(" Каковы они? Ах да, вот их неполный перечень.");
for (i = 0; i < LIM; i++)
puts(mytal[i]); /* печатает перечень талантов компьютера */
puts(m3);
gets(name);
printf (" Хорошо, %s, %s\n", name, MSG);
printf (" %s\n%s\n", m1, m2);
gets(talents);
puts(" Давайте, посмотрим, получил ли я этот перечень:");
puts(talents);
printf (" Спасибо за информацию, %s.\n", name);
}
Чтобы помочь вам разобраться в том, что делает эта программа, мы приводим результат ее работы:
Привет я Клайд, компьютер. У меня много талантов.
Позвольте рассказать о некоторых из них.
Каковы они? Ах да, вот их неполный перечень.
Быстро складываю числа.
Точно умножаю.
Записываю данные.
Правильно выполняю команды.
Понимаю язык Си
Достаточно обо мне — Как вас зовут?
Найджел Барнтвит
Хорошо, Найджел Барнтвит, у вас, наверное, много талантов.
Расскажите о некоторых.
Только ограничьтесь одной строкой.
Если вы не можете вспомнить что-нибудь, придумайте
Фехтование, пение тирольских песен, симуляция, дегустация сыра.
Давайте посмотрим, получил ли я этот перечень:
Фехтование, пение тирольских песен, симуляция, дегустация сыра.
Спасибо за информацию, Найджел Барнтвит
Тщательно исследуем программу. Но вместо того чтобы просматривать строку за строкой, применим более общий подход. Сначала рассмотрим способы определения строк в программе. Затем выясним, что нужно для чтения строки в программе. И, наконец, изучим способы вывода строки.
7.24.1. Строковые константы.
Вы, вероятно, заметили, когда читали программу, что есть много способов определения строк. Попытаемся теперь рассмотреть основные: использование строковых констант, массивов типа char, указателей на тип char и массивов, состоящих из символьных строк. В программе должно быть предусмотрено выделение памяти для запоминания строки, и мы еще вернемся к этому вопросу.
Всякий раз, когда компилятор встречается с чем-то, заключенным в двойные кавычки, он определяет это как строковую константу. Символы, заключенные в кавычки, плюс, завершающий символ '\0', записываются в последовательные ячейки памяти. Компилятор подсчитывает количество символов, поскольку ему нужно знать размер памяти, необходимой для запоминания строки. Наша Программа использует несколько таких строковых констант, чаще всего в качестве аргументов функций printf () и puts (). Заметим также, что мы можем определять строковые константы при помощи директивы #define
Если вы хотите включить в строку символ двойной кавычки, ему должен предшествовать символ обратной дробной черты:
printf("\"Беги, Спот, беги!\" — сказал Дик\n");
В результате работы этого оператора будет напечатана строка:
"Беги, Спот, беги! — " сказал Дик.
Строковые константы размещаются в статической памяти. Вся фраза в кавычках является указателем на место в памяти, где записана строка. Это аналогично использованию имени массива, служащего указателем на расположение массива. Если это действительно так, то как выглядит оператор, который выводит строку?
/* строки в качестве указателей */
#include <stdio.h>
void main ()
{
printf("%s, %u, %c\n", "We", "love", *"figs");
}
Итак, формат %s выводит строку We. Формат %u выводит целое без знака. Если слово "love" является указателем, то выдается его значение, являющееся адресом первого символа строки. Наконец, *"figs" должно выдать значение, на которое ссылается адрес, т. е. первый символ строки "figs". Произойдет ли это на самом деле? Да, мы получим следующий текст:
We, 34, f
Ну, вот! Давайте теперь вернемся к строкам, находящимся в символьных массивах.
7.24.2. Массивы символьных строк и их инициализация.
При определении массива символьных строк необходимо сообщить компилятору требуемый размер памяти. Один из способов сделать это — инициализировать массив при помощи строковой константы. Так как автоматические массивы нельзя инициализировать, необходимо для этого использовать статические или внешние массивы. Например, оператор
char m1[] = "Только ограничьтесь одной строкой,";
инициализировал внешний (по умолчанию) массив m1 для указанной строки. Этот вид инициализации является краткой формой стандартной инициализации массива
char m1[] = {' Т', ' о', ' л', ' ь', ' к', ' о', ' ', 'о', 'г',
'р', 'а', 'н', 'и', 'ч', 'ь', 'т', 'е', 'с', 'ь',
' ', 'о', 'д', 'н', 'о', 'и', ", 'с', 'т',
'р', 'о', 'к', 'о', 'и', '.', '\0'
(Обратите внимание на замыкающий нуль-символ. Без него мы имеем массив символов, а не строку.) Для той и другой формы (а мы рекомендуем первую) компилятор подсчитывает символы и таким образом получает размер массива.
Как и для других массивов, имя m1 является указателем на первый элемент массива:
m1 == &m1[0], *m1 == 'Т', и *(m1 + 1) == m1[1] == 'о'
Действительно, мы можем использовать указатель для создания строки. Например:
char *m3 = " \n Достаточно обо мне — как вас зовут?";
Это почти то же самое, что и
static char m3[] = " \n Достаточно обо мне — как вас зовут?";
Оба описания говорят об одном: mЗ является указателем строки со словами " Как вас зовут?". В том и другом случае сама строка определяет размер памяти, необходимой для ее размещения. Однако вид их не идентичен.
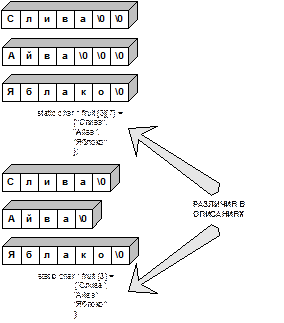
7.24.3. Различия: массив и указатель.
В чем же разница между этими двумя описаниями?
Описание с массивом вызывает создание в статической памяти массива из 38 элементов (по одному на каждый символ плюс один на завершающий символ ' \0'. Каждый элемент инициализируется соответствующим символом. В дальнейшем компилятор будет рассматривать имя mЗ как синоним адреса первого элемента массива, т. е. &m3[0]. Следует отметить, что mЗ является константой указателя. Вы не можете изменить m3, так как это означало бы изменение положения (адрес) массива в памяти. Можно использовать операции, подобные mЗ + 1, для идентификации следующего элемента массива, однако не разрешается выражение ++m3. Оператор увеличения можно использовать с именами переменных, но не констант.
Форма с указателем также вызывает создание в статической памяти 38 элементов для запоминания строки. Но, кроме того, выделяется еще одна ячейка памяти для переменной m3, являющейся указателем. Сначала эта переменная указывает на начало строки, но ее значение может изменяться. Поэтому мы можем использовать операцию увеличения; ++m3 будет указывать на второй символ строки (Д). Заметим, что мы не объявили *m3 статической переменной, потому что мы инициализировали не массив из 38 элементов, а одну переменную типа указатель. Не существует ограничений на класс памяти при инициализации обычных переменных, не являющихся массивом.
Существенны ли эти отличия? Чаще всего нет, но все зависит от того, что вы пытаетесь делать.
Посмотрите несколько примеров, а мы возвращаемся к вопросу выделения памяти для строк.
Массив и указатель: различия
В нижеследующем тексте мы обсудим различия в использовании описаний этих двух видов
static char heart[] = "Я люблю Тилли";
char *head = " Я люблю Милли'",
Основное отличие состоит в том, что указатель heart является константой, в то время как указатель head — переменной. Посмотрим, что на самом деле дает эта разница.
Во-первых, и в том и в другом случае можно использовать операцию сложения с указателем
for (i = 0, i < 6, i++)
putchar(*(heart + i));
putchar(\n');
for (i = 0, i < 6, i++)
putchar(*(head + i));
putchar('\n'),
результате получаем
Я люблю
Я люблю
Но только в случае с указателем можно использовать операцию увеличения:
while (*(head)!= ' \0') /* останов в конце строки */
putchar(*(head++)); /* печать символа и перемещение указателя */
дают в результате
Я люблю Милли!
Предположим, мы хотим заменить head на heart. Мы можем сказать
head = heart /* теперь head указывает на массив heart */
но теперь мы можем сказать
heart = head, /* запрещенная конструкция */
Ситуация аналогична х = 3 или 3 = х, левая часть оператора присваивания должна быть именем переменной. В данном случае head = heart, не уничтожит строку Милли, а только изменит адрес, записанный в head. Вот каким путем можно изменить обращение к heart и проникнуть в сам массив
heart [8] = 'М';
или
*(heart + 8) = 'М';
Элементы массива (но не имя) являются переменными
7.24.4. Явное задание размера памяти.
Иной путь выделения памяти заключается в явном ее задании. Во внешнем описании мы могли бы сказать:
char m1[44] = "Только ограничьтесь одной строкой.";
вместо
char m1[] = "Только ограничьтесь одной строкой.";
Можно быть уверенным, что число элементов, по крайней мере, на один (это снова нуль-символ) больше, чем длина строки. Как и в других статических или внешних массивах, любые неиспользованные элементы автоматически инициализируются нулем (который в символьном виде является нуль-символом, а не символом цифры нуль).

Отметим, что в нашей программе массиву name задан размер:
char name[81];
Поскольку массив name должен читаться во время работы программы, у компилятора нет другого способа узнать заранее, сколько памяти нужно выделить для массива. Это не символьная константа, в которой компилятор может посчитать символы. Поэтому мы предположили, что 80 символов будет достаточно, чтобы поместить в массив фамилию пользователя.
7.24.5. Массивы символьных строк.
Обычно бывает удобно иметь массив символьных строк. В этом случае можно использовать индекс для доступа к нескольким разным строкам. Покажем это на примере:
static char *myta1[LIM] = {" Быстро складываю числа",
" Точно умножаю",
" Записываю данные",
" Правильно выполняю команды",
" Понимаю язык Си" };
Разберемся в этом описании. Вспомним, что LIM имеет значение 5, мы можем сказать, что mytal является массивом, состоящим из пяти указателей на символьные строки. Каждая строка символов, конечно же, представляет собой символьный массив, поэтому у нас есть пять указателей на массивы. Первым указателем является mytal [0], и он ссылается на первую строку. Второй указатель mytal[1] ссылается на вторую строку. Каждый указатель, в частности, ссылается на первый символ своей строки:
*myta1[0] == 'Б', *myta1[1] == 'Т', myta1[2] == 'З'
и т. д.
Инициализация выполняется по правилам, определенным для массивов. Тексты в кавычках эквивалентны скобочной записи
{{...}, {...},..., {...}};
где многоточия подразумевают тексты, которые мы поленились напечатать. В первую очередь мы хотим отметить, что первая последовательность, заключенная в двойные кавычки, соответствует первым парным скобкам и используется для инициализации первого указателя символьной строки. Следующая последовательность в двойных кавычках инициализирует второй указатель и т. д. Запятая разделяет соседние последовательности.
Кроме того, мы могли бы явно задавать размер строк символов, используя описание, подобное такому:
static char myta1[LIM][LINLIM];
Разница заключается в том, что второй индекс задает «прямоугольный» массив, в котором все «ряды» (строки) имеют одинаковую длину. Описание
static char *myta1[LIM]
однако, определяет «рваный» массив, где длина каждого «ряда» определяется той строкой, которая этот «ряд» инициализировала. Рваный массив не тратит память напрасно.
7.24.6. Указатели и строки.
Возможно, вы заметили периодическое упоминание указателей в нашем рассказе о строках. Большинство операций языка Си, имеющих дело со строками, работает с указателями. Например, рассмотрим приведенную ниже бесполезную, но поучительную программу
/* указатели и строки */
#include<stdio.h>
#define PX(X) printf("X = %s; значение = %u; &X = %u\n", X, X, &Х)
void main ()
{
static char *mesg = " He делай глупостей!";
static char *copy;
copy = mesg;
printf("%s\n", copy);
PX(mesg);
PX(copy);
}
Взглянув на эту программу, вы можете подумать, что она копирует строку «Не делай глупостей!», и при беглом взгляде на вывод вам может показаться правильным это предположение:
Не делай глупостей!
mesg = Не делай глупостей!, значение = 14, &mesg = 32
сору = Не делай глупостей!, значение = 14, &сору = 34
Но изучим вывод РХ(). Сначала X, который последовательно является mesg и сору, печатается как строка (%s). Здесь нет сюрприза. Все строки содержат «Не делай глупостей!».
Далее... вернемся к этому несколько позднее.
Третьим элементом в каждой строке является &Х, т. е. адрес X. Указатели mesg и сору записаны в ячейках 32 и 34 соответственно.
Теперь о втором элементе, который мы называем значением. Это сам X. Значением указателя является адрес, который он содержит. Мы видим, что mesg ссылается на ячейку 14, и поэтому выполняется сору.
Смысл заключается в том, что сама строка никогда не копируется. Оператор сору = mesg; создает второй указатель, ссылающийся на ту же самую строку.
Зачем все эти предосторожности? Почему бы не скопировать всю строку? Хорошо, а что эффективнее — копировать один адрес или, скажем, 50 отдельных элементов? Часто бывает, что адрес — это все, что необходимо для выполнения работы.
Теперь, когда мы обсудили определение строк в программе, давайте займемся вводом строк.
7.25. Ввод и вывод строк.
Во многих приложениях более естественно выполнять ввод и вывод информации не посимвольно, а большими последовательностями. Например, файл торговых работников может иметь по одной записи в строке, а одна запись может содержать четыре поля: имя торгового работника, основная зарплата, комиссионные и количество проданного товара; при этом поля разделяются пробелами. В этом случае очень неудобно использовать символьный ввод/вывод.
Процесс ввода строки выполняется за два шага: выделение памяти для запоминания строки и применение функции ввода для получения строки.
7.25.1. Выделение памяти.
Сначала следует определить место для размещения строки при вводе. Как было отмечено раньше, это значит, выделить память, достаточную для размещения любых строк, которые мы предполагаем читать. Не следует надеяться, что компьютер подсчитает длину строки при ее вводе, а затем выделит для нее память. Он не будет этого делать (если только вы не напишите программу, которая должна это выполнять). Если вы попытаетесь сделать что-то подобное
static char *name;
scanf(" %s", name);
компилятор, вероятно, выполнит нужные действия. Но при вводе имя будет записываться на данные или текст вашей программы. Большинство программистов считает это очень забавным, но только в чужих программах.
Проще всего включить в описание явный размер массива:
char name[81];
Можно также использовать библиотечные функции языка Си, которые распределяют память, и мы рассмотрим их позднее.
В нашей программе для name использовался автоматический массив. Мы смогли это сделать, потому что не требовалось инициализации массива.
Как только выделена память для массива, можно считывать строку. Мы уже упоминали, что программы ввода не являются частью языка. Однако большинство систем имеют две библиотечные функции scanf() и gets(), которые могут считывать строки. Чаще всего используется функция gets(), поэтому мы вначале расскажем о ней.
7.25.2. Использование функций gets(), puts(), fgets() и fputs().
Функция fgets() имеет три аргумента, в то время как gets() имеет один. Вот пример ее использования:
/* считывает файл строка за строкой */
#include <stdio.h>
#define MAXLIN 80
void main()
{
FILE *f1;
char string[MAXLIN];
f1 = fopen("story.txt", "r");
while (fgets(string, MAXLIN, f1)!= NULL)
puts(string);
}
Первый из трех аргументов функции fgets() является указателем на местоположение считываемой строки. Мы располагаем вводимую информацию в символьный массив string.
Второй аргумент содержит +. Функция прекращает работу после считывания символа новой строки или после считывания символов общим числом MAXLIN — 1 (в зависимости от того, что произойдет раньше). В любом случае нуль-символ (' \0') добавляется в самый конец строки.
Третий аргумент указывает, конечно, на файл, который будет читаться.
Разница между gets() и fgets() заключается в том, что gets() заменяет символ новой строки на ' \0', в то время как fgets() сохраняет символ новой строки.
Подобно gets() функция fgets() возвращает значение NULL, если встречает символ EOF. Это позволяет вам проверить, как мы и сделали, достигли ли вы конца файла.
Функция fputs() очень похожа на puts(). Оператор
fputs(* Вы были правы.", fileptr);
передает строку " Вы были правы." в файл, на который ссылается указатель fileptr типа FILE. Конечно, сначала нужно открыть файл при помощи функции fopen(). В самом общем виде это выглядит так
status = fputs(указатель строки, указатель файла);
где status является целым числом, которое устанавливается в EOF, если fputs() встречает EOF или ошибку.
Подобно puts() эта функция не ставит завершающий символ ' \0' в конец копируемой строки. В отличие от puts() функция fputs() не добавляет символ новой строки в ее вывод.
Шесть функций ввода-вывода которые мы только что обсудили, должны дать вам инструмент, для чтения и записи текстовых файлов. Есть еще одно средство, которое может оказаться полезным, и мы его сейчас обсудим.
В соответствии со структурой файла лучше рассматривать каждую запись как символьную строку и единицу информации при считывании и записи. Для этого пригодна функция fgets(), которая считывает не отдельные символы, а целые строки. Вдобавок к функции fgets() и ее дополнению fputs() имеются аналогичные макросы gets() и puts().
Функция fgets() имеет три параметра: адрес массива, в котором хранится строка символов, максимальное число хранимых символов и указатель на считываемый файл. Эта функция считывает символы в массив до тех пор, пока количество введенных символов не будет на единицу меньше указанного размера (все символы, включая символ перевода строки) или не будет обнаружен признак конца файла.
Если fgets() считывает символ перевода строки, то он запоминается в массиве. Если считывается хотя бы один символ, то функция автоматически добавляет признак конца строки — null-символ \0. Предположим, что файл BOATSALE.DAT выглядит следующим образом:
Pat Pharr 32767 0.15 30 Beth Mollen 35000 0.12 23 Gary Kohut 40000 0.15 40
Если предположить, что максимальная длина строки равна 40 символам включая символ перевода строки, то следующая программа будет читать записи из файла и записывать их на стандартное устройство вывода:
/*
Программа на С, демонстрирующая считывание записей при помощи
функции fgets и их вывод на stdout при помощи функции fputs
*/
#include "stdafx.h"
#include "E:\LECTURE\AlgorithmProgramming\Universal_HederFile.h"
void StopWait(void);
#define INULL_CHAR 1
#define IMAX_REC_SIZE 40
main()
{
FILE *pfinfile;
char crecord[IMAX_REC_SIZE + INULL_CHAR];
pfinfile=fopen("E:\\LECTURE\\AlgorithmProgramming\\boatsale.dat", "r");
while(fgets(crecord,IMAX_REC_SIZE +INULL_CHAR,pfinfile)!= NULL)
|
|
|
|
|
Дата добавления: 2015-01-03; Просмотров: 609; Нарушение авторских прав?; Мы поможем в написании вашей работы!